Superimposition of Natural Language Conversations Over Software Enabled Services
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

HARTFORD / Including the Following Vicinities: BLOOMFIELD EAST HARTFORD WEST HARTFORD I^'- WETHERSFIELD K
pi i ^ 2 - • 'immmmv?^ » Business ^HH Directory ^CG AND | STREET GUIDE ^ 1 HARTFORD / Including the Following Vicinities: BLOOMFIELD EAST HARTFORD WEST HARTFORD i^'- WETHERSFIELD k HSfpnBnw WHk 1939 A complimentary service rendered to the residents by the merchants and professional people herein listed. We ask your cooperation in PATRONIZING THESE ESTABLISHMENTS STREET GUIDE LISTED ON PINK PAGES It is suggested that the blank pages opposite the business listings be used for numbers frequently called and that the directory be kept convenient to your telephone. Compiled and Published Annually by * UNITED CLASSIFIED AD SERVICE DURANT BLDG., ELIZABETH, N. J. Certified Distribution by Postal Telegraph Distribution can be verified by calling Postal Telegraph *Note—This Classified Business Directory is sponsored, com- piled and published by the United Classified Ad Service, Postal Telegraph acts solely as our agent in effecting the distribution and in rendering a messenger service for the collection of the Directory Listings. Copyright 1938 by United Classified Ad Service, Elizabeth, N. J. ACCOUNTANTS—CERTIFIED PUBLIC BREWER, SAMUEL G., 36 Pearl 2-6663 If no answer call 3-9955 HATHAWAY, EDWIN B. AND CO., 805 Main 7-2814 KNUST, EVERETT & CAMBRIA, 15 Lewis 2-2243 RAPHAEL, EDWARD, 650 Main -.7-8411 SCHAFFMAN, A., 54 Church - 2-7754 SCHWARTZ, HARRY K., 11 Asylum 2-1076 TOUCHE, NIVEN & CO., 36 Pearl 6-2392 ACCOUNTANTS—PUBLIC KAUFMAN, ALBERT S., 1026 Main ...2-9275 NEW ENGLAND ACCOUNTING SERVICE BUREAU, 36 Pearl 7-7028 Res., P. L. HANSON, 27 Frederick -
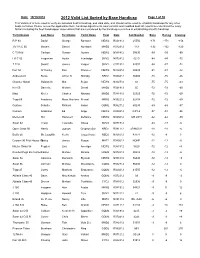
2012 Valid List Sorted by Base Handicap
Date: 10/19/2012 2012 Valid List Sorted by Base Handicap Page 1 of 30 This Valid List is to be used to verify an individual boat's handicap, and valid date, and should not be used to establish handicaps for any other boats not listed. Please review the appilication form, handicap adjustments, boat variants and modified boat list reports to understand the many factors including the fleet handicapper observations that are considered by the handicap committee in establishing a boat's handicap Yacht Design Last Name First Name Yacht Name Fleet Date Sail Number Base Racing Cruising R P 90 David George Rambler NEW2 R021912 25556 -171 -171 -156 J/V I R C 66 Meyers Daniel Numbers MHD2 R012912 119 -132 -132 -120 C T M 66 Carlson Gustav Aurora NEW2 N081412 50095 -99 -99 -90 I R C 52 Fragomen Austin Interlodge SMV2 N072412 5210 -84 -84 -72 T P 52 Swartz James Vesper SMV2 C071912 52007 -84 -87 -72 Farr 50 O' Hanley Ron Privateer NEW2 N072412 50009 -81 -81 -72 Andrews 68 Burke Arthur D Shindig NBD2 R060412 55655 -75 -75 -66 Chantier Naval Goldsmith Mat Sejaa NEW2 N042712 03 -75 -75 -63 Ker 55 Damelio Michael Denali MHD2 R031912 55 -72 -72 -60 Maxi Kiefer Charles Nirvana MHD2 R041812 32323 -72 -72 -60 Tripp 65 Academy Mass Maritime Prevail MRN2 N032212 62408 -72 -72 -60 Custom Schotte Richard Isobel GOM2 R062712 60295 -69 -69 -57 Custom Anderson Ed Angel NEW2 R020312 CAY-2 -57 -51 -36 Merlen 49 Hill Hammett Defiance NEW2 N020812 IVB 4915 -42 -42 -30 Swan 62 Tharp Twanette Glisse SMV2 N071912 -24 -18 -6 Open Class 50 Harris Joseph Gryphon Soloz NBD2 -

Pietro Aaron on Musica Plana: a Translation and Commentary on Book I of the Libri Tres De Institutione Harmonica (1516)
Pietro Aaron on musica plana: A Translation and Commentary on Book I of the Libri tres de institutione harmonica (1516) Dissertation Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Matthew Joseph Bester, B.A., M.A. Graduate Program in Music The Ohio State University 2013 Dissertation Committee: Graeme M. Boone, Advisor Charles Atkinson Burdette Green Copyright by Matthew Joseph Bester 2013 Abstract Historians of music theory long have recognized the importance of the sixteenth- century Florentine theorist Pietro Aaron for his influential vernacular treatises on practical matters concerning polyphony, most notably his Toscanello in musica (Venice, 1523) and his Trattato della natura et cognitione de tutti gli tuoni di canto figurato (Venice, 1525). Less often discussed is Aaron’s treatment of plainsong, the most complete statement of which occurs in the opening book of his first published treatise, the Libri tres de institutione harmonica (Bologna, 1516). The present dissertation aims to assess and contextualize Aaron’s perspective on the subject with a translation and commentary on the first book of the De institutione harmonica. The extensive commentary endeavors to situate Aaron’s treatment of plainsong more concretely within the history of music theory, with particular focus on some of the most prominent treatises that were circulating in the decades prior to the publication of the De institutione harmonica. This includes works by such well-known theorists as Marchetto da Padova, Johannes Tinctoris, and Franchinus Gaffurius, but equally significant are certain lesser-known practical works on the topic of plainsong from around the turn of the century, some of which are in the vernacular Italian, including Bonaventura da Brescia’s Breviloquium musicale (1497), the anonymous Compendium musices (1499), and the anonymous Quaestiones et solutiones (c.1500). -

State Consent Policies and the Meaningful Use of Electronic Health Records Among Nonfederal Acute Care Hospitals in the United States
Walden University ScholarWorks Walden Dissertations and Doctoral Studies Walden Dissertations and Doctoral Studies Collection 2021 State Consent Policies and the Meaningful Use of Electronic Health Records Among Nonfederal Acute Care Hospitals in the United States Adetoro Kafilat Longe Walden University Follow this and additional works at: https://scholarworks.waldenu.edu/dissertations Part of the Health and Medical Administration Commons This Dissertation is brought to you for free and open access by the Walden Dissertations and Doctoral Studies Collection at ScholarWorks. It has been accepted for inclusion in Walden Dissertations and Doctoral Studies by an authorized administrator of ScholarWorks. For more information, please contact [email protected]. Walden University College of Health Professions This is to certify that the doctoral study by Adetoro K. Longe has been found to be complete and satisfactory in all respects, and that any and all revisions required by the review committee have been made. Review Committee Dr. Rabeh Hijazi, Committee Chairperson, Health Sciences Faculty Dr. Kevin Broom, Committee Member, Health Sciences Faculty Dr. Suzanne Richins, University Reviewer, Health Sciences Faculty Chief Academic Officer and Provost Sue Subocz, Ph.D. Walden University 2021 Abstract State Consent Policies and the Meaningful Use of Electronic Health Records Among Nonfederal Acute Care Hospitals in the United States by Adetoro Kafilat Longe MJ, Loyola University, Chicago, 2010 BS, UT Southwestern Medical Center, Dallas, 1995 Proposal Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Healthcare Administration Walden University August 2021 Abstract The less-than-nationwide use of electronic health record (EHR) systems to send, receive, and integrate (SRI) patient summary of care (PSC) records limits the ability of hospital administrators to maximize efficiency and improve quality in the continuum of care. -

Summer- Honor Roll Edition
2007-08 Honor Roll of Donors (June 1, 2007 – May 31, 2008) To everyone who made a gift to Loyola Law School this year, thank you. It is gratifying to see the number of names on 2003 -04 2004 -05 2005 -06 2006 -07 2007 -08 this list grow year after year, and I am impressed by your commitment to Loyola. I know that with your continued Alumni 737,522 818,727 878,767 853,268 711,945 support, we will reach our endowment campaign goals and Corporations 223,865 319,263 475,190 708,491 986,790 further strengthen our faculty, academic programs and student body. Foundations 2,803,500 1,678,050 1,707,250 2,440,766 2,227,120 Best regards, Parents, Friends & Others 51,560 51,923 105,102 277,261 326,037 Victor Gold Total Fundraising 3,816,447 2,867,963 3,166,309 4,279,786 4,251,892 Dean and Professor of Law Dean’s Forum Sallie Miyawaki* Arthur J. Chapman Felipe I. Plascencia Hon. Kathryn Doi Todd Neal E. Schmale Endowed Eilene J. Moore John J. Collins Hon. William R. Pounders Lizette Espinosa Guillermo W. Schnaider Samuel J. Muir Abraham D. Cook Karen Rinehart David S. Ettinger Bradley N. Schweitzer DONORS $25,000+ Sharon Muir Jeffrey L. Crafts Thomas M. Riordan Gregory L. Ezor Barbara U. Schwerin Oscar A. Acosta Joseph W. Mullin, Jr.* William M. Crosby James R. Robie William E. Faith Shelly J. Shafron David S. Aikenhead Marci L. Newman Grogin Jeffrey H. Dasteel Mark P. Robinson, Jr. -

— 150 Years of Oriental Studies at Ca' Foscari
e-ISSN 2610-9506 I libri di Ca’ Foscari 8 ISSN 2610-8917 1868-2018: storie di un ateneo 3 — 150 Years of Oriental Studies at Ca’ Foscari edited by Laura De Giorgi and Federico Greselin Edizioni Ca’Foscari 150 Years of Oriental Studies at Ca’ Foscari I libri di Ca’ Foscari 8 150 Years of Oriental Studies at Ca’ Foscari edited by Laura De Giorgi and Federico Greselin Venezia Edizioni Ca’ Foscari - Digital Publishing 2018 150 Years of Oriental Studies at Ca’ Foscari edited by Laura De Giorgi and Federico Greselin © 2018 Laura De Giorgi and Federico Greselin for the text © 2018 Edizioni Ca’ Foscari - Digital Publishing for this edition cb Qualunque parte di questa pubblicazione può essere riprodotta, memorizzata in un sistema di recupero dati o trasmessa in qualsiasi forma o con qualsiasi mezzo, elettronico o meccanico, senza autorizzazione, a condizione che se ne citi la fonte. Any part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means without permission provided that the source is fully credited. Edizioni Ca’ Foscari - Digital Publishing Università Ca’ Foscari Venezia Dorsoduro 3246, 30123 Venezia http://edizionicafoscari.unive.it | [email protected] 1st edition September 2018 ISBN 978-88-6969-252-9 [ebook] ISBN 978-88-6969-253-6 [print] 150 Years of Oriental Studies at Ca’ Foscari / Edited by Laura De Giorgi and Federico Grese- lin — 1. ed. — Venezia: Edizioni Ca’ Foscari - Digital Publishing, 2018. — 220 pp.; 23 cm. — (I libri di Ca’ Foscari; 8). — ISBN 978-88-6969-253-6. -

CALENDAR Summary Volume
THE UNIVERSITY OF NEW SOUTH WALES • SYDNEY • AUSTRALIA CALENDAR Summary Volume 2005 IMPORTANT The programs, plans, courses and the arrangements for delivery of programs, plans and courses (including specified academic staff) as set out in this publication are indicative only. The University may discontinue or vary arrangements, programs, plans and courses at any time without notice and at its discretion. While the University will try to avoid or minimise any inconvenience, changes may also be made to programs, plans, courses, staff and procedures after enrolment. The University may set limits on the number of students in a course. Students or prospective students may obtain the most recent information from the School or Faculty if required. © The University of New South Wales This document is available in large print, on audiotape, on disk or in Braille for people with print handicap. Please contact Equity & Diversity Unit on (02) 9385 4734 or [email protected] The address of the University of New South Wales is: The University of New South Wales UNSW SYDNEY 2052 AUSTRALIA Telephone: (02) 9385 1000 Facsimile: (02) 9385 2000 Email: [email protected] http://www.unsw.edu.au Edited by UNSW Student Services. Designed, published and printed by Publishing & Printing Services, The University of New South Wales. CRICOS Provider Code No. 00098G ISSN 1325-667X Arms of THE UNIVERSITY OF NEW SOUTH WALES Granted by the College of Heralds, London, 3 March 1952 In 1994 the University title was added to the Arms to create the new University Symbol shown. Heraldic Description of the Arms Argent on a Cross Gules a Lion passant guardant between four Mullets of eight points Or a Chief Sable charged with an open Book proper thereon the word SCIENTIA in letters also Sable. -

L'archivio Della Commissione Soccorsi
COLLECTANEA ARCHIVI VATICANI 111 L’ARCHIVIO DELLA COMMISSIONE SOCCORSI (1939-1958) Inventario a cura di FRANCESCA DI GIOVANNI – GIUSEPPINA ROSELLI TOMO 3 CITTÀ DEL VATICANO ARCHIVIO SEGRETO VATICANO 2019 COLLECTANEA ARCHIVI VATICANI, 111 ISBN 978-88-98638-13-0 TUTTI I DIRITTI RISERVATI © 2019 by Archivio Segreto Vaticano SEGR. STATO, COMMISSIONE SOCCORSI INDICE DEI NOMI Avvertenza I numeri in cifre romane rinviano alle pagine introduttive, quelli in cifre arabiche alle pagine dell’in- ventario. Per i toponimi si è utilizzato il carattere corsivo al fine di distinguerli graficamente dai nomi di persona. Tra parentesi tonde per le località italiane è stata indicata la provincia di appartenenza, mentre per quelle straniere è stato inserito il riferimento allo Stato secondo la attuale situazione politica. Tra vir- golette alte sono riportati i nomi di giornali e riviste. Per le sigle degli ordini religiosi maschili e femminili si rimanda all’Annuario Pontificio. Abbreviazioni ab. = abate/abbadessa mil. = militare/i amb. = ambasciatore min. = ministro/i amm. = amministratore mon. = monastero ap. = apostolico/a mons.= monsignore arch. = architetto naz. = nazionale arcipr. = arciprete nunz. = nunziatura arciv. = arcivescovo on. = onorevole ass. = associazione/i osp. = ospedale avv.= avvocato p. = padre can. =canonico parr. = parroco canc. = cancelliere pont. = pontificio/a capp. = cappellano/i pref. = prefetto card. = cardinale prep. = preposito cav. = cavaliere/i pres. = presidente/ssa col. = colonnello princ. = principe/essa coll. = collegio proc. = procuratore/trice comm. = commendatore prof. = professore/essa commis. = commissario provinc. = provinciale congr. = congregazione/i rappr. = rappresentante/i conv. = convento reg. = regionale cons. = console rett. = rettore del. = delegato/a rev. = reverendo deleg. = delegazione sac. = sacerdote dir.= direttore/rice segr. -

Three Families: Journeys of Gratitude
FALL-winTer 2019-20 TheDifference Three families: Journeys of gratitude Glendale Foundation In this edition 1-2 MESSAGES Helen McDonagh: It’s a privilege… FALL-winTer 2019-20 Irene Bourdon: The greatest joy… Alice Issai: “We’ve come a long way in the past year” 3 COVER FEATURE Promise made, promise kept 4-5 COVER FEATURE Marilyn’s journey of gratitude 6-8 FOUNDATION IN OUR COMMUNITY AND BEYOND Transforming clinical practice Mission Armenia Reducing childhood obesity On the cover 9 COVER FEATURE Hattie praises the hospital Marilyn and Chip Brooks 10-11 PHILANTHROPY relax with Cocoa the cat Testing your family’s financial readiness (page 4) A Legacy of Giving Wall Jayson Lee honors his 12-13 Live Well Senior Program mother (page 3) Senior Health Fair Oct. 13 Hattie Eick’s gifts to 14-18 THE GUILD new moms (page 9) Summer membership party Courage Awards Oct. 24 The Guild President Anita Aghajanian profile 19-23 GALA 2019 “When You Wish” and thank you to our sponsors Remembering Hernan and Orfi Barros 24-25 Hospital acquires advanced 3-D mammography system Volunteer profile: Karen Saunders and Elan the therapy dog 26-30 Thank you, donors! (January 1 - June 30, 2019) Tribute gifts: In honor of, in memory of (January 1 - June 30, 2019) Understanding planned giving options 31 Golf Classic 2019 and appreciation for our sponsors 32-33 Care Hero program: A meaningful way to say “thank you” ”Light Up a Life” Dec. 5 13 10 24 It’s a privilege… …to lead the Foundation Board during these two years and serVe alongside my fellow Board members who often refer, in the first-person, to Adventist Health Glendale as “my hospital.” As a local business owner, I’Ve been involved in business-related activities in Glendale and a large portion of the Los Angeles area for many years. -

Congratulations TO
TO ALL 15,200 Congratulations WINNERS Home Lottery #10685/18 Ryan Evans (#217036) Troy Lightowlers (#105933) You’ve won the Grand Prize Home You’ve won a 2019 Mercedes-AMG in Elsternwick plus $250,000 gold! GT R Coupé or $350,000 gold! Lola Allen (#101315) William Anderson (#166755) Ragnar Haabjoern (#165143) Ian Martin (#183976) You’ve won a 2019 You’ve won a 2019 You’ve won a 2019 You’ve won a 2019 Land Rover Discovery Sport Land Rover Discovery Sport Land Rover Discovery Sport Land Rover Discovery Sport Michelle Royal- Louise McColl (#189921) Melanie Robinson (#144429) Hebblewhite (#006905) You’ve won a 2019 You’ve won a 2019 You’ve won a 2019 Land Rover Discovery Sport Land Rover Discovery Sport Land Rover Discovery Sport Holiday for Life #10686/18 Cash Calendar #10687/18 Christopher Miles Catherine Wood (#518160) (#397717) You’ve won 25 You’ve won $50,000 in the Cash Calendar years of Holidays or $100,000 in gold $5,000 in the Cash Calendar 368041 Julie Mortensen; Mortdale 443096 Barbara Barelli; Berwick 399808 George Sartzetakis; Doncaster 349944 Stephanie Budz; Sunbury 441765 Robert Street; Mitcham 336268 Anthony Clark; Cheltenham 344703 Madelynn Strongman; Westmeadows 397031 Darren Cotzabuyucas; Oakleigh 382747 Stanley Sung; Glen Iris 432421 Stella Cronin; Brunswick West 395061 Kalpana Thanabalan; South Melbourne 306635 Wayne Foley; Mooroolbark 317917 Nick The; Apollo Bay 303680 Stephanie Klevenz; Camberwell 388932 Peter Whitton; Point Cook 421015 Tin Li; Bulleen 378656 Mara Zatkoska; Mill Park Date of Issue Home Lottery Raffle -

To Our Donors
Glendale Foundation March 27, 2020 It won’t surprise you to know that The Difference magazine was written and produced weeks before our world changed with the COVID-19 pandemic. As you read through the many articles, stories and features, I know you will be touched by the things in life that will never change — friendship, service, gratitude, inspiration and compassion. To Our Donors To I hope that through the magazine, you can relive and remember happy experiences and have a renewed sense of hope and anticipation for the better days that are certain to be ahead for us. Irene Bourdon, MPH, CFRE President, Adventist Health Glendale Foundation SPRING-SUMMER 2020 TheDifference Dr. and Mrs. Ronald S. Wu Making our hospital and community a better place Glendale Foundation In this edition SPRING-SUMMER 2020 1-2 MESSAGES Helen McDonagh, Irene Bourdon and Alice Issai 3-5 COVER FEATURE Dr. Ronald and Mrs. Georgiana Wu 6-7 UN GALA 2020 CT scanner for Emergency Dept. Glendale Adventist Emergency Physicians pledge UNGALA sponsors On the cover 8-9 GRATEFUL PATIENT FEATURE Dr. Ronald and Mrs. Georgiana Heart attack at age 34! Wu are applauded by well- Emergency Dept. takes pride in cardiovascular care wishers in the Physicians A cardiologist explains risk factors and heart attack signs Medical Terrace on the occasion of Dr. Wu’s 10-11 GRATEFUL PATIENT FEATURE retirement from his Physician’s talk may have saved her life practice in June 2017. 12-13 DONOR PROFILE Markus Mettler, Leisure Glen Acute Post Care Center Thank you, Michele! 14-19 THE GUILD Counting Our Blessings and Holiday Luncheon 2019 Courage Awards 2019 and Beauty Bus Guild’s Holiday Fashion Show / Fundraiser at Bloomingdale’s Guild members profile: Gracie, Margaret and Georgiana Be Our Valentine luncheon 2020 6 20 OAK SOCIETY & FOUNDATION BOARD Spirit of Giving Award Board members honored for service 21 PHILANTHROPY Values-based estate planning Care Hero Award 22-30 Thank you, donors! (Jan. -

Elenco Magistrati.Htm
Elenco Magistrati Città Nome Cognome Funzione Ufficio in aspettativa mandato - SILVIA DELLA MONICA parlamentare In aspettativa - LORIS PIROZZI in aspettativa infermita' In aspettativa a seguito sospensione - ALFREDO LAUDONIO cautelare In aspettativa in aspettativa mandato - NITTO FRANCESCO PALMA parlamentare In aspettativa in aspettativa mandato - CATERINA CHINNICI amministrativo regionale In aspettativa in aspettativa mandato - ROBERTO MARIA CENTARO parlamentare In aspettativa a seguito sospensione - PATRIZIA SERENA PASQUIN cautelare In aspettativa in aspettativa mandato - FELICE CASSON parlamentare In aspettativa in aspettativa mandato - DONATELLA FERRANTI parlamentare In aspettativa in aspettativa mandato - ANNA FINOCCHIARO parlamentare In aspettativa a seguito sospensione - GIUSEPPE MARIA BLUMETTI cautelare In aspettativa in aspettativa mandato - ALFREDO MANTOVANO parlamentare In aspettativa a seguito sospensione - MICHELE SALVATORE cautelare In aspettativa a seguito sospensione - SEBASTIANO PIO MARIO PULIGA cautelare In aspettativa in aspettativa mandato - GIOVANNI KESSLER amministrativo provinciale In aspettativa - GIUSEPPE ANTONIO GIANNUZZI in aspettativa infermita' In aspettativa a seguito sospensione - FRANCESCO MANZO cautelare In aspettativa a seguito sospensione - CHIARA SCHETTINI cautelare In aspettativa 1 di 463 Elenco Magistrati a seguito sospensione - PIERLUIGI BACCARINI cautelare In aspettativa in aspettativa mandato - GIOVANNI CAROFIGLIO parlamentare In aspettativa in aspettativa per - LAURA VALLI ricongiungimento coniuge