Trends in Computational Social Choice
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Critical Strategies Under Approval Voting: Who Gets Ruled in and Ruled Out
Critical Strategies Under Approval Voting: Who Gets Ruled In And Ruled Out Steven J. Brams Department of Politics New York University New York, NY 10003 USA [email protected] M. Remzi Sanver Department of Economics Istanbul Bilgi University 80310, Kustepe, Istanbul TURKEY [email protected] January 2005 2 Abstract We introduce the notion of a “critical strategy profile” under approval voting (AV), which facilitates the identification of all possible outcomes that can occur under AV. Included among AV outcomes are those given by scoring rules, single transferable vote, the majoritarian compromise, Condorcet systems, and others as well. Under each of these systems, a Condorcet winner may be upset through manipulation by individual voters or coalitions of voters, whereas AV ensures the election of a Condorcet winner as a strong Nash equilibrium wherein voters use sincere strategies. To be sure, AV may also elect Condorcet losers and other lesser candidates, sometimes in equilibrium. This multiplicity of (equilibrium) outcomes is the product of a social-choice framework that is more general than the standard preference-based one. From a normative perspective, we argue that voter judgments about candidate acceptability should take precedence over the usual social-choice criteria, such as electing a Condorcet or Borda winner. Keywords: approval voting; elections; Condorcet winner/loser; voting games; Nash equilibrium. Acknowledgments. We thank Eyal Baharad, Dan S. Felsenthal, Peter C. Fishburn, Shmuel Nitzan, Richard F. Potthoff, and Ismail Saglam for valuable suggestions. 3 1. Introduction Our thesis in this paper is that several outcomes of single-winner elections may be socially acceptable, depending on voters’ individual views on the acceptability of the candidates. -

Brake & Branscomb
Colorado Secretary of State 8/3/2021 Election Rulemaking These proposed edits to the SOS draft are contributed by Emily Brake (R) and Harvie Branscomb (D), and approved by Frank Atwood, Chair of the Approval Voting Party This document may be found on http://electionquality.com version 1.3 8/10/2021 15:50 Only portions of the recent draft rule text are included here with inline edits and comments highlighted as follows: Comments are highlighted in yellow. INSERTS ARE IN GREEN AND LARGE FONT deletions are in red and include strikeout Other indications of strikeout are from the original tabulation process 2.13.2 In accordance with section 1-2-605(7), C.R.S., no later than 90 days following a General Election, the county clerk in each county must SECRETARY OF STATE WILL PROPOSE cancelLATION OF the registrations of electors TO EACH COUNTY CLERK: [Comment: SOS taking responsibility from counties will lead to less verification and less resilience. The SOS office has not been subject to watcher access but will be as various steps of the conduct of election are taken over.] (a) Whose records have been marked “Inactive – returned mail”, “Inactive – undeliverable ballot”, or “Inactive – NCOA”; AND (b) Who have been mailed a confirmation card; and (c) Who have since THEREAFTER failed to vote in two consecutive general elections. New Rule 2.13.3, amendments to current Rule 2.13.3, repeal of 2.13.5, and necessary renumbering:VOTERS WHO REQUEST AN EMERGENCY BALLOT BE SENT TO THEM ELECTRONICALLY MUST BE DIRECTED BY THE COUNTY CLERK TO THE ONLINE BALLOT DELIVERY SYSTEM MAINTAINED BY THE SECRETARY OF STATE TO RECEIVE THEIR BALLOT ELECTRONICALLY. -

THE SINGLE-MEMBER PLURALITY and MIXED-MEMBER PROPORTIONAL ELECTORAL SYSTEMS : Different Concepts of an Election
THE SINGLE-MEMBER PLURALITY AND MIXED-MEMBER PROPORTIONAL ELECTORAL SYSTEMS : Different Concepts of an Election by James C. Anderson A thesis presented to the University of Waterloo in fulfillment of the thesis requirement for the degree of Master of Arts in Political Science Waterloo, Ontario, Canada, 2006 © James C. Anderson 2006 Reproduced with permission of the copyright owner. Further reproduction prohibited without permission. Library and Bibliotheque et Archives Canada Archives Canada Published Heritage Direction du Branch Patrimoine de I'edition 395 Wellington Street 395, rue Wellington Ottawa ON K1A 0N4 Ottawa ON K1A 0N4 Canada Canada Your file Votre reference ISBN: 978-0-494-23700-7 Our file Notre reference ISBN: 978-0-494-23700-7 NOTICE: AVIS: The author has granted a non L'auteur a accorde une licence non exclusive exclusive license allowing Library permettant a la Bibliotheque et Archives and Archives Canada to reproduce,Canada de reproduire, publier, archiver, publish, archive, preserve, conserve,sauvegarder, conserver, transmettre au public communicate to the public by par telecommunication ou par I'lnternet, preter, telecommunication or on the Internet,distribuer et vendre des theses partout dans loan, distribute and sell theses le monde, a des fins commerciales ou autres, worldwide, for commercial or non sur support microforme, papier, electronique commercial purposes, in microform,et/ou autres formats. paper, electronic and/or any other formats. The author retains copyright L'auteur conserve la propriete du droit d'auteur ownership and moral rights in et des droits moraux qui protege cette these. this thesis. Neither the thesis Ni la these ni des extraits substantiels de nor substantial extracts from it celle-ci ne doivent etre imprimes ou autrement may be printed or otherwise reproduits sans son autorisation. -

Responsiveness, Capture and Efficient Policymaking
CENTRO DE INVESTIGACIÓN Y DOCENCIA ECONÓMICAS, A.C. ELECTIONS AND LOTTERIES: RESPONSIVENESS, CAPTURE AND EFFICIENT POLICYMAKING TESINA QUE PARA OBTENER EL GRADO DE MAESTRO EN CIENCIA POLÍTICA PRESENTA JORGE OLMOS CAMARILLO DIRECTOR DE LA TESINA: DR. CLAUDIO LÓPEZ-GUERRA CIUDAD DE MÉXICO SEPTIEMBRE, 2018 CONTENTS I. Introduction .............................................................................................................. 1 II. Literature Review ..................................................................................................... 6 1. Political Ambition .............................................................................................. 6 2. Electoral Systems and Policymaking ................................................................. 7 3. The Revival of Democracy by Lot ..................................................................... 8 III. Lottocracy in Theory .............................................................................................. 12 IV. Elections and Lotteries ........................................................................................... 14 1. Responsiveness ................................................................................................. 14 2. Legislative Capture ........................................................................................... 16 3. Efficiency.......................................................................................................... 18 V. A Formal Model of Legislator’s Incentives .......................................................... -

Are Condorcet and Minimax Voting Systems the Best?1
1 Are Condorcet and Minimax Voting Systems the Best?1 Richard B. Darlington Cornell University Abstract For decades, the minimax voting system was well known to experts on voting systems, but was not widely considered to be one of the best systems. But in recent years, two important experts, Nicolaus Tideman and Andrew Myers, have both recognized minimax as one of the best systems. I agree with that. This paper presents my own reasons for preferring minimax. The paper explicitly discusses about 20 systems. Comments invited. [email protected] Copyright Richard B. Darlington May be distributed free for non-commercial purposes Keywords Voting system Condorcet Minimax 1. Many thanks to Nicolaus Tideman, Andrew Myers, Sharon Weinberg, Eduardo Marchena, my wife Betsy Darlington, and my daughter Lois Darlington, all of whom contributed many valuable suggestions. 2 Table of Contents 1. Introduction and summary 3 2. The variety of voting systems 4 3. Some electoral criteria violated by minimax’s competitors 6 Monotonicity 7 Strategic voting 7 Completeness 7 Simplicity 8 Ease of voting 8 Resistance to vote-splitting and spoiling 8 Straddling 8 Condorcet consistency (CC) 8 4. Dismissing eight criteria violated by minimax 9 4.1 The absolute loser, Condorcet loser, and preference inversion criteria 9 4.2 Three anti-manipulation criteria 10 4.3 SCC/IIA 11 4.4 Multiple districts 12 5. Simulation studies on voting systems 13 5.1. Why our computer simulations use spatial models of voter behavior 13 5.2 Four computer simulations 15 5.2.1 Features and purposes of the studies 15 5.2.2 Further description of the studies 16 5.2.3 Results and discussion 18 6. -

MGF 1107 FINAL EXAM REVIEW CHAPTER 9 1. Amy (A), Betsy
MGF 1107 FINAL EXAM REVIEW CHAPTER 9 1. Amy (A), Betsy (B), Carla (C), Doris (D), and Emilia (E) are candidates for an open Student Government seat. There are 110 voters with the preference lists below. 36 24 20 18 8 4 A E D B C C B C E D E D C B C C B B D D B E D E E A A A A A Who wins the election if the method used is: a) plurality? b) plurality with runoff? c) sequential pairwise voting with agenda ABEDC? d) Hare system? e) Borda count? 2. What is the minimum number of votes needed for a majority if the number of votes cast is: a) 120? b) 141? 3. Consider the following preference lists: 1 1 1 A C B B A D D B C C D A If sequential pairwise voting and the agenda BACD is used, then D wins the election. Suppose the middle voter changes his mind and reverses his ranking of A and B. If the other two voters have unchanged preferences, B now wins using the same agenda BACD. This example shows that sequential pairwise voting fails to satisfy what desirable property of a voting system? 4. Consider the following preference lists held by 5 voters: 2 2 1 A B C C C B B A A First, note that if the plurality with runoff method is used, B wins. Next, note that C defeats both A and B in head-to-head matchups. This example shows that the plurality with runoff method fails to satisfy which desirable property of a voting system? 5. -

On the Distortion of Voting with Multiple Representative Candidates∗
The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) On the Distortion of Voting with Multiple Representative Candidates∗ Yu Cheng Shaddin Dughmi David Kempe Duke University University of Southern California University of Southern California Abstract voters and the chosen candidate in a suitable metric space (Anshelevich 2016; Anshelevich, Bhardwaj, and Postl 2015; We study positional voting rules when candidates and voters Anshelevich and Postl 2016; Goel, Krishnaswamy, and Mu- are embedded in a common metric space, and cardinal pref- erences are naturally given by distances in the metric space. nagala 2017). The underlying assumption is that the closer In a positional voting rule, each candidate receives a score a candidate is to a voter, the more similar their positions on from each ballot based on the ballot’s rank order; the candi- key questions are. Because proximity implies that the voter date with the highest total score wins the election. The cost would benefit from the candidate’s election, voters will rank of a candidate is his sum of distances to all voters, and the candidates by increasing distance, a model known as single- distortion of an election is the ratio between the cost of the peaked preferences (Black 1948; Downs 1957; Black 1958; elected candidate and the cost of the optimum candidate. We Moulin 1980; Merrill and Grofman 1999; Barbera,` Gul, consider the case when candidates are representative of the and Stacchetti 1993; Richards, Richards, and McKay 1998; population, in the sense that they are drawn i.i.d. from the Barbera` 2001). population of the voters, and analyze the expected distortion Even in the absence of strategic voting, voting systems of positional voting rules. -

Stable Voting
Stable Voting Wesley H. Hollidayy and Eric Pacuitz y University of California, Berkeley ([email protected]) z University of Maryland ([email protected]) September 12, 2021 Abstract In this paper, we propose a new single-winner voting system using ranked ballots: Stable Voting. The motivating principle of Stable Voting is that if a candidate A would win without another candidate B in the election, and A beats B in a head-to-head majority comparison, then A should still win in the election with B included (unless there is another candidate A0 who has the same kind of claim to winning, in which case a tiebreaker may choose between A and A0). We call this principle Stability for Winners (with Tiebreaking). Stable Voting satisfies this principle while also having a remarkable ability to avoid tied outcomes in elections even with small numbers of voters. 1 Introduction Voting reform efforts in the United States have achieved significant recent successes in replacing Plurality Voting with Instant Runoff Voting (IRV) for major political elections, including the 2018 San Francisco Mayoral Election and the 2021 New York City Mayoral Election. It is striking, by contrast, that Condorcet voting methods are not currently used in any political elections.1 Condorcet methods use the same ranked ballots as IRV but replace the counting of first-place votes with head- to-head comparisons of candidates: do more voters prefer candidate A to candidate B or prefer B to A? If there is a candidate A who beats every other candidate in such a head-to-head majority comparison, this so-called Condorcet winner wins the election. -
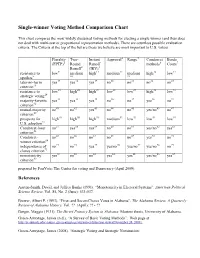
Single-Winner Voting Method Comparison Chart
Single-winner Voting Method Comparison Chart This chart compares the most widely discussed voting methods for electing a single winner (and thus does not deal with multi-seat or proportional representation methods). There are countless possible evaluation criteria. The Criteria at the top of the list are those we believe are most important to U.S. voters. Plurality Two- Instant Approval4 Range5 Condorcet Borda (FPTP)1 Round Runoff methods6 Count7 Runoff2 (IRV)3 resistance to low9 medium high11 medium12 medium high14 low15 spoilers8 10 13 later-no-harm yes17 yes18 yes19 no20 no21 no22 no23 criterion16 resistance to low25 high26 high27 low28 low29 high30 low31 strategic voting24 majority-favorite yes33 yes34 yes35 no36 no37 yes38 no39 criterion32 mutual-majority no41 no42 yes43 no44 no45 yes/no 46 no47 criterion40 prospects for high49 high50 high51 medium52 low53 low54 low55 U.S. adoption48 Condorcet-loser no57 yes58 yes59 no60 no61 yes/no 62 yes63 criterion56 Condorcet- no65 no66 no67 no68 no69 yes70 no71 winner criterion64 independence of no73 no74 yes75 yes/no 76 yes/no 77 yes/no 78 no79 clones criterion72 81 82 83 84 85 86 87 monotonicity yes no no yes yes yes/no yes criterion80 prepared by FairVote: The Center for voting and Democracy (April 2009). References Austen-Smith, David, and Jeffrey Banks (1991). “Monotonicity in Electoral Systems”. American Political Science Review, Vol. 85, No. 2 (June): 531-537. Brewer, Albert P. (1993). “First- and Secon-Choice Votes in Alabama”. The Alabama Review, A Quarterly Review of Alabama History, Vol. ?? (April): ?? - ?? Burgin, Maggie (1931). The Direct Primary System in Alabama. -

Random Selection in Politics
Random selection in politics Lyn Carson and Brian Martin Published in 1999 by Praeger Publishers, Westport, CT Available for purchase from Praeger This is the text submitted to Praeger in February 1999. It differs from the published version in minor ways, including formatting, copy-editing changes, page numbering (100 pages instead of 161) and omission of the index. This version prepared August 2008 Contents 1. Introduction 1 2. Random selection in decision making 10 3. Direct democracy 26 4. Citizen participation without random selection 36 5. Citizen participation with random selection: the early days 43 6. Citizen participation with random selection: yesterday, today, and tomorrow 52 7. Sortition futures 65 8. Strategies 76 Appendix: Examples of citizen participation 84 Bibliography 93 Acknowledgments Brownlea, John Burnheim, Ned Crosby, Many people we’ve talked to find the Jim Dator, Mary Lane, Marcus Schmidt, idea of random selection in politics and Stuart White. Their input was unnatural and unwelcome. This didn’t valuable even when we decided on an deter us! Fortunately, there were a few alternative approach. Helpful comments enthusiasts who got and kept us going. were also received from Ted Becker, Alan Davies, Fred Emery, and Merrelyn Stephen Healy, Lars Klüver, and Ken Emery provided the original inspiration Russell. Others who provided many years ago as well as ongoing information are acknowledged in the conversations. text. The process of obtaining comments Ted Becker encouraged us to write has been stimulating because not all this book. On drafts, we received readers go with us all the way on extensive comments from Arthur randomness. -

Document Country: Macedonia Lfes ID: Rol727
Date Printed: 11/06/2008 JTS Box Number: lFES 7 Tab Number: 5 Document Title: Macedonia Final Report, May 2000-March 2002 Document Date: 2002 Document Country: Macedonia lFES ID: ROl727 I I I I I I I I I IFES MISSION STATEMENT I I The purpose of IFES is to provide technical assistance in the promotion of democracy worldwide and to serve as a clearinghouse for information about I democratic development and elections. IFES is dedicated to the success of democracy throughout the world, believing that it is the preferred form of gov I ernment. At the same time, IFES firmly believes that each nation requesting assistance must take into consideration its unique social, cultural, and envi I ronmental influences. The Foundation recognizes that democracy is a dynam ic process with no single blueprint. IFES is nonpartisan, multinational, and inter I disciplinary in its approach. I I I I MAKING DEMOCRACY WORK Macedonia FINAL REPORT May 2000- March 2002 USAID COOPERATIVE AGREEMENT No. EE-A-00-97-00034-00 Submitted to the UNITED STATES AGENCY FOR INTERNATIONAL DEVELOPMENT by the INTERNATIONAL FOUNDATION FOR ELECTION SYSTEMS I I TABLE OF CONTENTS EXECUTNE SUMMARY I I. PROGRAMMATIC ACTNITIES ............................................................................................. 1 A. 2000 Pre Election Technical Assessment 1 I. Background ................................................................................. 1 I 2. Objectives ................................................................................... 1 3. Scope of Mission .........................................................................2 -

A Canadian Model of Proportional Representation by Robert S. Ring A
Proportional-first-past-the-post: A Canadian model of Proportional Representation by Robert S. Ring A thesis submitted to the School of Graduate Studies in partial fulfilment of the requirements for the degree of Master of Arts Department of Political Science Memorial University St. John’s, Newfoundland and Labrador May 2014 ii Abstract For more than a decade a majority of Canadians have consistently supported the idea of proportional representation when asked, yet all attempts at electoral reform thus far have failed. Even though a majority of Canadians support proportional representation, a majority also report they are satisfied with the current electoral system (even indicating support for both in the same survey). The author seeks to reconcile these potentially conflicting desires by designing a uniquely Canadian electoral system that keeps the positive and familiar features of first-past-the- post while creating a proportional election result. The author touches on the theory of representative democracy and its relationship with proportional representation before delving into the mechanics of electoral systems. He surveys some of the major electoral system proposals and options for Canada before finally presenting his made-in-Canada solution that he believes stands a better chance at gaining approval from Canadians than past proposals. iii Acknowledgements First of foremost, I would like to express my sincerest gratitude to my brilliant supervisor, Dr. Amanda Bittner, whose continuous guidance, support, and advice over the past few years has been invaluable. I am especially grateful to you for encouraging me to pursue my Master’s and write about my electoral system idea.