RDF Databases for Querying XML. a Model-Mapping Approach
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Describing Media Content of Binary Data in XML W3C Working Group Note 2 May 2005
Table of Contents Describing Media Content of Binary Data in XML W3C Working Group Note 2 May 2005 This version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050502 Latest version: http://www.w3.org/TR/xml-media-types Previous version: http://www.w3.org/TR/2004/WD-xml-media-types-20041102 Editors: Anish Karmarkar, Oracle Ümit Yalçınalp, SAP (formerly of Oracle) Copyright © 2005 W3C ® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. > >Abstract This document addresses the need to indicate the content-type associated with binary element content in an XML document and the need to specify, in XML Schema, the expected content-type(s) associated with binary element content. It is expected that the additional information about the content-type will be used for optimizing the handling of binary data that is part of a Web services message. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/. This document is a W3C Working Group Note. This document includes the resolution of the comments received on the Last Call Working Draft previously published. The comments on this document and their resolution can be found in the Web Services Description Working Group’s issues list and in the section C Change Log [p.11] . A diff-marked version against the previous version of this document is available. -
XML Specifications Growth of the Web
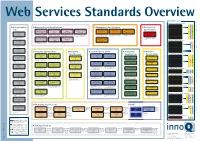
Web Services Standards Overview Dependencies Messaging Specifications SOAP 1.1 SOAP 1.2 Interoperability Business Process Specifications Management Specifications Presentation SOAP Message Transmission Optimization Mechanism WS-Notification the trademarks of their respective owners. of their respective the trademarks Management Using Web Management Of WS-BaseNotification Issues Business Process Execution WS-Choreography Model Web Service Choreography Web Service Choreography WS-Management Specifications Services (WSDM-MUWS) Web Services (WSDM-MOWS) Language for Web Services 1.1 Overview Interface Description Language AMD, Dell, Intel, Microsoft and Sun WS-Topics (BPEL4WS) · 1.1 · BEA Systems, IBM, (WSCI) · 1.0 · W3C 1.0 1.0 1.0 · W3C (CDL4WS) · 1.0 · W3C Microsystems Microsoft, SAP, Sun Microsystems, SAP, BEA Systems WS-BrokeredNotification Working Draft Candidate Recommendation OASIS OASIS Published Specification Web Services for Remote Security Resource Basic Profile Siebel Systems · OASIS-Standard and Intalio · Note OASIS-Standard OASIS-Standard Metadata Portlets (WSRP) WS-Addressing – Core 1.1 ̆ ̆ ̆ ̆ ̆ ̆ ̆ 2.0 WS-I Business Process Execution Language for Web Services WS-Choreography Model Overview defines the format Web Service Choreography Interface (WSCI) describes Web Service Choreography Description Language Web Service Distributed Management: Management Using Web Service Distributed Management: Management Of WS-Management describes a general SOAP-based WS-Addressing – WSDL Binding 1.1(BPEL4WS) provides a language for the formal -

What Is XML Schema?
72076_FM 3/22/02 10:39 AM Page i XML Schema Essentials R. Allen Wyke Andrew Watt Wiley Computer Publishing John Wiley & Sons, Inc. 72076_AppB 3/22/02 10:47 AM Page 378 72076_FM 3/22/02 10:39 AM Page i XML Schema Essentials R. Allen Wyke Andrew Watt Wiley Computer Publishing John Wiley & Sons, Inc. 72076_FM 3/22/02 10:39 AM Page ii Publisher: Robert Ipsen Editor: Cary Sullivan Developmental Editor: Scott Amerman Associate Managing Editor: Penny Linskey Associate New Media Editor: Brian Snapp Text Design & Composition: D&G Limited, LLC Designations used by companies to distinguish their products are often claimed as trademarks. In all instances where John Wiley & Sons, Inc., is aware of a claim, the product names appear in initial capital or ALL CAPITAL LETTERS. Readers, however, should contact the appropriate companies for more complete information regarding trademarks and registration. This book is printed on acid-free paper. Copyright © 2002 by R. Allen Wyke and Andrew Watt. All rights reserved. Published by John Wiley & Sons, Inc. Published simultaneously in Canada. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copy- right Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 750-4744. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 605 Third Avenue, New York, NY 10158-0012, (212) 850-6011, fax (212) 850- 6008, E-Mail: PERMREQ @ WILEY.COM. -

Semantics Developer's Guide
MarkLogic Server Semantic Graph Developer’s Guide 2 MarkLogic 10 May, 2019 Last Revised: 10.0-8, October, 2021 Copyright © 2021 MarkLogic Corporation. All rights reserved. MarkLogic Server MarkLogic 10—May, 2019 Semantic Graph Developer’s Guide—Page 2 MarkLogic Server Table of Contents Table of Contents Semantic Graph Developer’s Guide 1.0 Introduction to Semantic Graphs in MarkLogic ..........................................11 1.1 Terminology ..........................................................................................................12 1.2 Linked Open Data .................................................................................................13 1.3 RDF Implementation in MarkLogic .....................................................................14 1.3.1 Using RDF in MarkLogic .........................................................................15 1.3.1.1 Storing RDF Triples in MarkLogic ...........................................17 1.3.1.2 Querying Triples .......................................................................18 1.3.2 RDF Data Model .......................................................................................20 1.3.3 Blank Node Identifiers ..............................................................................21 1.3.4 RDF Datatypes ..........................................................................................21 1.3.5 IRIs and Prefixes .......................................................................................22 1.3.5.1 IRIs ............................................................................................22 -

Command Injection in XML Signatures and Encryption Bradley W
Command Injection in XML Signatures and Encryption Bradley W. Hill Information Security Partners, July 12, 2007 [email protected] Abstract. The XML Digital Signature1 (XMLDSIG) and XML Encryption2 (XMLENC) standards are complex protocols for securing XML and other content. Among its complexities, the XMLDSIG standard specifies various “Transform” algorithms to identify, manipulate and canonicalize signed content and key material. Unfortunately, the defined transforms have not been rigorously constrained to prevent their use as attack vectors, and denial of service or even arbitrary code execution are probable in implementations that have not specifically guarded against such risks. Attacks against the processing application can be embedded in the KeyInfo portion of a signature, making them inherently unauthenticated, or in the SignedInfo block. Although tampering with the SignedInfo should be detectable, a defective implied order of operations in the specification may still allow unauthenticated attacks here. The ability to execute arbitrary code and perform file system operations with a malicious, invalid signature has been confirmed by the researcher in at least two independent XMLDSIG implementations, and other implementations may be similarly vulnerable. This paper describes the vulnerabilities in detail and offers advice for remediation. The most damaging attack is also likely to apply in other contexts where XSLT is accepted as input, and should be considered by all implementers of complex XML processing systems. Categories and Subject Descriptors Primary Classification: K.6.5 Security and Protection Subject: Invasive software Unauthorized access Authentication Additional Classification: D.2.3 Coding Tools and Techniques (REVISED) Subject: Standards D.2.1 Requirements/Specifications (D.3.1) Subject: Languages Tools General Terms: Security, Reliability, Verification, and Design. -

Describing Media Content of Binary Data in XML W3C Working Group Note 4 May 2005
Table of Contents Describing Media Content of Binary Data in XML W3C Working Group Note 4 May 2005 This version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050504 Latest version: http://www.w3.org/TR/xml-media-types Previous version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050502 Editors: Anish Karmarkar, Oracle Ümit Yalçınalp, SAP Copyright © 2005 W3C ® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. > >Abstract This document addresses the need to indicate the content-type associated with binary element content in an XML document and the need to specify, in XML Schema, the expected content-type(s) associated with binary element content. It is expected that the additional information about the content-type will be used for optimizing the handling of binary data that is part of a Web services message. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/. This document is a W3C Working Group Note. This document includes the resolution of the comments received on the Last Call Working Draft previously published. The comments on this document and their resolution can be found in the Web Services Description Working Group’s issues list. There is no technical difference between this document and the 2 May 2005 version; the acknowledgement section has been updated to thank external contributors. -

RDF Query Languages Need Support for Graph Properties
RDF Query Languages Need Support for Graph Properties Renzo Angles1, Claudio Gutierrez1, and Jonathan Hayes1,2 1 Dept. of Computer Science, Universidad de Chile 2 Dept. of Computer Science, Technische Universit¨at Darmstadt, Germany {rangles,cgutierr,jhayes}@dcc.uchile.cl Abstract. This short paper discusses the need to include into RDF query languages the ability to directly query graph properties from RDF data. We study the support that current RDF query languages give to these features, to conclude that they are currently not supported. We propose a set of basic graph properties that should be added to RDF query languages and provide evidence for this view. 1 Introduction One of the main features of the Resource Description Framework (RDF) is its ability to interconnect information resources, resulting in a graph-like structure for which connectivity is a central notion [GLMB98]. As we will argue, basic concepts of graph theory such as degree, path, and diameter play an important role for applications that involve RDF querying. Considering the fact that the data model influences the set of operations that should be provided by a query language [HBEV04], it follows the need for graph operations support in RDF query languages. For example, the query “all relatives of degree 1 of Alice”, submitted to a genealogy database, amounts to retrieving the nodes adjacent to a resource. The query “are suspects A and B related?”, submitted to a police database, asks for any path connecting these resources in the (RDF) graph that is stored in this database. The query “what is the Erd˝osnumber of Alberto Mendelzon”, submitted to (a RDF version of) DBLP, asks simply for the length of the shortest path between the nodes representing Erd˝osand Mendelzon. -

XML Information Set
XML Information Set XML Information Set W3C Recommendation 24 October 2001 This version: http://www.w3.org/TR/2001/REC-xml-infoset-20011024 Latest version: http://www.w3.org/TR/xml-infoset Previous version: http://www.w3.org/TR/2001/PR-xml-infoset-20010810 Editors: John Cowan, [email protected] Richard Tobin, [email protected] Copyright ©1999, 2000, 2001 W3C® (MIT, INRIA, Keio), All Rights Reserved. W3C liability, trademark, document use and software licensing rules apply. Abstract This specification provides a set of definitions for use in other specifications that need to refer to the information in an XML document. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. The latest status of this document series is maintained at the W3C. This is the W3C Recommendation of the XML Information Set. This document has been reviewed by W3C Members and other interested parties and has been endorsed by the Director as a W3C Recommendation. It is a stable document and may be used as reference material or cited as a normative reference from another document. W3C's role in making the Recommendation is to draw attention to the specification and to promote its widespread deployment. This enhances the functionality and interoperability of the file:///C|/Documents%20and%20Settings/immdca01/Desktop/xml-infoset.html (1 of 16) [8/12/2002 10:38:58 AM] XML Information Set Web. This document has been produced by the W3C XML Core Working Group as part of the XML Activity in the W3C Architecture Domain. -
5241 Index 0939-0964.Qxd 29/08/02 5.30 Pm Page 941
5241_index_0939-0964.qxd 29/08/02 5.30 pm Page 941 INDEX 941 5241_index_0939-0964.qxd 29/08/02 5.30 pm Page 942 Index 942 Regular A Alternatives, 362 Analysis Patterns: Reusable Expression ABSENT value, 67 Object Models, 521 Symbols abstract attribute, 62, 64–66 ancestor (XPath axis), 54 of complexType element, ancestor-or-self (XPath axis), . escape character, 368, 369 247–248, 512, 719 54 . metacharacter, 361 of element element, 148–149 Annotation, 82 ? metacharacter, 361, 375 mapping to object-oriented defined, 390 ( metacharacter, 361 language, 513–514 mapping to object-oriented ) metacharacter, 361 Abstract language, 521 { metacharacter, 361 attribute type, 934 Microsoft use of term, } metacharacter, 361 defined, 58 821–822 + metacharacter, 361, 375 element type, 16, 17, 18, 934 properties of, 411 * metacharacter, 361, 375 object, corresponding to docu- annotation content option ^ metacharacter, 379 ment, 14 for schema element, 115 \ metacharacter, 361 uses of term, 238, 931–932 annotation element, 82, 83, | metacharacter, 361 Abstract character, 67 254, 260, 722, 859 \. escape character, 366 Abstract document attributes of, 118 \? escape character, 366 document information item content options for, 118–119 \( escape character, 367 view of, 62 example of use of, 117 \) escape character, 367 infoset view of, 62 function of, 116, 124, 128 \{ escape character, 367 makeup of, 59 nested, 83–84 \} escape character, 367 properties of, 66 Anonymous component, 82 \+ escape character, 367 Abstract element, 14–15 any element, 859 \- escape character, -

Web and Semantic Web Query Languages: a Survey
Web and Semantic Web Query Languages: A Survey James Bailey1, Fran¸coisBry2, Tim Furche2, and Sebastian Schaffert2 1 NICTA Victoria Laboratory Department of Computer Science and Software Engineering The University of Melbourne, Victoria 3010, Australia http://www.cs.mu.oz.au/~jbailey/ 2 Institute for Informatics,University of Munich, Oettingenstraße 67, 80538 M¨unchen, Germany http://pms.ifi.lmu.de/ Abstract. A number of techniques have been developed to facilitate powerful data retrieval on the Web and Semantic Web. Three categories of Web query languages can be distinguished, according to the format of the data they can retrieve: XML, RDF and Topic Maps. This ar- ticle introduces the spectrum of languages falling into these categories and summarises their salient aspects. The languages are introduced us- ing common sample data and query types. Key aspects of the query languages considered are stressed in a conclusion. 1 Introduction The Semantic Web Vision A major endeavour in current Web research is the so-called Semantic Web, a term coined by W3C founder Tim Berners-Lee in a Scientific American article describing the future of the Web [37]. The Semantic Web aims at enriching Web data (that is usually represented in (X)HTML or other XML formats) by meta-data and (meta-)data processing specifying the “meaning” of such data and allowing Web based systems to take advantage of “intelligent” reasoning capabilities. To quote Berners-Lee et al. [37]: “The Semantic Web will bring structure to the meaningful content of Web pages, creating an environment where software agents roaming from page to page can readily carry out sophisticated tasks for users.” The Semantic Web meta-data added to today’s Web can be seen as advanced semantic indices, making the Web into something rather like an encyclopedia. -

XML-Based RDF Data Management for Efficient Query Processing
XML-Based RDF Data Management for Efficient Query Processing Mo Zhou Yuqing Wu Indiana University, USA Indiana University, USA [email protected] [email protected] Abstract SPARQL[17] is a W3C recommended RDF query language. A The Semantic Web, which represents a web of knowledge, offers SPARQL query contains a collection of triples with variables called new opportunities to search for knowledge and information. To simple access patterns which form graph patterns for describing harvest such search power requires robust and scalable data repos- query requirements. For SELECT ?t example, the SPARQL itories that can store RDF data and support efficient evaluation of WHERE {?p type Person. ?r ?x ?t. SPARQL queries. Most of the existing RDF storage techniques rely ?p name ?n. ?p write ?r} query on the left re- on relation model and relational database technologies for these trieves all properties of tasks. They either keep the RDF data as triples, or decompose it reviews written by a person whose name is known. into multiple relations. The mis-match between the graph model The needs to develop applications on the Semantic Web and sup- of the RDF data and the rigid 2D tables of relational model jeop- port search in RDF graphs call for RDF repositories to be reliable, ardizes the scalability of such repositories and frequently renders a robust and efficient in answering SPARQL queries. As in the con- repository inefficient for some types of data and queries. We pro- text of RDB and XML, the selection of storage models is critical to pose to decompose RDF graph into a forest of semantically cor- a data repository as it is the dominating factor to determine how to related XML trees, store them in an XML repository and rewrite evaluate queries and how the system behaves when it scales up. -

Answering SPARQL Queries Modulo RDF Schema with Paths Faisal Alkhateeb, Jérôme Euzenat
Answering SPARQL queries modulo RDF Schema with paths Faisal Alkhateeb, Jérôme Euzenat To cite this version: Faisal Alkhateeb, Jérôme Euzenat. Answering SPARQL queries modulo RDF Schema with paths. [Research Report] RR-8394, INRIA. 2013, pp.46. hal-00904961 HAL Id: hal-00904961 https://hal.inria.fr/hal-00904961 Submitted on 15 Nov 2013 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Answering SPARQL queries modulo RDF Schema with paths Faisal Alkhateeb, Jérôme Euzenat RESEARCH REPORT N° 8394 November 2013 Project-Teams Exmo ISSN 0249-6399 ISRN INRIA/RR--8394--FR+ENG Answering SPARQL queries modulo RDF Schema with paths Faisal Alkhateeb∗, Jérôme Euzenat† Project-Teams Exmo Research Report n° 8394 — November 2013 — 46 pages Abstract: SPARQL is the standard query language for RDF graphs. In its strict instantiation, it only offers querying according to the RDF semantics and would thus ignore the semantics of data expressed with respect to (RDF) schemas or (OWL) ontologies. Several extensions to SPARQL have been proposed to query RDF data modulo RDFS, i.e., interpreting the query with RDFS semantics and/or considering external ontologies. We introduce a general framework which allows for expressing query answering modulo a particular semantics in an homogeneous way.