Forecasting Volatility and Volume in the Tokyo Stock Market: Long Memory, Fractality and Regime Switching
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Page 16 of 128 Exhibit No. Description Deposition
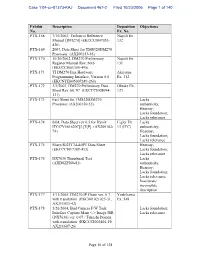
Case 1:04-cv-01373-KAJ Document 467-2 Filed 10/23/2006 Page 1 of 140 Exhibit Description Deposition Objections No. Ex. No. PTX-168 7/16/2003, Technical Reference Napoli Ex. Manual [DM270] (EKCCCI007053- 132 836) PTX-169 2003, Data Sheet for TMS320DM270 Processor (AX200153-55) PTX-170 10/30/2002, DM270 Preliminary Napoli Ex. Register Manual Rev. b0.6 131 (EKCCCI001305-495) PTX-171 TI DM270 Imx Hardware Akiyama Programming Interface, Version 0.0 Ex. 312 (EKCNYII005007249-260) PTX-172 3/3/2003, DM270 Preliminary Data Ohtake Ex. Sheet Rev. b0.7C (EKCCCI008094- 123 131) PTX-173 Fact Sheet for TMS320DM270 Lacks Processor (AX200150-52) authenticity; Hearsay; Lacks foundation; Lacks relevance PTX-174 6/04, Data Sheet rev 0.5 for Hynix Ligler Ex. Lacks HY57V561620C[L]T[P] (AX200163- 13 (ITC) authenticity; 74) Hearsay; Lacks foundation; Lacks relevance PTX-175 Sharp RJ21T3AA0PT Data Sheet Hearsay; (EKCCCI017389-413) Lacks foundation; Lacks relevance PTX-176 DX7630 Thumbnail Test Lacks (AXD022568-81) authenticity; Hearsay; Lacks foundation; Lacks relevance; Inaccurate/ incomplete description PTX-177 1/11/2005, DM270 IP Chain ver. 0.7 Yoshikawa with translation (EKC001021025-31, Ex. 348 AX211033-42) PTX-178 1/26/2004, Bud Camera F/W Task Lacks foundation; Interface Capture Main <-> Image ISR Lacks relevance (DX7630) ver. 0.07 / Takeshi Domen with translation (EKCCCI002404-19, AX211607-26) Page 16 of 128 Case 1:04-cv-01373-KAJ Document 467-2 Filed 10/23/2006 Page 2 of 140 Exhibit Description Deposition Objections No. Ex. No. PTX-179 2/17/2003, Budweiser Camera EXIF Akiyama Lacks foundation; File Access Library Spec (DX7630) Ex. -

KODAK MILESTONES 1879 - Eastman Invented an Emulsion-Coating Machine Which Enabled Him to Mass- Produce Photographic Dry Plates
KODAK MILESTONES 1879 - Eastman invented an emulsion-coating machine which enabled him to mass- produce photographic dry plates. 1880 - Eastman began commercial production of dry plates in a rented loft of a building in Rochester, N.Y. 1881 - In January, Eastman and Henry A. Strong (a family friend and buggy-whip manufacturer) formed a partnership known as the Eastman Dry Plate Company. ♦ In September, Eastman quit his job as a bank clerk to devote his full time to the business. 1883 - The Eastman Dry Plate Company completed transfer of operations to a four- story building at what is now 343 State Street, Rochester, NY, the company's worldwide headquarters. 1884 - The business was changed from a partnership to a $200,000 corporation with 14 shareowners when the Eastman Dry Plate and Film Company was formed. ♦ EASTMAN Negative Paper was introduced. ♦ Eastman and William H. Walker, an associate, invented a roll holder for negative papers. 1885 - EASTMAN American Film was introduced - the first transparent photographic "film" as we know it today. ♦ The company opened a wholesale office in London, England. 1886 - George Eastman became one of the first American industrialists to employ a full- time research scientist to aid in the commercialization of a flexible, transparent film base. 1888 - The name "Kodak" was born and the KODAK camera was placed on the market, with the slogan, "You press the button - we do the rest." This was the birth of snapshot photography, as millions of amateur picture-takers know it today. 1889 - The first commercial transparent roll film, perfected by Eastman and his research chemist, was put on the market. -

(12) United States Patent (10) Patent No.: US 8,970,761 B2 Anderson (45) Date of Patent: *Mar
US0089.70761 B2 (12) United States Patent (10) Patent No.: US 8,970,761 B2 Anderson (45) Date of Patent: *Mar. 3, 2015 (54) METHOD AND APPARATUS FOR (58) Field of Classification Search CORRECTING ASPECTRATO INA USPC .......................... 348/333.01, 333.11,333.12, CAMERA GRAPHICAL USER INTERFACE 348/333.O2 333.08 See application file for complete search history. (75) Inventor: Eric C. Anderson, Gardnerville, NV (US) (56) References Cited (73) Assignee: Flashpoint Technology, Inc., Raleigh, NC (US) U.S. PATENT DOCUMENTS (*) Notice: Subject to any disclaimer, the term of this 610,861 A 9, 1898 Goodwin patent is extended or adjusted under 35 725,034 A 4, 1903 Brownell U.S.C. 154(b) by 0 days. (Continued) This patent is Subject to a terminal dis FOREIGN PATENT DOCUMENTS claimer. DE 3518887 C1 9, 1986 (21) Appl. No.: 13/305,288 EP OO59435 A2 9, 1982 (22) Filed: Nov. 28, 2011 (Continued) OTHER PUBLICATIONS (65) Prior Publication Data US 2012/O133817 A1 May 31, 2012 Klein, W. F. “Cathode-Ray Tube Rotating Apparatus.” IBM Techni cal Disclosure Bulletin, vol. 18, No. 11, Apr. 1976, 3 pages. Related U.S. Application Data (Continued) (63) Continuation of application No. 09/213,131, filed on Dec. 15, 1998, now Pat. No. 8,102,457, which is a continuation of application No. 08/891,424, filed on Primary Examiner —Yogesh Aggarwal Jul. 9, 1997, now Pat. No. 5,973,734. (74) Attorney, Agent, or Firm — Withrow & Terranova, PLLC (51) Int. Cl. H04N 5/222 (2006.01) H04N I/00 (2006.01) (57) ABSTRACT H04N I/2 (2006.01) A device and method are provided that retrieves a plurality of (Continued) thumbnails corresponding to a plurality of images captured (52) U.S. -

Notice of Resolutions (AGM June 2003)
The Bank of Tokyo-Mitsubishi, Ltd. Global Securities Services Division Notice of Resolutions Below is the outcome of the votes taken in the AGMs held in June 2003. Y: Approved N: Rejected Agenda Item No. QUICK ISIN Description Remarks 123456789101112131415 1301 JP3257200000 KYOKUYO CO., LTD. YYYYYY 1331 JP3666000009 NICHIRO CORPORATION --CHGED FROM NICHIRO GYOGYO KAISHA YYYYYYY 1332 JP3718800000 NIPPON SUISAN KAISHA, LTD. YYYYY 1333 JP3876600002 MARUHA CORP. (FM TAIYO FISHERY) YYYYYY 1379 JP3843250006 HOKUTO YYYYYY 1491 JP3519000008 CHUGAI MINING YYYYY 1501 JP3889600007 MITSUI MINING YYYY 1503 JP3406200000 SUMITOMO COAL MINING YYY 1515 JP3680800004 NITTETSU MINING YYYYY 1518 JP3894000003 MITSUI-MATSUSHIMA (EX-MATSUSHIMA KOSAN) YYY 1725 JP3816710002 FUJITA CORPORATION (NEW) YYYY 1736 JP3172410007 OTEC CORPORATION YYYYYY 1742 JP3421900006 SECOM TECHNO SERVICE CO.,LTD. YYYYY 1757 JP3236100008 KIING HOME YYYYY 1777 JP3224800007 KAWASAKI SETSUBI KOGYO YYYYYY 1793 JP3190500003 OHMOTO GUMI YYYYYY 1800 JP3629600002 TONE GEO TECH YYYYY 1801 JP3443600006 TAISEI CORP. YYYYYY 1802 JP3190000004 OBAYASHI CORPORATION YYYYYY 1803 JP3358800005 SHIMIZU CORP. YYYYY 1805 JP3629800008 TOBISHIMA CORP. YYYYYYY 1808 JP3768600003 HASEKO CORP. ( CHGD FM HASEGAWA KOUMUTEN ) YYYY 1810 JP3863600007 MATSUI CONSTRUCTION YYY Y 1811 JP3427800002 ZENITAKA CORP. YYY YYYY 1812 JP3210200006 KAJIMA CORP. YYY YYY 1813 JP3825600004 FUDO CONSTRUCTION CO., LTD. YYY YY 1815 JP3545600003 TEKKEN CORP. (FM TEKKEN CONSTRUCTION CO., LTD.) YYY Y 1816 JP3128000001 ANDO CORP. YYY YYYY 1820 JP3659200004 NISHIMATSU CONSTRUCTION YYY YY 1821 JP3889200006 SUMITOMO MITSUI CONSTRUCTION CO., LTD. (FM. MITSUI COST. CO YY 1822 JP3498600000 DAIHO CONSTRUCTION YYY YYY 1824 JP3861200008 MAEDA CORP. YYY YY 1825 JP3227350000 ECO-TECH CONSTRUCTION CO.,LTD.(FM ISHIHARA CONSTRUCTION) Y Y YY Agenda 2 : Short of quorum 1827 JP3643600004 NAKANO CORP. -

06Ba54c425e4b8570c2b686b5c
http://people.smu.edu/rmonagha/third/mfg.html Third Party Lens Manufacturers by Robert Monaghan Related Local Links: Cautionary Tale on Fitting a Tokina Lens to a Minolta Maxxum Camera (Peter Van Eyk) Samigon Lenses Related Links: About Dr. Optiks Camera Mount Adapter FAQ (interchangeable mounts) Canon Camera Museum Chinon 35mm Pages Japan Photography History Kalimar Kalimex 35mm Lenses (post-soviet Ukraine/Czech) Kalimex (Kiev) My View on Mfgers (Klaus Schroiff) Nikon Corp. History Optical Glass Manufacturers Promaster Samsung History Samyang/Phoenix Short History of Japanese Lenses Sicor Optics Sigma Lens Site [02/00] Sigma Lenses Soligor T2 Lenses (for Miranda) [11/2002] Soligor Lenses [11/2002] Spiratone History Tamron Tokina Tokina (UK) Vivitar Third Party Lens Makers U.S. Importer/Distributors Name on Lens Manufacturers (country) Acetar Ace Optical Co. Ltd. (Japan) Actinar Aetna Optix Inc. Adorama Camera Co. Adorama (numerous mfgers) Alto Yamasaki Optical Co. Ltd. (Japan) Angenieux Angenieux Corp. (French) Aragon Photo Clearing Inc. Asanuma Tokina Optical Co. Ltd. (Japan) Bausch and Lomb Inc. Baltar (numerous mfgers) Bushnell Bausch and Lomb Inc. (numerous mfgers) Cambron Cambridge Camera Exchange Inc. Cimko Cima Kogaku Corp. Ltd. (Japan) Coligon Aetna Optix Inc. Congo Yamasaki Optical Co. Ltd. (Japan) CPC Combined Products Corp. CPO Century Precision Optics (USA) Cosina Cosina Inc./Samyang Corp. (Korea) Dejur Photo International Inc. Eitar Reeves Photographic Inc. Enna Europhot Inc. Eyemik Mitake Optical Co. Ltd. (Japan) Hi-Lux Nissin Koki Co. Ltd. (Japan) Kenlock Kenlock Corp. (Japan) Kiev/USA Kiev Arsenal (Ukraine) Kalimex s.r.o. (Czech) Kilfit Heinz Kilfit Munchen Corp. (West Germany?) Kimunor Kimura Seimitsu Kogyo Co. -

When@Dinosaurs@Flyz@The@Role@Of@Firm@Capab
p。ー・イ@エッ@「・@ーイ・ウ・ョエ・、@。エ@@druidQW nyu@sエ・イョ@s」ィッッャ@ッヲ@bオウゥョ・ウウL@n・キ@yッイォL@jオョ・@QRMQTL@RPQW when@dinosaurs@flyZ@the@role@of@firm@capabilities@in@the avianization@of@incumbents@during@disruptive technological@change r。ェ。@rッケ nッイエィ・。ウエ・イョ@iャャゥョッゥウ@uョゥカ・イウゥエケ m。ョ。ァ・ュ・ョエ イイッケ`ョ・ゥオN・、オ iイゥョ。@sエッケョ・カ。 pィゥャ。、・ャーィゥ。@uョゥカ・イウゥエケ m。ョ。ァ・ュ・ョエ sエッケョ・カ。i`ーィゥャ。オN・、オ cオイ「。@l。ュー・イエ fャッイゥ、。@iョエ・イョ。エゥッョ。ャ@uョゥカ・イウゥエケ m。ョァ・ュ・ョエ@。ョ、@iョエ・イョ。エゥッョ。ャ@bオウゥョ・ウウ 」ャ。ュー・イエ`ヲゥオN・、オ @ @ a「ウエイ。」エ pイゥッイ@イ・ウ・。イ」ィ@ウオァァ・ウエウ@エィ。エ@ャ。イァ・@ゥョ」オュ「・ョエウ@キゥャャ@「・」ッュ・@カゥ」エゥュウ@ッヲ@、ゥウイオーエゥカ・@エ・」ィョッャッァゥ」。ャ@」ィ。ョァ・N@w・ ゥョカ・ウエゥァ。エ・@エィ・@ゥュ。ァ・@ウ・ョウッイ@ゥョ、オウエイケ@ゥョ@キィゥ」ィ@エィ・@・ュ・イァ・ョ」・@ッヲ@cmos@ウ・ョウッイウ@」ィ。ャャ・ョァ・、@エィ・@ュ。ョオヲ。」エオイ・イウ ッヲ@ccd@ウ・ョウッイウN@aャエィッオァィ@エィゥウ@エ・」ィョッャッァゥ」。ャ@、ゥウイオーエゥッョ@ャ・、@エッ@エィ・@、ゥョッウ。オイゥコ。エゥッョ@ッヲ@ccd@エ・」ィョッャッァケL@ゥエ@。ャウッ@ャ・、 エッ@。カゥ。ョゥコ。エゥッョッイ@ウエイ。エ・ァゥ」@イ・ョ・キ。ャヲッイ@ウッュ・@ゥョ」オュ「・ョエウL@ウゥュゥャ。イ@エッ@ィッキ@ウッュ・@、ゥョッウ。オイウ@ウオイカゥカ・、@エィ・@ュ。ウウ cイ・エ。」・ッオウMt・イエゥ。イケ@・クエゥョ」エゥッョ@「ケ@・カッャカゥョァ@ゥョエッ@「ゥイ、ウN@w・@ヲゥョ、@エィ。エ@ccd@ュ。ョオヲ。」エオイ・イウ@エィ。エ@。カゥ。ョゥコ・、@キ・イ・ ーイ・。、。ーエ・、@エッ@エィ・@、ゥウイオーエゥカ・@cmos@エ・」ィョッャッァケ@ゥョ@エィ。エ@エィ・ケ@ーッウウ・ウウ・、@イ・ャ・カ。ョエ@」ッューャ・ュ・ョエ。イケ@エ・」ィョッャッァゥ・ウ 。ョ、@。」」・ウウ@エッ@ゥョMィッオウ・@オウ・イウ@エィ。エ@。ャャッキ・、@エィ・ュ@エッ@ウエイ。エ・ァゥ」。ャャケ@イ・ョ・キ@エィ・ュウ・ャカ・ウN j・ャ」ッ、・ウZoSRLM Powered by TCPDF (www.tcpdf.org) When Dinosaurs Fly ! ABSTRACT Prior research suggests that large incumbents will become victims of disruptive technological change. -

THREE ESSAYS by Tuhin Chaturvedi BE, Visvesw
CORPORATE DEVELOPMENT AS AN ADAPTIVE MECHANISM IN EVOLVING TECHNOLOGY ECOSYSTEMS: THREE ESSAYS by Tuhin Chaturvedi B.E., Visveswariah Technological University, 2005 MSc., The University of Warwick, 2009 Submitted to the Graduate Faculty of Joseph M. Katz Graduate School of Business in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Strategic Management University of Pittsburgh 2018 UNIVERSITY OF PITTSBURGH JOSEPH M. KATZ GRADUATE SCHOOL OF BUSINESS This dissertation was presented by Tuhin Chaturvedi It was defended on April 12, 2018 and approved by Ravi Madhavan, Ph.D., Professor of Business Administration Katz Graduate School of Business, University of Pittsburgh Susan K. Cohen, Ph.D., Associate Professor of Business Administration Katz Graduate School of Business, University of Pittsburgh Yu Cheng, Ph.D., Associate Professor of Statistics, Department of Statistics, University of Pittsburgh Tsuhsiang Hsu, Ph.D. Assistant Professor of Management, Mihaylo College of Economics and Business, California State University, Fullerton Dissertation Advisor: John E. Prescott, Ph.D., Thomas O’Brien Chair of Strategy, Katz Graduate School of Business, University of Pittsburgh ii Copyright © by Tuhin Chaturvedi 2018 iii CORPORATE DEVELOPMENT AS AN ADAPTIVE MECHANISM IN EVOLVING TECHNOLOGY ECOSYSTEMS: THREE ESSAYS Tuhin Chaturvedi, Ph.D. University of Pittsburgh, 2018 As contemporary business environments across the globe are increasingly affected by the advent of disruptive technologies, several technology ecosystems are in a consistent state of flux driven by the fast paced and discontinuous nature of technological change. This dissertation addresses the adaptive role of firms’ corporate development decisions in these dynamic and fast changing environments. I theorize on and empirically evaluate the role of four corporate development decisions – internal development, alliances, acquisitions and divestitures as adaptive mechanisms towards improving the likelihood of survival in evolving technology ecosystems. -

Case 7 Eastman Kodak: Meeting the Digital Challenge
CTAC07 4/13/07 17:22 Page 99 case 7 Eastman Kodak: Meeting the Digital Challenge January 2004 marked the beginning of Dan Carp’s fifth year as Eastman Kodak Inc.’s chief executive officer. By late February, it was looking as though 2004 would also be his most challenging. The year had begun with Kodak’s dissident shareholders becoming louder and bolder. The critical issue was Kodak’s digital imaging strategy that Carp had presented to investors in September 2003. The strategy called for a rapid accel- eration in Kodak’s technological and market development of its digital imaging business – involving some $3 billion in new investment. This would be financed in part by slashing Kodak’s dividend. Of particular concern to Carp was Carl Icahn, who had acquired 7% of Kodak’s stock. Icahn was not known for his patience or long-term horizons – he was famous for leading shareholder revolts and leveraged buyouts. His opposition to Carp’s strategy was based on skepticism over whether the massive investments in digital imaging would ever generate re- turns to shareholders. He viewed Kodak’s traditional photography business as a potential cash cow. If Kodak could radically cut costs, a sizable profit stream would be available to shareholders. The release of Kodak’s full-year results on January 22, 2004 lent weight to Carp’s critics: top-line growth was anemic while, on the bottom line, net income was down by almost two-thirds. Press commen- tary was mostly skeptical over Kodak’s future prospects. The Financial Times’ Lex column observed: ...Two key problems remain. -

European Semiconductor Industry Service (ESIS) Have Received This Data As a Loose-Leaf Service Section to Be Filed in Their Binder Set
DataQuest a company of MThe Dun & Bradstreet Corporation 7th April Dear Client, NEW FORMAT—MARKET SHARE DATA Dataquest's Eviropean Components Group completed preliminary 1988 European semiconductor market share estimates, which are enclosed herein. In the past, clients of the European Semiconductor Industry Service (ESIS) have received this data as a loose-leaf service section to be filed in their binder set. For your convenience we are now publishing this data in the form of a booklet. This booklet can still be filed as before, but offers much greater ease of use "on the move". We have also presented the market share estimates in a ranked format, rather than in alphabetical format, for your ease in comparing of vendors' market positions in different products and technologies. The previous year's rank is also shown for reference. Extra analysis is given, such as percentage market share for each vendor, for further ease in interpreting the estimates. We hope this helps make our estimates more usefuL to you. We would be interested in your comments regarding this new format. Yours sincerely %Y^^ • Bypon Harding Research Analyst European Components Group. 1290 Ridder Park Drive, San Jose, CA 95131-2398 (408) 437-8000 Telex 171973 Fax (408) 437-0292 European Semiconductor Industry Service Volume III—Companies E)ataQuest nn acompanyof IISI TheDun&Biadstreetcorporation 12^ Ridder Park Drive San Jose, California 95131-2398 (408) 437-8000 Telex: 171973 I^: (408) 437-0292 Sales/Service Offices: UNITED KINGDOM FRANCE EASTERN U.S. Dataquest Europe Limited Dataquest Europe SA Dataquest Boston Roussel House, Tour Gallieni 2 1740 Massachusetts Ave. -

(12) United States Patent (10) Patent No.: US 9.224,145 B1 Evans Et Al
USOO9224145B1 (12) United States Patent (10) Patent No.: US 9.224,145 B1 Evans et al. (45) Date of Patent: Dec. 29, 2015 (54) VENUE BASED DIGITAL RIGHTS USING 34: A 1 t 3. E. CAPTURE DEVICE WITH DGITAL 4,017,680W . A 4, 1977 AndersonUZaWa et al. WATERMARKING CAPABILITY 4,057,830 A 1 1/1977 Adcock 4,081,752 A 3, 1978 Sumi (75) Inventors: Gregory Morgan Evans, Raleigh, NC 4,125,111 A 1 1/1978 Hudspeth et al. (US); James Evans, Apex, NC (US); 4,131,919 A 12/1978 Lloyd et al. Thomas Roberts, Fuquay-Varina, NC (Continued) (US) FOREIGN PATENT DOCUMENTS (73) Assignee: Qurio Holdings, Inc., Raleigh, NC (US) AD 8-223524. A 8, 1996 (*) Notice: Subject to any disclaimer, the term of this DE 3518887 C1 9, 1986 patent is extended or adjusted under 35 (Continued) U.S.C. 154(b) by 1394 days. OTHER PUBLICATIONS (21) Appl. No.: 11/512,575 “Kodak DC220/260 Camera Twain Acquire Module.” Eastman 22) Filed: Aug. 30, 2006 Kodak Company, 1998, 4 pages. (22) Filed: ug. 5U, (Continued) (51) Int. Cl. G06F2L/00 (2006.01) Primary Examiner — Charles C Agwumezie H04N 7/2 (2006.01) (74) Attorney, Agent, or Firm — Withrow & Terranova, G06K 9/00 (2006.01) PLLC G06O20/40 (2012.01) (52) U.S. Cl. (57) ABSTRACT CPC .................................. G06O20/4014 (2013.01) A system for tracking copyright compliance comprises a (58) Field of Classification Search database, the database including unique identifiers for a plu CPC .................................................. G06Q2220/18 rality of content capture devices. The unique identifiers may USPC ............................................... -
WIPO LIST of NEUTRALS BIOGRAPHICAL DATA Matthew D. POWERS Tensegrity Law Group LLP Redwood Shores, CA United States of America N
ARBITRATION AND MEDIATION CENTER WIPO LIST OF NEUTRALS BIOGRAPHICAL DATA Matthew D. POWERS Tensegrity Law Group LLP Redwood Shores, CA United States of America Nationality: American EDUCATIONAL AND PROFESSIONAL QUALIFICATIONS J.D., Harvard Law School, 1982; B.S., Northwestern University, 1979. Admitted to practice law: - United States Supreme Court; - Federal, Second, Fifth, Seventh, and Ninth Circuits; - Court of International Trade; - Northern, Eastern, Central and Southern Districts of California; - Southern District of Texas; - Northern District of Indiana; - District of Arizona; - State of California. PRESENT POSITION Managing Partner, Tensegrity Law Group LLP; Member of the Firm’s Management Committee; Also teaches a patent litigation course at the University of California, Berkeley’s Boalt Hall School of Law, and has lectured on patent law at Stanford University and Santa Clara University. January 13, 2020 34, chemin des Colombettes, 1211 Geneva 20, Switzerland T +41 22 338 82 47 F +41 22 740 37 00 E [email protected] W www.wipo.int/amc 2 WIPO Profile – M. POWERS MEMBERSHIP IN PROFESSIONAL BODIES Organizations: - ICC Commission on Intellectual and Industrial Property; - American Intellectual Property Law Association (AIPLA); - International Bar Association; - United States Council for International Business; - American Bar Association (ABA), Intellectual Property, International and Litigation Sections; - Bay Area Inn of Court (Intellectual Property); Committee and Professional Positions: - Advisory Board, Institute for Transnational Arbitration; - Co-Editor in Chief, Journal of Proprietary Rights; - Editorial Board, The Trademark Reporter; - Editorial Board, International Litigation Quarterly; - Editorial Board, Mealey's Litigation Reports: Intellectual Property; - Executive Committee, Orientation in USA Law Program, University of California. AREAS OF SPECIALIZATION Intellectual property litigation, antitrust/trade regulation, product liability, and counseling. -

Information Productivity™ Rankings by Country
Strassmann, Inc. Global Information PRoductivity™ Rankings © Copyright 1996, All Rights Reserved Companies Total Revenues Weighted Country in Database (US$000) Average IP™ ARGENTINA 3 881,675 -0.751 AUSTRALIA 20 25,393,032 -0.119 AUSTRIA 11 12,234,878 -0.042 BELGIUM 23 17,921,628 -0.128 BRAZIL 33 60,641,605 -0.346 CANADA 311 265,364,969 -0.367 CHILE 15 8,009,723 0.017 COLOMBIA 6 1,662,989 -0.219 DENMARK 78 45,369,476 -0.159 FINLAND 57 58,337,766 0.078 FRANCE 124 511,606,973 -0.145 GERMANY 123 650,231,734 -0.036 GREECE 1 9 2,977,286 -0.606 HONG KONG 6 6,149,926 -2.658 INDIA 1 168,241 0.251 IRELAND 48 20,526,573 0.077 ITALY 161 346,779,093 -0.214 JAPAN 1,767 5,233,053,608 -0.170 KOREA (SOUTH) 41 113,933,255 -0.120 LUXEMBOURG 3 6,507,677 -0.060 MALAYSIA 2 1,158,941 0.679 MEXICO 30 28,921,380 -0.619 NETHERLANDS 78 321,808,668 0.066 NEW ZEALAND 6 5,704,196 1.097 NORWAY 65 28,838,430 0.042 PAKISTAN 2 44,402 0.302 PHILIPPINES 1 128,325 -0.325 PORTUGAL 3 301,723 1.671 SINGAPORE 1 1,388,783 -0.188 SOUTH AFRICA 9 18,655,473 0.032 SPAIN 4 3,031,222 -1.152 SWEDEN 24 75,540,278 0.117 SWITZERLAND 108 244,267,380 -0.689 TAIWAN 1 2,472,902 -0.651 THAILAND 14 2,924,239 0.292 UNITED KINGDOM 1,178 1,032,147,384 -0.032 UNITED STATES 2,959 4,839,398,019 0.077 7,335 13,994,483,852 IP Ranking within Country Overall Rank 1994 1994 IP Rank Company Name Within Country Revenues ($000) IP™ ARGENTINA 3770 ASTRA COMPANIA ARGENTINA DE PE 1 304,211 -0.127 5711 GAROVAGLIO Y ZORRAQUIN S.A.