On Poisson-Exponential-Tweedie Models for Ultra-Overdispersed Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Regression-Based Imputation of Explanatory Discrete Missing Data
Regression-based imputation of explanatory discrete missing data G. Hern´andez-Herrera1,2, A. Navarro1, and D. Mori˜na∗3,4 1Research Group on Psychosocial Risks, Organization of Work and Health (POWAH), Unitat de Bioestad´ıstica, Facultat de Medicina, Universitat Aut`onoma de Barcelona 2Instituto de Investigaciones M´edicas, Facultad de Medicina, Universidad de Antioquia 3Barcelona Graduate School of Mathematics (BGSMath), Departament de Matem`atiques, Universitat Aut`onoma de Barcelona 4Department of Econometrics, Statistics and Applied Economics, Riskcenter-IREA, Universitat de Barcelona (UB) Abstract Imputation of missing values is a strategy for handling non-responses in surveys or data loss in measurement processes, which may be more effective than ignoring the losses. When the variable represents a arXiv:2007.15031v1 [stat.AP] 29 Jul 2020 count, the literature dealing with this issue is scarce. If the vari- able has an excess of zeros it is necessary to consider models includ- ing parameters for handling zero-inflation. Likewise, if problems of over- or under-dispersion are observed, generalisations of the Pois- son, such as the Hermite or Conway-Maxwell Poisson distributions are recommended for carrying out imputation. In order to assess the performance of various regression models in the imputation of a dis- crete variable based on Poisson generalisations, compared to classical ∗Corresponding Author: David Mori˜na ([email protected]) 1 counting models, this work presents a comprehensive simulation study considering a variety of scenarios and real data from a lung cancer study. To do so we compared the results of estimations using only complete data, and using imputations based on the Poisson, negative binomial, Hermite, and COMPoisson distributions, and the ZIP and ZINB models for excesses of zeros. -

An Introduction to Poisson Regression Russ Lavery, K&L Consulting Services, King of Prussia, PA, U.S.A
NESUG 2010 Statistics and Analysis An Animated Guide: An Introduction To Poisson Regression Russ Lavery, K&L Consulting Services, King of Prussia, PA, U.S.A. ABSTRACT: This paper will be a brief introduction to Poisson regression (theory, steps to be followed, complications and interpretation) via a worked example. It is hoped that this will increase motivation towards learning this useful statistical technique. INTRODUCTION: Poisson regression is available in SAS through the GENMOD procedure (generalized modeling). It is appropriate when: 1) the process that generates the conditional Y distributions would, theoretically, be expected to be a Poisson random process and 2) when there is no evidence of overdispersion and 3) when the mean of the marginal distribution is less than ten (preferably less than five and ideally close to one). THE POISSON DISTRIBUTION: The Poison distribution is a discrete Percent of observations where the random variable X is expected distribution and is appropriate for to have the value x, given that the Poisson distribution has a mean modeling counts of observations. of λ= P(X=x, λ ) = (e - λ * λ X) / X! Counts are observed cases, like the 0.4 count of measles cases in cities. You λ can simply model counts if all data 0.35 were collected in the same measuring 0.3 unit (e.g. the same number of days or 0.3 0.5 0.8 same number of square feet). 0.25 λ 1 0.2 3 You can use the Poisson Distribution = 5 for modeling rates (rates are counts 0.15 20 per unit) if the units of collection were 8 different. -

Overdispersion, and How to Deal with It in R and JAGS (Requires R-Packages AER, Coda, Lme4, R2jags, Dharma/Devtools) Carsten F
Overdispersion, and how to deal with it in R and JAGS (requires R-packages AER, coda, lme4, R2jags, DHARMa/devtools) Carsten F. Dormann 07 December, 2016 Contents 1 Introduction: what is overdispersion? 1 2 Recognising (and testing for) overdispersion 1 3 “Fixing” overdispersion 5 3.1 Quasi-families . .5 3.2 Different distribution (here: negative binomial) . .6 3.3 Observation-level random effects (OLRE) . .8 4 Overdispersion in JAGS 12 1 Introduction: what is overdispersion? Overdispersion describes the observation that variation is higher than would be expected. Some distributions do not have a parameter to fit variability of the observation. For example, the normal distribution does that through the parameter σ (i.e. the standard deviation of the model), which is constant in a typical regression. In contrast, the Poisson distribution has no such parameter, and in fact the variance increases with the mean (i.e. the variance and the mean have the same value). In this latter case, for an expected value of E(y) = 5, we also expect that the variance of observed data points is 5. But what if it is not? What if the observed variance is much higher, i.e. if the data are overdispersed? (Note that it could also be lower, underdispersed. This is less often the case, and not all approaches below allow for modelling underdispersion, but some do.) Overdispersion arises in different ways, most commonly through “clumping”. Imagine the number of seedlings in a forest plot. Depending on the distance to the source tree, there may be many (hundreds) or none. The same goes for shooting stars: either the sky is empty, or littered with shooting stars. -

Poisson Versus Negative Binomial Regression
Handling Count Data The Negative Binomial Distribution Other Applications and Analysis in R References Poisson versus Negative Binomial Regression Randall Reese Utah State University [email protected] February 29, 2016 Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution Other Applications and Analysis in R References Overview 1 Handling Count Data ADEM Overdispersion 2 The Negative Binomial Distribution Foundations of Negative Binomial Distribution Basic Properties of the Negative Binomial Distribution Fitting the Negative Binomial Model 3 Other Applications and Analysis in R 4 References Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Count Data Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Count Data Data whose values come from Z≥0, the non-negative integers. Classic example is deaths in the Prussian army per year by horse kick (Bortkiewicz) Example 2 of Notes 5. (Number of successful \attempts"). Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Poisson Distribution Support is the non-negative integers. (Count data). Described by a single parameter λ > 0. When Y ∼ Poisson(λ), then E(Y ) = Var(Y ) = λ Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Acute Disseminated Encephalomyelitis Acute Disseminated Encephalomyelitis (ADEM) is a neurological, immune disorder in which widespread inflammation of the brain and spinal cord damages tissue known as white matter. -
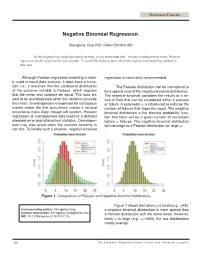
Negative Binomial Regression
STATISTICS COLUMN Negative Binomial Regression Shengping Yang PhD ,Gilbert Berdine MD In the hospital stay study discussed recently, it was mentioned that “in case overdispersion exists, Poisson regression model might not be appropriate.” I would like to know more about the appropriate modeling method in that case. Although Poisson regression modeling is wide- regression is commonly recommended. ly used in count data analysis, it does have a limita- tion, i.e., it assumes that the conditional distribution The Poisson distribution can be considered to of the outcome variable is Poisson, which requires be a special case of the negative binomial distribution. that the mean and variance be equal. The data are The negative binomial considers the results of a se- said to be overdispersed when the variance exceeds ries of trials that can be considered either a success the mean. Overdispersion is expected for contagious or failure. A parameter ψ is introduced to indicate the events where the first occurrence makes a second number of failures that stops the count. The negative occurrence more likely, though still random. Poisson binomial distribution is the discrete probability func- regression of overdispersed data leads to a deflated tion that there will be a given number of successes standard error and inflated test statistics. Overdisper- before ψ failures. The negative binomial distribution sion may also result when the success outcome is will converge to a Poisson distribution for large ψ. not rare. To handle such a situation, negative binomial 0 5 10 15 20 25 0 5 10 15 20 25 Figure 1. Comparison of Poisson and negative binomial distributions. -

Hermite Regression Analysis of Multi-Modal Count Data
Econometrics Working Paper EWP1001 ISSN 1485-6441 Department of Economics Hermite Regression Analysis of Multi-Modal Count Data David E. Giles* Department of Economics, University of Victoria Victoria, B.C., Canada V8W 2Y2 March, 2010 Abstract We discuss the modeling of count data whose em pirical distribution is both multi-modal and over- dispersed, and propose the Hermite distribution with covariates introduced through the conditional mean. The model is readily estimated by maximu m likelihood, and nests the Poisson model as a special case. The Hermite regression model is applied to data for the number of banking and currency crises in IMF-member countries, and is found to out-perform the Poisson and negative binomial models. Keywords: Count data, multi-modal data, over-dispersion, financial crises JEL Classifications: C16, C25, G15, G21 Author Contact: David E. Giles, Dept. of Economics, University of Victoria, P.O. Box 1700, STN CSC, Victoria, B.C., Canada V8W 2Y2; e-mail: [email protected]; Phone: (250) 721-8540; FAX: (250) 721-6214 1. Introduction Typically, models for count data (i.e., data that take only non-negative integer values) are based on distributions that do not allow for multi-modality. Obvious examples are the Poisson and negative binomial distributions. This seriously limits the usefulness of such models. We discuss a way of broadening the class of discrete distributions that are used in this field by adopting the Hermite distribution proposed by Kemp and Kemp (1965). Apart from Giles (2007), this distribution has not been used in the econometrics literature to date. Further, it appears that when it has been used in other fields, no consideration has been given to introducing covariates into the model, as is done with the conventional Poisson and negative binomial regression models. -

Generalized Linear Models
CHAPTER 6 Generalized linear models 6.1 Introduction Generalized linear modeling is a framework for statistical analysis that includes linear and logistic regression as special cases. Linear regression directly predicts continuous data y from a linear predictor Xβ = β0 + X1β1 + + Xkβk.Logistic regression predicts Pr(y =1)forbinarydatafromalinearpredictorwithaninverse-··· logit transformation. A generalized linear model involves: 1. A data vector y =(y1,...,yn) 2. Predictors X and coefficients β,formingalinearpredictorXβ 1 3. A link function g,yieldingavectoroftransformeddataˆy = g− (Xβ)thatare used to model the data 4. A data distribution, p(y yˆ) | 5. Possibly other parameters, such as variances, overdispersions, and cutpoints, involved in the predictors, link function, and data distribution. The options in a generalized linear model are the transformation g and the data distribution p. In linear regression,thetransformationistheidentity(thatis,g(u) u)and • the data distribution is normal, with standard deviation σ estimated from≡ data. 1 1 In logistic regression,thetransformationistheinverse-logit,g− (u)=logit− (u) • (see Figure 5.2a on page 80) and the data distribution is defined by the proba- bility for binary data: Pr(y =1)=y ˆ. This chapter discusses several other classes of generalized linear model, which we list here for convenience: The Poisson model (Section 6.2) is used for count data; that is, where each • data point yi can equal 0, 1, 2, ....Theusualtransformationg used here is the logarithmic, so that g(u)=exp(u)transformsacontinuouslinearpredictorXiβ to a positivey ˆi.ThedatadistributionisPoisson. It is usually a good idea to add a parameter to this model to capture overdis- persion,thatis,variationinthedatabeyondwhatwouldbepredictedfromthe Poisson distribution alone. -

Modeling of Pdfs of Non-Gaussian Data and Application to Wind Pressure Coefficients on Low-Rise Building
MODELING OF PDFS OF NON-GAUSSIAN DATA AND APPLICATION TO WIND PRESSURE COEFFICIENTS ON LOW-RISE BUILDING By LUPING YANG A THESIS PRESENTED TO THE GRADUATE SCHOOL OF THE UNIVERSITY OF FLORIDA IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF MASTER OF SCIENCE UNIVERSITY OF FLORIDA 2011 1 © 2011 Luping Yang 2 To my parents Qingcheng Yang and Chaoqun Pang 3 ACKNOWLEDGMENTS First of all, I wish to express my gratitude to my committee chair David O. Prevatt. This work would not have been accomplished without his patient guidance, continual support and great encouragement. I am also grateful to my co-chair and research advisor Dr. Kurtis R. Gurley. Working with Dr. Gurley has been a great pleasure for me. His insightful knowledge and amiable smile always gives me inspiration and encouragement when I encounter difficulties. His guidance to me has not only been limited to study and research but also extended to the way of thinking, the manner of interacting with people and the attitude of life. I wish to express my sincere gratitude to Dr. Sergei V. Shabanov in the Mathematical department for serving on my advisory committee. I would like to thank my family, Mr. and Mrs. Yang and my brother Wei Yang, for all their love, care and support. They have made me feel happy and have given me faith to study from thousands of miles away. Lastly, I wish to express my gratitude to my friends, colleagues and the hurricane research group at the University of Florida. Studying and working at UF has been a valuable and pleasant experience in my life. -

Modeling Overdispersion with the Normalized Tempered Stable Distribution
Modeling overdispersion with the normalized tempered stable distribution M. Kolossiatisa, J.E. Griffinb, M. F. J. Steel∗,c aDepartment of Hotel and Tourism Management, Cyprus University of Technology, P.O. Box 50329, 3603 Limassol, Cyprus. bInstitute of Mathematics, Statistics and Actuarial Science, University of Kent, Canterbury, CT2 7NF, U.K. cDepartment of Statistics, University of Warwick, Coventry, CV4 7AL, U.K. Abstract A multivariate distribution which generalizes the Dirichlet distribution is intro- duced and its use for modeling overdispersion in count data is discussed. The distribution is constructed by normalizing a vector of independent tempered sta- ble random variables. General formulae for all moments and cross-moments of the distribution are derived and they are found to have similar forms to those for the Dirichlet distribution. The univariate version of the distribution can be used as a mixing distribution for the success probability of a binomial distribution to define an alternative to the well-studied beta-binomial distribution. Examples of fitting this model to simulated and real data are presented. Keywords: Distribution on the unit simplex; Mice fetal mortality; Mixed bino- mial; Normalized random measure; Overdispersion 1. Introduction In many experiments we observe data as the number of observations in a sam- ple with some property. The binomial distribution is a natural model for this type of data. However, the data are often found to be overdispersed relative to that ∗Corresponding author. Tel.: +44-2476-523369; fax: +44-2476-524532 Email addresses: [email protected] (M. Kolossiatis), [email protected] (J.E. Griffin), [email protected] (M. -

A Comparison Between Approximations of Option Pricing Models and Risk-Neutral Densities Using Hermite Polynomials
U.U.D.M. Project Report 2020:16 A Comparison between Approximations of Option Pricing Models and Risk-Neutral Densities using Hermite Polynomials Nathaniel Ahy Examensarbete i matematik, 30 hp Handledare: Benny Avelin Examinator: Erik Ekström Juni 2020 Department of Mathematics Uppsala University Contents 1 Introduction 1 1.1 Background of Hermite Polynomials . .1 1.2 Financial Derivatives and Stochastic Volatility . .2 1.3 Hermite Polynomials in Finance . .5 1.4 Problem Formulation . .7 1.5 Methodology . .7 1.6 Outline . .8 2 Theory 10 2.1 Heston Model . 10 2.1.1 The Fundamental Theorem of Finance . 11 2.2 Gram-Charlier Expansions . 13 2.2.1 Cumulants and an Explicit Formula for Computing them 13 2.2.2 Gram–Charlier Expansions for the Heston Model . 14 2.3 Gram-Charlier Expansion Option Pricing Formula . 14 2.4 Necula, Drimus and Farkas Risk-Neutral Measure . 15 2.4.1 A closed form formula for the coefficients for the risk- neutral density . 17 2.4.2 Implementation of Closed Form Formula . 19 3 Option Pricing 21 3.1 Estimating Coefficients through quadratic programming . 21 3.1.1 The Active Set Algorithm . 25 3.2 Fitting the NDF log mean and standard deviation to a Model 27 4 Model Fitting Results 28 4.1 Computing the Cumulants . 28 4.2 Model Errors . 29 2 Uppsala University 5 Option Data 33 5.1 Fitting the GC Parameters to the Data . 33 6 Data Fitting Results 36 6.1 NDF Errors . 36 6.2 GC errors . 40 6.3 Model Complexity . 43 7 Conclusion 45 7.1 Conclusion . -

Variance Partitioning in Multilevel Logistic Models That Exhibit Overdispersion
J. R. Statist. Soc. A (2005) 168, Part 3, pp. 599–613 Variance partitioning in multilevel logistic models that exhibit overdispersion W. J. Browne, University of Nottingham, UK S. V. Subramanian, Harvard School of Public Health, Boston, USA K. Jones University of Bristol, UK and H. Goldstein Institute of Education, London, UK [Received July 2002. Final revision September 2004] Summary. A common application of multilevel models is to apportion the variance in the response according to the different levels of the data.Whereas partitioning variances is straight- forward in models with a continuous response variable with a normal error distribution at each level, the extension of this partitioning to models with binary responses or to proportions or counts is less obvious. We describe methodology due to Goldstein and co-workers for appor- tioning variance that is attributable to higher levels in multilevel binomial logistic models. This partitioning they referred to as the variance partition coefficient. We consider extending the vari- ance partition coefficient concept to data sets when the response is a proportion and where the binomial assumption may not be appropriate owing to overdispersion in the response variable. Using the literacy data from the 1991 Indian census we estimate simple and complex variance partition coefficients at multiple levels of geography in models with significant overdispersion and thereby establish the relative importance of different geographic levels that influence edu- cational disparities in India. Keywords: Contextual variation; Illiteracy; India; Multilevel modelling; Multiple spatial levels; Overdispersion; Variance partition coefficient 1. Introduction Multilevel regression models (Goldstein, 2003; Bryk and Raudenbush, 1992) are increasingly being applied in many areas of quantitative research. -

Multivariate Limit Theorems in the Context of Long-Range Dependence
Multivariate limit theorems in the context of long-range dependence Shuyang Bai Murad S. Taqqu September 4, 2018 Abstract We study the limit law of a vector made up of normalized sums of functions of long-range depen- dent stationary Gaussian series. Depending on the memory parameter of the Gaussian series and on the Hermite ranks of the functions, the resulting limit law may be (a) a multivariate Gaussian process involv- ing dependent Brownian motion marginals, or (b) a multivariate process involving dependent Hermite processes as marginals, or (c) a combination. We treat cases (a), (b) in general and case (c) when the Hermite components involve ranks 1 and 2. We include a conjecture about case (c) when the Hermite ranks are arbitrary. 1 Introduction A stationary time series displays long-range dependence if its auto-covariance decays slowly or if its spectral density diverges around the zero frequency. When there is long-range dependence, the asymptotic limits of various estimators are often either Brownian Motion or a Hermite process. The most common Hermite processes are fractional Brownian motion (Hermite process of order 1) and the Rosenblatt process (Hermite process of order 2), but there are Hermite processes of any order. Fractional Brownian motion is the only Gaussian Hermite process. Most existing limit theorems involve univariate convergence, that is, convergence to a single limit process, for example, Brownian motion or a Hermite process ([3, 5, 24]). In time series analysis, however, one often needs joint convergence, that is, convergence to a vector of processes. This is because one often needs to consider different statistics of the process jointly.