Measuring Software Quality
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Command Line Interface
Command Line Interface Squore 21.0.2 Last updated 2021-08-19 Table of Contents Preface. 1 Foreword. 1 Licence. 1 Warranty . 1 Responsabilities . 2 Contacting Vector Informatik GmbH Product Support. 2 Getting the Latest Version of this Manual . 2 1. Introduction . 3 2. Installing Squore Agent . 4 Prerequisites . 4 Download . 4 Upgrade . 4 Uninstall . 5 3. Using Squore Agent . 6 Command Line Structure . 6 Command Line Reference . 6 Squore Agent Options. 6 Project Build Parameters . 7 Exit Codes. 13 4. Managing Credentials . 14 Saving Credentials . 14 Encrypting Credentials . 15 Migrating Old Credentials Format . 16 5. Advanced Configuration . 17 Defining Server Dependencies . 17 Adding config.xml File . 17 Using Java System Properties. 18 Setting up HTTPS . 18 Appendix A: Repository Connectors . 19 ClearCase . 19 CVS . 19 Folder Path . 20 Folder (use GNATHub). 21 Git. 21 Perforce . 23 PTC Integrity . 25 SVN . 26 Synergy. 28 TFS . 30 Zip Upload . 32 Using Multiple Nodes . 32 Appendix B: Data Providers . 34 AntiC . 34 Automotive Coverage Import . 34 Automotive Tag Import. 35 Axivion. 35 BullseyeCoverage Code Coverage Analyzer. 36 CANoe. 36 Cantata . 38 CheckStyle. .. -

Coverity Static Analysis
Coverity Static Analysis Quickly find and fix Overview critical security and Coverity® gives you the speed, ease of use, accuracy, industry standards compliance, and quality issues as you scalability that you need to develop high-quality, secure applications. Coverity identifies code critical software quality defects and security vulnerabilities in code as it’s written, early in the development process when it’s least costly and easiest to fix. Precise actionable remediation advice and context-specific eLearning help your developers understand how to fix their prioritized issues quickly, without having to become security experts. Coverity Benefits seamlessly integrates automated security testing into your CI/CD pipelines and supports your existing development tools and workflows. Choose where and how to do your • Get improved visibility into development: on-premises or in the cloud with the Polaris Software Integrity Platform™ security risk. Cross-product (SaaS), a highly scalable, cloud-based application security platform. Coverity supports 22 reporting provides a holistic, more languages and over 70 frameworks and templates. complete view of a project’s risk using best-in-class AppSec tools. Coverity includes Rapid Scan, a fast, lightweight static analysis engine optimized • Deployment flexibility. You for cloud-native applications and Infrastructure-as-Code (IaC). Rapid Scan runs decide which set of projects to do automatically, without additional configuration, with every Coverity scan and can also AppSec testing for: on-premises be run as part of full CI builds with conventional scan completion times. Rapid Scan can or in the cloud. also be deployed as a standalone scan engine in Code Sight™ or via the command line • Shift security testing left. -

A Comparison of SPARK with MISRA C and Frama-C
A Comparison of SPARK with MISRA C and Frama-C Johannes Kanig, AdaCore October 2018 Abstract Both SPARK and MISRA C are programming languages intended for high-assurance applications, i.e., systems where reliability is critical and safety and/or security requirements must be met. This document summarizes the two languages, compares them with respect to how they help satisfy high-assurance requirements, and compares the SPARK technology to several static analysis tools available for MISRA C with a focus on Frama-C. 1 Introduction 1.1 SPARK Overview Ada [1] is a general-purpose programming language that has been specifically designed for safe and secure programming. Information on how Ada satisfies the requirements for high-assurance software, including the avoidance of vulnerabilities that are found in other languages, may be found in [2, 3, 4]. SPARK [5, 6] is an Ada subset that is amenable to formal analysis and thus can bring increased confidence to software requiring the highest levels of assurance. SPARK excludes features that are difficult to analyze (such as pointers and exception handling). Its restrictions guarantee the absence of unspecified behavior such as reading the value of an uninitialized variable, or depending on the evaluation order of expressions with side effects. But SPARK does include major Ada features such as generic templates and object-oriented programming, as well as a simple but expressive set of concurrency (tasking) features known as the Ravenscar profile. SPARK has been used in a variety of high-assurance applications, including hypervisor kernels, air traffic management, and aircraft avionics. In fact, SPARK is more than just a subset of Ada. -
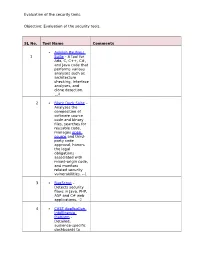
Evaluation of the Security Tools. SL No. Tool Name Comments 1
Evaluation of the security tools. Objective: Evaluation of the security tools. SL No. Tool Name Comments Axivion Bauhaus 1 Suite – A tool for Ada, C, C++, C#, and Java code that performs various analyses such as architecture checking, interface analyses, and clone detection. 4 2 Black Duck Suite – Analyzes the composition of software source code and binary files, searches for reusable code, manages open source and third- party code approval, honors the legal obligations associated with mixed-origin code, and monitors related security vulnerabilities. --1 3 BugScout – Detects security flaws in Java, PHP, ASP and C# web applications. -2 4 CAST Application Intelligence Platform – Detailed, audience-specific dashboards to Evaluation of the security tools. measure quality and productivity. 30+ languages, C, C++, Java, .NET, Oracle, PeopleSoft, SAP, Siebel, Spring, Struts, Hibernate and all major databases. 5 ChecKing – Integrated software quality portal that helps manage the quality of all phases of software development. It includes static code analyzers for Java, JSP, Javascript, HTML, XML, .NET (C#, ASP.NET, VB.NET, etc.), PL/SQL, embedded SQL, SAP ABAP IV, Natural/Adabas, C, C++, Cobol, JCL, and PowerBuilder. 6 ConQAT – Continuous quality assessment toolkit that allows flexible configuration of quality analyses (architecture conformance, clone detection, quality metrics, etc.) and dashboards. Supports Java, C#, C++, JavaScript, ABAP, Ada and many other languages. Evaluation of the security tools. 7 Coverity SAVE – A static code analysis tool for C, C++, C# and Java source code. Coverity commercialized a research tool for finding bugs through static analysis, the Stanford Checker, which used abstract interpretation to identify defects in source code. -

As Focused on Software Tools That Support Software Engineering, Along with Data Structures and Algorithms Generally
PETER C DILLINGER, Ph.D. 2110 N 89th St [email protected] Seattle WA 98103 http://www.peterd.org 404-509-4879 Overview My work in software has focused on software tools that support software engineering, along with data structures and algorithms generally. My core strength is seeing many paths to “success,” so I'm often the person consulted when others think they're stuck. Highlights ♦ Key developer and project lead in adapting and extending the legendary Coverity static analysis engine, for C/C++ bug finding, to find bugs with high accuracy in Java, C#, JavaScript, PHP, Python, Ruby, Swift, and VB. https://www.synopsys.com/blogs/software-security/author/pdillinger/ ♦ Inventor of a fast, scalable, and accurate method of detecting mistyped identifiers in dynamic languages such as JavaScript, PHP, Python, and Ruby without use of a natural language dictionary. Patent pending, app# 20170329697. Coverity feature: https://stackoverflow.com/a/34796105 ♦ Did the impossible with git: on wanting to “copy with history” as part of a refactoring, I quickly developed a way to do it despite the consensus wisdom. https://stackoverflow.com/a/44036771 ♦ Did the impossible with Bloom filters: made the data structure simultaneously fast and accurate with a simple hashing technique, now used in tools including LevelDB and RocksDB. https://en.wikipedia.org/wiki/Bloom_filter (Search "Dillinger") ♦ Early coder / Linux user: started BASIC in 1st grade; first game hack in 3rd grade; learned C in middle school; wrote Tetris in JavaScript in high school (1997); steady Linux user since 1998. Work Coverity, August 2009 to October 2017, acquired by Synopsys in 2014 Software developer, tech lead, and manager for static and dynamic program analysis projects. -

Coverity Support for SEI CERT C, C++, and Java Coding Standards
Coverity Support for SEI CERT C, C++, and Java Coding Standards Ensure the safety, The SEI CERT C, C++, and Oracle Java Coding Standards are lists of rules and reliability, and security recommendations for writing secure code in the C, C++, and Java programming languages They represent an important milestone in introducing best practices for of software written in C, ensuring the safety, reliability, security, and integrity of software written in C/C++ and C++, and Java Java Notably, the standards are designed to be enforceable by software code analyzers using static analysis techniques This greatly reduces the cost of compliance by way of automation Adhering to coding standards is a crucial step in establishing best coding practices Standards adherence is particularly important in safety-critical, high-impact industries, such as automotive, medical, and networking Software defects in products coming from these industries manifest themselves physically and tangibly—often with life- threatening consequences Synopsys provides a comprehensive solution for the SEI CERT C/C++ Coding Standards rules, along with high-impact SEI CERT Oracle Java Coding Standards (online version) rules and SEI CERT C Coding Standard recommendations (online version) Coverity static analysis implements the Rules category within the CERT C/ C++ standards, high-impact CERT Java L1 rules, and methods for managing violations and reporting on them Coverity also supports some of the best practices from the Recommendations category for the CERT C standard Acknowledgement -

SATE V Report: Ten Years of Static Analysis Tool Expositions
NIST Special Publication 500-326 SATE V Report: Ten Years of Static Analysis Tool Expositions Aurelien Delaitre Bertrand Stivalet Paul E. Black Vadim Okun Athos Ribeiro Terry S. Cohen This publication is available free of charge from: https://doi.org/10.6028/NIST.SP.500-326 NIST Special Publication 500-326 SATE V Report: Ten Years of Static Analysis Tool Expositions Aurelien Delaitre Prometheus Computing LLC Bertrand Stivalet Paul E. Black Vadim Okun Athos Ribeiro Terry S. Cohen Information Technology Laboratory Software and Systems Division This publication is available free of charge from: https://doi.org/10.6028/NIST.SP.500-326 October 2018 U.S. Department of Commerce Wilbur L. Ross, Jr., Secretary National Institute of Standards and Technology Walter Copan, NIST Director and Under Secretary of Commerce for Standards and Technology Certain commercial entities, equipment, or materials may be identified in this document in order to describe an experimental procedure or concept adequately. Such identification is not intended to imply recommendation or endorsement by the National Institute of Standards and Technology, nor is it intended to imply that the entities, materials, or equipment are necessarily the best available for the purpose. National Institute of Standards and Technology Special Publication 500-326 Natl. Inst. Stand. Technol. Spec. Publ. 500-326, 180 pages (October 2018) CODEN: NSPUE2 This publication is available free of charge from: https://doi.org/10.6028/NIST.SP.500-326 Abstract Software assurance has been the focus of the National Institute of Standards and Technology (NIST) Software Assurance Metrics and Tool Evaluation (SAMATE) team for many years. -

D3.4 – Language-Specific Source Code Quality Analysis
Project Number 318772 D3.4 – Language-Specific Source Code Quality Analysis Version 1.0 30 October 2014 Final Public Distribution Centrum Wiskunde & Informatica Project Partners: Centrum Wiskunde & Informatica, SOFTEAM, Tecnalia Research and Innovation, The Open Group, University of L0Aquila, UNINOVA, University of Manchester, University of York, Unparallel Innovation Every effort has been made to ensure that all statements and information contained herein are accurate, however the OSSMETER Project Partners accept no liability for any error or omission in the same. © 2014 Copyright in this document remains vested in the OSSMETER Project Partners. D3.4 – Language-Specific Source Code Quality Analysis Project Partner Contact Information Centrum Wiskunde & Informatica SOFTEAM Jurgen Vinju Alessandra Bagnato Science Park 123 Avenue Victor Hugo 21 1098 XG Amsterdam, Netherlands 75016 Paris, France Tel: +31 20 592 4102 Tel: +33 1 30 12 16 60 E-mail: [email protected] E-mail: [email protected] Tecnalia Research and Innovation The Open Group Jason Mansell Scott Hansen Parque Tecnologico de Bizkaia 202 Avenue du Parc de Woluwe 56 48170 Zamudio, Spain 1160 Brussels, Belgium Tel: +34 946 440 400 Tel: +32 2 675 1136 E-mail: [email protected] E-mail: [email protected] University of L0Aquila UNINOVA Davide Di Ruscio Pedro Maló Piazza Vincenzo Rivera 1 Campus da FCT/UNL, Monte de Caparica 67100 L’Aquila, Italy 2829-516 Caparica, Portugal Tel: +39 0862 433735 Tel: +351 212 947883 E-mail: [email protected] E-mail: [email protected] -

Static Analysis of Your OSS Project with Coverity
Static Analysis of Your OSS Project with Coverity LinuxCon EU 2015 Stefan Schmidt Samsung Open Source Group [email protected] Samsung Open Source Group 1 Agenda ● Introduction ● Survey of Available Analysers ● Coverity Scan Service ● Hooking it Up in Your Project ● Fine Tuning ● Work Flows & Examples ● Summary Samsung Open Source Group 2 Introduction Samsung Open Source Group 3 Static Analysers ● What is Static Analysis? – Analysis of the soure code without execution – Usage of algorithms and techniques to find bugs in source code ● What is it not? – A formal verification of your code – A proof that your code is bug free ● Why is it useful for us? – Allows to find many types of defects early in the development process – Resource leaks, NULL pointer dereferences, memory corruptions, buffer overflows, etc. – Supplements things like unit testing, runtime testing, Valgrind, etc. Samsung Open Source Group 4 Survey of Available Analysers Samsung Open Source Group 5 Static Analysers ● Sparse ● Clang Static Analyzer ● CodeChecker based on Clang Static Analyzer ● Klocwork (proprietary) ● Coverity (proprietary, free as in beer service for OSS projects) ● A list with more analysers can be found at [1] ● My personal experience started with – Clang Static Analyzer – Klocwork used internally (not allowed to share results) – finally settled for Coverity Scan service Samsung Open Source Group 6 Sparse ● Started 2003 by Linus Torvalds ● Semantic parser with a static analysis backend ● Well integrated into the Kernel build system (make C=1/C=2) ● To integrate it with your project using the build wrapper might be enough: make CC=cgcc Samsung Open Source Group 7 Clang Static Analyzer ● Command line tool scan-build as build wrapper ● Generates a report as static HTML files ● The analyser itself is implemented as C++ library ● Also used from within XCode ● Scan build had many false positives for us and needs more manual tuning (e.g. -

Static Analysis Christian Kaestner
Foundations of Software Engineering Static analysis Christian Kaestner 1 Two fundamental concepts • Abstraction. – Elide details of a specific implementation. – Capture semantically relevant details; ignore the rest. • Programs as data. – Programs are just trees/graphs! – …and we know lots of ways to analyze trees/graphs, right? 2 Learning goals • Give a one sentence definition of static analysis. Explain what types of bugs static analysis targets. • Give an example of syntactic or structural static analysis. • Construct basic control flow graphs for small examples by hand. • Distinguish between control- and data-flow analyses; define and then step through on code examples simple control and data- flow analyses. • Implement a dataflow analysis. • Explain at a high level why static analyses cannot be sound, complete, and terminating; assess tradeoffs in analysis design. • Characterize and choose between tools that perform static analyses. 3 goto fail; 4 1. static OSStatus 2. SSLVerifySignedServerKeyExchange(SSLContext *ctx, bool isRsa, 3. SSLBuffer signedParams, 4. uint8_t *signature, 5. UInt16 signatureLen) { 6. OSStatus err; 7. .… 8. if ((err = SSLHashSHA1.update(&hashCtx, &serverRandom)) != 0) 9. goto fail; 10. if ((err = SSLHashSHA1.update(&hashCtx, &signedParams)) != 0) 11. goto fail; 12. goto fail; 13. if ((err = SSLHashSHA1.final(&hashCtx, &hashOut)) != 0) 14. goto fail; 15. … 16.fail: 17. SSLFreeBuffer(&signedHashes); 18. SSLFreeBuffer(&hashCtx); 19. return err; 20.} 5 1. /* from Linux 2.3.99 drivers/block/raid5.c */ 2. static struct buffer_head * 3. get_free_buffer(struct stripe_head * sh, 4. int b_size) { 5. struct buffer_head *bh; 6. unsigned long flags; ERROR: function returns with 7. save_flags(flags); interrupts disabled! 8. cli(); // disables interrupts 9. if ((bh = sh->buffer_pool) == NULL) 10. -

A Critical Comparison on Six Static Analysis Tools: Detection, Agreement, and Precision
Noname manuscript No. (will be inserted by the editor) A Critical Comparison on Six Static Analysis Tools: Detection, Agreement, and Precision Valentina Lenarduzzi · Savanna Lujan · Nyyti Saarim¨aki · Fabio Palomba Received: date / Accepted: date Abstract Background. Developers use Automated Static Analysis Tools (ASATs) to control for potential quality issues in source code, including de- fects and technical debt. Tool vendors have devised quite a number of tools, which makes it harder for practitioners to select the most suitable one for their needs. To better support developers, researchers have been conducting several studies on ASATs to favor the understanding of their actual capabilities. Aims. Despite the work done so far, there is still a lack of knowledge regarding (1) which source quality problems can actually be detected by static analysis tool warnings, (2) what is their agreement, and (3) what is the precision of their recommendations. We aim at bridging this gap by proposing a large-scale comparison of six popular static analysis tools for Java projects: Better Code Hub, CheckStyle, Coverity Scan, Findbugs, PMD, and SonarQube. Method. We analyze 47 Java projects and derive a taxonomy of warnings raised by 6 state-of-the-practice ASATs. To assess their agreement, we compared them by manually analyzing - at line-level - whether they identify the same issues. Finally, we manually evaluate the precision of the tools. Results. The key results report a comprehensive taxonomy of ASATs warnings, show little to no agreement among the tools and a low degree of precision. Conclusions. We provide a taxonomy that can be useful to researchers, practi- tioners, and tool vendors to map the current capabilities of the tools. -

Alignment Between OASIS SARIF and OMG TOIF Dr
Alignment between OASIS SARIF and OMG TOIF Dr. Nikolai Mansourov, CISSP KDM Analytics, OMG liaison to OASIS Abstract This white paper describes the alignment between OMG TOIF and OASIS SARIF and suggests a roadmap for the interoperability between the two specifications. The proposed roadmap includes further alignment of the core concepts, a generic adaptor from SARIF to TOIF, a standard converter from TOIF to SARIF, coordinated efforts towards common weakness measures in the context of SCA tools, using SARIF to capture existing tool-specific measures, using TOIF as the platform for developing common ranking tools, and using TOIF as a platform for common risk assessment tools. Disclaimer: the views expressed in this white paper do not necessarily reflect the views of the Object Management Group (OMG), or the OMG System Assurance Task Force, or any of the member organizations of the OMG. Background Software developers use a variety of analysis tools to assess the quality of their programs. These tools report results which can indicate problems related to program quality such as correctness, security, performance, conformance to contractual or legal requirements, conformance to stylistic standards, understandability, and maintainability. To form an overall picture of program quality, developers must often aggregate the results produced by more than one tool. This aggregation is more difficult if each tool produces output in a different format. One particularly important class of analysis tools is referred to as static code analysis tools (SCA). SCA tools help software developers manage cybersecurity risk of their software. They scan source or machine code of the system under assessment and generate the so-called weakness finding reports.