Simplifying the Analysis of C++ Programs
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Command Line Interface
Command Line Interface Squore 21.0.2 Last updated 2021-08-19 Table of Contents Preface. 1 Foreword. 1 Licence. 1 Warranty . 1 Responsabilities . 2 Contacting Vector Informatik GmbH Product Support. 2 Getting the Latest Version of this Manual . 2 1. Introduction . 3 2. Installing Squore Agent . 4 Prerequisites . 4 Download . 4 Upgrade . 4 Uninstall . 5 3. Using Squore Agent . 6 Command Line Structure . 6 Command Line Reference . 6 Squore Agent Options. 6 Project Build Parameters . 7 Exit Codes. 13 4. Managing Credentials . 14 Saving Credentials . 14 Encrypting Credentials . 15 Migrating Old Credentials Format . 16 5. Advanced Configuration . 17 Defining Server Dependencies . 17 Adding config.xml File . 17 Using Java System Properties. 18 Setting up HTTPS . 18 Appendix A: Repository Connectors . 19 ClearCase . 19 CVS . 19 Folder Path . 20 Folder (use GNATHub). 21 Git. 21 Perforce . 23 PTC Integrity . 25 SVN . 26 Synergy. 28 TFS . 30 Zip Upload . 32 Using Multiple Nodes . 32 Appendix B: Data Providers . 34 AntiC . 34 Automotive Coverage Import . 34 Automotive Tag Import. 35 Axivion. 35 BullseyeCoverage Code Coverage Analyzer. 36 CANoe. 36 Cantata . 38 CheckStyle. .. -

Safe, Fast and Easy: Towards Scalable Scripting Languages
Safe, Fast and Easy: Towards Scalable Scripting Languages by Pottayil Harisanker Menon A dissertation submitted to The Johns Hopkins University in conformity with the requirements for the degree of Doctor of Philosophy. Baltimore, Maryland Feb, 2017 ⃝c Pottayil Harisanker Menon 2017 All rights reserved Abstract Scripting languages are immensely popular in many domains. They are char- acterized by a number of features that make it easy to develop small applications quickly - flexible data structures, simple syntax and intuitive semantics. However they are less attractive at scale: scripting languages are harder to debug, difficult to refactor and suffers performance penalties. Many research projects have tackled the issue of safety and performance for existing scripting languages with mixed results: the considerable flexibility offered by their semantics also makes them significantly harder to analyze and optimize. Previous research from our lab has led to the design of a typed scripting language built specifically to be flexible without losing static analyzability. Inthis dissertation, we present a framework to exploit this analyzability, with the aim of producing a more efficient implementation Our approach centers around the concept of adaptive tags: specialized tags attached to values that represent how it is used in the current program. Our frame- work abstractly tracks the flow of deep structural types in the program, and thuscan ii ABSTRACT efficiently tag them at runtime. Adaptive tags allow us to tackle key issuesatthe heart of performance problems of scripting languages: the framework is capable of performing efficient dispatch in the presence of flexible structures. iii Acknowledgments At the very outset, I would like to express my gratitude and appreciation to my advisor Prof. -

Comparative Studies of Programming Languages; Course Lecture Notes
Comparative Studies of Programming Languages, COMP6411 Lecture Notes, Revision 1.9 Joey Paquet Serguei A. Mokhov (Eds.) August 5, 2010 arXiv:1007.2123v6 [cs.PL] 4 Aug 2010 2 Preface Lecture notes for the Comparative Studies of Programming Languages course, COMP6411, taught at the Department of Computer Science and Software Engineering, Faculty of Engineering and Computer Science, Concordia University, Montreal, QC, Canada. These notes include a compiled book of primarily related articles from the Wikipedia, the Free Encyclopedia [24], as well as Comparative Programming Languages book [7] and other resources, including our own. The original notes were compiled by Dr. Paquet [14] 3 4 Contents 1 Brief History and Genealogy of Programming Languages 7 1.1 Introduction . 7 1.1.1 Subreferences . 7 1.2 History . 7 1.2.1 Pre-computer era . 7 1.2.2 Subreferences . 8 1.2.3 Early computer era . 8 1.2.4 Subreferences . 8 1.2.5 Modern/Structured programming languages . 9 1.3 References . 19 2 Programming Paradigms 21 2.1 Introduction . 21 2.2 History . 21 2.2.1 Low-level: binary, assembly . 21 2.2.2 Procedural programming . 22 2.2.3 Object-oriented programming . 23 2.2.4 Declarative programming . 27 3 Program Evaluation 33 3.1 Program analysis and translation phases . 33 3.1.1 Front end . 33 3.1.2 Back end . 34 3.2 Compilation vs. interpretation . 34 3.2.1 Compilation . 34 3.2.2 Interpretation . 36 3.2.3 Subreferences . 37 3.3 Type System . 38 3.3.1 Type checking . 38 3.4 Memory management . -

Static Analyses for Stratego Programs
Static analyses for Stratego programs BSc project report June 30, 2011 Author name Vlad A. Vergu Author student number 1195549 Faculty Technical Informatics - ST track Company Delft Technical University Department Software Engineering Commission Ir. Bernard Sodoyer Dr. Eelco Visser 2 I Preface For the successful completion of their Bachelor of Science, students at the faculty of Computer Science of the Technical University of Delft are required to carry out a software engineering project. The present report is the conclusion of this Bachelor of Science project for the student Vlad A. Vergu. The project has been carried out within the Software Language Design and Engineering Group of the Computer Science faculty, under the direct supervision of Dr. Eelco Visser of the aforementioned department and Ir. Bernard Sodoyer. I would like to thank Dr. Eelco Visser for his past and ongoing involvment and support in my educational process and in particular for the many opportunities for interesting and challenging projects. I further want to thank Ir. Bernard Sodoyer for his support with this project and his patience with my sometimes unconvential way of working. Vlad Vergu Delft; June 30, 2011 II Summary Model driven software development is gaining momentum in the software engi- neering world. One approach to model driven software development is the design and development of domain-specific languages allowing programmers and users to spend more time on their core business and less on addressing non problem- specific issues. Language workbenches and support languages and compilers are necessary for supporting development of these domain-specific languages. One such workbench is the Spoofax Language Workbench. -

Fiendish Designs
Fiendish Designs A Software Engineering Odyssey © Tim Denvir 2011 1 Preface These are notes, incomplete but extensive, for a book which I hope will give a personal view of the first forty years or so of Software Engineering. Whether the book will ever see the light of day, I am not sure. These notes have come, I realise, to be a memoir of my working life in SE. I want to capture not only the evolution of the technical discipline which is software engineering, but also the climate of social practice in the industry, which has changed hugely over time. To what extent, if at all, others will find this interesting, I have very little idea. I mention other, real people by name here and there. If anyone prefers me not to refer to them, or wishes to offer corrections on any item, they can email me (see Contact on Home Page). Introduction Everybody today encounters computers. There are computers inside petrol pumps, in cash tills, behind the dashboard instruments in modern cars, and in libraries, doctors’ surgeries and beside the dentist’s chair. A large proportion of people have personal computers in their homes and may use them at work, without having to be specialists in computing. Most people have at least some idea that computers contain software, lists of instructions which drive the computer and enable it to perform different tasks. The term “software engineering” wasn’t coined until 1968, at a NATO-funded conference, but the activity that it stands for had been carried out for at least ten years before that. -

Blossom: a Language Built to Grow
Macalester College DigitalCommons@Macalester College Mathematics, Statistics, and Computer Science Honors Projects Mathematics, Statistics, and Computer Science 4-26-2016 Blossom: A Language Built to Grow Jeffrey Lyman Macalester College Follow this and additional works at: https://digitalcommons.macalester.edu/mathcs_honors Part of the Computer Sciences Commons, Mathematics Commons, and the Statistics and Probability Commons Recommended Citation Lyman, Jeffrey, "Blossom: A Language Built to Grow" (2016). Mathematics, Statistics, and Computer Science Honors Projects. 45. https://digitalcommons.macalester.edu/mathcs_honors/45 This Honors Project - Open Access is brought to you for free and open access by the Mathematics, Statistics, and Computer Science at DigitalCommons@Macalester College. It has been accepted for inclusion in Mathematics, Statistics, and Computer Science Honors Projects by an authorized administrator of DigitalCommons@Macalester College. For more information, please contact [email protected]. In Memory of Daniel Schanus Macalester College Department of Mathematics, Statistics, and Computer Science Blossom A Language Built to Grow Jeffrey Lyman April 26, 2016 Advisor Libby Shoop Readers Paul Cantrell, Brett Jackson, Libby Shoop Contents 1 Introduction 4 1.1 Blossom . .4 2 Theoretic Basis 6 2.1 The Potential of Types . .6 2.2 Type basics . .6 2.3 Subtyping . .7 2.4 Duck Typing . .8 2.5 Hindley Milner Typing . .9 2.6 Typeclasses . 10 2.7 Type Level Operators . 11 2.8 Dependent types . 11 2.9 Hoare Types . 12 2.10 Success Types . 13 2.11 Gradual Typing . 14 2.12 Synthesis . 14 3 Language Description 16 3.1 Design goals . 16 3.2 Type System . 17 3.3 Hello World . -

The Humble Humorous Researcher: a Tribute to Michel Sintzoff
The Humble Humorous Researcher A Tribute to Michel Sintzoff Axel van Lamsweerde 1 Many of us lost a close colleague on November 28, 2010. More than that: we lost a friend. One that we used to meet regularly, all over the world, always listening to us, making interesting comments and suggestions on our work, joking on every occasion and making us discover how much fun our business is. Rather than reviewing his work in detail, this note puts more focus on Michel’s rich personality, with the hope that it will bring back fond memories among those who were lucky enough to share some good times with him. The style is intended to be personal and informal. Michel would have hated anything different, to be sure. Born in 1938 in Brussels, Michel completed his master’s degree in Mathematics at the Université catholique de Louvain (UCL) in 1962. After two years of civil service as a maths teacher in Katanga (Congo), he entered the MBLE Research Laboratory in Brussels in 1964 (MBLE stands for “ Manufacture Belge de Lampes et matériel Electrique”). This was a branch of Philips Research Labs specifically dedicated to background research in applied mathematics and computing science. After 18 years of research in programming languages, formal semantics, program analysis and concurrency at MBLE, he joined the newly founded department of Computing Science at UCL in 1982 with new interests in diverse areas such as proof systems, control theory and dynamical systems. Michel contributed to the PhD work of dozens of people in Belgium and France, as supervisor or contributor, without ever having been interested in getting a PhD himself. -

Coverity Static Analysis
Coverity Static Analysis Quickly find and fix Overview critical security and Coverity® gives you the speed, ease of use, accuracy, industry standards compliance, and quality issues as you scalability that you need to develop high-quality, secure applications. Coverity identifies code critical software quality defects and security vulnerabilities in code as it’s written, early in the development process when it’s least costly and easiest to fix. Precise actionable remediation advice and context-specific eLearning help your developers understand how to fix their prioritized issues quickly, without having to become security experts. Coverity Benefits seamlessly integrates automated security testing into your CI/CD pipelines and supports your existing development tools and workflows. Choose where and how to do your • Get improved visibility into development: on-premises or in the cloud with the Polaris Software Integrity Platform™ security risk. Cross-product (SaaS), a highly scalable, cloud-based application security platform. Coverity supports 22 reporting provides a holistic, more languages and over 70 frameworks and templates. complete view of a project’s risk using best-in-class AppSec tools. Coverity includes Rapid Scan, a fast, lightweight static analysis engine optimized • Deployment flexibility. You for cloud-native applications and Infrastructure-as-Code (IaC). Rapid Scan runs decide which set of projects to do automatically, without additional configuration, with every Coverity scan and can also AppSec testing for: on-premises be run as part of full CI builds with conventional scan completion times. Rapid Scan can or in the cloud. also be deployed as a standalone scan engine in Code Sight™ or via the command line • Shift security testing left. -

Predicate Dispatching
This pap er app ears in ECOOP the th Europ ean Conference on Ob ject Oriented Programming Brussels Belgium July pp Predicate Dispatching A Unied Theory of Dispatch Michael Ernst Craig Kaplan and Craig Chambers Department of Computer Science and Engineering University of Washington Seattle WA USA fmernstcskchambersgcswashingtonedu httpwwwcswashingtoneduresearchprojectscecil Abstract Predicate dispatching generalizes previous metho d dispatch mechanisms by p ermitting arbitrary predicates to control metho d ap plicabili ty and by using logical implication b etween predicates as the overriding relationship The metho d selected to handle a message send can dep end not just on the classes of the arguments as in ordinary ob jectoriented dispatch but also on the classes of sub comp onents on an arguments state and on relationships b etween ob jects This simple mechanism subsumes and extends ob jectoriented single and multiple dispatch MLstyle pattern matching predicate classes and classiers which can all b e regarded as syntactic sugar for predicate dispatching This pap er introduces predicate dispatching gives motivating examples and presents its static and dynamic semantics An implementation of predicate dispatching is available Introduction Many programming languages supp ort some mechanism for dividing the b o dy of a pro cedure into a set of cases with a declarative mechanism for selecting the right case for each dynamic invocation of the pro cedure Case selection can b e broken down into tests for applicability a case is a candidate -

A Comparison of SPARK with MISRA C and Frama-C
A Comparison of SPARK with MISRA C and Frama-C Johannes Kanig, AdaCore October 2018 Abstract Both SPARK and MISRA C are programming languages intended for high-assurance applications, i.e., systems where reliability is critical and safety and/or security requirements must be met. This document summarizes the two languages, compares them with respect to how they help satisfy high-assurance requirements, and compares the SPARK technology to several static analysis tools available for MISRA C with a focus on Frama-C. 1 Introduction 1.1 SPARK Overview Ada [1] is a general-purpose programming language that has been specifically designed for safe and secure programming. Information on how Ada satisfies the requirements for high-assurance software, including the avoidance of vulnerabilities that are found in other languages, may be found in [2, 3, 4]. SPARK [5, 6] is an Ada subset that is amenable to formal analysis and thus can bring increased confidence to software requiring the highest levels of assurance. SPARK excludes features that are difficult to analyze (such as pointers and exception handling). Its restrictions guarantee the absence of unspecified behavior such as reading the value of an uninitialized variable, or depending on the evaluation order of expressions with side effects. But SPARK does include major Ada features such as generic templates and object-oriented programming, as well as a simple but expressive set of concurrency (tasking) features known as the Ravenscar profile. SPARK has been used in a variety of high-assurance applications, including hypervisor kernels, air traffic management, and aircraft avionics. In fact, SPARK is more than just a subset of Ada. -

BEGINNING OBJECT-ORIENTED PROGRAMMING with JAVASCRIPT Build up Your Javascript Skills and Embrace PRODUCT Object-Oriented Development for the Modern Web INFORMATION
BEGINNING OBJECT-ORIENTED PROGRAMMING WITH JAVASCRIPT Build up your JavaScript skills and embrace PRODUCT object-oriented development for the modern web INFORMATION FORMAT DURATION PUBLISHED ON Instructor-Led Training 3 Days 22nd November, 2017 DESCRIPTION OUTLINE JavaScript has now become a universal development Diving into Objects and OOP Principles language. Whilst offering great benefits, the complexity Creating and Managing Object Literals can be overwhelming. Defining Object Constructors Using Object Prototypes and Classes In this course we show attendees how they can write Checking Abstraction and Modeling Support robust and efficient code with JavaScript, in order to Analyzing OOP Principles in JavaScript create scalable and maintainable web applications that help developers and businesses stay competitive. Working with Encapsulation and Information Hiding Setting up Strategies for Encapsulation LEARNING OUTCOMES Using the Meta-Closure Approach By completing this course, you will: Using Property Descriptors Implementing Information Hiding in Classes • Cover the new object-oriented features introduced as a part of ECMAScript 2015 Inheriting and Creating Mixins • Build web applications that promote scalability, Implementing Objects, Inheritance, and Prototypes maintainability and usability Using and Controlling Class Inheritance • Learn about key principles like object inheritance and Implementing Multiple Inheritance JavaScript mixins Creating and Using Mixins • Discover how to skilfully develop asynchronous code Defining Contracts with Duck Typing within larger JS applications Managing Dynamic Typing • Complete a variety of hands-on activities to build Defining Contracts and Interfaces up your experience of real-world challenges and Implementing Duck Typing problems Comparing Duck Typing and Polymorphism WHO SHOULD ATTEND Advanced Object Creation Mastering Patterns, Object Creation, and Singletons This course is for existing developers who are new to Implementing an Object Factory object-oriented programming in the JavaScript language. -
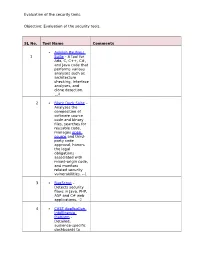
Evaluation of the Security Tools. SL No. Tool Name Comments 1
Evaluation of the security tools. Objective: Evaluation of the security tools. SL No. Tool Name Comments Axivion Bauhaus 1 Suite – A tool for Ada, C, C++, C#, and Java code that performs various analyses such as architecture checking, interface analyses, and clone detection. 4 2 Black Duck Suite – Analyzes the composition of software source code and binary files, searches for reusable code, manages open source and third- party code approval, honors the legal obligations associated with mixed-origin code, and monitors related security vulnerabilities. --1 3 BugScout – Detects security flaws in Java, PHP, ASP and C# web applications. -2 4 CAST Application Intelligence Platform – Detailed, audience-specific dashboards to Evaluation of the security tools. measure quality and productivity. 30+ languages, C, C++, Java, .NET, Oracle, PeopleSoft, SAP, Siebel, Spring, Struts, Hibernate and all major databases. 5 ChecKing – Integrated software quality portal that helps manage the quality of all phases of software development. It includes static code analyzers for Java, JSP, Javascript, HTML, XML, .NET (C#, ASP.NET, VB.NET, etc.), PL/SQL, embedded SQL, SAP ABAP IV, Natural/Adabas, C, C++, Cobol, JCL, and PowerBuilder. 6 ConQAT – Continuous quality assessment toolkit that allows flexible configuration of quality analyses (architecture conformance, clone detection, quality metrics, etc.) and dashboards. Supports Java, C#, C++, JavaScript, ABAP, Ada and many other languages. Evaluation of the security tools. 7 Coverity SAVE – A static code analysis tool for C, C++, C# and Java source code. Coverity commercialized a research tool for finding bugs through static analysis, the Stanford Checker, which used abstract interpretation to identify defects in source code.