Wikipedia Entity Expansion and Attribute Extraction from the Web Using Semi-Supervised Learning ∗
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

UPA : Redesigning Animation
This document is downloaded from DR‑NTU (https://dr.ntu.edu.sg) Nanyang Technological University, Singapore. UPA : redesigning animation Bottini, Cinzia 2016 Bottini, C. (2016). UPA : redesigning animation. Doctoral thesis, Nanyang Technological University, Singapore. https://hdl.handle.net/10356/69065 https://doi.org/10.32657/10356/69065 Downloaded on 05 Oct 2021 20:18:45 SGT UPA: REDESIGNING ANIMATION CINZIA BOTTINI SCHOOL OF ART, DESIGN AND MEDIA 2016 UPA: REDESIGNING ANIMATION CINZIA BOTTINI School of Art, Design and Media A thesis submitted to the Nanyang Technological University in partial fulfillment of the requirement for the degree of Doctor of Philosophy 2016 “Art does not reproduce the visible; rather, it makes visible.” Paul Klee, “Creative Credo” Acknowledgments When I started my doctoral studies, I could never have imagined what a formative learning experience it would be, both professionally and personally. I owe many people a debt of gratitude for all their help throughout this long journey. I deeply thank my supervisor, Professor Heitor Capuzzo; my cosupervisor, Giannalberto Bendazzi; and Professor Vibeke Sorensen, chair of the School of Art, Design and Media at Nanyang Technological University, Singapore for showing sincere compassion and offering unwavering moral support during a personally difficult stage of this Ph.D. I am also grateful for all their suggestions, critiques and observations that guided me in this research project, as well as their dedication and patience. My gratitude goes to Tee Bosustow, who graciously -
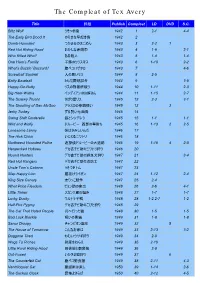
The Compleat of Tex Avery
The Compleat of Tex Avery Title 邦題 Publish Compleat LD DVD S.C. Blitz Wolf うそつき狼 1942 1 2-1 4-4 The Early Bird Dood It のろまな早起き鳥 1942 2 Dumb-Hounded つかまるのはごめん 1943 3 2-2 1 Red Hot Riding Hood おかしな赤頭巾 1943 4 1-9 2-1 Who Killed Who? ある殺人 1943 5 1-4 1-4 One Ham’s Family 子豚のクリスマス 1943 6 1-10 2-2 What’s Buzzin’ Buzzard? 腹ペコハゲタカ 1943 7 4-6 Screwball Squirrel 人の悪いリス 1944 8 2-5 Batty Baseball とんだ野球試合 1944 9 3-5 Happy-Go-Nutty リスの刑務所破り 1944 10 1-11 2-3 Big Heel-Watha インディアンのお婿さん 1944 11 1-15 2-7 The Screwy Truant さぼり屋リス 1945 12 2-3 3-1 The Shooting of Dan McGoo アラスカの拳銃使い 1945 13 3 Jerky Turkey ずる賢い七面鳥 1945 14 Swing Shift Cinderella 狼とシンデレラ 1945 15 1-1 1-1 Wild and Wolfy ドルーピー 西部の早射ち 1945 16 1-13 2 2-5 Lonesome Lenny 僕はさみしいんだ 1946 17 The Hick Chick いじわるニワトリ 1946 18 Northwest Hounded Police 迷探偵ドルーピーの大追跡 1946 19 1-16 4 2-8 Henpecked Hoboes デカ吉チビ助のニワトリ狩り 1946 20 Hound Hunters デカ吉チビ助の野良犬狩り 1947 21 3-4 Red Hot Rangers デカ吉チビ助の消防士 1947 22 Uncle Tom’s Cabana うそつきトム 1947 23 Slap Happy Lion 腰抜けライオン 1947 24 1-12 2-4 King Size Canary 太りっこ競争 1947 25 2-4 What Price Fleadom ピョン助の家出 1948 26 2-6 4-1 Little Tinker スカンク君の悩み 1948 27 1-7 1-7 Lucky Ducky ウルトラ子鴨 1948 28 1-2 2-7 1-2 Half-Pint Pygmy デカ吉チビ助のこびと狩り 1948 29 The Cat That Hated People 月へ行った猫 1948 30 1-5 1-5 Bad Luck Blackie 呪いの黒猫 1949 31 1-8 1-8 Senor Droopy チャンピオン誕生 1949 32 5 The House of Tomorrow こんなお家は 1949 33 2-13 3-2 Doggone Tired ねむいウサギ狩り 1949 34 2-9 Wags To Riches 財産をねらえ 1949 35 2-10 Little Rural Riding Hood 田舎狼と都会狼 1949 36 2-8 Out-Foxed いかさま狐狩り 1949 37 6 The Counterfeit Cat 腹ペコ野良猫 1949 38 2-11 4-3 Ventriloquist Cat 腹話術は楽し 1950 39 1-14 2-6 The Cuckoo Clock 恐怖よさらば 1950 40 2-12 4-5 The Compleat of Tex Avery Title 邦題 Publish Compleat LD DVD S.C. -

Cartoons— Not Just for Kids
Cartoons— Not just for kids. Part I 1. Chuck Jones later named this previously unnamed frog what? 2. In the 1990s the frog became the mascot for which television network? 3. What was Elmer Fudd’s original name? 4. What is the name of the opera that “Kill the Wabbit” came from? 5. Name a Looney Tunes animal cartoon character that wears pants: 6. What is the name of Pepe le Pew’s Girlfriend? 7. Name 3 Looney Tune Characters with speech impediments 8. Name the influential animator who had a hand in creating all of these characters: Bugs Bunny, Daffy Duck, Screwy Squirrel, and Droopy 9. Name the Tiny Tunes character based on the Tazmanian Devil 10. In what century does Duck Dodgers take place? 11. What is Dot’s full first name? 12. What kind of contracts do the animaniacs have? 13. What company do all of the above characters come from? Requiem for the Blue Civic – Jan. 2014 Cartoons 1 Part II 14. Name one of Darkwing Duck’s Catch phrases: 15. Name the three characters in “Tailspin” that also appear in “the Jungle book” (though the universes are apparently separate and unrelated) 16. Who is this? 17. Fill in these blanks: “ Life is like a ____________here in _____________ Race cars, lasers, aeroplanes ‐ it's a _______blur You might ______ a _____ or rewrite______ ________! __‐__!” 18. What was the name of Doug Funnie’s dog? 19. Whose catchphrase is: “So what’s the sitch”? 20. What kind of an animal is Ron Stoppable’s pet, Rufus? 21. -

1 Iconology in Animation: Figurative Icons in Tex Avery's Symphony In
Iconology in Animation: Figurative Icons in Tex Avery’s Symphony in Slang Nikos Kontos The current fascination with popular culture has generated numerous investigations focusing on a wide variety of subject matter deriving primarily from the mass media. In most cases they venture upon capturing its particular effects on the social practices of various target-audiences in our present era: effects that namely induce enjoyment and amusement within a life-world of frenetic consumerism verging upon the ‘hyper-real’. Popular culture has become a shibboleth, especially for those who are absorbed in demarcating post-modernity: its ubiquity hailed as a socially desirable manifestation of the mass-circulated ‘taste cultures’ and ‘taste publics’ – along with their ‘colonizing’ representations and stylizations – found in our post-industrial society. Hence, the large quantity of studies available tends to amplify on the pervasive theme of the postmodern condition with an emphasis on pastiche and/or parody. However, before the issue of post-modernity became an agenda-setting trend, semioticians had been in the forefront in joining the ranks of scholars who began to take seriously the mass-produced artifacts of popular culture and to offer their expertise in unraveling the immanent meanings of the sign systems ensconced within those productions. Since Roland Barthes’ and Umberto Eco’s critically acclaimed forays into the various genres of popular culture during the late 50’s and early 60’s, many semiotic scholars - following their lead - have attempted to extract from these mass art-forms meaningful insights concerning the semiotic significance portrayed in them. Many of these genres such as comics, detective/spy novels, science fiction, blockbuster films, etc., have been closely scrutinized and analyzed from an array of critical vantage points covering aspects that range, for example, from formal text-elements of the particular genre to its ideological ramifications in a socio-historical context. -

Blitz Wolf (Der Gross Méchant Loup), De Tex Avery
Blitz Wolf (Der gross HIDA méchant loup), de Tex Avery Présentation de l’oeuvre Fiche technique Réalisateur : Tex Avery Producteur : MGM (Metro-Goldwyn-Mayer) Genre: Film d’animation Pays: Etats-Unis Date de sortie : 22 août 1942 Durée: 10 minutes Synopsis Une variante sur l'histoire bien connue des trois petits cochons, avec un loup qui a bien des points communs avec Adolf Hitler. 1ère approche de l’œuvre 1) Quelle impression cette œuvre vous fait-elle? Quels sentiments avez-vous en la visionnant ? 2) Quelles questions vous posez-vous en regardant ce dessin animé? Contexte historique 3) D’après la date de ce dessin animée, quel est le contexte historique aux Etats-Unis ? (aidez- vous de la chronologie vue en cours) Décembre 1941 : entrée en guerre des USA après l’attaque japonaise sur Pearl Harbor Août 1942 : les Américains sont en pleine guerre dans le Pacifique Contexte artistique Le premier dessin animé de l’histoire du cinéma est présenté en 1906. Il s’intitule « Humorous Phases of Funny Faces » (Phases amusantes de figures rigolotes). Il a été réalisé à partir de dessins à la craie sur un tableau noir. Les Américains vont très vite s’emparer de cette nouvelle technique d’animation et créer une véritable industrie du cinéma d’animation. Trois studios émergent dans l’entre-deux guerres: les studios Fleischer (qui ont crée les personnages de Popeye ou Betty Boop), la Walt Disney Company (et son célèbre Mickey Mouse) et les studios de Tex Avery (à qui l’on doit les personnages de Bugs Bunny ou Droopy). -
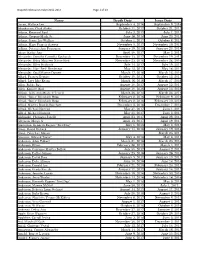
Dispatch Obituary Index
Dispatch Obituaries Index 2016-2017 Page 1 of 63 Name Death Date Issue Date Aaron, Wallace Lee September 4, 2016 September 9, 2016 Aboukaram, Chad Aladin October 11, 2017 October 21, 2017 Adams, Emanuel Paul July 3, 2017 July 7, 2017 Adams, Gregory Mark, Sr. June 16, 2018 June 20, 2018 Adams, Jessie Lee Wallace October 1, 2017 October 6, 2017 Adams, Mary Frances Sawyer November 5, 2017 November 10, 2017 Adkins, Patricia Ann Fronsman January 19, 2018 January 23, 2018 Akers, Kathy Ann April 30, 2017 May 2, 2017 Alexander, Dorothy Carmilla Upchurch December 15, 2017 December 19, 2017 Alexander, Edna Maureen Nance Ried November 23, 2016 November 26, 2016 Alexander, Ellen Rothrock July 14, 2017 July 19, 2017 Alexander, Hoy "Red" Henderson May 12, 2017 May 16, 2017 Alexander, Opal Maxine Dorsett March 17, 2016 March 18, 2016 Alford, Frances Bernice October 10, 2017 October 12, 2017 Alford, Luty Mae Evans March 16, 2016 March 17, 2016 Allen, Bobby Ray August 10, 2017 August 12, 2017 Allen, Emmett Earl August 10, 2016 August 13, 2016 Allison, Billy Ann Mitchell Terrell March 26, 2018 March 28, 2018 Allred, "Betty" Elizabeth Hope February 8, 2016 February 9, 2016 Allred, "Betty" Elizabeth Hope February 8, 2016 February 10, 2016 Allred, Martha Brenda Burchett December 5, 2016 December 7, 2016 Allred, Michael Norman May 31, 2017 June 1, 2017 Allred, Michael Norman May 31, 2017 June 3, 2017 Alsbrooke, Cheniqua Janelle April 23, 2017 April 28, 2017 Alverson, Marge A April 13, 2017 April 19, 2017 Amderson, Kenneth Eugene "Bird Dog" May 1, 2018 May 8, -

Visited on 5/21/2015
Spike Bulldog - Tom and Jerryvisited Wiki on 5/21/2015 Page 1 of 3 Submit Query Sign in Start a wikia Spike Bulldog Spike Bulldog For other uses, see the disambiguation page for Spike. Spike is a grey bulldog that appears in many episodes of Tom and Jerry. He is a friend of Jerry and a rival of Tom, however, sometimes he is a rival of both like the episode Dog Trouble. He hates Tom because in the episodes that Spike appears, fights Tom is chasing Jerry around but ends up giving Spike or his son, Tyke, a bad day. Obviously, whenever Spike tells Tom not to do a certain thing (ex. dirtying Tyke), Jerry does his best to get Tom in trouble (in the example, Jerry would get Tyke as dirty as possible). Tom Cat's son is his foe and hero. Spike also appeared in some of the recent cartoons featuring a basset hound called Droopy, another popular MGM cartoon character. He's also in Tom and Jerry Tales. He appeared in most episodes, in "Catfish Follies", he is a dogfish and also in "Zent Out of Shape" where he is similar to Godzilla. He also beats Jerry occasionally this probably that Spike finally notices it was Jerry who was actually really responsible for bothering his son, stealing his bones and getting disturbed and injured that Jerry caused on him and messing up his son. You can also see Spike in Mickey Mouse, but as Butch the Bulldog. Contents Appearance Spike has grey skin, a red dog leash and a anchored tatoo on his left upper arm as seen in "Quiet Please!". -

Tex Avery Follies
Tex Avery DOSSIER 170 Tex Avery Follies COLLÈGE AU CINÉMA Avec la participation de votre Conseil général SYNOPSIS One Cab’s Family (Bébé Taxi ou Tu seras un taxi, mon fils) : La naissance de Bébé Taxi rend fous de bonheur maman et papa Taxi qui assistent avec ravissement à la poussée de sa première dent, à son premier mot. Puis bébé taxi grandit et il affirme sa volonté d’être voiture de course et non taxi comme son père, causant une horrible désillusion à ses parents. Il part à l’aventure, provoque quelques incidents avant de faire la course avec un rapide. Son père tente de le rattraper et tombe en panne sur la voie ferrée. Son fils le sauve et est renversé par le rapide. Une fois rétabli, il choisit d’être taxi mais avec un moteur de bolide. The Hick Chick (Coqs de village ou Plouc à bec) : Lem, un coq de campagne stupide, demande Daisy en mariage. Mais Charles, un coq noir et distingué, survient, la séduit et se débarrasse de Lem. Charles l’amène à la ville où il la condamne à travailler dans une blanchisserie. Lem vient la sauver et, un an plus tard, à la naissance de leurs enfants, l’histoire recommence… Hound Hunters (George et Junior vagabonds ou Chasseurs de chiens) : George et junior ne veulent plus être vagabonds et les voilà agents de fourrière. Ils traquent en vain un minuscule chiot, mais toutes leurs ruses échouent minablement. Ils redeviennent vagabonds en compagnie du chiot qui les rejoint. Slap Happy Lion (Le Lion flagada ou Le Lion frapadingue) : Le lion du Jingling Bros Circus est tout à fait gaga et doit être poussé en fauteuil roulant par un infirmier. -

D E L'antiq U Ité a U IX Siè C Le D U IX Siè C Le À La Fin D U XVII S. XVIII E T
Arts, sociétés, cultures Art, espace, temps Arts, États et pouvoir Arts, mythes et religions Arts techniques, Arts, ruptures, expressions continuités Nom de l’œuvre - Nom de l’auteur ou de l’artiste Der Gross mechant loup ou Blitz Wolf, Tex Avery Reproduction de l’œuvre : siècle ème IX De l’AntiquitéDe au s. ème iècle s ème Du IX Du la fin XVII du À Blitz Wolf (parfois titré Der Gross méchant loup en français) est un court-métrage d'animation ème américain produit par la Metro-Goldwyn-Mayer en 1942 et un film de propagande anti-nazi de la Seconde Guerre mondiale parodiant Adolf Hitler. Il fut réalisé par Tex Avery et produit par Fred Quimby. Il fut nommé dans la catégorie Oscar du meilleur court-métrage d'animation. et et XIX Ce dessin animé est une parodie de l'histoire bien connue Les Trois Petits Cochons, produit dans le ton siècles de la propagande anti-allemande de la Seconde Guerre mondiale. Dans ce dessin animé, les cochons ème partent en guerre contre Adolf le Loup (sous les traits d’Adolf Hitler), qui menace d'envahir Cochonland (Pigmania dans la version américaine). Les deux cochons qui construisent leurs maisons en paille et en bois déclarent qu'ils n'ont pas besoin de prendre des précautions contre le loup puisqu'ils XVIII ont signé un Pacte de non-agression avec lui. Le cochon qui construit sa maison en pierre, le Sergent Pur Porc (Sergeant Pork dans la version américaine), prend ses précautions et renforce sa maison avec un puissant dispositif de défense composés de barbelés, de bunkers, d'obusiers et de tranchées. -

'Enter Bugs Bunny: Matador and Star in Bully for Bugs'. Revista De Estudios Taurinos, 41
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Sunderland University Institutional Repository Smith, Susan and Summers, Sam (2017) 'Enter Bugs Bunny: Matador and Star in Bully for Bugs'. Revista de Estudios Taurinos, 41. ISSN 1134-4970 (In Press) Downloaded from: http://sure.sunderland.ac.uk/8573/ Usage guidelines Please refer to the usage guidelines at http://sure.sunderland.ac.uk/policies.html or alternatively contact [email protected]. Enter Bugs Bunny: Matador and Star in Bully for Bugs I D Laugh-O-Grams cartoon Puss in Boots which the pro T B K match for his daughter, is persuaded by his feline friend Puss to visit the local cinema. There, they watch a cartoon billed RODOLPH VASELINO In THROWING THE BULL In Six Parts, the title of which unmistakably alludes to Ru V e silent version of Blood and Sand (1922). Here, the cartoonalising of Valentino as Vaselino and emulation of this star by becoming a masked matador who ends up having to rely on hypnotic help from Puss to defeat the bull comically deflates -presenting him within a form (animation) traditionally regarded as the poor relation to live action cinema. As such, this cartoon skit of Valentino in Blood and Sand illustrates import[ing] [] non- animated movie star trappings to re- - .1 Whilst it refrains from the sharper caricaturing of live action Hollywood stars that Crafton traces in Warner Bros. cartoons,2 D Laugh-O-Gram is nonetheless instructive in highlighting stardom and -

Black Representation in American Short Films, 1928-1954
University of Massachusetts Amherst ScholarWorks@UMass Amherst Doctoral Dissertations 1896 - February 2014 1-1-2002 Black representation in American short films, 1928-1954 Christopher P. Lehman University of Massachusetts Amherst Follow this and additional works at: https://scholarworks.umass.edu/dissertations_1 Recommended Citation Lehman, Christopher P., "Black representation in American short films, 1928-1954 " (2002). Doctoral Dissertations 1896 - February 2014. 914. https://scholarworks.umass.edu/dissertations_1/914 This Open Access Dissertation is brought to you for free and open access by ScholarWorks@UMass Amherst. It has been accepted for inclusion in Doctoral Dissertations 1896 - February 2014 by an authorized administrator of ScholarWorks@UMass Amherst. For more information, please contact [email protected]. m UMASS. DATE DUE UNIVERSITY LIBRARY UNIVERSITY OF MASSACHUSETTS AMHERST BLACK REPRESENTATION IN AMERICAN ANIMATED SHORT FILMS, 1928-1954 A Dissertation Presented by CHRISTOPHER P. LEHMAN Submitted to the Graduate School of the University of Massachusetts Amherst in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY May 2002 W. E. B. DuBois Department of Afro-American Studies © Copyright by Christopher P. Lehman 2002 All Rights Reserved BLACK REPRESENTATION IN AMERICAN ANIMATED SHORT FILMS, 1928-1954 A Dissertation Presented by CHRISTOPHER P. LEHMAN Approved as to style and content by: Ernest Allen, Chair Johnl|L Bracey, Jr., Member Robert P. Wolff, Member Lynda Morgan, Member Esther Terry, Department Head Afro-American Studies W. E. B. DuBois Department of ACKNOWLEDGMENTS Several archivists have enabled me to find sources for my research. I thank Tom Featherstone of Wayne State University's Walter Reuther Library for providing a copy of the film Brotherhood ofMan for me. -

Vitesse Et Dématérialisation. Le Corps Du Toon Chez Tex Avery Johanne Villeneuve
Document generated on 09/30/2021 12:20 p.m. Cinémas Revue d'études cinématographiques Journal of Film Studies Vitesse et dématérialisation. Le corps du toon chez Tex Avery Johanne Villeneuve La Représentation du corps au cinéma Article abstract Volume 7, Number 1-2, Fall 1996 This inquiry into the significance of Tex Avery's work in animation situates it within a specific reading of the comic body and its materiality. Heir to both the URI: https://id.erudit.org/iderudit/1000932ar European burlesque tradition and the archetype of the trickstet, inspired by DOI: https://doi.org/10.7202/1000932ar the "economic" heroes of the eighteenth century, the "toon" nevertheless projects its exuberance through negation, its speed through material explosion See table of contents and the momentum of an endlessly renewable body, enjoying fantastic flexibility and adaptability, with a profusion of means of action, etc. Predation and devouring are key to the frenetic activity of the toon, but they always go hand in hand with the body's ability to open up the whole universe. Publisher(s) Cinémas ISSN 1181-6945 (print) 1705-6500 (digital) Explore this journal Cite this article Villeneuve, J. (1996). Vitesse et dématérialisation. Le corps du toon chez Tex Avery. Cinémas, 7(1-2), 55–72. https://doi.org/10.7202/1000932ar Tous droits réservés © Cinémas, 1996 This document is protected by copyright law. Use of the services of Érudit (including reproduction) is subject to its terms and conditions, which can be viewed online. https://apropos.erudit.org/en/users/policy-on-use/ This article is disseminated and preserved by Érudit.