Morfeusz — a Practical Tool for the Morphological Analysis of Polish
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Effect of Using the Mind Mapping Technique on the Mastery of Grammar Among Tenth Graders In
Al Azhar University - Gaza Deanery of Graduate Studies & Scientific Research Faculty of Education Department of Curriculum and Teaching Methods The Effect of Using The Mind Mapping Technique on The Mastery of Grammar among Tenth Graders in Gaza Governorates Submitted By Aziz Harbi Elkahlout Supervised By Prof. Dr. Hassan Abu Jarad 2013/2014 أَلَمْ تَزَ كَيْفَ ضَزَبَ اللَّهُ مَثَلًا كَلِمَتً طَيِّبَتً كَشَجَزَةٍ طَيِّبَتٍ أَصْلُهَا ثَابِتٌ وَفَزْعُهَا فِي السَّمَاءِ}42{ تُؤْتِي أُكُلَهَا كُلَّ حِنيٍ بِإِذْنِ رَبِّهَا وَيَضْزِبُ اللَّهُ الْأَمْثَالَ لِلنَّاسِ لَعَلَّهُمْ يَتَذَكَّزُونَ}42{ صدق اهلل العظيم )سورة إبراهيم، اﻵية: 42-42( II Dedication To the soul of my mother, To my father for his love, endless support and encouragement, To my teachers and guides, To my dear wife for her extraordinary patience and understanding, To my daughters and sons, who endured a lot to let me continue. To my brothers, especially Safawt, for opening my eyes to higher education, To my friends for motivating and encouraging me to attain my dream, To the great martyrs and prisoners, the symbol of sacrifice, To all those who believe in the importance of learning. To all, I dedicate my research. III Acknowledgement All praise to Allah, the Lord of the worlds; and prayers and peace be upon prophet Mohammed, His servant and messenger. This thesis could not have been accomplished without the assistance, support, and encouragement of many people in my life. I would like to thank them for their support and guidance along the way. I would like to express my deepest appreciation to my supervisor, Professor Dr. Hassan Abu Jarad, who patiently revised each chapter of this thesis and provided invaluable guidance and support throughout my writing process. -

Ba'da and Qabla in Online News: a Corpus-Based Study
The American University in Cairo School of Humanities and Social Sciences ba’da and qabla in Online News: A Corpus-Based Study A Thesis Submitted to The Department of Applied Linguistics in partial fulfillment of the requirements for the degree of Master of Arts by Ayman Eddakrouri Under the supervision of Prof. Zeinab Taha Department of Applied Linguistics May 2016 This thesis is dedicated to my lovely wife, Dr. Amani Ramadan, who is indeed a gift from Allah. ACKNOWLEDGEMENT I would like to begin by expressing my deep gratitude to my supervisor, Prof. Zeinab Taha, not only for her guidance, comments, and notices during the whole period in which the research of this thesis was conducted, but also for her personal advice, encouragements, kindness, and thoughtfulness. I cannot capture in words what it has meant to me to have had the privilege of working with her. Indeed, she is more than a supervisor to me. I am most grateful to my first reader, Prof. Raghda Elessawi. Her guidance and patience with me, both during the writing of this thesis and over the entire course of my time at the American University in Cairo, were invaluable. I am deeply indebted to her. Also, I would like to thank my second reader, Prof. Amira Agameya, for her distinguished suggestions, notices, and feedback. I have greatly profited from her insightful responses to my work. A very special gratitude goes to Dr. Ashraf Abdou who helped me at the very beginning and initiated my knowledge in Corpus Linguistics. I owe a debt of gratitude to him. -

The Levinas Reader
The Levinas Reader Emmanuel Levinas EDITED BY SEAN HAND Basil Blackwell Copyright © Introduction and editorial apparatus, Sean Hand 1989 Copyright © 'The Phenomenological Theory of Being', 'There Is', 'Time and the Other', 'Martin Buber and the Theory of Knowledge', 'Ethics as First Philosophy', 'Substitution', 'Reality and Its Shadow', 'The Transcendence of Words', 'The Servant and her Master', 'The Other in Proust', 'God and Philosophy', 'Revelation in the Jewish Tradition', 'The Pact', 'Ideology and Idealism', 'Judaism', 'Judaism and the Pre sent', 'The State of Israel and the Religion of Israel', 'Means of Identification', 'The State of Caesar and the State of David', 'Politics After', 'Assimilation and New Culture', 'Ethics and Politics', Emmanuel Levinas, 1930, 1946, 1947, 1963, 1984, 1968, 1948, 1949, 1966, 1947, 1975, 1977, 1982, 1973, 1971, 1960, 1951, 1963, 1971, 1979, 1980, 1982 First published 1989 Basil Blackwell Ltd 108 Cowley Road, Oxford, OX4 lJF, UK Basil Blackwell Inc. 3 Cambridge Center, Cambridge, MA 02142, USA All rights reserved . Except for the quotation of short passages for the purposes of criticism and review, no part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanic al, photocopying, recording or otherwise, without the prior permission of the publisher. Except in the United States of America, this book is sold subject to the condition that it shall not, by way of trade or otherwise, be lent, re-sold, hired out, or otherwise circulated without the publisher's prior consent in any form of binding or cover other than that in which it is published and witout a similar condition including this condition being imposed on the subsequent purchaser. -

CHAPTER FOUR the WORD ORDER in SINHALA CHAPTER FOUR the Word Order in Sinhala
CHAPTER FOUR THE WORD ORDER IN SINHALA CHAPTER FOUR The Word Order in Sinhala 4.0. Preliminaries Languages in the world are classified according to their most typical syntactic structures. Greenberg (1963: 73-113) while considering the characteristics of different languages, divides them into three principal order types: Type 1. VSO (Verb, subject and object) Type 2. SVO (Subject, verb and object) Type 3. SOV (Subject, object and verb) Sinhala provides evidence for being classified as type 3. Indo -Aryan and Dravidian have the same order type. a. guruvaraya poto liyanovsi The teacher-S the book-0 writes- V-Pres The teacher writes the book "The basic word order in Sinhala remains as SOV, but this order may vary depending upon the context and the focus'' (Gair 2003:788). Thus, a simple SOV sentence like a can undergo changes as in the sentences l(b, c, d) b. kumsi.'rg pota kiyavonavn Kuma.ra-S the book-0 reads-V-Pres Kumara reads the book c. kumsi.ra kiyovondva poto Kumara—S reads-V-Pres the book-0 Kumara reads the book potd kiyavondva kuma.Td the book-0 reads- V-Pres Kumara -S Kumara reads the book The following utterance is less dominant in Sinhala. e. kiyavangvsi potd kumsi:r9 reads- V-Pres the book-0 Kuma:ra -S Kumara reads the book This chapter deals with the word order in Sinhala at the phrase level clause level and the sentence level. 4.1. The Word Order at the Phrase Level A phrase which is called in Sinhala /pHdokcefi/ is a group of words which form a grammatical unit. -

A Comparative Analysis of English and Igala Morphological Processes by Andrew-Ogidi, Rakiya Christiana December, 2006
A COMPARATIVE ANALYSIS OF ENGLISH AND IGALA MORPHOLOGICAL PROCESSES BY ANDREW-OGIDI, RAKIYA CHRISTIANA DECEMBER, 2006 A COMPARATIVE ANALYSIS OF ENGLISH AND IGALA MORPHOLOGICAL PROCESSES BY ANDREW-OGIDICHRISTIANA RAKIYA MA/ARTS/38422/02-04 A THESIS SUBMITTED TO THE POSTGRADUATE SCHOOL, AHMADU BELLO UNIVERSITY, ZARIA, IN PARTIAL FULFILMENT OF THE REQUIREMENTS FOR THE AWARD OF MASTER DEGREE. (ENGLISH LANGUAGE) DEPARTMENT OF ENGLISH FACULTY OF ARTS AHMADU BELLO UNIVERSITY, ZARIA NIGERIA DECEMBER, 2006 ii DECLARATION I Andrew-Ogidi, Rakiya Christiana do solemnly declare that, this Thesis has been written by me and that it is a record of my own research work. It has not been presented in any previous application for higher degree. All sources of information are duly acknowledged by means of references. ………………………………..…………. …………….……… Andrew-Ogidi, Christiana Rakiya Date iii CERTIFICATION This is to certify that, this thesis, entitled ‘A comparative analysis of English and Igala Morphological processes’ submitted by Andrew-Ogidi, Rakiya Christiana meets the regulations governing the award of the Degree of Master of Arts of Ahmadu Bello University, Zaria and is approved for its contribution to knowledge and literary presentation. ……………………………………….. ………………… Dr. Joshua A. Adebayo Date Chairman, Supervisory Committee ……………………………………….. ………………… Dr. Gbenga Ibileye Date Member Supervisory Committee ……………………………………….. ………………… Dr. Joshua A. Adebayo Date ……………………………………….. ………………… Dean Post-graduate School Date iv DEDICATION To Faith Eneole Ogidi – my beautiful daughter v ACKNOWLEDGEMENTS Glory belongs to God who sees the intents of a mans heart, life up the humble, and debases the proud. In Him is the fullness of all knowledge. Without Him, this research would have been a mirage. Once again, by Him, I have lept over a well. -
Stone-Kovner Presentation on the Use of Articles in English
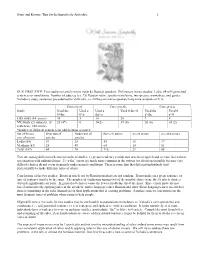
Stone and Kovner: Tips for the Imperfectly Articulate 1 OUR FIRST STEP: Two studies on article errors made by Russian speakers. Differences in two studies: Lydia, 84 self-generated sentences or translations: Number of subjects (ca. 25) Russian native speaker translators, interpreters, wannabees, and guides. Volodia’s study, sentences pre-selected for difficulty, ca. 20 Russian native speakers long-time residents of U.S. Correct is 0 Correct is the Correct is a Study Used the Used a Used a Used 0 the>0 Used the Used 0 0>the 0>a the>a a>the a>0 LRS study (84 errors) 34 5 10 20 7 8 VK Study (21 subjects, 18 25 (4*) 0 14(2) 39 (6) 20 (6) 10 (2) sentences, 108 errors) *number of different sentences in which errors occurred Set of Errors Over use of Under use of the<->0 errors a<->0 errors a<->the errors (no. of errors) articles articles Lydia (84) 39 28 54 13 17 Vladimir (83) 25 49 64 10 51 Total (167) 64 76 118 23 68 Two interesting differences between results of studies: 1) greater tendency to underuse articles in speech and overuse in a written test situation with unlimited time; 2) “a-the” errors are much more common in the written test situation (possibly because very difficult choices do not occur frequently under natural conditions) There is some hint that different individuals tend preferentially to make different types of errors. Conclusions of the two studies: Errors in article use by Russian speakers are not random. Errors made on a given sentence or type of sentence tend to be the same. -

A a Posteriori a Priori Aachener Förderdiagnostische Abbild
WSK-Gesamtlemmaliste (Stand: Januar 2017) A abgeleitetes Adverb Abklatsch a posteriori abgeleitetes Nominal Abkürzung a priori abgeleitetes Verb Abkürzungsprozess Aachener abgeleitetes Wort Abkürzungspunkt Förderdiagnostische abgerüstete Abkürzungsschrift Abbild Transliterationsvariante Abkürzungswort Abbildtheorie abgeschlossene Kategorie Ablativ Abbildung Abgeschlossenheit Ablativ, absoluter Abbildung, Beschränkung Abglitt einer ablative Abgraph Abbildung, Bild einer ablative case Abgrenzungssignal Abbildung, konzeptuelle ablativus absolutus abhängige Prädikation Abbildung-1 ablativus causae abhängige Rede Abbildungen, ablativus comitativus abhängige Struktur Komposition von ablativus comparationis abhängiger Fragesatz Abbildungsfunktion ablativus copiae abhängiger Hauptsatz Abbildungstheorie ablativus discriminis abhängiger Satz Abbreviation ablativus instrumenti abhängiges Morphem abbreviatory convention ablativus limitationis Abhängigkeit Abbreviatur ablativus loci Abhängigkeit, entfernte Abbreviaturschrift ablativus mensurae Abhängigkeit, funktionale Abbruchpause ablativus modi Abbruchsignal Abhängigkeit, gegenseitige ablativus originis Abc Abhängigkeit, kodierte ablativus pretii Abdeckung Abhängigkeit, ablativus qualitatis Abduktion konzeptuelle ablativus respectus Abecedarium Abhängigkeit, ablativus separativus sequenzielle abessive ablativus sociativus Abhängigkeitsbaum A-Bewegung ablativus temporis Abhängigkeitsgrammatik Abfolge Ablaut Abhängigkeitshypothese Abfolge, markierte Ablaut, qualitativer ability abfragen Ablaut, quantitativer -

A Profile of the Hungarian DP the Interaction of Lexicalization, Agreement and Linearization with the Functional Sequence
Faculty of Humanities, Social Sciences and Education Center for Advanced Study in Theoretical Linguistics A profile of the Hungarian DP The interaction of lexicalization, agreement and linearization with the functional sequence A dissertation for the degree of Philosophiae Doctor December 2011 A profile of the Hungarian DP The interaction of lexicalization, agreement and linearization with the functional sequence Eva´ Katalin D´ek´any A thesis submitted for the degree Philosophiae Doctor University of Tromsø Faculty of Humanities, Social Sciences and Education Center for Advanced Study in Theoretical Linguistics December 2011 ii Contents Acknowledgements ix Abbreviations xi Letter-to-sound correspondences xiii 1 Introduction 1 1.1 Thedomainofinquiryandaimofthethesis . ......... 1 1.2 Whythisempiricalbasis. ...... 1 1.2.1 Motivating the domain of inquiry . ...... 1 1.2.2 ProblemareasintheHungarianxNP . .... 2 1.2.3 Interimsummary................................ 6 1.3 Howtosetupthefunctionalsequence . ........ 6 1.3.1 Lexicalization................................ ... 8 1.3.2 Agreement .................................... 8 1.3.3 Linearization ................................. .. 9 1.4 Theoutlineofthethesis . .. .. .. .. .. .. .. .. .. .. .. ...... 9 I The lexicalization problem 11 2 The functional sequence meets the lexicalization problem 13 2.1 Introducing the lexicalization problem . ............ 13 2.2 Polysemy in the lexicalization of the functional sequence............... 13 2.2.1 Polysemyofphrasalmodifiers. ..... 13 2.2.2 Polysemyofheads -

Evolution of Case in Ossetic*
Iran and the Caucasus 14 (2010) 287-322 Evolution of Case in Ossetic * Oleg Belyaev Moscow State University Abstract Ossetic sets itself apart from the other New Iranian languages by having a relatively elaborate system of nine cases. Since most of them are relatively late innovations, and only four cases (Nom., Gen, Abl., and Iness.) can be traced back to Proto-Iranian, many scholars tend to ascribe the development of the case system to Caucasian in- fluence. The exact nature of this influence, however, has never been demonstrated. The aim of this paper is, first, to not only reconstruct the etymologies of Ossetic cases, but also to provide a chronology of how the case system developed. The sec- ond aim pursued here is to give a systematic comparison of the case system of Os- setic with those of the neighbouring languages and to determine if there is any ex- ternal influence on the case system and, if so, what languages this influence came from. I conclude that Ossetic developed from a case system identical to those of Khotanese and Sogdian towards the present state under the influence of contact with Georgian and, later, with Turkic and Vaynakh languages. In the process of the discussion, I also argue that two new cases, the Directive and Regressive, are under- going grammaticalisation in contemporary Ossetic. Keywords Ossetic, North-East Iranian languages, Georgian, Vaynakh Languages, Case, Internal Reconstruction, Language Contact, Areal Linguistics §1. INTRODUCTION Compared to other modern Eastern Iranian languages, which usually have case inventories ranging from two to four cases, Ossetic has a strikingly elaborate system of nine cases (eight in Digor). -

WSK-Gesamtlemmaliste (Stand: Mai 2017)
WSK-Gesamtlemmaliste (Stand: Mai 2017) A abgeleitetes Verb Ablativ a posteriori abgeleitetes Wort Ablativ, absoluter a priori abgerüstete ablative Transliterationsvariante Aachener Förderdiagnostische ablative case abgeschlossene Kategorie Abbild ablativus absolutus Abgeschlossenheit Abbildtheorie ablativus causae Abglitt Abbildung ablativus comitativus Abgraph Abbildung, Beschränkung ablativus comparationis einer Abgrenzungssignal ablativus copiae Abbildung, Bild einer abhängige Prädikation ablativus discriminis Abbildung, konzeptuelle abhängige Rede ablativus instrumenti Abbildung-1 abhängige Struktur ablativus limitationis Abbildungen, Komposition abhängiger Fragesatz von ablativus loci abhängiger Hauptsatz Abbildungsfunktion ablativus mensurae abhängiger Satz Abbildungstheorie ablativus modi abhängiges Morphem Abbreviation ablativus originis Abhängigkeit abbreviatory convention ablativus pretii Abhängigkeit, entfernte Abbreviatur ablativus qualitatis Abhängigkeit, funktionale Abbreviaturschrift ablativus respectus Abhängigkeit, gegenseitige Abbruchpause ablativus separativus Abhängigkeit, kodierte Abbruchsignal ablativus sociativus Abhängigkeit, konzeptuelle Abc ablativus temporis Abhängigkeit, sequenzielle Abdeckung Ablaut Abhängigkeitsbaum Abduktion Ablaut, qualitativer Abhängigkeitsgrammatik Abecedarium Ablaut, quantitativer Abhängigkeitshypothese abessive Ablautausgleich ability A-Bewegung Ablautbildung Abjad Abfolge Ablautdoppelung Abklatsch Abfolge, markierte Ablautkombination Abkürzung abfragen Ablautreihe Abkürzungsprozess -

Title Table of Contents 1
On the nature of anticausative morphology: External arguments in change-of-state contexts Von der philosophisch-historischen Fakultät der Universität Stuttgart zur Erlangung der Würde eines Doktors der Philosophie (Dr. phil.) genehmigte Abhandlung Vorgelegt von Florian Mathis Schäfer aus Regensburg Hauptberichterin: Prof. Dr. Artemis Alexiadou Mitberichter: Prof. Dr. Hubert Haider Mitberichter: Prof. Dr. Halldór Ármann Sigurðsson Tag der mündlichen Prüfung: 09.10.2007 Institut für Linguistik/Anglistik der Universität Stuttgart 2007 Acknowledgements I would like to thank those people who got me interested in the study of language by teaching me linguistics. I would like to mention especially Brigitte Asbach-Schnittker, Gisbert Fanselow, Caroline Féry , Hans-Martin Gärtner, Douglas Saddy, Matthias Schlesewsky, Peter Staudacher, and my supervisor Artemis Alexiadou. I would like to especially thank Artemis Alexiadou for her encouragement, help and advise during the time it took me to develop and complete this work. I would also like to thank Hubert Haider and Halldór Sigurðsson who agreed to participate in my committee. During my time in Stuttgart, I was surrounded by a number of people who not only discussed linguistics with me but who also provided a pleasant social environment. Thanks to Nadine Aldinger, Roberta D’Allessandro, Agnes Bende-Farkas, Jonny Butler, Silke Fischer, Chiara Frigeni, Susann Fischer, Ljudmilla Geist, Kirsten Gengel, Fabian Heck, Steffen Heidinger, Christian Hying, Gianina Iordachioaia, Matthias Jilka, Hans Kamp, Susanne Lohrmann, Fabienne Martin, Tom McFadden, Maria Melchiors, Enyd Michel, Sabine Mohr, Arndt Riester, Jasper Roodenburg, Antje Roßdeutscher, Giuseppina Rota, Björn Rothstein, Britta Sauereisen, Sabine Schulte im Walde, Torgrim Solstad, Sven Strobel, Johannes Wespel. Many thanks also to Sandhya Sundaresan for correcting the English of this work. -
Creole Genesis and Universality: Case, Word Order, and Agreement Gerald Taylor Snow Brigham Young University
Brigham Young University BYU ScholarsArchive All Theses and Dissertations 2017-03-01 Creole Genesis and Universality: Case, Word Order, and Agreement Gerald Taylor Snow Brigham Young University Follow this and additional works at: https://scholarsarchive.byu.edu/etd Part of the Linguistics Commons BYU ScholarsArchive Citation Snow, Gerald Taylor, "Creole Genesis and Universality: Case, Word Order, and Agreement" (2017). All Theses and Dissertations. 6338. https://scholarsarchive.byu.edu/etd/6338 This Thesis is brought to you for free and open access by BYU ScholarsArchive. It has been accepted for inclusion in All Theses and Dissertations by an authorized administrator of BYU ScholarsArchive. For more information, please contact [email protected], [email protected]. Creole Genesis and Universality: Case, Word Order, and Agreement Gerald Taylor Snow A thesis submitted to the faculty of Brigham Young University in partial fulfillment of the requirements for the degree of Master of Arts Deryle W. Lonsdale, Chair Dallin D. Oaks Heather Willson-Sturman Department of Linguistics and English Language Brigham Young University Copyright © 2017 Gerald Taylor Snow All Rights Reserved ABSTRACT Creole Genesis and Universality: Case, Word Order, and Agreement Gerald Taylor Snow Department of Linguistics and English Language, BYU Master of Arts The genesis of creole languages is important to the field of linguistics for at least two reasons. As newly emerging languages, creoles provide a unique window on the human language faculty and on the development of language generally (Veenstra 2008). They also offer insight into what are arguably universal linguistic structures. Two opposing theories have been in contention in the literature with respect to creole genesis: (1) that creoles owe their origin to the lexifier and substrate languages of their speech community and to other environmental influences (McWhorter 1997); and alternatively, (2) that universal innate linguistic structures or principles are the generative source of creole grammar (Bickerton 1981).