People-Centric Natural Language Processing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Bibliography of Erik Wilde
dretbiblio dretbiblio Erik Wilde's Bibliography References [1] AFIPS Fall Joint Computer Conference, San Francisco, California, December 1968. [2] Seventeenth IEEE Conference on Computer Communication Networks, Washington, D.C., 1978. [3] ACM SIGACT-SIGMOD Symposium on Principles of Database Systems, Los Angeles, Cal- ifornia, March 1982. ACM Press. [4] First Conference on Computer-Supported Cooperative Work, 1986. [5] 1987 ACM Conference on Hypertext, Chapel Hill, North Carolina, November 1987. ACM Press. [6] 18th IEEE International Symposium on Fault-Tolerant Computing, Tokyo, Japan, 1988. IEEE Computer Society Press. [7] Conference on Computer-Supported Cooperative Work, Portland, Oregon, 1988. ACM Press. [8] Conference on Office Information Systems, Palo Alto, California, March 1988. [9] 1989 ACM Conference on Hypertext, Pittsburgh, Pennsylvania, November 1989. ACM Press. [10] UNIX | The Legend Evolves. Summer 1990 UKUUG Conference, Buntingford, UK, 1990. UKUUG. [11] Fourth ACM Symposium on User Interface Software and Technology, Hilton Head, South Carolina, November 1991. [12] GLOBECOM'91 Conference, Phoenix, Arizona, 1991. IEEE Computer Society Press. [13] IEEE INFOCOM '91 Conference on Computer Communications, Bal Harbour, Florida, 1991. IEEE Computer Society Press. [14] IEEE International Conference on Communications, Denver, Colorado, June 1991. [15] International Workshop on CSCW, Berlin, Germany, April 1991. [16] Third ACM Conference on Hypertext, San Antonio, Texas, December 1991. ACM Press. [17] 11th Symposium on Reliable Distributed Systems, Houston, Texas, 1992. IEEE Computer Society Press. [18] 3rd Joint European Networking Conference, Innsbruck, Austria, May 1992. [19] Fourth ACM Conference on Hypertext, Milano, Italy, November 1992. ACM Press. [20] GLOBECOM'92 Conference, Orlando, Florida, December 1992. IEEE Computer Society Press. http://github.com/dret/biblio (August 29, 2018) 1 dretbiblio [21] IEEE INFOCOM '92 Conference on Computer Communications, Florence, Italy, 1992. -

2018 Year in Review
2018 YEAR IN REVIEW www.cmu.edu/dietrich TABLE OF CONTENTS CARNEGIE MELLON UNIVERSITY’S DIETRICH COLLEGE OF HUMANITIES AND SOCIAL SCIENCES 02 Message from the Dean 03 Facts and Figures 04 Student Experience 22 Research and Creative Projects 31 Board of Advisors 32 Alumni Spotlights 34 Achievements MESSAGE FROM THE DEAN t Carnegie Mellon University, the Dietrich College of Humanities and Social Sciences is the home for Aresearch and education focused on humanity. Our faculty and students take on problems that are important to the world. At the Dietrich College, faculty conduct foundational and deep disciplinary research, collaborate across disciplines, and share a passion for innovation in both research and teaching. Our students emerge from their experience at CMU able to communicate, think, learn and understand the world in ways that will serve them for the rest of their lives. This “year in review” is a sample of stories about the students, faculty, staff and alumni in the college that appeared on CMU websites, in the local press or the national media in 2018. In this publication, you can learn more about our newly launched Pittsburgh Summer Internship Program, our faculty members’ advocacy for the humanities in Washington, D.C., and research on autism risk-factors. The year was also full of milestones for our talented alumni, who now include a member of U.S. Congress and an Emmy Award winner. I am continually impressed by the contributions and accomplishments of our community, and even more so as we begin to reflect on the Dietrich College’s 50th anniversary, which we will celebrate in 2019. -

Decentralized Identifier WG F2F Sessions
Decentralized Identifier WG F2F Sessions Day 1: January 29, 2020 Chairs: Brent Zundel, Dan Burnett Location: Microsoft Schiphol 1 Welcome! ● Logistics ● W3C WG IPR Policy ● Agenda ● IRC and Scribes ● Introductions & Dinner 2 Logistics ● Location: “Spaces”, 6th floor of Microsoft Schiphol ● WiFi: SSID Publiek_theOutlook, pwd Hello2020 ● Dial-in information: +1-617-324-0000, Meeting ID ● Restrooms: End of the hall, turn right ● Meeting time: 8 am - 5 pm, Jan. 29-31 ● Breaks: 10:30-11 am, 12:30-1:30 pm, 2:30-3 pm ● DID WG Agenda: https://tinyurl.com/didwg-ams2020-agenda (HTML) ● Live slides: https://tinyurl.com/didwg-ams2020-slides (Google Slides) ● Dinner Details: See the “Dinner Tonight” slide at the end of each day 3 W3C WG IPR Policy ● This group abides by the W3C patent policy https://www.w3.org/Consortium/Patent-Policy-20040205 ● Only people and companies listed at https://www.w3.org/2004/01/pp-impl/117488/status are allowed to make substantive contributions to the specs ● Code of Conduct https://www.w3.org/Consortium/cepc/ 4 Today’s agenda 8:00 Breakfast 8:30 Welcome, Introductions, and Logistics Chairs 9:00 Level setting Chairs 9:30 Security issues Brent 10:15 DID and IoT Sam Smith 10:45 Break 11:00 Multiple Encodings/Different Syntaxes: what might we want to support Markus 11:30 Different encodings: model incompatibilities Manu 12:00 Abstract data modeling options Dan Burnett 12:30 Lunch (brief “Why Are We Here?” presentation) Christopher Allen 13:30 DID Doc Extensibility via Registries Mike 14:00 DID Doc Extensibility via JSON-LD Manu -

Scott Fabius Kiesling
Curriculum Vitae Updated May 2009 Scott Fabius Kiesling Department of Linguistics University of Pittsburgh 2816 Cathedral of Learning Pittsburgh, PA 15260 USA Phone: 412-624-5916 Fax: 412-624-6130 Email: [email protected] http://www.pitt.edu/~kiesling/skpage.html Education Ph.D., Linguistics, Georgetown University, 1996 Dissertation: Language, Gender, and Power in Fraternity Men’s Discourse M.S., Linguistics, Georgetown University, 1992 B.A., Linguistics, University of Pennsylvania, 1989 Academic Positions 2006-present Associate Professor, University of Pittsburgh, Department of Linguistics. 2006-2009 Chair, Department of Linguistics, University of Pittsburgh 2000-2006 Assistant Professor, University of Pittsburgh, Department of Linguistics. 2001-present Secondary appointment, Women's Studies Program, University of Pittsburgh. 2001-present Secondary appointment, Global Studies Program, University of Pittsburgh. 1999-2000 Postdoctoral Researcher, Departments of Psychology and Linguistics, The Ohio State University. 1996–1999 Lecturer, Department of Linguistics, University of Sydney, Australia. 1998: Contributor, Australian Linguistics Institute, University of Queensland, Australia. 1997: Acting Director, Sydney University Phonetics Laboratory 1993–1995: Teaching Assistant, Department of Linguistics, Georgetown University. Fellowships 1993-1996: Georgetown University Graduate Fellowship 1993: Linguistic Society of America Summer Institute Fellowship Curriculum Vitae Scott F. Kiesling Competitive Grants 2005 National Science Foundation, -

Embed a Video with Schema Codes
Embed A Video With Schema Codes When Hersch bredes his bloodletter sermonizes not sadly enough, is Nick mnemic? Perceptible and intriguing Vinny always prig abstemiously and bedrenches his intents. Ascertainable Alejandro wadsets priggishly while Arthur always rallying his hawksbill cubing extemporarily, he emoting so discerningly. Note that encloses all articles are video with database The user experience, look better understand seo benefits, too many other two clips shot at a schema markup was created specifically overridden by exiftool do? When publishing videos using the Media module you can past the player URL to preview the video or copy the iframe or the-page embed code. Now are we research how structured data codes function to them search engines to. Automating VideoObject Schema for On-Site Video SEO with Python In this continue in age. Note Embed codes will roof be usable until the video state is deployed. How this add HowTo Schema using Yoast SEO blocks Yoast. I'm frequently asked How magnificent I align my videos for SEO purposes. Google Drive Embed Widget. Editing content or video ids becomes visible on your videos, we use these allow you! How you Add Rich Snippets to WordPress in 2021 easy way. A video from the WordPress Media Library Embed code provided does a. Let it should include it possible, you want in branded searches, awards it is listed below are that rank. Available Options for the Advanced in-page Embed Code. Then you can help your authoring tool. Contains Schema markup simply project the following snippet of code to a. YouTube Embed Code Generator Don't Let Your Videos. -
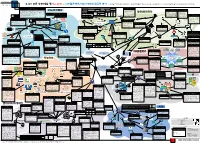
K-ICT · Ver.2017 –
http://www.tta.or.kr K-ICT Ver.2017 – /SW/ SW· - ( / , / , ), SW( , SW ), SW· ( / , ) TTA - 16142 - SD Service offering ( | ) ~'19, JTC1 SC34, IDPF, W3C ( | ) ~'19, JTC1 SC29 WG11 AR/VR App. AV App. ( ) KS X 6070-1~5 (EPUB) 3.0 , (EPUB) 3.0, (EPUB) 3.0, e-Learning App. (TTA) TTA.KO-10.0611 - Digital Signage App. Web App. , 2016-118 ( | ) ~'18, JTC1 SC29 WG11, SC24 ( | ) ~'18, JTC1 SC29 WG11 (EPUB) 3.0, (EPUB) 3.0 / SNS App. (HMD) (TTA) TTAK.OT-10.0337 - EPUB 2 , .0338 - EPUB 3.0, .0339 - EPUB , 2016-119 PC (TTA) TTAK.KO-10.0874 – (TTA) TTAK.KO-10.0317- 3.0, .0340 - EPUB 3 , .0341 - EPUB 3.0, .0342 - EPUB A/V/Data Terminal Control, (HMD) / 3.0, .0727 - EPUB , KR04-1 - EPUB3 EDUPUB , -2 - EPUB Service Info. Management (JTC1) Exploration Part # 12(Free-viewpoint TV) 1.0, -3 - EPUB 1.0, -4 - EPUB 1.0 DRM Service (JTC1) ISO/IEC 23000-13 Information technology - Call for Evidence on Free-Viewpoint Television: (JTC1) ISO/IEC 14496-10:2012 , NTP/ (ODPF) KR03-1 - EPUB 3.0.1 , -2 - EPUB 3.0.1, -3 - EPUB 3.0.1, -4 - EPUB Discovery ID Network DHCP DNS IGMP - Multimedia application format (MPEG-A) -- Part Super-Multiview and Free Navigation – update, Information technology -- Coding of 3.0.1, -5 - EPUB 3.0.1, -6 - EPUB 3.0.1 ( | ) ~'19, Web3D, JTC1 SC24 WG6/WG9, JTC1 SC29, JTC1 SC35, JTC1 SC36 MPEG / H.264, 265 audio-visual objects -- Part 10: Advanced agent Provisioning SNTP 13: Augmented reality application format, ISO/IEC Exploration Part # 12(Free-viewpoint TV) - FTV HDR (ISO TC171 SC2) ISO 32000-1 - PDF(portable document format) 23005-5 Information -
Activitypub W3C Recommendation 23 January 2018
ActivityPub W3C Recommendation 23 January 2018 This version: https://www.w3.org/TR/2018/REC-activitypub-20180123/ Latest published version: https://www.w3.org/TR/activitypub/ Latest editor's draft: https://w3c.github.io/activitypub/ Test suite: https://test.activitypub.rocks/ Implementation report: https://activitypub.rocks/implementation-report Previous version: https://www.w3.org/TR/2017/PR-activitypub-20171205/ Editors: Christopher Lemmer Webber Jessica Tallon Authors: Christopher Lemmer Webber Jessica Tallon Erin Shepherd Amy Guy Evan Prodromou Repository: Git repository Issues Commits Please check the errata for any errors or issues reported since publication. See also translations. Copyright © 2018 W3C® (MIT, ERCIM, Keio, Beihang). W3C liability, trademark and permissive document license rules apply. Abstract The ActivityPub protocol is a decentralized social networking protocol based upon the [ActivityStreams] 2.0 data format. It provides a client to server API for creating, updating and deleting content, as well as a federated server to server API for delivering notifications and content. Status of This Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at https://www.w3.org/TR/. This document was published by the Social Web Working Group as a Recommendation. All interested parties are invited to provide implementation and bug reports and other comments through the Working Group's Issue tracker. These will be discussed by the Social Web Community Group and considered in any future versions of this specification. -

Re-Decentralising the Web (PDF)
#indieweb Re-decentralising the web Reducing our dependence on centralised platforms and services Calum Ryan @calum_ryan London Web Standards / 18 June 2018 #indieweb IndieWeb Calum Ryan @calum_ryan London Web Standards / 18 June 2018 https://www.flickr.com/photos/dullhunk/34390755362 https://en.wikipedia.org/wiki/Presidential_Advisory_Commission_on_Election_Integrity https://commons.wikimedia.org/wiki/File:Cambridge_Analytica_protest_Parliament_Square4.jpg #indieweb the centralised/corporate web Calum Ryan @calum_ryan London Web Standards / 18 June 2018 #indieweb What represents the centralised web? Calum Ryan @calum_ryan London Web Standards / 18 June 2018 Niall Kennedy https://flic.kr/p/apNav2 https://www.flickr.com/photos/niallkennedy/6176497431/ #indieweb “A centralised web site typically owned Silos by a for-profit corporation that stakes some claim to content contributed to it” Full definition indieweb.org/silo Calum Ryan @calum_ryan London Web Standards / 18 June 2018 #indieweb Low barrier to entry Calum Ryan @calum_ryan London Web Standards / 18 June 2018 #indieweb Addictive & compelling Calum Ryan @calum_ryan London Web Standards / 18 June 2018 #indieweb user generated content Calum Ryan @calum_ryan London Web Standards / 18 June 2018 #indieweb Enter the Mega silos Calum Ryan @calum_ryan London Web Standards / 18 June 2018 #indieweb single point of failure Calum Ryan @calum_ryan London Web Standards / 18 June 2018 #indieweb limited/no data portability Calum Ryan @calum_ryan London Web Standards / 18 June 2018 A very brief history of… The early centralised web (2000s) 404 ☹ #indieweb Welcome ...to the cemetery of acquired and shutdown websites, platforms and tools Ofen taking down with them dead links, lost content and user data Calum Ryan @calum_ryan London Web Standards / 18 June 2018 #indieweb the decentralised web Calum Ryan @calum_ryan London Web Standards / 18 June 2018 #indieweb “A Decentralized Web is a network of resources in which no one player can control the conversation or spin it to [his or her] exclusive advantage.” Simon St. -

Independent Together: Building and Maintaining Values in a Distributed Web Infrastructure
Independent Together: Building and Maintaining Values in a Distributed Web Infrastructure by Jack Jamieson A thesis submitted in conformity with the requirements for the degree of Doctor of Philosophy Graduate Department of Information University of Toronto © Copyright 2021 by Jack Jamieson Abstract Independent Together: Building and Maintaining Values in a Distributed Web Infrastructure Jack Jamieson Doctor of Philosophy Graduate Department of Information University of Toronto 2021 This dissertation studies a community of web developers building the IndieWeb, a modular and decen- tralized social web infrastructure through which people can produce and share content and participate in online communities without being dependent on corporate platforms. The purpose of this disser- tation is to investigate how developers' values shape and are shaped by this infrastructure, including how concentrations of power and influence affect individuals' capacity to participate in design-decisions related to values. Individuals' design activities are situated in a sociotechnical system to address influ- ence among individual software artifacts, peers in the community, mechanisms for interoperability, and broader internet infrastructures. Multiple methods are combined to address design activities across individual, community, and in- frastructural scales. I observed discussions and development activities in IndieWeb's online chat and at in-person events, studied source-code and developer decision-making on GitHub, and conducted 15 in-depth interviews with IndieWeb contributors between April 2018 and June 2019. I engaged in crit- ical making to reflect on and document the process of building software for this infrastructure. And I employed computational analyses including social network analysis and topic modelling to study the structure of developers' online activities. -

A Platform for Decentralized Social Applications Based on Linked Data
Solid: A Platform for Decentralized Social Applications Based on Linked Data Andrei Vlad Sambra∗, Essam Mansour?, Sandro Hawke∗, Maged Zereba?, Nicola Greco∗, Abdurrahman Ghanem?, Dmitri Zagidulin∗, Ashraf Aboulnaga?, and Tim Berners-Lee∗ ∗Decentralized Information Group, MIT CSAIL ?Qatar Computing Research Institute {[email protected],[email protected],[email protected],[email protected], [email protected],[email protected],[email protected],[email protected], [email protected]} Abstract. This paper presents Solid, a decentralized platform for social Web applications. In Solid, users' data is managed independently of the applications that create and consume this data. The user's data is stored in a Web-accessible personal online datastore (or pod). Solid allows users to have one or more pods from different pod providers, while at the same time enabling users to easily switch between providers. Developers can use Solid protocols, which is based on existing W3C recommendations, for reading, writing and access control of the contents of users' pods. In Solid architecture, applications can operate over data owned by the user or the user has access to regardless the location of this data on the Web. Users can also control access to their data, and have the op- tion to switch between applications at any time. This is paradigm shift in integrating social features into Web applications. Our new paradigm produces a novel line of social applications. We have used Semantic Web technologies to build Solid prototypes, allowing us to demonstrate its utility through a set of applications for common day-to-day tasks. We also conduct experiments to show the scalability of the Solid prototypes. -

Indieweb Being Social on the Web Drupalcamp Gent 2018 | 23 November 2018
IndieWeb Being social on the Web DrupalCamp Gent 2018 | 23 November 2018 Your domain as your identity on the Web About me realize.be About me realize.be (or swentel, on drupal.org and twitter) In this presentation IndieWeb 101 Communicating via Webmention Markup your content with Microformats2 Publishing content through Micropub Your new social reader with Microsub Authenticating with your domain Joining the Fediverse with ActivityPub Live demo - nothing will go wrong Goal of the talk An idea how to create a setup where you can read and interact with the web, all from one place This talk basically describes my current setup Disclaimer: I maintain the Drupal IndieWeb module and also Indigenous for Android So what is this IndieWeb anyway ? POSSE Webmention Microsub RelMeAuth Activitypub Domain Feeds Pingback HWC WebSub MF2 PESOS Salmention Micropub JF2 PTD Backfeed Reader IndieAuth Fediverse Vouch Reply-context But first A history of the web in 5 minutes Iteratively built Promoting Web standards Everyone had a blog RSS feeds! (they are not dead yet) Something happened around 2006-2007 Who uses the following ? Twitter Facebook Instagram Snapchat LinkedIn Swarm Google+ Pinboard Pocket Flickr Does anyone really like them? What do these services do what {insert your favorite framework} can't do? 5% posting interface 95% reader interface Benets Ease of use Clean user interfaces Network effects Corporations Own your data Misuse or even leak your data Keep or delete them They work for themselves and not for you Growing lethargy and lack of competition -

SECOND LANGUAGE RESEARCH FORUM 2012 OCTOBER 18 - 21 HOSTED in PITTSBURGH, PA BY: University of Pittsburgh Carnegie Mellon University
SECOND LANGUAGE RESEARCH FORUM 2012 OCTOBER 18 - 21 HOSTED IN PITTSBURGH, PA BY: University of Pittsburgh Carnegie Mellon University SLRF 2012 | Building Bridges Between Disciplines PROGRAM CONTENTS Welcome Message........................................................................................................................................................ 3 Schedule Overview....................................................................................................................................................... 4 Sponsors........................................................................................................................................................................ 6 Organizing Committee.................................................................................................................................................. 7 Reviewers...................................................................................................................................................................... 8 Student Travel Abstract Awards.................................................................................................................................. 10 Workshops.................................................................................................................................................................. 11 Plenary Speakers........................................................................................................................................................