A Framework for Exploring the Evolutionary Roots of Creativity
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

“Laboratório” De T V Digital Usando Softw Are Open Source
“Laboratório” de TV digital usando software open source Objectivos Realizar uma pesquisa de software Open Source, nomeadamente o que está disponível em Sourceforge.net relacionado com a implementação de operações de processamento de sinais audiovisuais que tipicamente existem em sistemas de produção de TV digital. Devem ser identificadas aplicações para: • aquisição de vídeo, som e imagem • codificação com diferentes formatos (MPEG-2, MPEG-4, JPEG, etc.) • conversão entre formatos • pré e pós processamento (tal como filtragens) • edição • anotação Instalação dos programas e teste das suas funcionalidades. Linux Aquisição Filtros Codificação :: VLC :: Xine :: Ffmpeg :: Kino (DV) :: VLC :: Transcode :: Tvtime Television Viewer (TV) :: Video4Linux Grab Edição :: Mpeg4IP :: Kino (DV) Conversão :: Jashaka :: Kino :: Cinelerra :: VLC Playback :: Freej :: VLC :: FFMpeg :: Effectv :: MJPEG Tools :: PlayerYUV :: Lives :: Videometer :: MPlayer Anotação :: Xmovie :: Agtoolkit :: Video Squirrel VLC (VideoLan Client) VLC - the cross-platform media player and streaming server. VLC media player is a highly portable multimedia player for various audio and video formats (MPEG-1, MPEG-2, MPEG-4, DivX, mp3, ogg, ...) as well as DVDs, VCDs, and various streaming protocols. It can also be used as a server to stream in unicast or multicast in IPv4 or IPv6 on a high-bandwidth network. http://www.videolan.org/ Kino (DV) Kino is a non-linear DV editor for GNU/Linux. It features excellent integration with IEEE-1394 for capture, VTR control, and recording back to the camera. It captures video to disk in Raw DV and AVI format, in both type-1 DV and type-2 DV (separate audio stream) encodings. http://www.kinodv.org/ Tvtime Television Viewer (TV) Tvtime is a high quality television application for use with video capture cards on Linux systems. -

Multimedia Systems DCAP303
Multimedia Systems DCAP303 MULTIMEDIA SYSTEMS Copyright © 2013 Rajneesh Agrawal All rights reserved Produced & Printed by EXCEL BOOKS PRIVATE LIMITED A-45, Naraina, Phase-I, New Delhi-110028 for Lovely Professional University Phagwara CONTENTS Unit 1: Multimedia 1 Unit 2: Text 15 Unit 3: Sound 38 Unit 4: Image 60 Unit 5: Video 102 Unit 6: Hardware 130 Unit 7: Multimedia Software Tools 165 Unit 8: Fundamental of Animations 178 Unit 9: Working with Animation 197 Unit 10: 3D Modelling and Animation Tools 213 Unit 11: Compression 233 Unit 12: Image Format 247 Unit 13: Multimedia Tools for WWW 266 Unit 14: Designing for World Wide Web 279 SYLLABUS Multimedia Systems Objectives: To impart the skills needed to develop multimedia applications. Students will learn: z how to combine different media on a web application, z various audio and video formats, z multimedia software tools that helps in developing multimedia application. Sr. No. Topics 1. Multimedia: Meaning and its usage, Stages of a Multimedia Project & Multimedia Skills required in a team 2. Text: Fonts & Faces, Using Text in Multimedia, Font Editing & Design Tools, Hypermedia & Hypertext. 3. Sound: Multimedia System Sounds, Digital Audio, MIDI Audio, Audio File Formats, MIDI vs Digital Audio, Audio CD Playback. Audio Recording. Voice Recognition & Response. 4. Images: Still Images – Bitmaps, Vector Drawing, 3D Drawing & rendering, Natural Light & Colors, Computerized Colors, Color Palletes, Image File Formats, Macintosh & Windows Formats, Cross – Platform format. 5. Animation: Principle of Animations. Animation Techniques, Animation File Formats. 6. Video: How Video Works, Broadcast Video Standards: NTSC, PAL, SECAM, ATSC DTV, Analog Video, Digital Video, Digital Video Standards – ATSC, DVB, ISDB, Video recording & Shooting Videos, Video Editing, Optimizing Video files for CD-ROM, Digital display standards. -

Kubuntu Desktop Guide
Kubuntu Desktop Guide Ubuntu Documentation Project <[email protected]> Kubuntu Desktop Guide by Ubuntu Documentation Project <[email protected]> Copyright © 2004, 2005, 2006 Canonical Ltd. and members of the Ubuntu Documentation Project Abstract The Kubuntu Desktop Guide aims to explain to the reader how to configure and use the Kubuntu desktop. Credits and License The following Ubuntu Documentation Team authors maintain this document: • Venkat Raghavan The following people have also have contributed to this document: • Brian Burger • Naaman Campbell • Milo Casagrande • Matthew East • Korky Kathman • Francois LeBlanc • Ken Minardo • Robert Stoffers The Kubuntu Desktop Guide is based on the original work of: • Chua Wen Kiat • Tomas Zijdemans • Abdullah Ramazanoglu • Christoph Haas • Alexander Poslavsky • Enrico Zini • Johnathon Hornbeck • Nick Loeve • Kevin Muligan • Niel Tallim • Matt Galvin • Sean Wheller This document is made available under a dual license strategy that includes the GNU Free Documentation License (GFDL) and the Creative Commons ShareAlike 2.0 License (CC-BY-SA). You are free to modify, extend, and improve the Ubuntu documentation source code under the terms of these licenses. All derivative works must be released under either or both of these licenses. This documentation is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE AS DESCRIBED IN THE DISCLAIMER. Copies of these licenses are available in the appendices section of this book. Online versions can be found at the following URLs: • GNU Free Documentation License [http://www.gnu.org/copyleft/fdl.html] • Attribution-ShareAlike 2.0 [http://creativecommons.org/licenses/by-sa/2.0/] Disclaimer Every effort has been made to ensure that the information compiled in this publication is accurate and correct. -

Video Editing
SIG Linux / Open Source Software Video Editing Antonio Misaka Sept 10, 2014 Video Editing Agenda ● Video Editors ● Kdenlive ● Kdenlive installation ● Kdenlive configuration ● Kdenlive demonstration Sept. 10, 2014 2/28 Video Editing Video Editors ● Cinelerra (Linux) ● Pitivi (Linux, FreeBSD) ● Kdenlive (Linux, FreeBSD, Mac OS X) ● Kino (Linux, FreeBSD) – Dead – Aug 2013 ● VideoLan Movie Creator – VLMC (Linux, Mac OS X, Windows) -> Unstable Sept. 10, 2014 3/28 Video Editing Cinelerra (Linux) ● Heroine Virtual ● Video editing and compositing software package ● Very high-fidelity audio and video ● Audio 64 bit of precision ● RGBA and YUVA color spaces ● Resolution and frame rate-independent Sept. 10, 2014 4/28 Video Editing Pitivi (Linux, FreeBSD) ● Collabora Multimedia ●1st video default movie editor with Ubuntu 10.04 (Lucid Lynx) ● Removed from Ubuntu 11.10 (Oneiric Ocelot) ● Gnome Foundation – February 2014 €100,000 Sept. 10, 2014 5/28 Video Editing Kdenlive (Linux, FreeBSD) ● All of the formats supported by Ffmpeg ● Supports 4:3 and 16:9 ● Aspect ratios for both PAL, NTSC and various HD standards ● Current version 0.9.8 Sept. 10, 2014 6/28 Video Editing Installation Sept. 10, 2014 7/28 Video Editing Installation Sept. 10, 2014 8/28 Video Editing Configuration Sept. 10, 2014 9/28 Video Editing Configuration Sept. 10, 2014 10/28 Video Editing Configuration Sept. 10, 2014 11/28 Video Editing Configuration Sept. 10, 2014 12/28 Video Editing Configuration Sept. 10, 2014 13/28 Video Editing Configuration Sept. 10, 2014 14/28 Video Editing Configuration Sept. 10, 2014 15/28 Video Editing Configuration Sept. 10, 2014 16/28 Video Editing Configuration Sept. -

LIFE Packages
LIFE packages Index Office automation Desktop Internet Server Web developpement Tele centers Emulation Health centers Graphics High Schools Utilities Teachers Multimedia Tertiary schools Programming Database Games Documentation Internet - Firefox - Browser - Epiphany - Nautilus - Ftp client - gFTP - Evolution - Mail client - Thunderbird - Internet messaging - Gaim - Gaim - IRC - XChat - Gaim - VoIP - Skype - Videomeeting - Gnome meeting - GnomeBittorent - P2P - aMule - Firefox - Download manager - d4x - Telnet - Telnet Web developpement - Quanta - Bluefish - HTML editor - Nvu - Any text editor - HTML galerie - Album - Web server - XAMPP - Collaborative publishing system - Spip Desktop - Gnome - Desktop - Kde - Xfce Graphics - Advanced image editor - The Gimp - KolourPaint - Simple image editor - gPaint - TuxPaint - CinePaint - Video editor - Kino - OpenOffice Draw - Vector vraphics editor - Inkscape - Dia - Diagram editor - Kivio - Electrical CAD - Electric - 3D modeller/render - Blender - CAD system - QCad Utilities - Calculator - gCalcTool - gEdit - gxEdit - Text editor - eMacs21 - Leafpad - Application finder - Xfce4-appfinder - Desktop search tool - Beagle - File explorer - Nautilus -Archive manager - File-Roller - Nautilus CD Burner - CD burner - K3B - GnomeBaker - Synaptic - System updates - apt-get - IPtables - Firewall - FireStarter - BackupPC - Backup - Amanda - gnome-terminal - Terminal - xTerm - xTerminal - Scanner - Xsane - Partition editor - gParted - Making image of disks - Partitimage - Mirroring over network - UDP Cast -
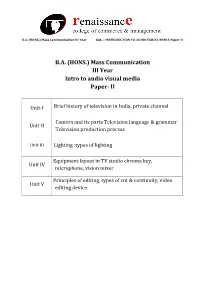
Mass Communication III Year Intro to Audio Visual Media Paper- II
B.A. (HONS.) Mass Communication III Year Sub. – INTRODUCTION TO AUDIO VISUAL MEDIA Paper II B.A. (HONS.) Mass Communication III Year Intro to audio visual media Paper- II Unit-I Brief history of television in India, private channel Camera and its parts Television language & grammar Unit-II Television production process Unit III Lighting :types of lighting Equipment layout in TV studio chroma key, Unit IV microphone, vision mixer Principles of editing, types of cut & continuity, video Unit V editing device B.A. (HONS.) Mass Communication III Year Sub. – INTRODUCTION TO AUDIO VISUAL MEDIA Paper II Unit-I Brief history of television in India, private channel Television came to India on September 15, 1959 with experimental transmission from Delhi. It was a modest beginning with a make shift studio, a low power transmitter and only 21 community television sets.All India Radio provided the engineering and programme professionals. A daily one-hour service with a news bulletin was started in 1965. In1972 television services were extended to a second city—Mumbai. By1975 television stations came up in Calcutta, Chennai, Srinagar, Amritsar and Lucknow. In 1975-76 the Satellite Instructional Television Experiment brought television programmes for people in 2400 villages inthe most inaccessible of the least developed areas tlirough a satellite lentto India for one year.Doordarshan is a Public broadcast terrestrial ltelevision channel run by Prasar Bharati, a board formedby the Government of India. It is one of the largest broadcasting organizations in the world in terms of the of studios and transmitters. Doordarshanhad its beginning with the experimental telecast started in Delhi in September, 1959 with a small transmitter and a makeshift studio. -

A Comparative Study of the First Computer Literacy Programs for Children in the United States, France, and the Soviet Union, 1970-1990
Making Citizens of the Information Age: A Comparative Study of the First Computer Literacy Programs for Children in the United States, France, and the Soviet Union, 1970-1990 The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Boenig-Liptsin, Margarita. 2015. Making Citizens of the Information Age: A Comparative Study of the First Computer Literacy Programs for Children in the United States, France, and the Soviet Union, 1970-1990. Doctoral dissertation, Harvard University, Graduate School of Arts & Sciences. Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:23845438 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA Making Citizens of the Information Age: A comparative study of the first computer literacy programs for children in the United States, France, and the Soviet Union, 1970-1990 A dissertation presented by Margarita Boenig-Liptsin to The Department of History of Science in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the subject of History of Science Harvard University Cambridge, Massachusetts August 2015 © 2015 Margarita Boenig-Liptsin All rights reserved. Dissertation Advisor: Professor Sheila Jasanoff Margarita Boenig-Liptsin Making Citizens of the Information Age: A comparative study of the first computer literacy programs for children in the United States, France, and the Soviet Union, 1970-1990 ABSTRACT In this dissertation I trace the formation of citizens of the information age by comparing visions and practices to make children and the general public computer literate or cultured in the United States, France, and the Soviet Union. -

The Current State of Linux Video Production Software and Its Developer Community
The Current State of Linux Video Production Software and its Developer Community Richard Spindler Schönau 75 6323, Bad Häring, Austria [email protected] Abstract At the time it was started, there were two potential applications available that could have According to Linux and Open Source/Free been used instead of starting a new project. Those Software thought leaders, the current situation in 1 2 Linux video editing and production software still two options were Cinelerra and Kino which were leaves a lot to be desired. Here we give an accurate already quite mature and widely used at that time. overview of the software that is already being However for the needs of the author, Kino was too developed for Linux video editing, or that is simple to support the kind of workflow that he currently being worked on. We will introduce the anticipated, and Cinelerra was too complex to developers or/and the development communities teach quickly to his collaborators. They were not that are behind these projects, and how the only choices, as new editing applications collaboration between projects works. We will emerged, likely because other Free Software mention interesting events and places where Linux enthusiasts were finding themselves in a similar video developers meet, and what groups might be dilemma. Those however, were also very much at interested in our work, or ought to be involved into a starting point of development, and far from being specific aspects of our work. We will outline mature enough for general use. where projects are still lacking to support specific use cases, and why they matter. -

1. Why POCS.Key
Symptoms of Complexity Prof. George Candea School of Computer & Communication Sciences Building Bridges A RTlClES A COMPUTER SCIENCE PERSPECTIVE OF BRIDGE DESIGN What kinds of lessonsdoes a classical engineering discipline like bridge design have for an emerging engineering discipline like computer systems Observation design?Case-study editors Alfred Spector and David Gifford consider the • insight and experienceof bridge designer Gerard Fox to find out how strong the parallels are. • bridges are normally on-time, on-budget, and don’t fall ALFRED SPECTORand DAVID GIFFORD • software projects rarely ship on-time, are often over- AS Gerry, let’s begin with an overview of THE DESIGN PROCESS bridges. AS What is the procedure for designing and con- GF In the United States, most highway bridges are budget, and rarely work exactly as specified structing a bridge? mandated by a government agency. The great major- GF It breaks down into three phases: the prelimi- ity are small bridges (with spans of less than 150 nay design phase, the main design phase, and the feet) and are part of the public highway system. construction phase. For larger bridges, several alter- There are fewer large bridges, having spans of 600 native designs are usually considered during the Blueprints for bridges must be approved... feet or more, that carry roads over bodies of water, preliminary design phase, whereas simple calcula- • gorges, or other large obstacles. There are also a tions or experience usually suffices in determining small number of superlarge bridges with spans ap- the appropriate design for small bridges. There are a proaching a mile, like the Verrazzano Narrows lot more factors to take into account with a large Bridge in New Yor:k. -

Videoredaktori Openshot 1.4.X Lühike Kasutamisjuhend
Arvo Mägi Videoredaktori OpenShot 1.4.x lühike kasutamisjuhend Tallinn, 2012 Saateks Videokaamerate hinnad on langenud ja turisti käes näeb videokaamerat juba peaaegu sama tihti kui digifotokaamerat. Videoredaktor on seetõttu tänapäeval muutunud sama tähtsaks rakendus- programmiks kui fotoredaktor. Linuxi jaoks on mitmeid videoredaktoreid (Kdenlive, Kino, Cinerella, LiVES, PiTiVi jt), kuid seni on nende kvaliteet ja/või kasutamismugavus jätnud soovida. Üks paremaid Linuxi videoredaktoreid on Kdenlive, mis on koostatud KDE 4.x töölaua jaoks. Ehkki seda saab kasutada ka koos GNOME töölauaga, paigaldatakse koos Kdenlivega palju KDE teeke. OpenShot on videoredaktor, mis on kirjutatud GNOME töölaua jaoks. Paljud peavad seda parimaks Linuxi videoredaktoriks. OpenShot on mittelineaarne (non-linear) videoredaktor, st selle abil saab videot redigeerida alates suvalisest kaadrist. Jonathan Thomas alustas projekti 2008. a augustis. Kasutusel on Python, GTK 2, MLT Framework (melt) ja konverteerimisprogramm ffmpeg. Kaht viimast kasutab ka Kdenlive. Ubuntu 12.04 varamutes on OpenShot 1.4.0, kuid ilmunud on juba 1.4.1 (mis oli vigane) ja 1.4.2, mis on Ubuntu 12.10 varamutes. Soovitatav on kasutada ppa-varamut, mis tagab uusima versiooni kasutamise. 3D tiitelslaidide tegemiseks tuleb paigaldada blender ja tavaliste tiitelslaidide teksti redigeerimiseks inkscape, mõlemad on Ubuntu varamutes. OpenShot toetab järgmisi videotüüpe: AVCHD, QuickTime, DVD, Xbox 360, Vimeo, Flickr, Picasa, YouTube, Nokia ja Metacafe. Kasutada saab järgmisi videovorminguid: Ogg Theora, MPEG-TS, MKV, ipod, vob, mov, mp4 ja mpeg. Üldine töö põhimõte on järgmine. Kaamera kõvakettalt või mälukaardilt laetakse vajalikud failid arvuti kõvakettale. Sealt laetakse käesoleva projekti jaoks vajalikud videofailid OpenShot projektiakna failinimistusse. Lisaks videofailidele saab projektis kasutada ka üksikslaide (fotosid) ja slaidikomplekte, tekstiga ja 3D tiitelslaide ning helifaile (nt taustamuusika). -

Videoediting with Kdenlive
Videoediting with Kdenlive Jürgen Weigert openSUSE video-dude Videoediting, what can we do? Basic tasks ... • Trim start and end of your footage • Add title and logo • Remove pause • Repair or patch up glitches in the recording • Effects: fade in, fade out, cross-fade © June 18, 2010 Novell Inc. 2 Videoediting, what can we do? (2) Advanced tasks • Synchronize to music, MTV-style • Compose multiple layers of video • Pick best material from repeated recordings • Forcing a pace or padding up • Assembling shots into scenes of a storybook • Animated titles and logos • “crazy” effekts ... © June 18, 2010 Novell Inc. 3 Videoediting, what can we do? (3) … Software-developers have fun • Yes, it crashes now and then. – Kdenlive saves its projects as XML files, which are really robust. • More features – it is still maturing – Kdenlive has advanced another version already.. • Bugs? - reproduce, report upstream, fix them – Kdenlive has many “simple” bugs © June 18, 2010 Novell Inc. 4 Why pick kdenlive? •Capture (aka Input) • dvgrab, bttvgrab, recordmydesktop, krecord, ... •Editing (aka Processing) • kino, broadcast2000, cinelerra, lumiera, jashaka, cinefx, LiVES, kdenlive ... •Postprocessing (aka Output) • mplayer/mencoder, dvdauthor, devede, k3b, ... © June 18, 2010 Novell Inc. 5 Why pick kdenlive? (2) This is what the websites say: kinodv.org “Easy and reliable DV editing for the Linux desktop” © June 18, 2010 Novell Inc. 6 Why pick kdenlive? (2) This is what the websites say: kinodv.org “Easy and reliable DV editing for the Linux desktop” Broadcast2000 “<?php default_page("It's not here anymore. Use <A HREF=\"cinelerra ...” cinelerra.org “Cinelerra is the most advanced non- linear video editor and compositor for Linux.” Lumiera “was born as a rewrite of the Cinelerra codebase. -

TROGUARD: Context-Aware Protec�On Against Web-Based Socially Engineered Trojans
TROGUARD: Context-Aware Protec6on Against Web-Based Socially Engineered Trojans Rui Han, Alejandro Mesa, University of Miami Mihai Christodorescu, QualComm Research Saman Zonouz, Rutgers University Mo#va#on • Waterfall screen saver Trojan 2 Mac OS threats Rank Name Percentage 1 Trojan.OSX.FakeCo.a 52% 2 Trojan-DownloaDer.OSX.Jahlav.d 8% 3 Trojan-DownloaDer.OSX.Flashfake.aI 7% 4 Trojan-DownloaDer.OSX.FavDonw.c 5% 5 Trojan-DownloaDer.OSX.FavDonw.a 2% 6 Trojan-DownloaDer.OSX.Flashfake.ab 2% 7 Trojan-FakeAV.OSX.Defma.gen 2% 8 Trojan-FakeAV.OSX.Defma.f 1% 9 Exploit.OSX.Smid.b 1% 10 Trojan-DownloaDer.OSX.Flashfake.af 1% McAfee an6virus solu6on: hVp:www.securelist.com 3 Example Malwares Malware Descripons Plaorm TrojanClicker.VB Trojan socially Windows engineered as adobe .395 flash update and Mac OS X Trojan or Adware socially Windows, Mac Faked An6-Virus engineered as an6-virus so]ware OS X, and Linux Malware socially Android Opfake Browser engineered as Opera Browser Legi6mate applicaons Mac OS X and WireLuker socially engineered with ad-wares and Trojan iOS 4 ContribUons • Answer the ques6on: “Is this program doing what I expected it to do?” • Bridge the seman6c gap between func6onality classes and low level behaviors • Built on 100 Linux app profiles • High detec6on rate on 50 Trojan apps 5 TROGUARD ArchItectUre TROGUARD Offline Dynamic Application Functionality Application Functionality Functionality Class Profile Database Feature Tracing Generation Extraction Application Functionality Profile Database Online Inference of Download Perceived