Dispensability of Mammalian DNA
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Efficacy and Mechanistic Evaluation of Tic10, a Novel Antitumor Agent
University of Pennsylvania ScholarlyCommons Publicly Accessible Penn Dissertations 2012 Efficacy and Mechanisticv E aluation of Tic10, A Novel Antitumor Agent Joshua Edward Allen University of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/edissertations Part of the Oncology Commons Recommended Citation Allen, Joshua Edward, "Efficacy and Mechanisticv E aluation of Tic10, A Novel Antitumor Agent" (2012). Publicly Accessible Penn Dissertations. 488. https://repository.upenn.edu/edissertations/488 This paper is posted at ScholarlyCommons. https://repository.upenn.edu/edissertations/488 For more information, please contact [email protected]. Efficacy and Mechanisticv E aluation of Tic10, A Novel Antitumor Agent Abstract TNF-related apoptosis-inducing ligand (TRAIL; Apo2L) is an endogenous protein that selectively induces apoptosis in cancer cells and is a critical effector in the immune surveillance of cancer. Recombinant TRAIL and TRAIL-agonist antibodies are in clinical trials for the treatment of solid malignancies due to the cancer-specific cytotoxicity of TRAIL. Recombinant TRAIL has a short serum half-life and both recombinant TRAIL and TRAIL receptor agonist antibodies have a limited capacity to perfuse to tissue compartments such as the brain, limiting their efficacy in certain malignancies. To overcome such limitations, we searched for small molecules capable of inducing the TRAIL gene using a high throughput luciferase reporter gene assay. We selected TRAIL-inducing compound 10 (TIC10) for further study based on its induction of TRAIL at the cell surface and its promising therapeutic index. TIC10 is a potent, stable, and orally active antitumor agent that crosses the blood-brain barrier and transcriptionally induces TRAIL and TRAIL-mediated cell death in a p53-independent manner. -

Nucleolin and Its Role in Ribosomal Biogenesis
NUCLEOLIN: A NUCLEOLAR RNA-BINDING PROTEIN INVOLVED IN RIBOSOME BIOGENESIS Inaugural-Dissertation zur Erlangung des Doktorgrades der Mathematisch-Naturwissenschaftlichen Fakultät der Heinrich-Heine-Universität Düsseldorf vorgelegt von Julia Fremerey aus Hamburg Düsseldorf, April 2016 2 Gedruckt mit der Genehmigung der Mathematisch-Naturwissenschaftlichen Fakultät der Heinrich-Heine-Universität Düsseldorf Referent: Prof. Dr. A. Borkhardt Korreferent: Prof. Dr. H. Schwender Tag der mündlichen Prüfung: 20.07.2016 3 Die vorgelegte Arbeit wurde von Juli 2012 bis März 2016 in der Klinik für Kinder- Onkologie, -Hämatologie und Klinische Immunologie des Universitätsklinikums Düsseldorf unter Anleitung von Prof. Dr. A. Borkhardt und in Kooperation mit dem ‚Laboratory of RNA Molecular Biology‘ an der Rockefeller Universität unter Anleitung von Prof. Dr. T. Tuschl angefertigt. 4 Dedicated to my family TABLE OF CONTENTS 5 TABLE OF CONTENTS TABLE OF CONTENTS ............................................................................................... 5 LIST OF FIGURES ......................................................................................................10 LIST OF TABLES .......................................................................................................12 ABBREVIATION .........................................................................................................13 ABSTRACT ................................................................................................................19 ZUSAMMENFASSUNG -

Análise Integrativa De Perfis Transcricionais De Pacientes Com
UNIVERSIDADE DE SÃO PAULO FACULDADE DE MEDICINA DE RIBEIRÃO PRETO PROGRAMA DE PÓS-GRADUAÇÃO EM GENÉTICA ADRIANE FEIJÓ EVANGELISTA Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas Ribeirão Preto – 2012 ADRIANE FEIJÓ EVANGELISTA Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas Tese apresentada à Faculdade de Medicina de Ribeirão Preto da Universidade de São Paulo para obtenção do título de Doutor em Ciências. Área de Concentração: Genética Orientador: Prof. Dr. Eduardo Antonio Donadi Co-orientador: Prof. Dr. Geraldo A. S. Passos Ribeirão Preto – 2012 AUTORIZO A REPRODUÇÃO E DIVULGAÇÃO TOTAL OU PARCIAL DESTE TRABALHO, POR QUALQUER MEIO CONVENCIONAL OU ELETRÔNICO, PARA FINS DE ESTUDO E PESQUISA, DESDE QUE CITADA A FONTE. FICHA CATALOGRÁFICA Evangelista, Adriane Feijó Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas. Ribeirão Preto, 2012 192p. Tese de Doutorado apresentada à Faculdade de Medicina de Ribeirão Preto da Universidade de São Paulo. Área de Concentração: Genética. Orientador: Donadi, Eduardo Antonio Co-orientador: Passos, Geraldo A. 1. Expressão gênica – microarrays 2. Análise bioinformática por module maps 3. Diabetes mellitus tipo 1 4. Diabetes mellitus tipo 2 5. Diabetes mellitus gestacional FOLHA DE APROVAÇÃO ADRIANE FEIJÓ EVANGELISTA Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas. -

Supp Material.Pdf
Simon et al. Supplementary information: Table of contents p.1 Supplementary material and methods p.2-4 • PoIy(I)-poly(C) Treatment • Flow Cytometry and Immunohistochemistry • Western Blotting • Quantitative RT-PCR • Fluorescence In Situ Hybridization • RNA-Seq • Exome capture • Sequencing Supplementary Figures and Tables Suppl. items Description pages Figure 1 Inactivation of Ezh2 affects normal thymocyte development 5 Figure 2 Ezh2 mouse leukemias express cell surface T cell receptor 6 Figure 3 Expression of EZH2 and Hox genes in T-ALL 7 Figure 4 Additional mutation et deletion of chromatin modifiers in T-ALL 8 Figure 5 PRC2 expression and activity in human lymphoproliferative disease 9 Figure 6 PRC2 regulatory network (String analysis) 10 Table 1 Primers and probes for detection of PRC2 genes 11 Table 2 Patient and T-ALL characteristics 12 Table 3 Statistics of RNA and DNA sequencing 13 Table 4 Mutations found in human T-ALLs (see Fig. 3D and Suppl. Fig. 4) 14 Table 5 SNP populations in analyzed human T-ALL samples 15 Table 6 List of altered genes in T-ALL for DAVID analysis 20 Table 7 List of David functional clusters 31 Table 8 List of acquired SNP tested in normal non leukemic DNA 32 1 Simon et al. Supplementary Material and Methods PoIy(I)-poly(C) Treatment. pIpC (GE Healthcare Lifesciences) was dissolved in endotoxin-free D-PBS (Gibco) at a concentration of 2 mg/ml. Mice received four consecutive injections of 150 μg pIpC every other day. The day of the last pIpC injection was designated as day 0 of experiment. -

Whole Exome Sequencing in Families at High Risk for Hodgkin Lymphoma: Identification of a Predisposing Mutation in the KDR Gene
Hodgkin Lymphoma SUPPLEMENTARY APPENDIX Whole exome sequencing in families at high risk for Hodgkin lymphoma: identification of a predisposing mutation in the KDR gene Melissa Rotunno, 1 Mary L. McMaster, 1 Joseph Boland, 2 Sara Bass, 2 Xijun Zhang, 2 Laurie Burdett, 2 Belynda Hicks, 2 Sarangan Ravichandran, 3 Brian T. Luke, 3 Meredith Yeager, 2 Laura Fontaine, 4 Paula L. Hyland, 1 Alisa M. Goldstein, 1 NCI DCEG Cancer Sequencing Working Group, NCI DCEG Cancer Genomics Research Laboratory, Stephen J. Chanock, 5 Neil E. Caporaso, 1 Margaret A. Tucker, 6 and Lynn R. Goldin 1 1Genetic Epidemiology Branch, Division of Cancer Epidemiology and Genetics, National Cancer Institute, NIH, Bethesda, MD; 2Cancer Genomics Research Laboratory, Division of Cancer Epidemiology and Genetics, National Cancer Institute, NIH, Bethesda, MD; 3Ad - vanced Biomedical Computing Center, Leidos Biomedical Research Inc.; Frederick National Laboratory for Cancer Research, Frederick, MD; 4Westat, Inc., Rockville MD; 5Division of Cancer Epidemiology and Genetics, National Cancer Institute, NIH, Bethesda, MD; and 6Human Genetics Program, Division of Cancer Epidemiology and Genetics, National Cancer Institute, NIH, Bethesda, MD, USA ©2016 Ferrata Storti Foundation. This is an open-access paper. doi:10.3324/haematol.2015.135475 Received: August 19, 2015. Accepted: January 7, 2016. Pre-published: June 13, 2016. Correspondence: [email protected] Supplemental Author Information: NCI DCEG Cancer Sequencing Working Group: Mark H. Greene, Allan Hildesheim, Nan Hu, Maria Theresa Landi, Jennifer Loud, Phuong Mai, Lisa Mirabello, Lindsay Morton, Dilys Parry, Anand Pathak, Douglas R. Stewart, Philip R. Taylor, Geoffrey S. Tobias, Xiaohong R. Yang, Guoqin Yu NCI DCEG Cancer Genomics Research Laboratory: Salma Chowdhury, Michael Cullen, Casey Dagnall, Herbert Higson, Amy A. -

Supplementary Table 3: Genes Only Influenced By
Supplementary Table 3: Genes only influenced by X10 Illumina ID Gene ID Entrez Gene Name Fold change compared to vehicle 1810058M03RIK -1.104 2210008F06RIK 1.090 2310005E10RIK -1.175 2610016F04RIK 1.081 2610029K11RIK 1.130 381484 Gm5150 predicted gene 5150 -1.230 4833425P12RIK -1.127 4933412E12RIK -1.333 6030458P06RIK -1.131 6430550H21RIK 1.073 6530401D06RIK 1.229 9030607L17RIK -1.122 A330043C08RIK 1.113 A330043L12 1.054 A530092L01RIK -1.069 A630054D14 1.072 A630097D09RIK -1.102 AA409316 FAM83H family with sequence similarity 83, member H 1.142 AAAS AAAS achalasia, adrenocortical insufficiency, alacrimia 1.144 ACADL ACADL acyl-CoA dehydrogenase, long chain -1.135 ACOT1 ACOT1 acyl-CoA thioesterase 1 -1.191 ADAMTSL5 ADAMTSL5 ADAMTS-like 5 1.210 AFG3L2 AFG3L2 AFG3 ATPase family gene 3-like 2 (S. cerevisiae) 1.212 AI256775 RFESD Rieske (Fe-S) domain containing 1.134 Lipo1 (includes AI747699 others) lipase, member O2 -1.083 AKAP8L AKAP8L A kinase (PRKA) anchor protein 8-like -1.263 AKR7A5 -1.225 AMBP AMBP alpha-1-microglobulin/bikunin precursor 1.074 ANAPC2 ANAPC2 anaphase promoting complex subunit 2 -1.134 ANKRD1 ANKRD1 ankyrin repeat domain 1 (cardiac muscle) 1.314 APOA1 APOA1 apolipoprotein A-I -1.086 ARHGAP26 ARHGAP26 Rho GTPase activating protein 26 -1.083 ARL5A ARL5A ADP-ribosylation factor-like 5A -1.212 ARMC3 ARMC3 armadillo repeat containing 3 -1.077 ARPC5 ARPC5 actin related protein 2/3 complex, subunit 5, 16kDa -1.190 activating transcription factor 4 (tax-responsive enhancer element ATF4 ATF4 B67) 1.481 AU014645 NCBP1 nuclear cap -

PDF Download
Ki-67 (ABT-KI67) mouse mAb Ready to use Catalog No : YM6189R Reactivity : Human, Mouse Applications : IHC-p,IF/ICC Gene Name : MKI67 Protein Name : Antigen KI-67 Human Gene Id : 4288 Human Swiss Prot P46013 No : Immunogen : Synthesized peptide derived from human Ki-67 Specificity : This antibody detects endogenous levels of human Ki-67. Heat-induced epitope retrieval (HIER) TRIS-EDTA of pH8.0 was highly recommended as antigen repair method in paraffin section Formulation : Liquid in PBS containing, 0.5% BSA and 0.02% sodium azide. Source : Mouse/IgG1, Kappa Dilution : Ready to use for IHC-p and IF Purification : The antibody was affinity-purified from mouse ascites by affinity- chromatography using specific immunogen. Storage Stability : 4°C/ 1 years Background : marker of proliferation Ki-67(MKI67) Homo sapiens This gene encodes a nuclear protein that is associated with and may be necessary for cellular proliferation. Alternatively spliced transcript variants have been described. A related pseudogene exists on chromosome X. [provided by RefSeq, Mar 2009], Function : developmental stage:Expression of this antigen occurs preferentially during late G1, S, G2 and M phases of the cell cycle, while in cells in G0 phase the antigen cannot be detected.,function:Thought to be required for maintaining cell 1 / 2 proliferation.,online information:Ki-67 entry,similarity:Contains 1 FHA domain.,subcellular location:Predominantly localized in the G1 phase in the perinucleolar region, in the later phases it is also detected throughout the nuclear interior, being predominantly localized in the nuclear matrix. In mitosis, it is present on all chromosomes.,subunit:Interacts with KIF15. -

UC San Diego UC San Diego Previously Published Works
UC San Diego UC San Diego Previously Published Works Title The nucleolar protein NIFK promotes cancer progression via CK1α/β-catenin in metastasis and Ki-67-dependent cell proliferation. Permalink https://escholarship.org/uc/item/8645k8vd Journal eLife, 5(MARCH2016) ISSN 2050-084X Authors Lin, Tsung-Chieh Su, Chia-Yi Wu, Pei-Yu et al. Publication Date 2016-03-17 DOI 10.7554/elife.11288 Peer reviewed eScholarship.org Powered by the California Digital Library University of California RESEARCH ARTICLE The nucleolar protein NIFK promotes cancer progression via CK1a/b-catenin in metastasis and Ki-67-dependent cell proliferation Tsung-Chieh Lin1†, Chia-Yi Su1†, Pei-Yu Wu2, Tsung-Ching Lai1, Wen-An Pan2,3, Yi-Hua Jan1, Yu-Chang Chang1, Chi-Tai Yeh4, Chi-Long Chen5,6, Luo-Ping Ger7, Hong-Tai Chang8,9, Chih-Jen Yang10, Ming-Shyan Huang10, Yu-Peng Liu11,12, Yuan-Feng Lin13, John Y-J Shyy14, Ming-Daw Tsai1,2*, Michael Hsiao1* 1Genomics Research Center, Academia Sinica, Taipei, Taiwan; 2Institute of Biological Chemistry, Academia Sinica, Taipei, Taiwan; 3Institute of Biochemical Sciences, National Taiwan University, Taipei, Taiwan; 4Department of Medical Research and Education, Taipei Medical University-Shuang Ho Hospital, New Taipei City, Taiwan; 5Department of Pathology, Taipei Medical University Hospital, Taipei Medical University, Taipei, Taiwan; 6Department of Pathology, College of Medicine, Taipei Medical University, Taipei, Taiwan; 7Department of Medical Education and Research, Kaohsiung Veterans General, Kaohsiung, Taiwan; 8Department of Surgery, -

Single Cell Multi-Omics Analysis of Chromothriptic Medulloblastoma Highlights Genomic and Transcriptomic Consequences of Genome Instability
bioRxiv preprint doi: https://doi.org/10.1101/2021.06.25.449944; this version posted June 25, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Single cell multi-omics analysis of chromothriptic medulloblastoma highlights genomic and transcriptomic consequences of genome instability R. Gonzalo Parra*1,2, Moritz J Przybilla*1,2,3, Milena Simovic*4,5, Hana Susak*1,2, Manasi Ratnaparkhe4, John KL Wong6, Verena Körber7, Philipp Mallm8, Martin Sill9, Thorsten Kolb4, Rithu Kumar4, Nicola Casiraghi1,2, David R Norali Ghasemi9, Kendra Korinna Maaß9, Kristian W Pajtler9,10, Anna Jauch11, Andrey Korshunov12, Thomas Höfer7, Marc Zapatka6, Stefan M Pfister9,10, Oliver Stegle*#1,2,3, Aurélie Ernst*#4 *These authors contributed equally (author order alphabetically) We suggest to define an explicit order among the first authors at a later stage, to make it as fair as possible also in the line of the revisions. #Corresponding authors 1European Molecular Biology Laboratory, Genome Biology Unit, Heidelberg, Germany. 2 Division of Computational Genomics and Systems Genetics, German Cancer Research Center (DKFZ), Heidelberg, Germany 3 Wellcome Sanger Institute, Wellcome Trust Genome Campus, Cambridge, UK 4 Group “Genome Instability in Tumors”, German Cancer Research Center (DKFZ), Heidelberg, Germany 5 Faculty of Biosciences, Heidelberg University 6 Division of Molecular Genetics, German Cancer Research Center (DKFZ), Heidelberg, Germany 7 Division of Theoretical Systems Biology, German Cancer Research Center (DKFZ), Heidelberg, Germany 8 Single-cell Open Lab, German Cancer Research Center (DKFZ) and Bioquant, Heidelberg, Germany 9 Hopp Children's Cancer Center (KiTZ), Heidelberg, Germany. -

Comparative Transcriptomics Reveals Similarities and Differences
Seifert et al. BMC Cancer (2015) 15:952 DOI 10.1186/s12885-015-1939-9 RESEARCH ARTICLE Open Access Comparative transcriptomics reveals similarities and differences between astrocytoma grades Michael Seifert1,2,5*, Martin Garbe1, Betty Friedrich1,3, Michel Mittelbronn4 and Barbara Klink5,6,7 Abstract Background: Astrocytomas are the most common primary brain tumors distinguished into four histological grades. Molecular analyses of individual astrocytoma grades have revealed detailed insights into genetic, transcriptomic and epigenetic alterations. This provides an excellent basis to identify similarities and differences between astrocytoma grades. Methods: We utilized public omics data of all four astrocytoma grades focusing on pilocytic astrocytomas (PA I), diffuse astrocytomas (AS II), anaplastic astrocytomas (AS III) and glioblastomas (GBM IV) to identify similarities and differences using well-established bioinformatics and systems biology approaches. We further validated the expression and localization of Ang2 involved in angiogenesis using immunohistochemistry. Results: Our analyses show similarities and differences between astrocytoma grades at the level of individual genes, signaling pathways and regulatory networks. We identified many differentially expressed genes that were either exclusively observed in a specific astrocytoma grade or commonly affected in specific subsets of astrocytoma grades in comparison to normal brain. Further, the number of differentially expressed genes generally increased with the astrocytoma grade with one major exception. The cytokine receptor pathway showed nearly the same number of differentially expressed genes in PA I and GBM IV and was further characterized by a significant overlap of commonly altered genes and an exclusive enrichment of overexpressed cancer genes in GBM IV. Additional analyses revealed a strong exclusive overexpression of CX3CL1 (fractalkine) and its receptor CX3CR1 in PA I possibly contributing to the absence of invasive growth. -
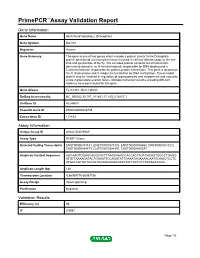
Download Validation Data
PrimePCR™Assay Validation Report Gene Information Gene Name dachshund homolog 2 (Drosophila) Gene Symbol DACH2 Organism Human Gene Summary This gene is one of two genes which encode a protein similar to the Drosophila protein dachshund a transcription factor involved in cell fate determination in the eye limb and genital disc of the fly. The encoded protein contains two characteristic dachshund domains: an N-terminal domain responsible for DNA binding and a C-terminal domain responsible for protein-protein interactions. This gene is located on the X chromosome and is subject to inactivation by DNA methylation. The encoded protein may be involved in regulation of organogenesis and myogenesis and may play a role in premature ovarian failure. Multiple transcript variants encoding different isoforms have been found for this gene. Gene Aliases FLJ31391, MGC138545 RefSeq Accession No. NC_000023.10, NT_011651.17, NG_012817.1 UniGene ID Hs.86603 Ensembl Gene ID ENSG00000126733 Entrez Gene ID 117154 Assay Information Unique Assay ID qHsaCID0009489 Assay Type SYBR® Green Detected Coding Transcript(s) ENST00000373131, ENST00000373125, ENST00000508860, ENST00000510272, ENST00000484479, ENST00000344497, ENST00000400297 Amplicon Context Sequence AGCAAGTGGAGCAGGCACTTAAGCAAGCCACCACTAGTGACAGTGGCCTGAGG ATGTTAAAAGATACTGGAATTCCAGATATTGAAATAGAAAACAATGGGACTCCTC ATGATAGTGCTGCTATGCAAGGAGGTAACTATTACTGTTTAGAAATGGC Amplicon Length (bp) 126 Chromosome Location X:86069775-86087136 Assay Design Intron-spanning Purification Desalted Validation Results Efficiency (%) -

Nº Ref Uniprot Proteína Péptidos Identificados Por MS/MS 1 P01024
Document downloaded from http://www.elsevier.es, day 26/09/2021. This copy is for personal use. Any transmission of this document by any media or format is strictly prohibited. Nº Ref Uniprot Proteína Péptidos identificados 1 P01024 CO3_HUMAN Complement C3 OS=Homo sapiens GN=C3 PE=1 SV=2 por 162MS/MS 2 P02751 FINC_HUMAN Fibronectin OS=Homo sapiens GN=FN1 PE=1 SV=4 131 3 P01023 A2MG_HUMAN Alpha-2-macroglobulin OS=Homo sapiens GN=A2M PE=1 SV=3 128 4 P0C0L4 CO4A_HUMAN Complement C4-A OS=Homo sapiens GN=C4A PE=1 SV=1 95 5 P04275 VWF_HUMAN von Willebrand factor OS=Homo sapiens GN=VWF PE=1 SV=4 81 6 P02675 FIBB_HUMAN Fibrinogen beta chain OS=Homo sapiens GN=FGB PE=1 SV=2 78 7 P01031 CO5_HUMAN Complement C5 OS=Homo sapiens GN=C5 PE=1 SV=4 66 8 P02768 ALBU_HUMAN Serum albumin OS=Homo sapiens GN=ALB PE=1 SV=2 66 9 P00450 CERU_HUMAN Ceruloplasmin OS=Homo sapiens GN=CP PE=1 SV=1 64 10 P02671 FIBA_HUMAN Fibrinogen alpha chain OS=Homo sapiens GN=FGA PE=1 SV=2 58 11 P08603 CFAH_HUMAN Complement factor H OS=Homo sapiens GN=CFH PE=1 SV=4 56 12 P02787 TRFE_HUMAN Serotransferrin OS=Homo sapiens GN=TF PE=1 SV=3 54 13 P00747 PLMN_HUMAN Plasminogen OS=Homo sapiens GN=PLG PE=1 SV=2 48 14 P02679 FIBG_HUMAN Fibrinogen gamma chain OS=Homo sapiens GN=FGG PE=1 SV=3 47 15 P01871 IGHM_HUMAN Ig mu chain C region OS=Homo sapiens GN=IGHM PE=1 SV=3 41 16 P04003 C4BPA_HUMAN C4b-binding protein alpha chain OS=Homo sapiens GN=C4BPA PE=1 SV=2 37 17 Q9Y6R7 FCGBP_HUMAN IgGFc-binding protein OS=Homo sapiens GN=FCGBP PE=1 SV=3 30 18 O43866 CD5L_HUMAN CD5 antigen-like OS=Homo