7. Aptitude and Achievement Tests: the Curious Case of the Indestructible Strawperson
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Department of Life Skills and Aptitude Training
Life / Communication and Aptitude Training Program The Life/Communication skills and Aptitude training program at Shivalik College of Engineering (SCE) is specially designed for SCE students who are aspiring to develop their professional competencies by sharpening their skills and knowledge. The ability to understand our own self and people better, communicate effectively, to manage interpersonal relationships, to manage meetings, to manage projects, to do a presentation, to lead a team or to solve a dispute among peers, is even more important than all our education or specialized knowledge in one single field. This course teaches and explains the basics of all soft skills and analytical mind that anyone should have in order to achieve personal excellence and accomplishing the goals more easily. The course is structured in several sections. This will be achieved by Interactive simulations, speed & mock tests, games, activities, group discussions, Individual presentations, Role Plays and videos. “All birds find shelter during a rain, but eagle avoids rain by flying above the clouds” — Dr. A.P.J Abdul Kalam Training Department aims at moulding the students so as to meet the industry expectations in career building and in turn bring laurels to the parent institution. The Training department prepares carefully laid down training schedule for the year, along with customized pre-placement training on the campus for various companies before their respective campus drives, and overseeing the process to its end, is the responsibility of the Training department. The department endeavors to carry out successfully all the processes methodically throughout the year. GOALS & OBJECTIVES GOALS • To enhance the employability skills among the students to meet out the corporate expectations. -

Gifted and Talented Identification
Gifted and Talented Identification Parent Handbook Carol Swalley, Administrator Thompson School District 1 Table of Contents Identification Process • Preface and Rationale • Definition • Types of Gifted • Search/Referral/Nomination/ • Gathering BOE/ Review BOE/ID Process • Program Match • Identification Process Flow Chart • Portability • Collecting a Body of Evidence • Student Profile of Body of Evidence • Types of Assessments • GT determination Types of Gifted • General Intellectual Ability • Specific Academic Aptitude with Cognitive Ability • Specific Academic Aptitude without Cognitive Ablility • Specific Talent including Creative, Leadership, Psychomotor, Visual and Performing Arts, Music Information • Resources • Question and Answer sheet, both English and Spanish • Dispute Resolution Process 2 Preface Like any field, the field of gifted and talented is always growing and changing with new discoveries and insights into the identification and education of gifted children. The following Identification Handbook is meant to be a living document for growth and change over time as new research refines strategies, and active use of forms shows better processes and communications. Its purpose is to assist with bringing consistency in identification practices across the district. Rationale The Exceptional Children’s Education Act (ECEA) requires all administrative units (AUs) in Colorado to identify and serve students between the ages of five and twenty-one, and age four in administrative units with Early Access, whose aptitude or competence in abilities, talents, and potential for accomplishment in one or more domains are so exceptional or developmentally advanced that they require special provisions to meet their educational programming needs. Administrative units include: school districts, Charter School Institute (CSI), multi-district administrative units and Boards of Cooperative Educational Services (BOCES). -

TEST and ASSESS YOUR BRAIN QUOTIENT Ii
i TEST AND ASSESS YOUR BRAIN QUOTIENT ii This page is intentionally left blank iii TEST AND ASSESS YOUR BRAIN QUOTIENT Discover your true intelligence with tests of aptitude, logic, memory, EQ, creative and lateral thinking PHILIP CARTER London and Philadelphia iv Publisher’s note Every possible effort has been made to ensure that the information contained in this book is accurate at the time of going to press, and the publishers and author cannot accept responsibility for any errors or omissions, however caused. No responsibility for loss or damage occasioned to any person acting, or refraining from action, as a result of the material in this publication can be accepted by the editor, the publisher or the author. First published in Great Britain and the United States in 2009 by Kogan Page Limited Apart from any fair dealing for the purposes of research or private study, or criticism or review, as permitted under the Copyright, Designs and Patents Act 1988, this publication may only be reproduced, stored or transmitted, in any form or by any means, with the prior permission in writing of the publishers, or in the case of reprographic reproduction in accordance with the terms and licences issued by the CLA. Enquiries concerning reproduction outside these terms should be sent to the publishers at the undermentioned addresses: 120 Pentonville Road 525 South 4th Street, #241 London N1 9JN Philadelphia PA 19147 United Kingdom USA www.koganpage.com © Philip Carter, 2009 The right of Philip Carter to be identifi ed as the author of this work has been asserted by him in accordance with the Copyright, Designs and Patents Act 1988. -

Intelligence and Aptitude 228 28 VOLUME 11, NUMBER 1, FEBRUARY 2002
0≥π£®Ø¨Øßπ ¶Ø≤ )!3 )Æ¥•¨¨©ß•Æ£• °Æ§ !∞¥©¥µ§• •≤ØÆ≥©Æ )Æ¥•¨¨©ß•Æ£• °Æ§ !∞¥©¥µ§• #ØÆ£•∞¥ ض ©Æ¥•¨¨©ß•Æ£• °Æ§ °∞¥©¥µ§•) .°¥µ≤• °Æ§ ¥®•Ø≤©•≥ ض ©Æ¥•¨¨©ß•Æ£• " 3∞•°≤≠°Æ) 4®µ≤≥¥ØÆ•) 'µ¨¨¶Ø≤§ 6•≤ÆØÆ) 3¥•≤Æ¢•≤ß °Æ§ *0/ $°≥/ %≠Ø¥©ØÆ°¨ )Æ¥•¨¨©ß•Æ£•) 3Ø£©°¨ ©Æ¥•¨¨©ß•Æ£•) ≠•°≥µ≤•≠•Æ¥ ض ©Æ¥•¨¨©ß•Æ£• °Æ§ °∞¥©¥µ§•≥) £ØÆ£•∞¥ ض )1) §•∂©°¥©ØÆ )1) £ØÆ≥¥°Æ£π ض )1/ -•°≥µ≤•≠•Æ¥ ض ≠µ¨¥©∞¨• ©Æ¥•¨¨©ß•Æ£•/ &¨µ©§ ©Æ¥•¨¨©ß•Æ£• °Æ§ £≤π≥¥°¨¨©∫•§ ©Æ¥•¨¨©ß•Æ£• ∑∑∑Ƶ≠•≤ØÆ≥©Æ ∑∑∑Ƶ≠•≤ØÆ≥©Æ #Ø≠∞©¨•§ ¢π !≠©¥ 3®•´®°≤ %≠°©¨ Ƶ≠•≤ØÆ≥ß≠°©¨£Ø≠ #ØÆ¥°£¥ !" #$%&''('# 0≥π£®Ø¨Øßπ ¶Ø≤ )!3 )Æ¥•¨¨©ß•Æ£• °Æ§ !∞¥©¥µ§• 4Ø∞©£≥ 0°ß• .µ≠¢•≤ #ØÆ£•∞¥ ض )Æ¥•¨¨©ß•Æ£• °Æ§ !∞¥©¥µ§• 0¨°Æ¥ ©Æ¥•¨¨©ß•Æ£• •≤ØÆ≥©Æ ! 3π≥¥•≠≥ ©Æ¥•¨¨©ß•Æ£• (( -°¨¨•°¢©¨©¥π ض ©Æ¥•¨¨©ß•Æ£• (# !∞¥©¥µ§• 4®•Ø≤π ض ≠µ¨¥©∞¨• ©Æ¥•¨¨©ß•Æ£•≥ &% .°¥µ≤• °Æ§ 4®•Ø≤©•≥ ض )Æ¥•¨¨©ß•Æ£• #°¥¥•¨¨+≥ 4®•Ø≤π ض )Æ¥•¨¨©ß•Æ£• ,&¨µ©§ °Æ§ #≤π≥¥°¨¨©∫•§/ & 3∞•°≤≠°Æ0≥ 4®•Ø≤π ض )Æ¥•¨¨©ß•Æ£• ,ß " ¶°£¥Ø≤/ '& 3¥•≤Æ¢•≤ß0≥ 4®•Ø≤π ض )Æ¥•¨¨©ß•Æ£• ,4≤©°≤£®©£ 4®•Ø≤π/ ' 4®µ≤≥¥ØÆ0≥ 4®•Ø≤π ض )Æ¥•¨¨©ß•Æ£• #( 'µ©¨¶Ø≤§0≥ 4®•Ø≤π ض )Æ¥•¨¨©ß•Æ£• #' 0®©¨©∞ % 6•≤ÆØÆ0≥ 4®•Ø≤π ض )Æ¥•¨¨©ß•Æ£• #3 #°¥¥•¨¨"(Ø≤Æ"#°≤≤ب¨ ¥®•Ø≤π # %≠Ø¥©ØÆ°¨ ©Æ¥•¨¨©ß•Æ£•∑∑∑Ƶ≠•≤ØÆ≥©Æ !" 3Ø£©°¨ ©Æ¥•¨¨©ß•Æ£• $% #ØÆ£•∞¥ ض )Æ¥•¨¨©ß•Æ£• 1µØ¥©•Æ¥ '( (•≤©¥°¢©¨©¥π ض )1 '•Æ©µ≥ " )Æ¥•¨¨•£¥µ°¨ ß©¶¥•§Æ•≥≥ !!$ %Æ∂©≤ØÆ≠•Æ¥ °Æ§ ©Æ¥•¨¨©ß•Æ£• "' &¨πÆÆ •¶¶•£¥ !&& (©ß® )1 ≥Ø£©•¥π !'! (•°¨¥® °Æ§ ©Æ¥•¨¨©ß•Æ£• !'# &•≤¥©¨©¥π °Æ§ ©Æ¥•¨¨©ß•Æ£• !#& .°¥©ØÆ≥ °Æ§ ©Æ¥•¨¨©ß•Æ£• !#7 2•¨©ß©Ø≥©¥π °Æ§ ©Æ¥•¨¨©ß•Æ£•∑∑∑Ƶ≠•≤ØÆ≥©Æ !$( 3•∏ °Æ§ ∞≥π£®Ø¨Øßπ ,#Ø≤≤•¨°¥©ØÆ ∑©¥® )1/ !$$ 2°£• °Æ§ )Æ¥•¨¨©ß•Æ£• !3$ #ØßÆ©¥©∂• •∞©§•≠©Ø¨Øßπ -

Music Aptitude and Related Tests
Music G-5719 Aptitude and Related Tests An Introduction Edwin E. Gordon i G-5719 Music Aptitude and Related Tests An Introduction Edwin E. Gordon GIA Publications, Inc. Chicago www.giamusic.com Table of Contents Music Aptitude and Related Tests: An Introduction . .3 Music Aptitude and Music Achievement . .4 Developmental and Stabilized Music Aptitudes . .5 Measurement and Evaluation . .6 Test Descriptions Audie . .7 Primary Measures of Music Audiation . .8 Intermediate Measures of Music Audiation . .10 Musical Aptitude Profile . .10 Advanced Measures of Music Audiation . .13 Harmonic Improvisation Readiness Record . .14 Rhythm Improvisation Readiness Record . .15 Instrument Timbre Preference Test . .15 Iowa Tests of Music Literacy . .16 Summary . .18 iv Music Aptitude and Related Tests: An Introduction by Edwin E. Gordon The purpose of this booklet is to introduce you to music aptitude tests and other tests that are related to music aptitude. It describes the various tests and explains how they can be used with students in dif- ferent age groups as well as students with special needs. The outcome of these tests can assist you in better understanding the individual musical strengths and weaknesses of your students. As a result, you will be able to customize your instruction to fit studentsÕ differences and needs. The extensive technical aspects of the test will not be discussed, however, because all information pertaining to means, stan- dard deviations, reliabilities, various types of validities, standardiza- tion programs, derived norms, -

The Role of Aptitude in the Failure Or Success of Foreign Language Learning Laura Furcsa Eszterházy Károly Egyetem
PAIDEIA 6. évfolyam, 1. szám (2018) DOI: 10.33034/PAIDEIA.2018.6.1.31 The role of aptitude in the failure or success of foreign language learning Laura Furcsa Eszterházy Károly Egyetem Introduction One of the major challenges in language pedagogy is the explanation of different levels of success. A huge number of studies have looked at how different variables contribute to the success of language learning. There- fore the scope of this study was restricted to a single cognitive variable by focusing attention on language learning aptitude. Accordingly recent studies of unsuccessful learners are reviewed from this point of view as well as language learners’ characteristics and theories related to aptitude are discussed. This section is followed by the investigation of the role of aptitude in empirical studies. Learners’ characteristics influencing success There are several factors which are considered to have an influential role in the lack of success in language learning. Larsen-Freeman and Long (1991) listed the following factors: age, language aptitude, social-psycho- logical factors, personality, hemisphere specialization, and learning strat- egies. In addition to these individual variables, native language variables, input variables, and instructional variables are also mentioned. Gardner and MacIntyre (1992) gave a more systematic classification of these vari- ables, which they group into three broad categories: 1. Cognitive Variables: intelligence, language aptitude, language learn- ing strategies, previous language training and experience -

CHAPTER 8: INTELLIGENCE What Is Intelligence? the Ability to Solve
CHAPTER 8: INTELLIGENCE What is intelligence? The ability to solve problems and to adapt to and learn from life’s everyday experiences The ability to solve problems The capacity to adapt and learn from experiences Includes characteristics such as creativity and interpersonal skills The mental abilities that enable one to adapt to, shape, or select one’s environment The ability to judge, comprehend, and reason The ability to understand and deal with people, objects, and symbols The ability to act purposefully, think rationally, and deal effectively with the environment As you think about what intelligence is, you should ask the following questions: To what extent is intelligence genetic? To what extent is intelligence stable? How do cognitive abilities interact with other aspects of functioning? Are there true sex differences? Is intelligence a global capacity (similar to “good health”) or can it be differentiated into various dimensions (called “factors” or “aptitudes”)? Are there a number of “intelligences”? How do you measure intelligence? Intelligence Quotient (IQ): Measure of intelligence that takes into account a child’s mental and chronological age IQ Score = MA / CA x 100 Mental age (MA): the typical intelligence level found for people at a given chronological age Chronological age (CA): the actual age of the child taking the intelligence test People whose mental age is equal to their chronological age will always have an IQ of 100. If the chronological age exceeds mental age – below- average intelligence (below 100). If the mental age exceed the chronological age – above-average intelligence (above 100). The normal distribution: most of the population falls in the middle range of scores between 84 and 116. -

Chapter 1.Pmd
VARIAVARIAVARIAVARIATIONSTIONS ININ PSYPSYCHOLOGICALCHOLOGICAL ATATATTRIBUTESTRIBUTESTRIBUTES After reading this chapter, you would be able to: understand psychological attributes on which people differ from each other, learn about different methods that are used to assess psychological attributes, explain what constitutes intelligent behaviour, learn how psychologists assess intelligence to identify mentally challenged and gifted individuals, understand how intelligence has different meaning in different cultures, and understand the difference between intelligence and aptitude. Introduction Individual Differences in Human Functioning Assessment of Psychological Attributes Intelligence Theories of Intelligence Theory of Multiple Intelligences Triarchic Theory of Intelligence Planning, Attention-arousal, and Simultaneous- successive Model of Intelligence Individual Differences in Intelligence CONTENTS Variations of Intelligence Some Misuses of Intelligence Tests (Box 1.1) Culture and Intelligence Emotional Intelligence Key Terms Characteristics of Emotionally Intelligent Persons (Box 1.2) Summary Special Abilities Review Questions Aptitude : Nature and Measurement Project Ideas Creativity Weblinks Pedagogical Hints 1 Chapter 1 • Variations in Psychological Attributes 2021–22 If you observe your friends, classmates or relatives, you will find how they differ from each other in the manner they perceive, learn, and think, as also in their performance on various tasks. Such individual differences can be noticed in every walk of life. That people differ from one another is obvious. Introduction In Class XI, you have learnt about psychological principles that are applied to understand human behaviour. We also need to know how people differ, what brings about these differences, and how such differences can be assessed. You will recall how one of the main concerns of modern psychology has been the study of individual differences from the time of Galton. -

EXAMINING the SPATIAL ABILITY PHENOMENON from the STUDENT's PERSPECTIVE a Dissertation Submitted to the Faculty of Purdue
EXAMINING THE SPATIAL ABILITY PHENOMENON FROM THE STUDENT’S PERSPECTIVE A Dissertation Submitted to the Faculty of Purdue University by James L. Mohler In Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy August 2006 Purdue University West Lafayette, Indiana ii Copyright 2006 by Mohler, James L. iii DEDICATION To my wife, Lisa—for her steadfast love and support of all that I do. To my parents—for starting me down this academic road. iv ACKNOWLEDGMENTS There are many who have supported the creation of this work, making it difficult to choose the words that truly express the heartfelt gratitude and appreciation I feel. Words at times do not seem to carry the full import. Nevertheless, I would like to begin by thanking the members of my committee for their guidance, suggestions, criticisms, and support. As my chair, Dr. Timothy Newby has been quite patient with me as I have traversed a somewhat "non- traditional" path in the pursuit of this degree and the completion of this work. His continued encouragement and advice have been invaluable. To Drs. James Lehman and Ala Samarapungavan I extend gratitude for their timely reviews and thoughtful insights during the creation of this document and the execution of this project. To Dr. Craig Miller, for his continued "encouragement" to make the time to get this done (which at times made me love and hate him like a brother), I am grateful. And, to Dr. Donna Enersen, who late in this project was willing to jump on-board and provide critical expertise in qualitative research, I am equally thankful. -
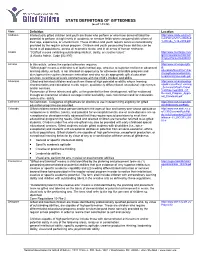
STATE DEFINITONS of GIFTEDNESS (As of 1-13-16)
STATE DEFINITONS OF GIFTEDNESS (as of 1-13-16) State Definition Location Alabama Intellectually gifted children and youth are those who perform or who have demonstrated the http://www.alsde.edu/sec/ potential to perform at high levels in academic or creative fields when compared with others of ses/Policy/AAC%20Gifted their age, experience, or environment. These children and youth require services not ordinarily %20Code_5-14-2009.pdf provided by the regular school program. Children and youth possessing these abilities can be found in all populations, across all economic strata, and in all areas of human endeavor. Alaska “‘[G]ifted’ means exhibiting outstanding intellect, ability, or creative talent.” http://www.touchngo.com/ (4 Alaska Admin. Code §52.890) lglcntr/akstats/aac/title04/ chapter052/section890.ht m Arizona In this article, unless the context otherwise requires: http://www.azed.gov/gifte "Gifted pupil" means a child who is of lawful school age, who due to superior intellect or advanced d- learning ability, or both, is not afforded an opportunity for otherwise attainable progress and education/files/2012/10/ar development in regular classroom instruction and who needs appropriate gifted education izonagiftededucationstatu tesadministrativecode.pdf services, to achieve at levels commensurate with the child's intellect and ability. Arkansas Gifted and talented children and youth are those of high potential or ability whose learning http://www.arkansased.go characteristics and educational needs require qualitatively differentiated educational experiences v/public/userfiles/Learning and/or services. _Services/Gifted%20and Possession of these talents and gifts, or the potential for their development, will be evidenced %20Talented/2009_GT_ Revised_Program_Appro through an interaction of above average intellectual ability, task commitment and /or motivation, val_Standards.pdf and creative ability. -

GRE ® Psychology Test Practice Book (PDF)
GRE ® Psychology Test Practice Book This practice book contains ◾ one actual, full-length GRE® Psychology Test ◾ test-taking strategies Become familiar with ◾ test structure and content ◾ test instructions and answering procedures Compare your practice test results with the performance of those who took the test at a GRE administration. www.ets.org/gre Table of Contents Overview ...............................................................................................................3 Test Content .........................................................................................................3 Preparing for the Test ...........................................................................................4 Test-Taking Strategies ..........................................................................................5 What Your Scores Mean .......................................................................................5 Taking the Practice Test .......................................................................................5 Scoring the Practice Test ......................................................................................6 Evaluating Your Performance ...............................................................................6 Practice Test ..........................................................................................................7 Worksheet for Scoring the Practice Test ............................................................43 Score Conversion Table .....................................................................................45 -

On the Relationship Between Aptitude and Intelligence in Second Language Acquisition
Teachers College, Columbia University Working Papers in TESOL & Applied Linguistics, Vol. 4, Special Issue Aptitude and Intelligence in SLA On the Relationship between Aptitude and Intelligence in Second Language Acquisition Jim Teepen1 Teachers College, Columbia University ABSTRACT Better understanding of the varied factors that account for successful second language acquisition is a goal that is of obvious interest to anyone within the field of language study. Before the influence of these factors can be adequately understood, of course, they must be defined and utilized in an accurate and consistent way. This paper endeavors to explore and clarify the ambiguity surrounding usage of the terms intelligence and aptitude in second language acquisition in effort to understand the more central issue of how the qualities designated by these terms relate to second language acquisition. This should enable a clearer picture to emerge about the relative importance of intelligence and aptitude among the constellation of factors associated with second language acquisition. INTRODUCTION The role and meanings of the terms intelligence and aptitude as they have been used in second language acquisition (SLA) discourse are significant for virtually all aspects of SLA. If it were the case that only individuals with what for the moment will be called exceptionally high innate abilities are able to become highly proficient in a second language, then it may be sensible to arrange academic programs based on this fact. If, alternatively, it turns out that intellectual abilities are not predictive of success with a second language, the pedagogical ramifications are clearly quite different. Similar significant consequences follow for other elements within the domain of SLA.