Weakly Supervised Cyberbullying Detection with Participant-Vocabulary Consistency
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
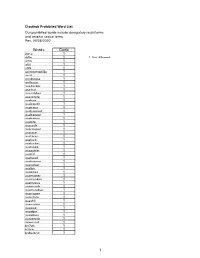
2020-05-25 Prohibited Words List
Clouthub Prohibited Word List Our prohibited words include derogatory racial terms and graphic sexual terms. Rev. 05/25/2020 Words Code 2g1c 1 4r5e 1 1 Not Allowed a2m 1 a54 1 a55 1 acrotomophilia 1 anal 1 analprobe 1 anilingus 1 ass-fucker 1 ass-hat 1 ass-jabber 1 ass-pirate 1 assbag 1 assbandit 1 assbang 1 assbanged 1 assbanger 1 assbangs 1 assbite 1 asscock 1 asscracker 1 assface 1 assfaces 1 assfuck 1 assfucker 1 assfukka 1 assgoblin 1 asshat 1 asshead 1 asshopper 1 assjacker 1 asslick 1 asslicker 1 assmaster 1 assmonkey 1 assmucus 1 assmunch 1 assmuncher 1 assnigger 1 asspirate 1 assshit 1 asssucker 1 asswad 1 asswipe 1 asswipes 1 autoerotic 1 axwound 1 b17ch 1 b1tch 1 babeland 1 1 Clouthub Prohibited Word List Our prohibited words include derogatory racial terms and graphic sexual terms. Rev. 05/25/2020 ballbag 1 ballsack 1 bampot 1 bangbros 1 bawdy 1 bbw 1 bdsm 1 beaner 1 beaners 1 beardedclam 1 bellend 1 beotch 1 bescumber 1 birdlock 1 blowjob 1 blowjobs 1 blumpkin 1 boiolas 1 bollock 1 bollocks 1 bollok 1 bollox 1 boner 1 boners 1 boong 1 booobs 1 boooobs 1 booooobs 1 booooooobs 1 brotherfucker 1 buceta 1 bugger 1 bukkake 1 bulldyke 1 bumblefuck 1 buncombe 1 butt-pirate 1 buttfuck 1 buttfucka 1 buttfucker 1 butthole 1 buttmuch 1 buttmunch 1 buttplug 1 c-0-c-k 1 c-o-c-k 1 c-u-n-t 1 c.0.c.k 1 c.o.c.k. -

Horace Grant Gay Erotic Fan Fiction by Smacko It Was the Day That Joey
Horace Grant Gay Erotic Fan Fiction By Smacko It was the day that Joey had always dreamed of. He was finally getting the chance to meet his favorite basketball player, Horace Grant of the Chicago Bulls. He was so excited to finally meet his idol. He was ushered into the dressing room by Phil Jackson. Phil told him that he was really going to enjoy finally meeting Horace and that Horace was one of his favorite players. As he brought Joey into the locker room, Joey noticed that many of the other Bulls players were on there way out and there was no sight of Horace. At first Joey was disappointed. Finally after the rest of the Bulls players had left, Phil told him that Horace should be out of the showers anytime and that he had to go to a meeting with the owner of the team, Jerry Kraus. Finally Horace emerged from the showers only wearing a towel. Joey ran over and said “Hey Horace, I am your biggest fan.” Horace chuckled and said “I have been looking forward to meeting you for some time.” Joey could see the outline of a large member underneath his towel. Horace hugged Joey close and Joey could feel his pulsing member quivering against him. He suddenly became more aroused than he had ever been before. The feeling of Horace’s member against him sent chills up his spine. As he backed away he shivered in delight. Horace said “I have a surprise that you are going to love.” He reached into his towel and pulled out a set of Rec Specs TM. -

Die Coca-Cola-Blacklist: Dies Darf Nicht Auf Coca-Cola-Flaschen Geschrieben Werden 1
Die Coca-Cola-Blacklist: Dies darf nicht auf Coca-Cola-Flaschen geschrieben werden 1 „Group 0“: µ barthoisgay boner chink abart bartke boning chowbox abfall battlefield boob chubby abfluss bbw boody cialis abfluß bdolfbitler booger circlejerk abort beast booty climax abschaum beatthe bordell clit abscheu beefcattle bourbon cloake abwasser behindies brackwasser closetqueen abwichs bellywhacker brainfuk clubcola adult berber brainjuicer clubmate aersche bestial bratze cocaln affe biatch brauchwasser cock affegsicht biatsch breasts cocks afri bigboobs brecheisen coitus after bigfat brechmittel cojones ahole bigtits bremsspur cokaine ahrschloch bigtitts browntown cokamurat aktmodel binde brueste cokmuncher altepute bionade brust coksucka amaretto bitch brutal coprophagie anahl blacklist buceta copulation anai blackwallstreet buffoon cornhole anarchi blaehen bugger covered anarl blaehung buggery cox angerfist blaeser bukkake cptmorgan animal blähung bull crap anthrax blasehase bulldager crapper antidfb blasen bullen cretin antrax blasmaeuler bullshit crossdresser apecrime blasmaul bumbandit crossdressing areschloch blechschlüpfer bumhole cuckold arsch bleichmittel bumse cum arsebandit blockhead bunghole cumm arzchloch blödfrau busen cumshot asbach blödk bushboogie cunilingus aschevonoma blödmann butt cunillingus ausfluss blödvolk buttface cunnilingus ausfluß bloody butthole cunt ausscheidung blowjob buttmuch cuntlick auswurf blowjob buttpirate cunts autobahn blowyourwad buttplug cyberfuc ayir bluemovie butts dalailama azzlicka blumkin cacker -

Design Justice: Community-Led Practices to Build the Worlds We
Design Justice Information Policy Series Edited by Sandra Braman The Information Policy Series publishes research on and analysis of significant problems in the field of information policy, including decisions and practices that enable or constrain information, communication, and culture irrespective of the legal siloes in which they have traditionally been located, as well as state- law- society interactions. Defining information policy as all laws, regulations, and decision- making principles that affect any form of information creation, processing, flows, and use, the series includes attention to the formal decisions, decision- making processes, and entities of government; the formal and informal decisions, decision- making processes, and entities of private and public sector agents capable of constitutive effects on the nature of society; and the cultural habits and predispositions of governmentality that support and sustain government and governance. The parametric functions of information policy at the boundaries of social, informational, and technological systems are of global importance because they provide the context for all communications, interactions, and social processes. Virtual Economies: Design and Analysis, Vili Lehdonvirta and Edward Castronova Traversing Digital Babel: Information, e- Government, and Exchange, Alon Peled Chasing the Tape: Information Law and Policy in Capital Markets, Onnig H. Dombalagian Regulating the Cloud: Policy for Computing Infrastructure, edited by Christopher S. Yoo and Jean- François Blanchette Privacy on the Ground: Driving Corporate Behavior in the United States and Europe, Kenneth A. Bamberger and Deirdre K. Mulligan How Not to Network a Nation: The Uneasy History of the Soviet Internet, Benjamin Peters Hate Spin: The Manufacture of Religious Offense and Its Threat to Democracy, Cherian George Big Data Is Not a Monolith, edited by Cassidy R. -

VAGINA Vagina, Pussy, Bearded Clam, Vertical Smile, Beaver, Cunt, Trim, Hair Pie, Bearded Ax Wound, Tuna Taco, Fur Burger, Cooch
VAGINA vagina, pussy, bearded clam, vertical smile, beaver, cunt, trim, hair pie, bearded ax wound, tuna taco, fur burger, cooch, cooter, punani, snatch, twat, lovebox, box, poontang, cookie, fuckhole, love canal, flower, nana, pink taco, cat, catcher's mitt, muff, roast beef curtains, the cum dump, chocha, black hole, sperm sucker, fish sandwich, cock warmer, whisker biscuit, carpet, love hole, deep socket, cum craver, cock squeezer, slice of heaven, flesh cavern, the great divide, cherry, tongue depressor, clit slit, hatchet wound, honey pot, quim, meat massager, chacha, stinkhole, black hole of calcutta, cock socket, pink taco, bottomless pit, dead clam, cum crack, twat, rattlesnake canyon, bush, cunny, flaps, fuzz box, fuzzy wuzzy, gash, glory hole, grumble, man in the boat, mud flaps, mound, peach, pink, piss flaps, the fish flap, love rug, vadge, the furry cup, stench-trench, wizard's sleeve, DNA dumpster, tuna town, split dick, bikini bizkit, cock holster, cockpit, snooch, kitty kat, poody tat, grassy knoll, cold cut combo, Jewel box, rosebud, curly curtains, furry furnace, slop hole, velcro love triangle, nether lips, where Uncle's doodle goes, altar of love, cupid's cupboard, bird's nest, bucket, cock-chafer, love glove, serpent socket, spunk-pot, hairy doughnut, fun hatch, spasm chasm, red lane, stinky speedway, bacon hole, belly entrance, nookie, sugar basin, sweet briar, breakfast of champions, wookie, fish mitten, fuckpocket, hump hole, pink circle, silk igloo, scrambled eggs between the legs, black oak, Republic of Labia, -

Signalandnoise
Signal and Noise Can technology provide a window into the new world of digital politics in the UK? Alex Krasodomski-Jones Open Access. Some rights reserved. As the publisher of this work, Demos wants to encourage the circulation of our work as widely as possible while retaining the copyright. We therefore have an open access policy which enables anyone to access our content online without charge. Anyone can download, save, perform or distribute this work in any format, including translation, without written permission. This is subject to the terms of the Demos licence found at the back of this publication. Its main conditions are: · Demos and the author(s) are credited · This summary and the address www.demos.co.uk are displayed · The text is not altered and is used in full · The work is not resold · A copy of the work or link to its use online is sent to Demos. You are welcome to ask for permission to use this work for purposes other than those covered by the licence. Demos gratefully acknowledges the work of Creative Commons in inspiring our approach to copyright. To find out more go to www.creativecommons.org PARTNERS CREDITS This paper was written by the Centre for the Analysis of Social Media (CASM) at Demos in partnership with BCS, The Chartered Institute for IT. BCS, The Chartered Institute for IT, is committed to making IT good for society. We use the power of our network to bring about positive, tangible change. We champion the global IT profession and the interests of individuals, engaged in that profession, for the benefit of all. -

Internet Blocking in Public Schools
Electronic Frontier Electronic Frontier Foundation Phone +1 (415) 436-9333 454 Shotwell Street Fax +1 (415) 436-9993 Foundation San Francisco, CA 94110 [email protected] USA http://www.eff.org/ Online Policy Group Phone +1 (415) 826-3532 Online Policy Group 304 Winfield Street Fax +1 (928) 244-2347 San Francisco, CA 94110 [email protected] USA http://www.onlinepolicy.org/ Internet Blocking in Public Schools A Study on Internet Access in Educational Institutions Version 1.1 of 26 June 2003 ii Version 1.1 of 26 June 2003 Contents 1) Abstract ..................................................................................................................................1 A. OPG & EFF study the effectiveness of Internet blocking software…………………………………..… 1 B. Implications for censorship and civil liberties issues…………………………………………………….. 2 C. Summary of study results…………………………………………………………………………………. 2 2) Preface...................................................................................................................................3 A. Need for study……………………………………………………………………………………………… 3 B. Children’s Internet Protection Act……………………………………………………………………….… 3 C. Related litigation and legal definitions…………………………………………………………………..… 8 D. Impact on schools……………………………………………………………………………….……….. 10 3) Methodology ......................................................................................................................... 11 A. Determine study parameters (curriculum, search engine, internet blocking software)……………… 11 B. Extract topics -

The Upshot on Princess Merida in Disney/Pixar's Brave: Why The
humanities Article The Upshot on Princess Merida in Disney/Pixar’s Brave: Why the Tomboy Trajectory Is Off Target Lauren Dundes Department of Sociology, McDaniel College, Westminster, MD 21157, USA; [email protected] Received: 25 June 2020; Accepted: 14 August 2020; Published: 16 August 2020 Abstract: Princess Merida, the “tomboy” princess in Disney/Pixar’s Brave, won praise for escaping the strictures of femininity and maternal demands for feminine propriety. In addition to her overt defiance of gender roles and demand for agency, Merida also enacts hegemonic masculinity by mocking her suitors during an archery contest in which she is the prize. The ridicule is the prelude to her dramatic, winning bullseye that feminizes the men, in a scene rich in symbolism about gender and power. In enacting the final phase of the tomboy paradigm, however, Merida reverses her trajectory as her rebellion against femininity ebbs. She then resolves conflict by displaying vulnerability rather than performing brave deeds. This marked shift to a more traditional gender role raises questions about her stature as a model of autonomy able to withstand the pressure to conform. Keywords: Disney princess; gender stereotypes; hegemonic masculinity; gender roles; archery; bullseye; humor; tomboy; emasculation 1. Introduction The influence of Disney productions in socializing children has prompted significant discourse about what their content teaches young viewers (Giroux 1999; Zipes 2015), especially with the advent of the Disney Plus network. From its release in November 2019 until April 2020, Disney Plus attracted subscriptions in excess of 50 million (Swartz 2020). The corporate juggernaut’s expanding dominance has resulted in calls to examine the values promulgated in its programming, with the perpetuation of gender stereotypes among the chief concerns (Dundes et al. -

California State University, Northridge Blackbeard's
CALIFORNIA STATE UNIVERSITY, NORTHRIDGE BLACKBEARD'S CUP A graduate project submitted in partial fulfillment of the requirements For the degree of Master of Fine Arts in Screenwriting By Stephen Baxter Harris May 2015 The graduate project of Stephen Baxter Harris is approved: _________________________________________ ______________ Dr. Kenneth Portnoy Date _________________________________________ ______________ Professor Scott Sturgeon Date _________________________________________ ______________ Professor Eric Edson, Chair Date CALIFORNIA STATE UNIVERSITY, NORTHRIDGE ii Table of Contents Signature Page ii Abstract iv BLACKBEARD’S CUP 1 iii ABSTRACT BLACKBEARD'S CUP By Stephen Baxter Harris Master of Fine Arts in Screenwriting Blackbeard's Cup is about Bud Beachley, a 7th grade surfer kid who rebels against authority because he loves pirates. When he finds the enchanted skull of Blackbeard the Pirate. He uses it to wish for perfect waves to surf which accidentally summons Evil Skeletons from the ocean floor who want Blackbeard's gold. The Skeletons kill anything and anyone in town who opposes them, so Bud must learn what it truly means to rebel in order to stop the Skeletons from destroying his town. iv EXT. MINI GOLF COURSE - NIGHT TITLE CARD: 1985 Wind and rain batter PIRATE STATUES and OCCULT MONSTER STATUES on KOOKY MINI GOLF putting greens. LIGHTNING strikes near a scaled down replica of a pirate ship which serves as the entrance to the course. Thunder rumbles. Lightning strikes closer, lights the crude plaster face of a BLACKBEARD THE PIRATE STATUE who stands at the entrance. INT. MINI GOLF ARCADE AND SNACK SHOP - NIGHT Its a brand new video arcade with all the hits like Karate Champ, Paperboy, Marble Madness, Frogger, Spy Hunter, Shark Attack, Super Mario Brothers, ect. -

Diplomarbeit
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by OTHES DIPLOMARBEIT Titel der Diplomarbeit „Bad language: A study of German- English bilinguals’ perception of swear words in L1 and L2“ Band 1 von 5 Bänden Verfasserin Ioana-Adriana Rusu angestrebter akademischer Grad Magistra der Philosophie (Mag.phil.) Wien, 2012 Studienkennzahl lt. Studienblatt: A 190 334 347 Studienrichtung lt. Studienblatt: UF Englisch UF Französisch Betreuer: Univ.-Prof. Mag. Dr. Nikolaus Ritt Contents Acknowledgements ............................................................................................................................4 List of abbreviations ........................................................................................................................5 1 Introduction ................................................................................................................................6 1 Theoretical part ..........................................................................................................................7 1.1 Research question ...............................................................................................................7 2.2 General Introduction to swear words ................................................................................ 11 2.2.1 Categories .................................................................................................................. 11 2.2.2 Epithets by Goffman ................................................................................................. -

Weakly Supervised Machine Learning for Cyberbullying Detection
Weakly Supervised Machine Learning for Cyberbullying Detection Elaheh Raisi Dissertation submitted to the Faculty of the Virginia Polytechnic Institute and State University in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Computer Science and Applications Bert Huang, Chair Naren Ramakrishnan Madhav V. Marathe Gang Wang Richard Y. Han March 28, 2019 Blacksburg, Virginia Keywords: Machine Learning, Weak Supervision, Cyberbullying detection, Social Media, Co-trained Ensemble Copyright 2019, Elaheh Raisi Weakly Supervised Machine Learning for Cyberbullying Detection Elaheh Raisi (ABSTRACT) The advent of social media has revolutionized human communication, significantly improving individuals lives. It makes people closer to each other, provides access to enormous real-time information, and eases marketing and business. Despite its uncountable benefits, however, we must consider some of its negative implications such as online harassment and cyberbullying. Cyberbullying is becoming a serious, large-scale problem damaging people's online lives. This phenomenon is creating a need for automated, data-driven techniques for analyzing and detecting such behaviors. In this research, we aim to address the computational challenges associated with harassment-based cyberbullying detection in social media by developing machine-learning framework that only requires weak supervision. We propose a general framework that trains an ensemble of two learners in which each learner looks at the problem from a different perspective. One learner identifies bullying incidents by examining the language content in the message; another learner considers the social structure to discover bullying. Each learner is using different body of information, and the individual learner co-train one another to come to an agreement about the bullying concept. -

'A Place I Can Call Home'
CHICAGO’SFREEWEEKLYSINCE | JULY | JULY CHICAGO’SFREEWEEKLYSINCE Omen gets back in the game The TRiiBE 26 Why is the rent so damn high? Maya Dukmasova and Anjulie Rao 16 The worst hecklers are the cats Brianna Wellen 19 ‘A place I can call Chicago has one of the largest Rohingya refugee populations in the home’ country. This is one survivor’s story. By EF 12 THIS WEEK CHICAGOREADER | JULY | VOLUME NUMBER IN THIS ISSUE T R - CITYLIFE populationsinthecountryThisis ScandinavianschlockYesterday 31 TheSecretHistoryof @ 04 SightseeingHowanambitious onesurvivor’sstory andtheideaoffi ndinghome ChicagoMusicDrummerKahil planforanairportinthelakefailed throughtheBeatles El’Zabarelevatesgroovetoa totakefl ight 23 MoviesofnoteBefore transcendentplane PTB 05 PSAGivemeyourtiredmasses Stonewallutilizesrevealing 34 EarlyWarningsClaud ECSKKH DEKS yearningtoplaycornhole interviewsandrivetingarchival HieroglyphicsShonenKnifeand C LSK footageToniMorrisonThePieces morejustannouncedshows D P JR ThatIAmisrichwithinsightsabout 34 GossipWolfGuitaristand CEAL NEWS&POLITICS M EP M 06 Joravsky|PoliticsHowfear BlacknessandSpiderManFar soulsingerIsaiahSharkeydrops A EJL drivestheoppositiontosingle FromHomeprovideseyepopping akaleidoscopicnewalbumblack SWDI payerhealthcare escapism metaltakesontheFantasticFour BJ MS SWMD L G andmore EA SN L G D D C S MEBW ARTS&CULTURE OPINION L CS C -J 16 ArchitectureAvisittothe 36 ForeignPolicyHowDemocrats FL CPF ‘Evicted’exhibitinMilwaukee andRepublicanskeepusconstantly TA ECS 18 VisualArtQuiltsofValorpieces