Weakly Supervised Machine Learning for Cyberbullying Detection
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Anti-Bullying Policy and Procedures
Anti-Bullying Policy and Procedures Version: 3 Name & job title of policy owner Eugene Amoako Date approved by Nathan Singleton, 15th June 2017 Director of Young People Date published on SharePoint: June 2017 Next review date: June 2020 © LifeLine Community Projects Page 1 of 8 Contents 1. Our values and beliefs ................................................................................................. 3 2. Statutory duties of schools .......................................................................................... 3 3. Scope of this policy and links to other policies ........................................................... 3 4. Definition ..................................................................................................................... 3 5. Creating an anti-bullying climate in school ................................................................. 4 6. Identifying and reporting concerns about bullying .................................................... 4 7. Responding to reports about bullying ......................................................................... 5 7.1 Staff ....................................................................................................................... 5 7.2 Support .................................................................................................................. 5 7.3 Students who have bullied will be helped through appropriate measures from the following menu: .................................................................................................... -

Parent to Parent Back from Lockdown Toolkit a Collection of Ideas & Strategies to Support Parents and Young People To
Parent to Parent Back from Lockdown Toolkit A collection of Ideas & Strategies to support parents and young people to get back to School After Lockdown Bullying In response to our successful ‘Returning to School After Lockdown ‘survey which was sent out to Young People and their families, we have sourced and collated a selection of printable worksheets and activities to help support some of the young people’s biggest concerns and to encourage the young people to plan and set themselves goals for their return to school. Thank you to each and every one for sharing their thoughts and worries with us. All these resources are available from the links to the organisation that has developed them on the bottom of each page. Or can be sourced through a ‘google search’. Please use what you need from this resource to help you and your young person work towards feeling more confident and prepared for returning to school. Bullying Sometimes in school we feel we are being bullied, here are some activities to help you understand what bullying is. It's not easy to stand up to a bully but if you think you are being bullied make sure you tell and adult you trust Bullying is something that can hurt you on the inside or on the outside. It hurts you on the outside by hitting you and hurting you physically. It hurts you on the inside by name calling, skitting or hurting your feelings. Bullying is done on purpose, it’s not an accident. If someone hurts you during a game by accident that is not bullying, but if every time you played a game they hurt you, or your feelings that would be bullying. -
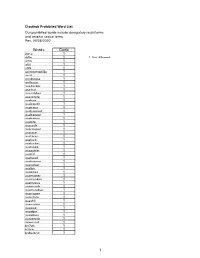
2020-05-25 Prohibited Words List
Clouthub Prohibited Word List Our prohibited words include derogatory racial terms and graphic sexual terms. Rev. 05/25/2020 Words Code 2g1c 1 4r5e 1 1 Not Allowed a2m 1 a54 1 a55 1 acrotomophilia 1 anal 1 analprobe 1 anilingus 1 ass-fucker 1 ass-hat 1 ass-jabber 1 ass-pirate 1 assbag 1 assbandit 1 assbang 1 assbanged 1 assbanger 1 assbangs 1 assbite 1 asscock 1 asscracker 1 assface 1 assfaces 1 assfuck 1 assfucker 1 assfukka 1 assgoblin 1 asshat 1 asshead 1 asshopper 1 assjacker 1 asslick 1 asslicker 1 assmaster 1 assmonkey 1 assmucus 1 assmunch 1 assmuncher 1 assnigger 1 asspirate 1 assshit 1 asssucker 1 asswad 1 asswipe 1 asswipes 1 autoerotic 1 axwound 1 b17ch 1 b1tch 1 babeland 1 1 Clouthub Prohibited Word List Our prohibited words include derogatory racial terms and graphic sexual terms. Rev. 05/25/2020 ballbag 1 ballsack 1 bampot 1 bangbros 1 bawdy 1 bbw 1 bdsm 1 beaner 1 beaners 1 beardedclam 1 bellend 1 beotch 1 bescumber 1 birdlock 1 blowjob 1 blowjobs 1 blumpkin 1 boiolas 1 bollock 1 bollocks 1 bollok 1 bollox 1 boner 1 boners 1 boong 1 booobs 1 boooobs 1 booooobs 1 booooooobs 1 brotherfucker 1 buceta 1 bugger 1 bukkake 1 bulldyke 1 bumblefuck 1 buncombe 1 butt-pirate 1 buttfuck 1 buttfucka 1 buttfucker 1 butthole 1 buttmuch 1 buttmunch 1 buttplug 1 c-0-c-k 1 c-o-c-k 1 c-u-n-t 1 c.0.c.k 1 c.o.c.k. -

Horace Grant Gay Erotic Fan Fiction by Smacko It Was the Day That Joey
Horace Grant Gay Erotic Fan Fiction By Smacko It was the day that Joey had always dreamed of. He was finally getting the chance to meet his favorite basketball player, Horace Grant of the Chicago Bulls. He was so excited to finally meet his idol. He was ushered into the dressing room by Phil Jackson. Phil told him that he was really going to enjoy finally meeting Horace and that Horace was one of his favorite players. As he brought Joey into the locker room, Joey noticed that many of the other Bulls players were on there way out and there was no sight of Horace. At first Joey was disappointed. Finally after the rest of the Bulls players had left, Phil told him that Horace should be out of the showers anytime and that he had to go to a meeting with the owner of the team, Jerry Kraus. Finally Horace emerged from the showers only wearing a towel. Joey ran over and said “Hey Horace, I am your biggest fan.” Horace chuckled and said “I have been looking forward to meeting you for some time.” Joey could see the outline of a large member underneath his towel. Horace hugged Joey close and Joey could feel his pulsing member quivering against him. He suddenly became more aroused than he had ever been before. The feeling of Horace’s member against him sent chills up his spine. As he backed away he shivered in delight. Horace said “I have a surprise that you are going to love.” He reached into his towel and pulled out a set of Rec Specs TM. -

Online Harassment and Cyber Bullying Jack Dent
BRIEFING PAPER Number 07967, 13 September 2017 By Pat Strickland Online harassment and cyber bullying Jack Dent Contents: 1. The problem 2. Recent governments’ approaches to internet regulation 3. The law in England and Wales 4. Do we need specific law for online harassment? 5. Will there be changes to the law? 6. Children and online bullying 7. Online abuse of Members of Parliament 8. Reporting online abuse and harassment 9. Sources of help and advice 10. Scotland 11. Northern Ireland www.parliament.uk/commons-library | intranet.parliament.uk/commons-library | [email protected] | @commonslibrary 2 Online harassment and cyber bullying Contents Summary 3 1. The problem 5 2. Recent governments’ approaches to internet regulation 6 3. The law in England and Wales 7 3.1 Relevant offences 7 3.2 Guidance on prosecuting social media offences 7 3.3 A new code of practice 9 4. Do we need specific law for online harassment? 10 5. Will there be changes to the law? 12 5.1 The Law Commission consultation 12 5.2 A Green Paper in 2017? 13 5.3 The 2017 General Election manifestos 13 6. Children and online bullying 16 What can parents do? 17 7. Online abuse of Members of Parliament 19 2017 General Election 20 Independent review into abuse of Parliamentary candidates 20 8. Reporting online abuse and harassment 21 8.1 What are social media companies doing? 21 8.2 The challenge for social media companies 23 9. Sources of help and advice 27 Adults 27 Parents and children 27 10. Scotland 28 10.1 The law 28 10.2 Guidance and help for victims 28 11. -

Die Coca-Cola-Blacklist: Dies Darf Nicht Auf Coca-Cola-Flaschen Geschrieben Werden 1
Die Coca-Cola-Blacklist: Dies darf nicht auf Coca-Cola-Flaschen geschrieben werden 1 „Group 0“: µ barthoisgay boner chink abart bartke boning chowbox abfall battlefield boob chubby abfluss bbw boody cialis abfluß bdolfbitler booger circlejerk abort beast booty climax abschaum beatthe bordell clit abscheu beefcattle bourbon cloake abwasser behindies brackwasser closetqueen abwichs bellywhacker brainfuk clubcola adult berber brainjuicer clubmate aersche bestial bratze cocaln affe biatch brauchwasser cock affegsicht biatsch breasts cocks afri bigboobs brecheisen coitus after bigfat brechmittel cojones ahole bigtits bremsspur cokaine ahrschloch bigtitts browntown cokamurat aktmodel binde brueste cokmuncher altepute bionade brust coksucka amaretto bitch brutal coprophagie anahl blacklist buceta copulation anai blackwallstreet buffoon cornhole anarchi blaehen bugger covered anarl blaehung buggery cox angerfist blaeser bukkake cptmorgan animal blähung bull crap anthrax blasehase bulldager crapper antidfb blasen bullen cretin antrax blasmaeuler bullshit crossdresser apecrime blasmaul bumbandit crossdressing areschloch blechschlüpfer bumhole cuckold arsch bleichmittel bumse cum arsebandit blockhead bunghole cumm arzchloch blödfrau busen cumshot asbach blödk bushboogie cunilingus aschevonoma blödmann butt cunillingus ausfluss blödvolk buttface cunnilingus ausfluß bloody butthole cunt ausscheidung blowjob buttmuch cuntlick auswurf blowjob buttpirate cunts autobahn blowyourwad buttplug cyberfuc ayir bluemovie butts dalailama azzlicka blumkin cacker -

Anti-Bullying Guide
scouts.org.uk/bullying TOGETHER WE CAN BEAT BULLYING. The Scouting Guide to Taking Action !@£$%&* !@£$%&* 02 Let’s stamp out bullying together SCOUTING HAS THE POWER TO CREATE AN ENVIRONMENT IN WHICH BULLYING IS NOT ACCEPTABLE... This guide has been written to help you to reduce the chances of bullying happening, and to help young people who may be being bullied. The Scout Association has an Anti- Bullying Policy that states: ‘It is the responsibility of all adults in Scouting to help develop a caring and supportive atmosphere, where bullying in any form is unacceptable.’ This applies to everyone within Scouting – adults and young people. In Scouting we create positive and respect environments where we value and celebrate our differences. This makes it difficult for bullying to occur. However, at some time we will all have experienced bullying, either as a target or an observer. That’s why it’s important that all adults and young people understand the role they play in addressing and preventing bullying. Let’s stamp out bullying together 03 3 CONTENTS 5 WHAT IS BULLYING? - 5 UNDERSTANDING BULLYING - HOW DO I RECOGNISE6 THE SIGNS? - HOW CAN I HELP? - 7 CREATING YOUR OWN 8 ANTI-BULLYING CODE - RESPONDING TO BULLYING - INVOLVING PARENTS - 9 CYBERBULLYING - 10 WHERE CAN I FIND HELP? - 12 WHAT IS BULLYING? Physical: Threatening or causing injury to a person or property Young people say that bullying Verbal: Teasing, insulting, ridiculing, is their biggest concern humiliating or making sexist, racist, or homophobic comments to someone Bullying is found in all walks of life, and can happen anywhere, to anyone. -

Bullying Prevention in the Elementary Classroom Using Social Skills
BULLYING PREVENTION IN THE ELEMENTARY CLASSROOM USING SOCIAL SKILLS Stacie Anderson, B.S. Colleen Swiatowy, B.S. An Action Research Project Submitted to the Graduate Faculty of the School of Education in Partial Fulfillment of the Requirement for the Degree of Master of Arts in Teaching and Leadership Saint Xavier University & Pearson Achievement Solutions, Inc. Field-Based Master’s Program Chicago, Illinois December, 2008 i TABLE OF CONTENTS ABSTRACT …………………………………………………………………………… iii CHAPTER 1: PROBLEM STATEMENT AND CONTEXT ………………………… 1 General Statement of the Problem …………………………………………….. 1 Immediate Context of the Problem ……………………………………………. 1 Local Context of the Problem ……………………………………… ………… 6 National Context of the Problem …………………………………………….... 8 CHAPTER 2: PROBLEM DOCUMENTATION ……………………………………. 9 Evidence of the Problem ………………………………………………………. 9 Probable Causes ……………………………………………………………….. 18 CHAPTER 3: THE SOLUTION STRATEGY ………………………………………. 28 Review of the Literature ………………………………………………………. 28 Project Objective and Processing Statements …………………………………. 37 Project Action Plan ……………………………………………………………. 37 Methods of Assessment ……………………………………………………….. 39 CHAPTER 4: PROJECT RESULTS …………………………………………………. 41 Historical Description of the Intervention …………………………………….. 41 Presentation and Analysis of Results …………………………………………. 48 Conclusions and Recommendations ………………………………………….. 54 REFERENCES ………………………………………………………………………… 57 APPENDICES …………………………………………………………………………. 65 Appendix A: Student Survey… ………………………………………………. 65 Appendix B: Parent Survey -

Design Justice: Community-Led Practices to Build the Worlds We
Design Justice Information Policy Series Edited by Sandra Braman The Information Policy Series publishes research on and analysis of significant problems in the field of information policy, including decisions and practices that enable or constrain information, communication, and culture irrespective of the legal siloes in which they have traditionally been located, as well as state- law- society interactions. Defining information policy as all laws, regulations, and decision- making principles that affect any form of information creation, processing, flows, and use, the series includes attention to the formal decisions, decision- making processes, and entities of government; the formal and informal decisions, decision- making processes, and entities of private and public sector agents capable of constitutive effects on the nature of society; and the cultural habits and predispositions of governmentality that support and sustain government and governance. The parametric functions of information policy at the boundaries of social, informational, and technological systems are of global importance because they provide the context for all communications, interactions, and social processes. Virtual Economies: Design and Analysis, Vili Lehdonvirta and Edward Castronova Traversing Digital Babel: Information, e- Government, and Exchange, Alon Peled Chasing the Tape: Information Law and Policy in Capital Markets, Onnig H. Dombalagian Regulating the Cloud: Policy for Computing Infrastructure, edited by Christopher S. Yoo and Jean- François Blanchette Privacy on the Ground: Driving Corporate Behavior in the United States and Europe, Kenneth A. Bamberger and Deirdre K. Mulligan How Not to Network a Nation: The Uneasy History of the Soviet Internet, Benjamin Peters Hate Spin: The Manufacture of Religious Offense and Its Threat to Democracy, Cherian George Big Data Is Not a Monolith, edited by Cassidy R. -

VAGINA Vagina, Pussy, Bearded Clam, Vertical Smile, Beaver, Cunt, Trim, Hair Pie, Bearded Ax Wound, Tuna Taco, Fur Burger, Cooch
VAGINA vagina, pussy, bearded clam, vertical smile, beaver, cunt, trim, hair pie, bearded ax wound, tuna taco, fur burger, cooch, cooter, punani, snatch, twat, lovebox, box, poontang, cookie, fuckhole, love canal, flower, nana, pink taco, cat, catcher's mitt, muff, roast beef curtains, the cum dump, chocha, black hole, sperm sucker, fish sandwich, cock warmer, whisker biscuit, carpet, love hole, deep socket, cum craver, cock squeezer, slice of heaven, flesh cavern, the great divide, cherry, tongue depressor, clit slit, hatchet wound, honey pot, quim, meat massager, chacha, stinkhole, black hole of calcutta, cock socket, pink taco, bottomless pit, dead clam, cum crack, twat, rattlesnake canyon, bush, cunny, flaps, fuzz box, fuzzy wuzzy, gash, glory hole, grumble, man in the boat, mud flaps, mound, peach, pink, piss flaps, the fish flap, love rug, vadge, the furry cup, stench-trench, wizard's sleeve, DNA dumpster, tuna town, split dick, bikini bizkit, cock holster, cockpit, snooch, kitty kat, poody tat, grassy knoll, cold cut combo, Jewel box, rosebud, curly curtains, furry furnace, slop hole, velcro love triangle, nether lips, where Uncle's doodle goes, altar of love, cupid's cupboard, bird's nest, bucket, cock-chafer, love glove, serpent socket, spunk-pot, hairy doughnut, fun hatch, spasm chasm, red lane, stinky speedway, bacon hole, belly entrance, nookie, sugar basin, sweet briar, breakfast of champions, wookie, fish mitten, fuckpocket, hump hole, pink circle, silk igloo, scrambled eggs between the legs, black oak, Republic of Labia, -

Cyber-Bullying Policy
Cyberbullying Policy CHARTERHOUSE This document complies with or has regard to the following: Advice for parents and carers on cyberbullying (Department for Education 2014) Boarding schools: national minimum standards (Department for Education 2015) Cyberbullying: understand, prevent and respond: guidance for schools (Childnet Int. 2016) Keeping children safe in education (Department for Education, 2020) Searching, screening and confiscation (Department for Education 2018) Sexting in Schools and Colleges (UKCCIS, 2016) This document should be read alongside the following Charterhouse policies: Anti-bullying policy (2018) E-safety policy (2020) IT - pupil acceptable use policy (2020) Mobile computing device policy (2020) Safeguarding and child protection policy (2020) Terms used in this policy 1. In this policy, 'platform' refers to any software, website, chatroom, message facility, multimedia 1 mobile or other app(lication) which facilitates electronic communication by voice, social networking, photo1 or video sharing, SMS/MMS or other instant text/image messaging, video or other online chat. Examples include (but are not limited to) Outlook, Facebook, Messenger, WhatsApp, YouTube, Twitter, Snapchat, Instagram, Chatroulette, Skype, Tumblr, Omegle, TikTok and gaming chat rooms. 2. 'Device' refers to any electronic device capable of facilitating the kinds of communication outlined above, including (but not limited to) mobile phones, smartphones, tablets, laptops, PCs and games consoles. 3. This policy relates both to what is done in public (on websites open for others to see) or private (in closed user-groups), and to devices which are controlled both by the School and by pupils personally. 1 Cyberbullying Policy CHARTERHOUSE How we define 'cyberbullying' at Charterhouse 4. Cyberbullying is the use of modern electronic technology to bully other people. -

Signalandnoise
Signal and Noise Can technology provide a window into the new world of digital politics in the UK? Alex Krasodomski-Jones Open Access. Some rights reserved. As the publisher of this work, Demos wants to encourage the circulation of our work as widely as possible while retaining the copyright. We therefore have an open access policy which enables anyone to access our content online without charge. Anyone can download, save, perform or distribute this work in any format, including translation, without written permission. This is subject to the terms of the Demos licence found at the back of this publication. Its main conditions are: · Demos and the author(s) are credited · This summary and the address www.demos.co.uk are displayed · The text is not altered and is used in full · The work is not resold · A copy of the work or link to its use online is sent to Demos. You are welcome to ask for permission to use this work for purposes other than those covered by the licence. Demos gratefully acknowledges the work of Creative Commons in inspiring our approach to copyright. To find out more go to www.creativecommons.org PARTNERS CREDITS This paper was written by the Centre for the Analysis of Social Media (CASM) at Demos in partnership with BCS, The Chartered Institute for IT. BCS, The Chartered Institute for IT, is committed to making IT good for society. We use the power of our network to bring about positive, tangible change. We champion the global IT profession and the interests of individuals, engaged in that profession, for the benefit of all.