The Impact of Event Processing Flow on Asynchronous Server Efficiency 567
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Migrating-To-Red-Hat-Amq-7.Pdf
Red Hat AMQ 2021.Q2 Migrating to Red Hat AMQ 7 For Use with Red Hat AMQ 2021.Q2 Last Updated: 2021-07-26 Red Hat AMQ 2021.Q2 Migrating to Red Hat AMQ 7 For Use with Red Hat AMQ 2021.Q2 Legal Notice Copyright © 2021 Red Hat, Inc. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/ . In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. Node.js ® is an official trademark of Joyent. Red Hat is not formally related to or endorsed by the official Joyent Node.js open source or commercial project. -
Play Framework Documentation
Play framework documentation Welcome to the play framework documentation. This documentation is intended for the 1.1 release and may significantly differs from previous versions of the framework. Check the version 1.1 release notes. The 1.1 branch is in active development. Getting started Your first steps with Play and your first 5 minutes of fun. 1. Play framework overview 2. Watch the screencast 3. Five cool things you can do with Play 4. Usability - details matter as much as features 5. Frequently Asked Questions 6. Installation guide 7. Your first application - the 'Hello World' tutorial 8. Set up your preferred IDE 9. Sample applications 10. Live coding script - to practice, and impress your colleagues with Tutorial - Play guide, a real world app step-by-step Learn Play by coding 'Yet Another Blog Engine', from start to finish. Each chapter will be a chance to learn one more cool Play feature. 1. Starting up the project 2. A first iteration of the data model 3. Building the first screen 4. The comments page 5. Setting up a Captcha 6. Add tagging support 7. A basic admin area using CRUD 8. Adding authentication 9. Creating a custom editor area 10. Completing the application tests 11. Preparing for production 12. Internationalisation and localisation The essential documentation Generated with playframework pdf module. Page 1/264 Everything you need to know about Play. 1. Main concepts i. The MVC application model ii. A request life cycle iii. Application layout & organization iv. Development lifecycle 2. HTTP routing i. The routes file syntax ii. Routes priority iii. -

The Netty Project 3.2 User Guide the Proven Approach to Rapid Network
The Netty Project 3.2 User Guide The Proven Approach to Rapid Network Application Development 3.2.6.Final Preface .............................................................................................................................. iii 1. The Problem ........................................................................................................... iii 2. The Solution ........................................................................................................... iii 1. Getting Started ............................................................................................................... 1 1.1. Before Getting Started ............................................................................................ 1 1.2. Writing a Discard Server ......................................................................................... 1 1.3. Looking into the Received Data ................................................................................ 3 1.4. Writing an Echo Server ........................................................................................... 4 1.5. Writing a Time Server ............................................................................................ 5 1.6. Writing a Time Client ............................................................................................. 7 1.7. Dealing with a Stream-based Transport ...................................................................... 8 1.7.1. One Small Caveat of Socket Buffer ................................................................ -
HCP-CS Third-Party Software V1.1
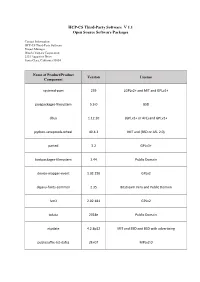
HCP-CS Third-Party Software V 1.1 Open Source Software Packages Contact Information: HCP-CS Third-Party Software Project Manager Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component systemd-pam 239 LGPLv2+ and MIT and GPLv2+ javapackages-filesystem 5.3.0 BSD dbus 1.12.10 (GPLv2+ or AFL) and GPLv2+ python-setuptools-wheel 40.4.3 MIT and (BSD or ASL 2.0) parted 3.2 GPLv3+ fontpackages-filesystem 1.44 Public Domain device-mapper-event 1.02.150 GPLv2 dejavu-fonts-common 2.35 Bitstream Vera and Public Domain lvm2 2.02.181 GPLv2 tzdata 2018e Public Domain ntpdate 4.2.8p12 MIT and BSD and BSD with advertising publicsuffix-list-dafsa 2E+07 MPLv2.0 Name of Product/Product Version License Component subversion-libs 1.10.2 ASL 2.0 ncurses-base 6.1 MIT javapackages-tools 5.3.0 BSD libX11-common 1.6.6 MIT apache-commons-pool 1.6 ASL 2.0 dnf-data 4.0.4 GPLv2+ and GPLv2 and GPL junit 4.12 EPL-1.0 fedora-release 29 MIT log4j12 1.2.17 ASL 2.0 setup 2.12.1 Public Domain cglib 3.2.4 ASL 2.0 and BSD basesystem 11 Public Domain slf4j 1.7.25 MIT and ASL 2.0 libselinux 2.8 Public Domain tomcat-lib 9.0.10 ASL 2.0 Name of Product/Product Version License Component LGPLv2+ and LGPLv2+ with exceptions and GPLv2+ glibc-all-langpacks 2.28 and GPLv2+ with exceptions and BSD and Inner-Net and ISC and Public Domain and GFDL antlr-tool 2.7.7 ANTLR-PD LGPLv2+ and LGPLv2+ with exceptions and GPLv2+ glibc 2.28 and GPLv2+ with exceptions and BSD and Inner-Net and ISC and Public Domain and GFDL apache-commons-daemon -

Vert.X in Action MEAP
MEAP Edition Manning Early Access Program Vert.x in Action Version 1 Copyright 2018 Manning Publications For more information on this and other Manning titles go to www.manning.com ©Manning Publications Co. We welcome reader comments about anything in the manuscript - other than typos and other simple mistakes. These will be cleaned up during production of the book by copyeditors and proofreaders. https://forums.manning.com/forums/vertx-in-action welcome Thank you for purchasing the MEAP of Vert.x in Action. Asynchronous and reactive applications are an important topic in modern distributed systems, especially as the progressive shift to virtualized and containerized runtime environments emphasize the need for resource efficient, adaptable and dependable application designs. Asynchronous programming is key to maximizing hardware resource usage, as it allows dealing with more concurrent connections than with the traditional blocking I/O paradigms. Services need to cater for workloads that may drastically change throughout from one hour to the other, hence we need to design code that naturally supports horizontal scalability. Last but not least, failure is inevitable when we have services interacting with other services over the network. Embracing failure is key for designing dependable systems. Assemble asynchronous programming, horizontal scalability, resilience and you have what we call today reactive applications, which can also be summarized without marketing jargon as “scalable and dependable applications”. That being said there is no free lunch and the transition to writing asynchronous and reactive applications is difficult when you have a background in more traditional software stacks. Grokking asynchrony in itself is difficult, but the implications of scalability and resilience on the design of an application are anything but trivial. -

Open Source Used in DNA Apps - Assurance Edge Assurance 1.0
Open Source Used In DNA Apps - Assurance Edge Assurance 1.0 Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-1132399293 Open Source Used In DNA Apps - Assurance Edge Assurance 1.0 1 This document contains licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of any source code to which you may be entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-1132399293 Contents 1.1 metrics-servlets 4.1.0 1.2 reactor-netty 0.9.7.RELEASE 1.2.1 Available under license 1.3 jakarta-ws-rs-api 2.1.5 1.3.1 Available under license 1.4 jetty-util 9.4.18.v20190429 1.4.1 Available under license 1.5 jsr305 3.0.2 1.6 woodstox-core-asl 4.4.1 1.7 snake-yaml 1.24 1.7.1 Available under license 1.8 profiler 1.0.2 1.9 joda-time 2.9.1 1.9.1 Available under license 1.10 rsocket-transport-netty 1.0.0-RC7 1.10.1 Available under license 1.11 slf4j 1.7.26 1.11.1 Available under license 1.12 stax-api 1.0-2 1.13 mongodb-driver-core 3.6.4 1.14 jetty-client 9.4.18.v20190429 1.14.1 Available under license 1.15 grpc-stub 1.9.0 1.16 jakarta-inject 2.5.0 1.16.1 Available under license 1.17 log4j-slf4j-impl -

Play for Java MEAP V2
MEAP Edition Manning Early Access Program Play for Java version 2 Copyright 2012 Manning Publications For more information on this and other Manning titles go to www.manning.com ©Manning Publications Co. Please post comments or corrections to the Author Online forum: http://www.manning-sandbox.com/forum.jspa?forumID=811 Licensed to Yuri Delfino <[email protected]> brief contents PART I: INTRODUCTION AND FIRST STEPS 1. Introduction to Play 2 2. The parts of an application 3. A basic CRUD application PART II: CORE FUNCTIONALITY 4. An enterprise app, Play-style 5. Models and persistence 6. Controllers—handling HTTP requests 7. Handling user input 8. View templates—producing output 9. Security 10. Testing your applications 11. Deployment PART III: ADVANCE TOPICS 12. Client-side development and Play 13. SBT project management 14. Convenience libraries 15. Cloud integration ©Manning Publications Co. Please post comments or corrections to the Author Online forum: http://www.manning-sandbox.com/forum.jspa?forumID=811 Licensed to Yuri Delfino <[email protected]> 1 Introduction to1 Play 2 This chapter covers: What the Play framework is What high-productivity web frameworks are about Why Play supports both Java and Scala What a minimal Play application looks like Play isn’t really a Java web framework. Java’s involved, but that isn’t the whole story. The first version of Play may have been written in the Java language, but it also ignored the conventions of the Java platform, providing a fresh alternative to excessive enterprise architectures. Play was not based on Java Enterprise Edition APIs and made for Java developers. -

Play Framework Recipes V0.2
1 Play Framework Recipes Copyright 2013 Alvin J. Alexander All rights reserved. No part of this book may be reproduced without prior written permission from the author. Disclaimer: This book is presented solely for educational and entertainment purposes. The author and publisher are not offering it as legal, accounting, or other professional services advice. While best efforts have been used in preparing this book, the author and publisher make no representations or warranties of any kind and assume no liabilities of any kind with respect to the accuracy or completeness of the contents and specifically disclaim any implied warranties of merchantability or fitness of use for a particular purpose. Neither the author nor the publisher shall be held liable or responsible to any person or entity with respect to any loss or incidental or consequential damages caused, or alleged to have been caused, directly or indirectly, by the information or programs contained herein. No warranty may be created or extended by sales representatives or written sales materials. Every company is different and the advice and strategies contained herein may not be suitable for your situation. You should seek the services of a competent professional before beginning any improvement program. Second edition, published August 12, 2013 (the “0.2” release) First edition, published August 1, 2013 (the “0.1” release) 2 Table of Contents Preface................................................................................................................................. -

HTTP/2: Analysis and Measurements
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Universidad Carlos III de Madrid e-Archivo UNIVERSIDAD CARLOS III DE MADRID ESCUELA POLITÉCNICA SUPERIOR DEPARTAMENTO DE INGENIERÍA TELEMÁTICA ITT: Sistemas de Telecomunicaciones Proyecto Fin de Carrera HTTP/2: Analysis and measurements Author: José Fernando Calcerrada Cano Tutor: Marcelo Bagnulo Braun Cotutor: Anna Maria Mandalari January 2016 “This, Jen, is the Internet.” Maurice Moss, IT Crowd. Abstract HTTP/2: Analysis and measurements by José Fernando Calcerrada Cano The upgrade of HTTP, the protocol that powers the Internet of the people, was published as RFC on May of 2015. HTTP/2 aims to improve the users experience by solving well- know problems of HTTP/1.1 and also introducing new features. The main goal of this project is to study HTTP/2 protocol, the support in the software, its deployment and im- plementation on the Internet and how the network reacts to an upgrade of the existing protocol. To shed some light on this question we build two experiments. We build a crawler to monitor the HTTP/2 adoption across Internet using the Alexa top 1 million websites as sample. We find that 22,653 servers announce support for HTTP/2, but only 10,162 websites are served over it. The support for HTTP/2 Upgrade is minimal, just 16 servers support it and only 10 of them load the content of the websites over HTTP/2 on plain TCP. Motivated by those numbers, we investigate how the new protocol behaves with the middleboxes along the path in the network. -

Dell EMC Powerstore Open Source License and Copyright Information
Open Source License and Copyright Information Dell EMC PowerStore Open Source License and Copyright Information June 2021 Rev A04 Revisions Revisions Date Description May 2020 Initial release September 2020 Version updates for some licenses and addition of iwpmd component December 2020 Version updates for some licenses, and addition and deletion of other components January 2021 Version updates for some licenses June 2021 Version updates for some licenses, and addition and deletion of other components The information in this publication is provided “as is.” Dell Inc. makes no representations or warranties of any kind with respect to the information in this publication, and specifically disclaims implied warranties of merchantability or fitness for a particular purpose. Use, copying, and distribution of any software described in this publication requires an applicable software license. Copyright © 2020-2021 Dell Inc. or its subsidiaries. All Rights Reserved. Dell Technologies, Dell, EMC, Dell EMC and other trademarks are trademarks of Dell Inc. or its subsidiaries. Other trademarks may be trademarks of their respective owners. [6/1/2021] [Open Source License and Copyright Information] [Rev A04] 2 Dell EMC PowerStore: Open Source License and Copyright Information Table of contents Table of contents Revisions............................................................................................................................................................................. 2 Table of contents ............................................................................................................................................................... -

Integration of Jboss Undertow HTTP Server with Apache Camel Project
Masarykova univerzita Fakulta}w¡¢£¤¥¦§¨ informatiky !"#$%&'()+,-./012345<yA| Integration of JBoss Undertow HTTP server with Apache Camel project Master’s thesis Dávid Šimanský Brno, Autumn 2014 Declaration Hereby I declare, that this paper is my original authorial work, which I have worked out by my own. All sources, references and literature used or excerpted during elaboration of this work are properly cited and listed in complete reference to the due source. Dávid Šimanský Advisor: Mgr. Marek Grác, PhD. ii Acknowledgement I would like to thank to my supervisor Mgr. Marek Grác, Ph.D. and my technical supervisor from Red Hat Czech, s.r.o, Mgr. Jiří Sedláček, for providing constant feedback during the preparation of this master’s thesis. Many thanks goes to all my other colleagues from Red Hat that expressed their valuable thoughts and helped to make this thesis better. iii Abstract The purpose of this master’s thesis is to design and develop new Camel component by integrating two open-source project Apache Camel and JBoss Undertow. This new component will act as HTTP provider in the Camel integration framework. iv Keywords Apache Camel, Undertow, Java NIO, XNIO, integration framework, web server, component v Contents 1 Introduction ...........................3 2 Technologies ...........................5 2.1 Apache Camel ........................5 2.1.1 Fundamental principles of Camel . .5 2.1.2 Message types . .8 2.1.3 Architecture overview . .9 2.2 Component development .................. 12 2.3 Integration in action .................... 14 2.4 Java NIO .......................... 15 2.5 XNIO ............................ 17 2.6 Undertow .......................... 17 2.6.1 Embedded server . 18 2.6.2 Performance benchmark . -

Netty Content Is Distributed in Accordance with the Following License Agreement(S)
Netty content is distributed in accordance with the following license agreement(s): The Netty Project ================= Please visit the Netty web site for more information: * http://netty.io/ Copyright 2014 The Netty Project The Netty Project licenses this file to you under the Apache License, version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at: http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. Also, please refer to each LICENSE.<component>.txt file, which is located in the 'license' directory of the distribution file, for the license terms of the components that this product depends on. ----------------------------------------------------------------------------- -- This product contains the extensions to Java Collections Framework which has been derived from the works by JSR-166 EG, Doug Lea, and Jason T. Greene: * LICENSE: * license/LICENSE.jsr166y.txt (Public Domain) * HOMEPAGE: * http://gee.cs.oswego.edu/cgi-bin/viewcvs.cgi/jsr166/ * http://viewvc.jboss.org/cgi- bin/viewvc.cgi/jbosscache/experimental/jsr166/ This product contains a modified version of Robert Harder's Public Domain Base64 Encoder and Decoder, which can be obtained at: * LICENSE: * license/LICENSE.base64.txt