Event-Driven I/O a Hands-On Introduction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Alexander, Kleymenov
Alexander, Kleymenov Key Skills ▪ Ruby ▪ JavaScript ▪ C/C++ ▪ SQL ▪ PL/SQL ▪ XML ▪ UML ▪ Ruby on Rails ▪ EventMachine ▪ Sinatra ▪ JQuery ▪ ExtJS ▪ Databases: Oracle (9i,10g), MySQL, PostgreSQL, MS SQL ▪ noSQL: CouchDB, MongoDB ▪ Messaging: RabbitMQ ▪ Platforms: Linux, Solaris, MacOS X, Windows ▪ Testing: RSpec ▪ TDD, BDD ▪ SOA, OLAP, Data Mining ▪ Agile, Scrum Experience May 2017 – June 2018 Digitalkasten Internet GmbH (Germany, Berlin) Lead Developer B2B & B2C SaaS: Development from the scratch. Ruby, Ruby on Rails, Golang, Elasticsearch, Ruby, Ruby on Rails, Golang, Elasticsearch, Postgresql, Javascript, AngularJS 2 / Angular 5, Ionic 2 & 3, Apache Cordova, RabbitMQ, OpenStack January 2017 – April 2017 (project work) Stellenticket Gmbh (Germany, Berlin) Lead developer Application prototype development with Ruby, Ruby on Rails, Javascript, Backbone.js, Postgresql. September 2016 – December 2016 Part-time work & studying German in Goethe-Institut e.V. (Germany, Berlin) Freelancer & Student Full-stack developer and German A1. May 2016 – September 2016 Tridion Assets Management Gmbh (Germany, Berlin) Team Lead Development team managing. Develop and implement architecture of application HRLab (application for HRs). Software development trainings for team. Planning of software development and life cycle. Ruby, Ruby on Rails, Javascript, Backbone.js, Postgresql, PL/pgSQL, Golang, Redis, Salesforce API November 2015 – May 2016 (Germany, Berlin) Ecratum Gmbh Ruby, Ruby on Rails developer ERP/CRM - Application development with: Ruby 2, RoR4, PostgreSQL, Redis/Elastic, EventMachine, MessageBus, Puma, AWS/EC2, etc. April 2014 — November 2015 (Russia, Moscow - Australia, Melbourne - Munich, Germany - Berlin, Germany) Freelance/DHARMA Dev. Ruby, Ruby on Rails developer notarikon.net Application development with: Ruby 2, RoR 4, PostgreSQL, MongoDB, Javascript (CoffeeScript), AJAX, jQuery, Websockets, Redis + own project: http://featmeat.com – complex service for health control: trainings tracking and data providing to medical adviser. -

Leader/Followers
Leader/Followers Douglas C. Schmidt, Carlos O’Ryan, Michael Kircher, Irfan Pyarali, and Frank Buschmann {schmidt, coryan}@uci.edu, {Michael.Kircher, Frank.Buschmann}@mchp.siemens.de, [email protected] University of California at Irvine, Siemens AG, and Washington University in Saint Louis The Leader/Followers architectural pattern provides an efficient concurrency model where multiple threads take turns sharing a set of event sources in order to detect, de- multiplex, dispatch, and process service requests that occur on these event sources. Example Consider the design of a multi-tier, high-volume, on-line transaction processing (OLTP) system. In this design, front-end communication servers route transaction requests from remote clients, such as travel agents, claims processing centers, or point-of-sales terminals, to back-end database servers that process the requests transactionally. After a transaction commits, the database server returns its results to the associated communication server, which then forwards the results back to the originating remote client. This multi-tier architecture is used to improve overall system throughput and reliability via load balancing and redundancy, respectively.It LAN WAN Front-End Back-End Clients Communication Servers Database Servers also relieves back-end servers from the burden of managing different communication protocols with clients. © Douglas C. Schmidt 1998 - 2000, all rights reserved, © Siemens AG 1998 - 2000, all rights reserved 19.06.2000 lf.doc 2 Front-end communication servers are actually ``hybrid'' client/server applications that perform two primary tasks: 1 They receive requests arriving simultaneously from hundreds or thousands of remote clients over wide area communication links, such as X.25 or TCP/IP. -

A Survey of Architectural Styles.V4
Survey of Architectural Styles Alexander Bird, Bianca Esguerra, Jack Li Liu, Vergil Marana, Jack Kha Nguyen, Neil Oluwagbeminiyi Okikiolu, Navid Pourmantaz Department of Software Engineering University of Calgary Calgary, Canada Abstract— In software engineering, an architectural style is a and implementation; the capabilities and experience of highest-level description of an accepted solution to a common developers; and the infrastructure and organizational software problem. This paper describes and compares a selection constraints [30]. These styles are not presented as out-of-the- of nine accepted architectural styles selected by the authors and box solutions, but rather a framework within which a specific applicable in various domains. Each pattern is presented in a software design may be made. If one were to say “that cannot general sense and with a domain example, and then evaluated in be called a layered architecture because the such and such a terms of benefits and drawbacks. Then, the styles are compared layer must communicate with an object other than the layer in a condensed table of advantages and disadvantages which is above and below it” then one would have missed the point of useful both as a summary of the architectural styles as well as a architectural styles and design patterns. They are not intended tool for selecting a style to apply to a particular project. The to be definitive and final, but rather suggestive and a starting paper is written to accomplish the following purposes: (1) to give readers a general sense of several architectural styles and when point, not to be used as a rule book but rather a source of and when not to apply them, (2) to facilitate software system inspiration. -

Distributed Programming with Ruby
DISTRIBUTED PROGRAMMING WITH RUBY Mark Bates Upper Saddle River, NJ • Boston • Indianapolis • San Francisco New York • Toronto • Montreal • London • Munich • Paris • Madrid Capetown • Sydney • Tokyo • Singapore • Mexico City Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the pub- lisher was aware of a trademark claim, the designations have been printed with initial Editor-in-Chief capital letters or in all capitals. Mark Taub The author and publisher have taken care in the preparation of this book, but make no Acquisitions Editor expressed or implied warranty of any kind and assume no responsibility for errors or Debra Williams Cauley omissions. No liability is assumed for incidental or consequential damages in connection Development Editor with or arising out of the use of the information or programs contained herein. Songlin Qiu The publisher offers excellent discounts on this book when ordered in quantity for bulk Managing Editor purchases or special sales, which may include electronic versions and/or custom covers Kristy Hart and content particular to your business, training goals, marketing focus, and branding Senior Project Editor interests. For more information, please contact: Lori Lyons U.S. Corporate and Government Sales Copy Editor 800-382-3419 Gayle Johnson [email protected] Indexer For sales outside the United States, please contact: Brad Herriman Proofreader International Sales Apostrophe Editing [email protected] Services Visit us on the web: informit.com/ph Publishing Coordinator Kim Boedigheimer Library of Congress Cataloging-in-Publication Data: Cover Designer Bates, Mark, 1976- Chuti Prasertsith Distributed programming with Ruby / Mark Bates. -

The Need for Hardware/Software Codesign Patterns - a Toolbox for the New Digital Designer
The need for Hardware/Software CoDesign Patterns - a toolbox for the new Digital Designer By Senior Consultant Carsten Siggaard, Danish Technological Institute May 30. 2008 Abstract Between hardware and software the level of abstraction has always differed a lot, this is not a surprise, hardware is an abstraction for software and the topics which is considered important by either a hardware developer or a software developer are quite different, making the communication between software and hardware developers (or even departments) difficult. In this report the software concept of design patterns is expanded into hardware, and the need for a new kind of design pattern, The Digital Design Pattern, is announced. Copyright © 2008 Danish Technological Institute Page 1 of 20 Contents Contents ............................................................................................................................................... 2 Background .......................................................................................................................................... 4 What is a design pattern ....................................................................................................................... 4 Three Disciplines when using Design Patterns ................................................................................ 5 Pattern Hatching ........................................................................................................................... 6 Pattern Mining............................................................................................................................. -

Migrating-To-Red-Hat-Amq-7.Pdf
Red Hat AMQ 2021.Q2 Migrating to Red Hat AMQ 7 For Use with Red Hat AMQ 2021.Q2 Last Updated: 2021-07-26 Red Hat AMQ 2021.Q2 Migrating to Red Hat AMQ 7 For Use with Red Hat AMQ 2021.Q2 Legal Notice Copyright © 2021 Red Hat, Inc. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/ . In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. Node.js ® is an official trademark of Joyent. Red Hat is not formally related to or endorsed by the official Joyent Node.js open source or commercial project. -
Play Framework Documentation
Play framework documentation Welcome to the play framework documentation. This documentation is intended for the 1.1 release and may significantly differs from previous versions of the framework. Check the version 1.1 release notes. The 1.1 branch is in active development. Getting started Your first steps with Play and your first 5 minutes of fun. 1. Play framework overview 2. Watch the screencast 3. Five cool things you can do with Play 4. Usability - details matter as much as features 5. Frequently Asked Questions 6. Installation guide 7. Your first application - the 'Hello World' tutorial 8. Set up your preferred IDE 9. Sample applications 10. Live coding script - to practice, and impress your colleagues with Tutorial - Play guide, a real world app step-by-step Learn Play by coding 'Yet Another Blog Engine', from start to finish. Each chapter will be a chance to learn one more cool Play feature. 1. Starting up the project 2. A first iteration of the data model 3. Building the first screen 4. The comments page 5. Setting up a Captcha 6. Add tagging support 7. A basic admin area using CRUD 8. Adding authentication 9. Creating a custom editor area 10. Completing the application tests 11. Preparing for production 12. Internationalisation and localisation The essential documentation Generated with playframework pdf module. Page 1/264 Everything you need to know about Play. 1. Main concepts i. The MVC application model ii. A request life cycle iii. Application layout & organization iv. Development lifecycle 2. HTTP routing i. The routes file syntax ii. Routes priority iii. -

The Netty Project 3.2 User Guide the Proven Approach to Rapid Network
The Netty Project 3.2 User Guide The Proven Approach to Rapid Network Application Development 3.2.6.Final Preface .............................................................................................................................. iii 1. The Problem ........................................................................................................... iii 2. The Solution ........................................................................................................... iii 1. Getting Started ............................................................................................................... 1 1.1. Before Getting Started ............................................................................................ 1 1.2. Writing a Discard Server ......................................................................................... 1 1.3. Looking into the Received Data ................................................................................ 3 1.4. Writing an Echo Server ........................................................................................... 4 1.5. Writing a Time Server ............................................................................................ 5 1.6. Writing a Time Client ............................................................................................. 7 1.7. Dealing with a Stream-based Transport ...................................................................... 8 1.7.1. One Small Caveat of Socket Buffer ................................................................ -

Django and Mongodb
1. .bookmarks . 5 2. 1.1 Development Cycle . 5 3. Creating and Deleting Indexes . 5 4. Diagnostic Tools . 5 5. Django and MongoDB . 5 6. Getting Started . 5 7. International Documentation . 6 8. Monitoring . 6 9. Older Downloads . 6 10. PyMongo and mod_wsgi . 6 11. Python Tutorial . 6 12. Recommended Production Architectures . 6 13. Shard v0.7 . 7 14. v0.8 Details . 7 15. v0.9 Details . 7 16. v1.0 Details . 7 17. v1.5 Details . 7 18. v2.0 Details . 8 19. Building SpiderMonkey . 8 20. Documentation . 8 21. Dot Notation . 8 22. Dot Notation . 23. Getting the Software . 8 24. Language Support . 8 25. Mongo Administration Guide . 9 26. Working with Mongo Objects and Classes in Ruby . 9 27. MongoDB Language Support . 9 28. Community Info . 9 29. Internals . 9 30. TreeNavigation . 10 31. Old Pages . 10 31.1 Storing Data . 10 31.2 Indexes in Mongo . 10 31.3 HowTo . 10 31.4 Searching and Retrieving . 10 31.4.1 Locking . 10 31.5 Mongo Developers' Guide . 11 31.6 Locking in Mongo . 11 31.7 Mongo Database Administration . .. -

Active Object
Active Object an Object Behavioral Pattern for Concurrent Programming R. Greg Lavender Douglas C. Schmidt [email protected] [email protected] ISODE Consortium Inc. Department of Computer Science Austin, TX Washington University, St. Louis An earlier version of this paper appeared in a chapter in the book ªPattern Languages of Program Design 2º ISBN 0-201-89527-7, edited by John Vlissides, Jim Coplien, and Norm Kerth published by Addison-Wesley, 1996. : Output : Input Handler Handler : Routing Table : Message Abstract Queue This paper describes the Active Object pattern, which decou- 3: enqueue(msg) ples method execution from method invocation in order to : Output 2: find_route(msg) simplify synchronized access to a shared resource by meth- Handler ods invoked in different threads of control. The Active Object : Message : Input pattern allows one or more independent threads of execution Queue Handler 1: recv(msg) to interleave their access to data modeled as a single ob- ject. A broad class of producer/consumer and reader/writer OUTGOING OUTGOING MESSAGES GATEWAY problems are well-suited to this model of concurrency. This MESSAGES pattern is commonly used in distributed systems requiring INCOMING INCOMING multi-threaded servers. In addition,client applications (such MESSAGES MESSAGES as windowing systems and network browsers), are increas- DST DST ingly employing active objects to simplify concurrent, asyn- SRC SRC chronous network operations. 1 Intent Figure 1: Connection-Oriented Gateway The Active Object pattern decouples method execution from method invocation in order to simplify synchronized access to a shared resource by methods invoked in different threads [2]. Sources and destinationscommunicate with the Gateway of control. -
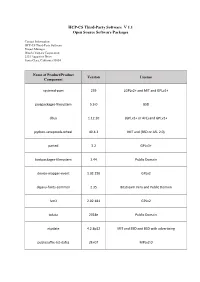
HCP-CS Third-Party Software V1.1
HCP-CS Third-Party Software V 1.1 Open Source Software Packages Contact Information: HCP-CS Third-Party Software Project Manager Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component systemd-pam 239 LGPLv2+ and MIT and GPLv2+ javapackages-filesystem 5.3.0 BSD dbus 1.12.10 (GPLv2+ or AFL) and GPLv2+ python-setuptools-wheel 40.4.3 MIT and (BSD or ASL 2.0) parted 3.2 GPLv3+ fontpackages-filesystem 1.44 Public Domain device-mapper-event 1.02.150 GPLv2 dejavu-fonts-common 2.35 Bitstream Vera and Public Domain lvm2 2.02.181 GPLv2 tzdata 2018e Public Domain ntpdate 4.2.8p12 MIT and BSD and BSD with advertising publicsuffix-list-dafsa 2E+07 MPLv2.0 Name of Product/Product Version License Component subversion-libs 1.10.2 ASL 2.0 ncurses-base 6.1 MIT javapackages-tools 5.3.0 BSD libX11-common 1.6.6 MIT apache-commons-pool 1.6 ASL 2.0 dnf-data 4.0.4 GPLv2+ and GPLv2 and GPL junit 4.12 EPL-1.0 fedora-release 29 MIT log4j12 1.2.17 ASL 2.0 setup 2.12.1 Public Domain cglib 3.2.4 ASL 2.0 and BSD basesystem 11 Public Domain slf4j 1.7.25 MIT and ASL 2.0 libselinux 2.8 Public Domain tomcat-lib 9.0.10 ASL 2.0 Name of Product/Product Version License Component LGPLv2+ and LGPLv2+ with exceptions and GPLv2+ glibc-all-langpacks 2.28 and GPLv2+ with exceptions and BSD and Inner-Net and ISC and Public Domain and GFDL antlr-tool 2.7.7 ANTLR-PD LGPLv2+ and LGPLv2+ with exceptions and GPLv2+ glibc 2.28 and GPLv2+ with exceptions and BSD and Inner-Net and ISC and Public Domain and GFDL apache-commons-daemon -

Performance Analysis of the Reactor Pattern in Network Services
Performance Analysis of the Reactor Pattern in Network Services Swapna Gokhale1, Aniruddha Gokhale2, Jeff Gray3, Paul Vandal1, Upsorn Praphamontripong1 1University of Connecticut 2Vanderbilt University Dept. of Computer Science Dept. of Electrical Engineering and Engineering and Computer Science Storrs, CT 06269 USA Nashville, TN 37235 USA [email protected] [email protected] 3University of Alabama at Birmingham Dept of Computer and Information Science Birmingham, AL USA [email protected] Abstract 1. Introduction Service oriented computing (SoC), which is made feasi- ble by middleware-based distributed systems, is an emerg- ing technology to provide the next-generation services to meet societal needs ranging from basic necessities, such as The growing reliance on services provided by software education, energy, communications and healthcare to emer- applications places a high premium on the reliable and ef- gency and disaster management. For SOC to be successful ficient operation of these applications. A number of these in meeting the demands of society, assurance on the perfor- applications follow the event-driven software architecture mance of these services is necessary. Since these services style since this style fosters evolvability by separating event are primarily built using communication middleware, the handling from event demultiplexing and dispatching func- problem reduces to the issue of performance assurance of tionality. The event demultiplexing capability, which ap- the middleware platforms. pears repeatedly across a class of event-driven applica- Middleware typically comprises a number of building tions, can be codified into a reusable pattern, such as the blocks, which are essentially patterns-based reusable soft- Reactor pattern. In order to enable performance analysis of ware frameworks.