And Actor-Driven Paradigms to Increase Web Application Performance
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Alexander, Kleymenov
Alexander, Kleymenov Key Skills ▪ Ruby ▪ JavaScript ▪ C/C++ ▪ SQL ▪ PL/SQL ▪ XML ▪ UML ▪ Ruby on Rails ▪ EventMachine ▪ Sinatra ▪ JQuery ▪ ExtJS ▪ Databases: Oracle (9i,10g), MySQL, PostgreSQL, MS SQL ▪ noSQL: CouchDB, MongoDB ▪ Messaging: RabbitMQ ▪ Platforms: Linux, Solaris, MacOS X, Windows ▪ Testing: RSpec ▪ TDD, BDD ▪ SOA, OLAP, Data Mining ▪ Agile, Scrum Experience May 2017 – June 2018 Digitalkasten Internet GmbH (Germany, Berlin) Lead Developer B2B & B2C SaaS: Development from the scratch. Ruby, Ruby on Rails, Golang, Elasticsearch, Ruby, Ruby on Rails, Golang, Elasticsearch, Postgresql, Javascript, AngularJS 2 / Angular 5, Ionic 2 & 3, Apache Cordova, RabbitMQ, OpenStack January 2017 – April 2017 (project work) Stellenticket Gmbh (Germany, Berlin) Lead developer Application prototype development with Ruby, Ruby on Rails, Javascript, Backbone.js, Postgresql. September 2016 – December 2016 Part-time work & studying German in Goethe-Institut e.V. (Germany, Berlin) Freelancer & Student Full-stack developer and German A1. May 2016 – September 2016 Tridion Assets Management Gmbh (Germany, Berlin) Team Lead Development team managing. Develop and implement architecture of application HRLab (application for HRs). Software development trainings for team. Planning of software development and life cycle. Ruby, Ruby on Rails, Javascript, Backbone.js, Postgresql, PL/pgSQL, Golang, Redis, Salesforce API November 2015 – May 2016 (Germany, Berlin) Ecratum Gmbh Ruby, Ruby on Rails developer ERP/CRM - Application development with: Ruby 2, RoR4, PostgreSQL, Redis/Elastic, EventMachine, MessageBus, Puma, AWS/EC2, etc. April 2014 — November 2015 (Russia, Moscow - Australia, Melbourne - Munich, Germany - Berlin, Germany) Freelance/DHARMA Dev. Ruby, Ruby on Rails developer notarikon.net Application development with: Ruby 2, RoR 4, PostgreSQL, MongoDB, Javascript (CoffeeScript), AJAX, jQuery, Websockets, Redis + own project: http://featmeat.com – complex service for health control: trainings tracking and data providing to medical adviser. -

Distributed Programming with Ruby
DISTRIBUTED PROGRAMMING WITH RUBY Mark Bates Upper Saddle River, NJ • Boston • Indianapolis • San Francisco New York • Toronto • Montreal • London • Munich • Paris • Madrid Capetown • Sydney • Tokyo • Singapore • Mexico City Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the pub- lisher was aware of a trademark claim, the designations have been printed with initial Editor-in-Chief capital letters or in all capitals. Mark Taub The author and publisher have taken care in the preparation of this book, but make no Acquisitions Editor expressed or implied warranty of any kind and assume no responsibility for errors or Debra Williams Cauley omissions. No liability is assumed for incidental or consequential damages in connection Development Editor with or arising out of the use of the information or programs contained herein. Songlin Qiu The publisher offers excellent discounts on this book when ordered in quantity for bulk Managing Editor purchases or special sales, which may include electronic versions and/or custom covers Kristy Hart and content particular to your business, training goals, marketing focus, and branding Senior Project Editor interests. For more information, please contact: Lori Lyons U.S. Corporate and Government Sales Copy Editor 800-382-3419 Gayle Johnson [email protected] Indexer For sales outside the United States, please contact: Brad Herriman Proofreader International Sales Apostrophe Editing [email protected] Services Visit us on the web: informit.com/ph Publishing Coordinator Kim Boedigheimer Library of Congress Cataloging-in-Publication Data: Cover Designer Bates, Mark, 1976- Chuti Prasertsith Distributed programming with Ruby / Mark Bates. -

Migrating-To-Red-Hat-Amq-7.Pdf
Red Hat AMQ 2021.Q2 Migrating to Red Hat AMQ 7 For Use with Red Hat AMQ 2021.Q2 Last Updated: 2021-07-26 Red Hat AMQ 2021.Q2 Migrating to Red Hat AMQ 7 For Use with Red Hat AMQ 2021.Q2 Legal Notice Copyright © 2021 Red Hat, Inc. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/ . In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. Node.js ® is an official trademark of Joyent. Red Hat is not formally related to or endorsed by the official Joyent Node.js open source or commercial project. -
Play Framework Documentation
Play framework documentation Welcome to the play framework documentation. This documentation is intended for the 1.1 release and may significantly differs from previous versions of the framework. Check the version 1.1 release notes. The 1.1 branch is in active development. Getting started Your first steps with Play and your first 5 minutes of fun. 1. Play framework overview 2. Watch the screencast 3. Five cool things you can do with Play 4. Usability - details matter as much as features 5. Frequently Asked Questions 6. Installation guide 7. Your first application - the 'Hello World' tutorial 8. Set up your preferred IDE 9. Sample applications 10. Live coding script - to practice, and impress your colleagues with Tutorial - Play guide, a real world app step-by-step Learn Play by coding 'Yet Another Blog Engine', from start to finish. Each chapter will be a chance to learn one more cool Play feature. 1. Starting up the project 2. A first iteration of the data model 3. Building the first screen 4. The comments page 5. Setting up a Captcha 6. Add tagging support 7. A basic admin area using CRUD 8. Adding authentication 9. Creating a custom editor area 10. Completing the application tests 11. Preparing for production 12. Internationalisation and localisation The essential documentation Generated with playframework pdf module. Page 1/264 Everything you need to know about Play. 1. Main concepts i. The MVC application model ii. A request life cycle iii. Application layout & organization iv. Development lifecycle 2. HTTP routing i. The routes file syntax ii. Routes priority iii. -

The Netty Project 3.2 User Guide the Proven Approach to Rapid Network
The Netty Project 3.2 User Guide The Proven Approach to Rapid Network Application Development 3.2.6.Final Preface .............................................................................................................................. iii 1. The Problem ........................................................................................................... iii 2. The Solution ........................................................................................................... iii 1. Getting Started ............................................................................................................... 1 1.1. Before Getting Started ............................................................................................ 1 1.2. Writing a Discard Server ......................................................................................... 1 1.3. Looking into the Received Data ................................................................................ 3 1.4. Writing an Echo Server ........................................................................................... 4 1.5. Writing a Time Server ............................................................................................ 5 1.6. Writing a Time Client ............................................................................................. 7 1.7. Dealing with a Stream-based Transport ...................................................................... 8 1.7.1. One Small Caveat of Socket Buffer ................................................................ -

Django and Mongodb
1. .bookmarks . 5 2. 1.1 Development Cycle . 5 3. Creating and Deleting Indexes . 5 4. Diagnostic Tools . 5 5. Django and MongoDB . 5 6. Getting Started . 5 7. International Documentation . 6 8. Monitoring . 6 9. Older Downloads . 6 10. PyMongo and mod_wsgi . 6 11. Python Tutorial . 6 12. Recommended Production Architectures . 6 13. Shard v0.7 . 7 14. v0.8 Details . 7 15. v0.9 Details . 7 16. v1.0 Details . 7 17. v1.5 Details . 7 18. v2.0 Details . 8 19. Building SpiderMonkey . 8 20. Documentation . 8 21. Dot Notation . 8 22. Dot Notation . 23. Getting the Software . 8 24. Language Support . 8 25. Mongo Administration Guide . 9 26. Working with Mongo Objects and Classes in Ruby . 9 27. MongoDB Language Support . 9 28. Community Info . 9 29. Internals . 9 30. TreeNavigation . 10 31. Old Pages . 10 31.1 Storing Data . 10 31.2 Indexes in Mongo . 10 31.3 HowTo . 10 31.4 Searching and Retrieving . 10 31.4.1 Locking . 10 31.5 Mongo Developers' Guide . 11 31.6 Locking in Mongo . 11 31.7 Mongo Database Administration . .. -
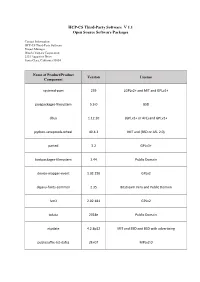
HCP-CS Third-Party Software V1.1
HCP-CS Third-Party Software V 1.1 Open Source Software Packages Contact Information: HCP-CS Third-Party Software Project Manager Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component systemd-pam 239 LGPLv2+ and MIT and GPLv2+ javapackages-filesystem 5.3.0 BSD dbus 1.12.10 (GPLv2+ or AFL) and GPLv2+ python-setuptools-wheel 40.4.3 MIT and (BSD or ASL 2.0) parted 3.2 GPLv3+ fontpackages-filesystem 1.44 Public Domain device-mapper-event 1.02.150 GPLv2 dejavu-fonts-common 2.35 Bitstream Vera and Public Domain lvm2 2.02.181 GPLv2 tzdata 2018e Public Domain ntpdate 4.2.8p12 MIT and BSD and BSD with advertising publicsuffix-list-dafsa 2E+07 MPLv2.0 Name of Product/Product Version License Component subversion-libs 1.10.2 ASL 2.0 ncurses-base 6.1 MIT javapackages-tools 5.3.0 BSD libX11-common 1.6.6 MIT apache-commons-pool 1.6 ASL 2.0 dnf-data 4.0.4 GPLv2+ and GPLv2 and GPL junit 4.12 EPL-1.0 fedora-release 29 MIT log4j12 1.2.17 ASL 2.0 setup 2.12.1 Public Domain cglib 3.2.4 ASL 2.0 and BSD basesystem 11 Public Domain slf4j 1.7.25 MIT and ASL 2.0 libselinux 2.8 Public Domain tomcat-lib 9.0.10 ASL 2.0 Name of Product/Product Version License Component LGPLv2+ and LGPLv2+ with exceptions and GPLv2+ glibc-all-langpacks 2.28 and GPLv2+ with exceptions and BSD and Inner-Net and ISC and Public Domain and GFDL antlr-tool 2.7.7 ANTLR-PD LGPLv2+ and LGPLv2+ with exceptions and GPLv2+ glibc 2.28 and GPLv2+ with exceptions and BSD and Inner-Net and ISC and Public Domain and GFDL apache-commons-daemon -

A Coap Server with a Rack Interface for Use of Web Frameworks Such As Ruby on Rails in the Internet of Things
A CoAP Server with a Rack Interface for Use of Web Frameworks such as Ruby on Rails in the Internet of Things Diploma Thesis Henning Muller¨ Matriculation No. 2198830 March 10, 2015 Supervisor Prof. Dr.-Ing. Carsten Bormann Reviewer Dr.-Ing. Olaf Bergmann Adviser Dipl.-Inf. Florian Junge Faculty 3: Computer Science and Mathematics 2afc1e5 cbna This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 License. http://creativecommons.org/licenses/by-nc-sa/4.0/ Henning Muller¨ [email protected] Abstract We present a Constrained Application Protocol (CoAP) server with a Rack interface to enable application development for the Internet of Things (or Wireless Embedded Internet) using frameworks such as Ruby on Rails. Those frameworks avoid the need for reinvention of the wheel, and simplify the use of Test-driven Development (TDD) and other agile software development methods. They are especially beneficial on less constrained devices such as infrastructure devices or application servers. Our solution supports development of applications almost without paradigm change compared to HTTP and provides performant handling of numerous concurrent clients. The server translates transparently between the protocols and also supports specifics of CoAP such as service and resource discovery, block-wise transfers and observing resources. It also offers the possibility of transparent transcoding between JSON and CBOR payloads. The Resource Directory draft was implemented by us as a Rails application running on our server software. Wir stellen einen Constrained Application Protocol (CoAP) Server mit einem Rack In- terface vor, der Anwendungsentwicklung fur¨ das Internet der Dinge (bzw. das Wireless Embedded Internet) mit Frameworks wie Ruby on Rails ermoglicht.¨ Solche Framworks verhindern die Notwendigkeits, das Rad neu zu erfinden und vereinfachen die Anwen- dung testgetriebener Entwicklung (TDD) und anderer agiler Methoden der Softwareen- twicklung. -

Load Testing of Containerised Web Services
UPTEC IT 16003 Examensarbete 30 hp Mars 2016 Load Testing of Containerised Web Services Christoffer Hamberg Abstract Load Testing of Containerised Web Services Christoffer Hamberg Teknisk- naturvetenskaplig fakultet UTH-enheten Load testing web services requires a great deal of environment configuration and setup. Besöksadress: This is especially apparent in an environment Ångströmlaboratoriet Lägerhyddsvägen 1 where virtualisation by containerisation is Hus 4, Plan 0 used with many moving and volatile parts. However, containerisation tools like Docker Postadress: offer several properties, such as; application Box 536 751 21 Uppsala image creation and distribution, network interconnectivity and application isolation that Telefon: could be used to support the load testing 018 – 471 30 03 process. Telefax: 018 – 471 30 00 In this thesis, a tool named Bencher, which goal is to aid the process of load testing Hemsida: containerised (with Docker) HTTP services, is http://www.teknat.uu.se/student designed and implemented. To reach its goal Bencher automates some of the tedious steps of load testing, including connecting and scaling containers, collecting system metrics and load testing results to name a few. Bencher’s usability is verified by testing a number of hypotheses formed around different architecture characteristics of web servers in the programming language Ruby. With a minimal environment setup cost and a rapid test iteration process, Bencher proved its usability by being successfully used to verify the hypotheses in this thesis. However, there is still need for future work and improvements, including for example functionality for measuring network bandwidth and latency, that could be added to enhance process even further. To conclude, Bencher fulfilled its goal and scope that were set for it in this thesis. -

Building Blocks of a Scalable Web Crawler
Building blocks of a scalable web crawler Marc Seeger Computer Science and Media Stuttgart Media University September 15, 2010 A Thesis Submitted in Fulfilment of the Requirements for a Degree of Master of Science in Computer Science and Media Primary thesis advisor: Prof. Walter Kriha Secondary thesis advisor: Dr. Dries Buytaert I I Abstract The purpose of this thesis was the investigation and implementation of a good architecture for collecting, analysing and managing website data on a scale of millions of domains. The final project is able to automatically collect data about websites and analyse the content management system they are using. To be able to do this efficiently, different possible storage back-ends were examined and a system was implemented that is able to gather and store data at a fast pace while still keeping it searchable. This thesis is a collection of the lessons learned while working on the project combined with the necessary knowledge that went into architectural decisions. It presents an overview of the different infrastructure possibilities and general approaches and as well as explaining the choices that have been made for the implemented system. II Acknowledgements I would like to thank Acquia and Dries Buytaert for allowing me to experience life in the USA while working on a great project. I would also like to thank Chris Brookins for showing me what agile project management is all about. Working at Acquia combined a great infrastructure and atmosphere with a pool of knowledgeable people. Both these things helped me immensely when trying to find and evaluate a matching architecture to this project. -

Vert.X in Action MEAP
MEAP Edition Manning Early Access Program Vert.x in Action Version 1 Copyright 2018 Manning Publications For more information on this and other Manning titles go to www.manning.com ©Manning Publications Co. We welcome reader comments about anything in the manuscript - other than typos and other simple mistakes. These will be cleaned up during production of the book by copyeditors and proofreaders. https://forums.manning.com/forums/vertx-in-action welcome Thank you for purchasing the MEAP of Vert.x in Action. Asynchronous and reactive applications are an important topic in modern distributed systems, especially as the progressive shift to virtualized and containerized runtime environments emphasize the need for resource efficient, adaptable and dependable application designs. Asynchronous programming is key to maximizing hardware resource usage, as it allows dealing with more concurrent connections than with the traditional blocking I/O paradigms. Services need to cater for workloads that may drastically change throughout from one hour to the other, hence we need to design code that naturally supports horizontal scalability. Last but not least, failure is inevitable when we have services interacting with other services over the network. Embracing failure is key for designing dependable systems. Assemble asynchronous programming, horizontal scalability, resilience and you have what we call today reactive applications, which can also be summarized without marketing jargon as “scalable and dependable applications”. That being said there is no free lunch and the transition to writing asynchronous and reactive applications is difficult when you have a background in more traditional software stacks. Grokking asynchrony in itself is difficult, but the implications of scalability and resilience on the design of an application are anything but trivial. -

Open Source Used in DNA Apps - Assurance Edge Assurance 1.0
Open Source Used In DNA Apps - Assurance Edge Assurance 1.0 Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-1132399293 Open Source Used In DNA Apps - Assurance Edge Assurance 1.0 1 This document contains licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of any source code to which you may be entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-1132399293 Contents 1.1 metrics-servlets 4.1.0 1.2 reactor-netty 0.9.7.RELEASE 1.2.1 Available under license 1.3 jakarta-ws-rs-api 2.1.5 1.3.1 Available under license 1.4 jetty-util 9.4.18.v20190429 1.4.1 Available under license 1.5 jsr305 3.0.2 1.6 woodstox-core-asl 4.4.1 1.7 snake-yaml 1.24 1.7.1 Available under license 1.8 profiler 1.0.2 1.9 joda-time 2.9.1 1.9.1 Available under license 1.10 rsocket-transport-netty 1.0.0-RC7 1.10.1 Available under license 1.11 slf4j 1.7.26 1.11.1 Available under license 1.12 stax-api 1.0-2 1.13 mongodb-driver-core 3.6.4 1.14 jetty-client 9.4.18.v20190429 1.14.1 Available under license 1.15 grpc-stub 1.9.0 1.16 jakarta-inject 2.5.0 1.16.1 Available under license 1.17 log4j-slf4j-impl