Interference Management and Exploitation in Emerging Wireless Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Sunrise 4G / LTE Roaming Operator List
Sunrise 4G / LTE Roaming Operator List Die 4G/LTE Netzabdeckung/Geschwindigkeit ist abhängig von der Mobilfunkinfrastruktur des jeweiligen Roamingpartners und der Region im jeweiligen Land. The 4G/LTE network coverage/speed depends on the mobile communication infrastructure of the roaming partner and the respective region in the country. Country LTE / 4G Afghanistan Planned Albania YES Algeria YES Andorra YES Angola Planned Anguilla YES Antigua And Barbuda YES Argentina YES Armenia YES Aruba YES Australia YES Austria YES Azerbaijan YES Bahamas Planned Bahrain YES Bangladesh Planned Barbados YES Belarus YES Belgium YES Benin Planned Bermuda YES Bolivia YES Bosnia and Herzegovina Planned Botswana YES Brazil YES British Virgin Islands YES Bulgaria YES Burkina Faso Planned Burundi Planned Cambodia YES Cameroon YES Canada YES Cape Verde YES Cayman Islands YES Central African Republic Planned Chad YES Chile YES China YES Colombia YES Congo In progress Costa Rica YES Cote Divoire YES Croatia YES Cuba In progress Curacao YES Cyprus YES Czech Republic YES Denmark YES Dominica YES Dominican Republic YES Ecuador YES Egypt YES El Salvador YES Equatorial Guinea Planned Estonia YES Ethiopia Planned Faroe Islands YES Fiji YES Finland YES France YES French Guiana YES French Polynesia Planned French West Indies YES Gabon Planned Gambia YES Georgia YES Germany YES Ghana Planned Gibraltar YES Greece YES Greenland Planned Grenada YES Guadeloupe YES Guatemala YES Guinea Planned Guinea-Bissau Planned Guyana YES Haiti YES Honduras YES Hong Kong YES Hungary -

ICT Decision 2016-5 Digicel Dispute Re LIME's 4G LTE Advertising
ICT Decision 2016-5 The Authority makes two determinations in relation to Digicel’s complaints regarding LIME’s 4G LTE advertising campaign. Table of Contents Table of Contents ....................................................................................................................................... 1 OVERVIEW .................................................................................................................................................. 2 APPLICATIONS ........................................................................................................................................... 2 LEGAL BASIS AND GENERAL STANDARDS ............................................................................................. 2 Legal Basis .............................................................................................................................................. 2 General Standards ................................................................................................................................. 3 PROCEDURAL MATTERS ........................................................................................................................... 4 DETERMINATION REQUEST 2015 ....................................................................................................... 6 DETERMINATION REQUEST 2014 ....................................................................................................... 7 SUBMISSIONS ........................................................................................................................................... -

T-Mobile 600 Mhz LTE Cities & Towns
T-Mobile 600 MHz LTE Cities & Towns As of July 2019 Alabama Bowie Hayden Sacaton Flats Village Aliceville Brenda Holbrook Safford Bellamy Bryce Hunter Creek Salome Billingsley Buckeye Icehouse Canyon San Jose Butler Bullhead City Jakes Corner San Manuel Carbon Hill Bylas Jerome San Simon Carrollton Cactus Flats Kachina Village San Tan Valley Chatom Cameron Katherine Sanders Cherokee Camp Verde Kearny Scenic Clanton Casa Blanca Kingman Scottsdale Coaling Casa Grande Kohatk Sedona Coffeeville Casas Adobes La Paz Valley Seligman Cuba Catalina Lake Havasu City Sierra Vista Daleville Catalina Foothills Lake Montezuma Sierra Vista Southeast Demopolis Cave Creek Lazy Y U Six Shooter Canyon Double Springs Centennial Park Lechee Solomon Eldridge Central Litchfield Park Somerton Epes Central Heights-Midland City Littlefield South Tucson Faunsdale Chandler Littletown St David Florence Chino Valley Maricopa Star Valley Gainesville Christopher Creek Maricopa Colony Strawberry Gilbertown Chuichu McConnico Summerhaven Gordo Clacks Canyon Mead Ranch Summit Grimes Clarkdale Meadview Sun Lakes Hackleburg Clifton Mesa Sun Valley Jackson Colorado City Mesa del Caballo Superior Jasper Congress Mescal Surprise Kansas Copper Hill Mesquite Creek Swift Trail Junction Linden Cornville Miracle Valley Tanque Verde Malcolm Cottonwood Mohave Valley Tat Momoli Maplesville Crystal Beach Mojave Ranch Estates Tempe Marion Cutter Morenci Thatcher Moundville Deer Creek Morristown Three Points New Brockton Desert Hills Mountainaire Tolleson Oak Hill Dewey-Humboldt Munds -
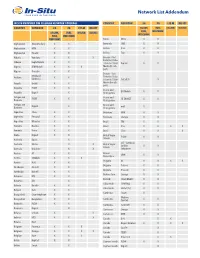
Network List Addendum
Network List Addendum IN-SITU PROVIDED SIM CELLULAR NETWORK COVERAGE COUNTRY NETWORK 2G 3G LTE-M NB-IOT COUNTRY NETWORK 2G 3G LTE-M NB-IOT (VULINK, (TUBE, (VULINK) (VULINK) TUBE, WEBCOMM) (VULINK, (TUBE, (VULINK) (VULINK) WEBCOMM) TUBE, WEBCOMM) WEBCOMM) Benin Moov X X Afghanistan TDCA (Roshan) X X Bermuda ONE X X Afghanistan MTN X X Bolivia Viva X X Afghanistan Etisalat X X Bolivia Tigo X X Albania Vodafone X X X Bonaire / Sint Eustatius / Saba Albania Eagle Mobile X X / Curacao / Saint Digicel X X Algeria ATM Mobilis X X X Martin (French part) Algeria Ooredoo X X Bonaire / Sint Mobiland Andorra X X Eustatius / Saba (Andorra) / Curacao / Saint TelCell SX X Angola Unitel X X Martin (French part) Anguilla FLOW X X Bosnia and BH Mobile X X Anguilla Digicel X Herzegovina Antigua and Bosnia and FLOW X X HT-ERONET X X Barbuda Herzegovina Antigua and Bosnia and Digicel X mtel X Barbuda Herzegovina Argentina Claro X X Botswana MTN X X Argentina Personal X X Botswana Orange X X Argentina Movistar X X Brazil TIM X X Armenia Beeline X X Brazil Vivo X X X X Armenia Ucom X X Brazil Claro X X X Aruba Digicel X X British Virgin FLOW X X Islands Australia Optus X CCT - Carribean Australia Telstra X X British Virgin Cellular X X Islands Australia Vodafone X X Telephone Austria A1 X X Brunei UNN X X Darussalam Austria T-Mobile X X X Bulgaria A1 X X X X Austria H3G X X Bulgaria Telenor X X Azerbaijan Azercell X X Bulgaria Vivacom X X Azerbaijan Bakcell X X Burkina Faso Orange X X Bahamas BTC X X Burundi Smart Mobile X X Bahamas Aliv X Cabo Verde CVMOVEL -

Quickc: Practical Sub-Millisecond Transport for Small Cells
QuickC: Practical sub-millisecond transport for small cells Rakesh Misra Aditya Gudipati Sachin Katti Stanford University Stanford University Stanford University [email protected] [email protected] [email protected] ABSTRACT 14 Cellular operators want to be able to deploy small cells with the No Coordinaon 12 same ease as WiFi access points, to quickly address traffic hotspots Coordinaon over Internet in dense urban areas. However, deploying small cells has not been 10 easy. The reason is that due to scarcity of licensed spectrum, small Coordinaon over QuickC cells need to use the same spectrum as the existing macro cells, 8 and they need to explicitly coordinate their spectrum usage with each other to manage interference. The challenge is that this co- 6 ordination needs to happen with latencies less than a millisecond, otherwise adding small cells does not help scale the overall network 4 capacity. Implementing such tight coordination in dense urban de- Network capacity scaling ployments has not been easy in practice. 2 We present QuickC, a wireless transport technology that can sim- plify small cell deployment. QuickC enables small cells to coordi- 0 0 1 2 3 4 5 6 7 8 9 10 nate with their neighboring macro and small cells with sub-1ms Number of small cells per macro sector latencies over the operator’s licensed spectrum but in a way that Figure 1: Network capacity with small cells (capacity of a macro- the users of this spectrum are negligibly affected. QuickC is de- only network is normalized to 1). If small cells do not coordinate signed to be an “add on" to existing cellular networks and does not with their neighboring cells, adding more small cells per macro require any invasive changes to the existing infrastructure or stan- causes more interference in the network and therefore does not dards. -

Assessing the Case for Single Wholesale Networks in Mobile Communications a REPORT PREPARED for the GSMA
Assessing the case for Single Wholesale Networks in mobile communications A REPORT PREPARED FOR THE GSMA SEPTEMBER 2014 © Frontier Economics Ltd, London. September 2014 | Frontier Economics i Assessing the case for Single Wholesale Networks in mobile communications Executive Summary 1 1 Introduction 11 2 Network competition and SWNs 13 2.1 What is network competition? .................................................. 13 2.2 The performance of the mobile sector under network competition ............................................................................... 15 2.3 What is an SWN? ..................................................................... 21 3 Achieving coverage objectives 27 3.1 Incentives on firms to expand coverage ................................... 27 3.2 Empirical evidence on coverage performance ......................... 29 3.3 Conclusion ............................................................................... 38 4 Achieving innovation objectives 39 5 Achieving reductions in network costs 52 5.1 Impact of duplication on overall network costs ......................... 53 5.2 Impact on unit costs ................................................................. 61 5.3 Conclusion ............................................................................... 64 6 Co-existence between an SWN and existing mobile networks 65 6.1 Impact of co-existence on market performance ....................... 66 6.2 Impact of measures to promote the SWN ................................ 69 6.3 Conclusion .............................................................................. -

Unleashing the Internet in the Caribbean Removing Barriers to Connectivity and Stimulating Better Access in the Region
Unleashing the Internet in the Caribbean Removing Barriers to Connectivity and Stimulating Better Access in the Region February 2017 iStock.com/Claudiad By Bionda Fonseca-Hoeve, Michele Marius, Shernon Osepa, Jane Coffin, and Michael Kende Unleashing the Internet in the Caribbean – Stimulating Better Access in the Region 1 Table of Contents Letter from the President ........................................................................................................................................................................................................................... 2 Acknowledgements ........................................................................................................................................................................................................................................... 3 Executive Summary ............................................................................................................................................................................................................................................ 4 1 Introduction .............................................................................................................................................................................................................................................................. 6 2 Overview of the Caribbean ............................................................................................................................................................................................................. -

IR.88 LTE and EPC Roaming Guidelines V17.0 (Current)
GSM Association Non-confidential Official Document IR.88 - LTE and EPC Roaming Guidelines LTE and EPC Roaming Guidelines Version 18.0 07 June 2018 This is a Non-binding Permanent Reference Document of the GSMA Security Classification: Non-confidential Access to and distribution of this document is restricted to the persons permitted by the security classification. This document is confidential to the Association and is subject to copyright protection. This document is to be used only for the purposes for which it has been supplied and information contained in it must not be disclosed or in any other way made available, in whole or in part, to persons other than those permitted under the security classification without the prior written approval of the Association. Copyright Notice Copyright © 2018 GSM Association Disclaimer The GSM Association (“Association”) makes no representation, warranty or undertaking (express or implied) with respect to and does not accept any responsibility for, and hereby disclaims liability for the accuracy or completeness or timeliness of the information contained in this document. The information contained in this document may be subject to change without prior notice. Antitrust Notice The information contain herein is in full compliance with the GSM Association’s antitrust compliance policy. V18.0 Page 1 of 93 GSM Association Non-confidential Official Document IR.88 - LTE and EPC Roaming Guidelines Table of Contents 1 Introduction 6 1.1 Overview 6 1.2 Scope 6 1.3 Definition of Terms 7 1.4 Document Cross-References -

LTE (Telecommunication) from Wikipedia, the Free Encyclopedia
66//22//1133 LLTTEE((tteelleeccoommmmuunniiccaattiioonn) )- WWiikkiippeeddiiaa, ,tthhe effrreee eeennccyycc llooppeeddiiaa LTE (telecommunication) From Wikipedia, the free encyclopedia LTLTEE, an ininitialismitialism ooff long-term evolution, marketed as 4G LTE, is a standard for wireless communication of high-spehigh-speeded data foforr mobile phones and data terminals. It is based on the GSM/EDGE and UMTS/HSPA network technologies,improvements. increasing[1][2] The thestandard capacity is developedand speed byusing the a 3GPP different (3rd radio Generat interfaceion Partnership together wit Project)h core and is specified in its Release 8 document series, with minor enhancements described in Release 9. The world's first pubpublliiclclyy avaiavailablelable LTE ser ser vicevice was launchedlaunched by by TTeleliiaSonaSoneera ira inn Oslo and StocStockholmkholm on DecemDecemberber 14 2009.[3][3] LTE is the natural upgrade path for carriers with both GSM/UMTSGSM/UMTS networks networks anandd CDMA networks such as Verizon WirelWireless,ess, who laulaunchednched the fifirstrst large-sclarge-scaalele LTE networ networ kk in North America in 2010,[4][5] and au by KDDI in JapaJapann havhavee announced ththeyey will migramigratete to LTE. LTE is, Adoption of LTE technology as of May 8, 2012. therefore, anticipated toto be becomecome the first truly global mobile phone standard, although the differedifferentnt LTE CountrieCountriess with commerccommercialial LTE service frequencies and bands used in different countries will mean that only multi-band -
Mobile Network Codes (MNC) for the International Identification Plan for Public Networks and Subscriptions (According to Recommendation ITU-T E.212 (09/2016))
Annex to ITU Operational Bulletin No. 1162 – 15.XII.2018 INTERNATIONAL TELECOMMUNICATION UNION TSB TELECOMMUNICATION STANDARDIZATION BUREAU OF ITU __________________________________________________________________ Mobile Network Codes (MNC) for the international identification plan for public networks and subscriptions (According to Recommendation ITU-T E.212 (09/2016)) (POSITION ON 15 DECEMBER 2018) __________________________________________________________________ Geneva, 2018 Mobile Network Codes (MNC) for the international identification plan for public networks and subscriptions Note from TSB 1. A centralized List of Mobile Network Codes (MNC) for the international identification plan for public networks and subscriptions has been created within TSB. 2. This List of Mobile Network Codes (MNC) is published as an annex to ITU Operational Bulletin No. 1162 of 15.XII.2018. Administrations are requested to verify the information in this List and to inform ITU on any modifications that they wish to make. The notification form can be found on the ITU website at http://www.itu.int/en/ITU-T/inr/forms/Pages/mnc.aspx . 3. This List will be updated by numbered series of amendments published in the ITU Operational Bulletin. Furthermore, the information contained in this Annex is also available on the ITU website. 4. Please address any comments or suggestions concerning this List to the Director of TSB: International Telecommunication Union (ITU) Director of TSB Tel: +41 22 730 5211 Fax: +41 22 730 5853 E-mail: [email protected] 5. The designations employed and the presentation of material in this List do not imply the expression of any opinion whatsoever on the part of ITU concerning the legal status of any country or geographical area, or of its authorities. -

The Broadband Infrastructure Inventory
THE BROADBAND INFRASTRUCTURE INVENTORY AND PUBLIC AWARENESS IN THE CARIBBEAN (BIIPAC) (BARBADOS, BELIZE, DONINICAN REPUBLIC, GUYANA, HAITI, JAMAICA, SURINAME, AND REPUBLIC OF TRINIDAD & TOBAGO) A CONSOLIDATION OF SUMMARY OF FINDINGS AND RECOMMENDATIONS OF THE FOUR COMPONENTS OF BIIPAC B. Claire Downes-Haynes July 2016 THE BROADBAND INFRASTRUCTURE INVENTORY AND PUBLIC AWARENESS IN THE CARIBBEAN (BIIPAC) (Barbados, Belize, Dominican Republic, Guyana, Haiti, Jamaica, Suriname, and Republic of Trinidad & Tobago) Consolidation of Summary of Findings and Recommendations of the Four Components of BIIPAC Prepared by B. Claire Downes-Haynes July 2016 i | Page Table of Contents Preface ......................................................................................................................................................... iii 1. INTRODUCTION ..................................................................................................................................... 1 1.1 THE PROJECT ................................................................................................................................. 1 1.2 BROADBAND IN THE REGION ........................................................................................................ 4 2. COUNTRY FINDINGS AND RECOMMENDATIONS .................................................................................. 7 2.1 BARBADOS .......................................................................................................................................... 7 2.1.1 -

Find Your GSM Carrier by Country Name
This cellular phone frequency list is provided solely as a reference to help customers. Cellular carriers and frequencies change often with little or no notice. Before making a purchase or travelling abroad, B&H encourages customers to verify a phone’s service compatibility with local cellular companies. This list does not guarantee coverage or compatibility in all regions of a country. Find Your GSM Carrier by Country Name: A B C D E F G H I J K L M N O P Q R S T U V W Y Z 2G/2.5G 3G (UMTS) / Network 4G (LTE) (EDGE) 3.5G (HSPA+) AWCC 900 / 1800 - - Etisalat 900 / 1800 2100 - Afghanistan MTN 900 / 1800 2100 - Roshan (telco) 900 - - 2G/2.5G 3G (UMTS) / Network 4G (LTE) (EDGE) 3.5G (HSPA+) Telekom Albania (AMC) 900 / 1800 2100 3 / 7 Albtelecom 900 / 1800 2100 3 / 7 Albania Plus 900 / 1800 2100 - Vodafone Albania 900 / 1800 2100 3 / 7 2G/2.5G 3G (UMTS) / Network 4G (LTE) (EDGE) 3.5G (HSPA+) Djezzy 900 / 1800 2100 - Algeria Mobilis/Algerie Telecom 900 / 1800 2100 - Ooredoo (Nedjma) 900 / 1800 2100 - 2G/2.5G 3G (UMTS) / Network 4G (LTE) (EDGE) 3.5G (HSPA+) American Samoa Blue Sky Communications 850 - - 2G/2.5G 3G (UMTS) / Network 4G (LTE) (EDGE) 3.5G (HSPA+) Andorra STA (Andorra Telecom) 900 / 1800 2100 20 2G/2.5G 3G (UMTS) / Network 4G (LTE) (EDGE) 3.5G (HSPA+) Movicel (Movicel Telecomunicaces, 900 / 1800 2100 3 Angola S.A.) Unitel (Unitel S.A.) 900 / 1800 2100 1 2G/2.5G 3G (UMTS) / Network 4G (LTE) (EDGE) 3.5G (HSPA+) Digicel 850 / 1900 900 / 1900 - Anguilla LIME (Cable & Wireless) 850 / 1900 2100 - Weblinks 850 / 1900 - - 2G/2.5G 3G (UMTS)