Detecting Vulnerable Javascript Libraries in Hybrid Android Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
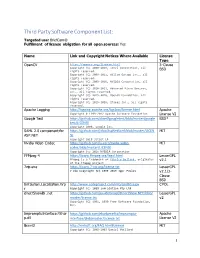
Third Party Software Component List: Targeted Use: Briefcam® Fulfillment of License Obligation for All Open Sources: Yes
Third Party Software Component List: Targeted use: BriefCam® Fulfillment of license obligation for all open sources: Yes Name Link and Copyright Notices Where Available License Type OpenCV https://opencv.org/license.html 3-Clause Copyright (C) 2000-2019, Intel Corporation, all BSD rights reserved. Copyright (C) 2009-2011, Willow Garage Inc., all rights reserved. Copyright (C) 2009-2016, NVIDIA Corporation, all rights reserved. Copyright (C) 2010-2013, Advanced Micro Devices, Inc., all rights reserved. Copyright (C) 2015-2016, OpenCV Foundation, all rights reserved. Copyright (C) 2015-2016, Itseez Inc., all rights reserved. Apache Logging http://logging.apache.org/log4cxx/license.html Apache Copyright © 1999-2012 Apache Software Foundation License V2 Google Test https://github.com/abseil/googletest/blob/master/google BSD* test/LICENSE Copyright 2008, Google Inc. SAML 2.0 component for https://github.com/jitbit/AspNetSaml/blob/master/LICEN MIT ASP.NET SE Copyright 2018 Jitbit LP Nvidia Video Codec https://github.com/lu-zero/nvidia-video- MIT codec/blob/master/LICENSE Copyright (c) 2016 NVIDIA Corporation FFMpeg 4 https://www.ffmpeg.org/legal.html LesserGPL FFmpeg is a trademark of Fabrice Bellard, originator v2.1 of the FFmpeg project 7zip.exe https://www.7-zip.org/license.txt LesserGPL 7-Zip Copyright (C) 1999-2019 Igor Pavlov v2.1/3- Clause BSD Infralution.Localization.Wp http://www.codeproject.com/info/cpol10.aspx CPOL f Copyright (C) 2018 Infralution Pty Ltd directShowlib .net https://github.com/pauldotknopf/DirectShow.NET/blob/ LesserGPL -

** OPEN SOURCE LIBRARIES USED in Tv.Verizon.Com/Watch
** OPEN SOURCE LIBRARIES USED IN tv.verizon.com/watch ------------------------------------------------------------ 02/27/2019 tv.verizon.com/watch uses Node.js 6.4 on the server side and React.js on the client- side. Both are Javascript frameworks. Below are the licenses and a list of the JS libraries being used. ** NODE.JS 6.4 ------------------------------------------------------------ https://github.com/nodejs/node/blob/master/LICENSE Node.js is licensed for use as follows: """ Copyright Node.js contributors. All rights reserved. Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. """ This license applies to parts of Node.js originating from the https://github.com/joyent/node repository: """ Copyright Joyent, Inc. and other Node contributors. -

Npm Packages As Ingredients: a Recipe-Based Approach
npm Packages as Ingredients: a Recipe-based Approach Kyriakos C. Chatzidimitriou, Michail D. Papamichail, Themistoklis Diamantopoulos, Napoleon-Christos Oikonomou, and Andreas L. Symeonidis Electrical and Computer Engineering Dept., Aristotle University of Thessaloniki, Thessaloniki, Greece fkyrcha, mpapamic, thdiaman, [email protected], [email protected] Keywords: Dependency Networks, Software Reuse, JavaScript, npm, node. Abstract: The sharing and growth of open source software packages in the npm JavaScript (JS) ecosystem has been exponential, not only in numbers but also in terms of interconnectivity, to the extend that often the size of de- pendencies has become more than the size of the written code. This reuse-oriented paradigm, often attributed to the lack of a standard library in node and/or in the micropackaging culture of the ecosystem, yields interest- ing insights on the way developers build their packages. In this work we view the dependency network of the npm ecosystem from a “culinary” perspective. We assume that dependencies are the ingredients in a recipe, which corresponds to the produced software package. We employ network analysis and information retrieval techniques in order to capture the dependencies that tend to co-occur in the development of npm packages and identify the communities that have been evolved as the main drivers for npm’s exponential growth. 1 INTRODUCTION Given that dependencies and reusability have be- come very important in today’s software develop- The popularity of JS is constantly increasing, and ment process, npm registry has become a “must” along is increasing the popularity of frameworks for place for developers to share packages, defining code building server (e.g. -

Enhancement of a Vulnerability Checker for Software Libraries with Similarity Metrics Based on File-Hashes
Gottfried Wilhelm Leibniz Universität Hannover Faculty of Electrical Engineering and Computer Science Institute of Practical Computer Science Software Engineering Group Enhancement of a Vulnerability Checker for Software Libraries with Similarity Metrics based on File-Hashes Bachelor Thesis in Computer Science by Huu Kim Nguyen First Examiner: Prof. Dr. Kurt Schneider Second Examiner: Dr. Jil Klünder Supervisor: M.Sc. Fabien Patrick Viertel Hannover, March 19, 2020 ii Declaration of Independence I hereby certify that I have written the present bachelor thesis independently and without outside help and that I have not used any sources and aids other than those specified in the work. The work has not yet been submitted to any other examination office in the same or similar form. Hannover, March 19, 2020 _____________________________________ Huu Kim Nguyen iii iv Abstract This bachelor thesis presents a software which checks a software project for libraries that have security vulnerabilities so the user is notified to update them. External software libraries and frameworks are used in websites and other software to provide new functionality. Using outdated and vulnerable libraries poses a large risk to developers and users. Finding vulnerabilities should be part of the software development. Manually finding vulnerable libraries is a time consuming process. The solution presented in this thesis is a vulnerability checker which scans the project library for any libraries that contain security vulnerabilities provided that the software project is written in Java or in JavaScript. It uses hash signatures obtained from these libraries to check against a database that has hash signatures of libraries that are known to have security vulnerabilities. -

Investigating the Reproducbility of NPM Packages
Investigating the Reproducbility of NPM packages Pronnoy Goswami Thesis submitted to the Faculty of the Virginia Polytechnic Institute and State University in partial fulfillment of the requirements for the degree of Master of Science in Computer Engineering Haibo Zeng, Chair Na Meng Paul E. Plassmann May 6, 2020 Blacksburg, Virginia Keywords: Empirical, JavaScript, NPM packages, Reproducibility, Software Security, Software Engineering Copyright 2020, Pronnoy Goswami Investigating the Reproducbility of NPM packages Pronnoy Goswami (ABSTRACT) The meteoric increase in the popularity of JavaScript and a large developer community has led to the emergence of a large ecosystem of third-party packages available via the Node Package Manager (NPM) repository which contains over one million published packages and witnesses a billion daily downloads. Most of the developers download these pre-compiled published packages from the NPM repository instead of building these packages from the available source code. Unfortunately, recent articles have revealed repackaging attacks to the NPM packages. To achieve such attacks the attackers primarily follow three steps – (1) download the source code of a highly depended upon NPM package, (2) inject mali- cious code, and (3) then publish the modified packages as either misnamed package (i.e., typo-squatting attack) or as the official package on the NPM repository using compromised maintainer credentials. These attacks highlight the need to verify the reproducibility of NPM packages. Reproducible Build is a concept that allows the verification of build artifacts for pre-compiled packages by re-building the packages using the same build environment config- uration documented by the package maintainers. This motivates us to conduct an empirical study (1) to examine the reproducibility of NPM packages, (2) to assess the influence of any non-reproducible packages, and (3) to explore the reasons for non-reproducibility. -

Javascript Frameworks for Modern Web Development the Essential Frameworks, Libraries, and Tools to Learn Right Now Second Edition
JavaScript Frameworks for Modern Web Development The Essential Frameworks, Libraries, and Tools to Learn Right Now Second Edition Sufyan bin Uzayr Nicholas Cloud Tim Ambler JavaScript Frameworks for Modern Web Development Sufyan bin Uzayr Nicholas Cloud Al Manama, United Arab Emirates Florissant, MO, USA Tim Ambler Nashville, TN, USA ISBN-13 (pbk): 978-1-4842-4994-9 ISBN-13 (electronic): 978-1-4842-4995-6 https://doi.org/10.1007/978-1-4842-4995-6 Copyright © 2019 by Sufyan bin Uzayr, Nicholas Cloud, Tim Ambler This work is subject to copyright. All rights are reserved by the Publisher, whether the whole or part of the material is concerned, specifically the rights of translation, reprinting, reuse of illustrations, recitation, broadcasting, reproduction on microfilms or in any other physical way, and transmission or information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed. Trademarked names, logos, and images may appear in this book. Rather than use a trademark symbol with every occurrence of a trademarked name, logo, or image we use the names, logos, and images only in an editorial fashion and to the benefit of the trademark owner, with no intention of infringement of the trademark. The use in this publication of trade names, trademarks, service marks, and similar terms, even if they are not identified as such, is not to be taken as an expression of opinion as to whether or not they are subject to proprietary rights. While the advice and information in this book are believed to be true and accurate at the date of publication, neither the authors nor the editors nor the publisher can accept any legal responsibility for any errors or omissions that may be made. -

Pronghorn-Licenses-V2.Pdf
Pronghorn Application Server is @copyright Itential, LLC 2015. Pronghorn uses open source software. Pronghorn has direct dependencies on the following software. Name License URI ---------------------------------------------------------------------------------------------------- angular-animate MIT https://github.com/angular/angular.js angular-aria MIT https://github.com/angular/angular.js angular-material MIT https://github.com/angular/material angular MIT https://github.com/angular/angular.js body-parser MIT https://github.com/expressjs/body-parser bootstrap MIT https://github.com/twbs/bootstrap btoa Apache 2.0 https://github.com/coolaj86/node-browser-compat caller-id MIT https://github.com/pixelsandbytes/caller-id continuation-local-storage BSD https://github.com/othiym23/node-continuation-local-storage cookie-parser MIT https://github.com/expressjs/cookie-parser diff BSD https://github.com/kpdecker/jsdiff express-generator MIT https://github.com/expressjs/generator express-session MIT https://github.com/expressjs/session express MIT https://github.com/strongloop/express forever MIT https://github.com/nodejitsu/forever jade MIT https://github.com/visionmedia/jade jquery-ui MIT https://github.com/jquery/jquery-ui jquery MIT https://github.com/jquery/jquery jsnlog-nodejs Apache 2.0 https://github.com/mperdeck/jsnlog-nodejs jsnlog Apache 2.0 https://github.com/mperdeck/jsnlog.js lodash MIT https://github.com/lodash/lodash material-design-icons CC-BY-4.0 https://github.com/google/material-design-icons moment MIT https://github.com/moment/moment -

Npm Packages As Ingredients: a Recipe-Based Approach
npm Packages as Ingredients: A Recipe-based Approach Kyriakos C. Chatzidimitriou, Michail D. Papamichail, Themistoklis Diamantopoulos, Napoleon-Christos Oikonomou and Andreas L. Symeonidis Electrical and Computer Engineering Dept., Aristotle University of Thessaloniki, Thessaloniki, Greece Keywords: Dependency Networks, Software Reuse, JavaScript, npm, Node. Abstract: The sharing and growth of open source software packages in the npm JavaScript (JS) ecosystem has been exponential, not only in numbers but also in terms of interconnectivity, to the extend that often the size of de- pendencies has become more than the size of the written code. This reuse-oriented paradigm, often attributed to the lack of a standard library in node and/or in the micropackaging culture of the ecosystem, yields interest- ing insights on the way developers build their packages. In this work we view the dependency network of the npm ecosystem from a “culinary” perspective. We assume that dependencies are the ingredients in a recipe, which corresponds to the produced software package. We employ network analysis and information retrieval techniques in order to capture the dependencies that tend to co-occur in the development of npm packages and identify the communities that have been evolved as the main drivers for npm’s exponential growth. 1 INTRODUCTION come very important in today’s software develop- ment process, npm registry has become a “must” The popularity of JS is constantly increasing, and place for developers to share packages, defining code along is increasing the popularity of frameworks for reuse as a state-of-the-practice development paradigm building server (e.g. Node.js), web (e.g. -

Javascript Frameworks for Modern Web Development the Essential Frameworks, Libraries, and Tools to Learn Right Now
apress.com Computer Science : Web Development bin Uzayr, S., Cloud, N., Ambler, T. JavaScript Frameworks for Modern Web Development The Essential Frameworks, Libraries, and Tools to Learn Right Now Focuses on front end frameworks, such as React, VueJS, and also addresses niche-focused and performance driven frameworks such as Kraken, Mongoose, etc Provides not only comprehensive coverage of the features and uses of each framework covered, but also advises the reader on which framework to use for different situations, alleviating the problem of ‘too much choice’ when it comes to the multitude of JavaScript frameworks available Apress Practical advice and guidance that will help not only new developers, but those with experience looking for a single resource that covers the most 2nd ed., XXVI, 550 p. 97 2nd illus. relevant technologies in today’s JavaScript landscape edition Enrich your software design skills and take a guided tour of the wild, vast, and untamed frontier that is JavaScript development. Especially useful for frontend developers, this revision includes specific chapters on React and VueJS, as well as an updated one on Angular. To help Printed book you get the most of your new skills, each chapter also has a "further reading" section. This Softcover book will serve as an introduction to both new and well established libraries and frameworks, Printed book such as Angular, VueJS, React, Grunt, Yeoman, RequireJS, Browserify, Knockout, Kraken, Async.js, Underscore, and Lodash. It also covers utilities that have gained popular traction and support Softcover from seasoned developers and tools applicable to the entire development stack, both client- ISBN 978-1-4842-4994-9 and server-side. -

Javascript Raamistikude Analüüs Ja Võrdlus Struktureeritud SPA Rakendustes Magistritöö
TALLINNA TEHNIKAÜLIKOOL Infotehnoloogia teaduskond Informaatika instituut Infosüsteemide õppetool JavaScript raamistikude analüüs ja võrdlus struktureeritud SPA rakendustes Magistritöö Üliõpilane: Jevgeni Rumjantsev Üliõpilaskood: 144252IAPM Juhendaja: lektor Raul Liivrand Tallinn 2015 Autorideklaratsioon Kinnitan, et olen koostanud antud lõputöö iseseisvalt ning seda ei ole kellegi teise poolt varem kaitsmisele esitatud. Kõik töö koostamisel kasutatud teiste autorite tööd, olulised seisukohad, kirjandusallikatest ja mujalt pärinevad andmed on töös viidatud. (kuupäev) (allkiri) Annotatsioon Magistritööl on kaks eesmärki: 1. Analüüsida tänapäeval populaarsemaid JavaScript raamistikke eesmärgiga arendada erinevate suurustega rakendusi. Analüüs tehakse abstraktsel näiterakendusel, mis käsitleb taaskasutatavat põhifunktsionaalsust ja raamistikuga seotud probleeme, produktiivsust, rakenduse hallatavust ja paindlikkust. 2. Võrrelda sarnase funktsionaalsusega JavaScript raamistikud eesmärgiga aru saada, millist raamistiku on parem kasutada. Lisaks ka aru saada, kas analüüsitud JavaScript raamistikuga ehitatud rakendust on võimalik toetada lähi- ja kaugtulevikus. Rakendust pannakse kokku kogukonna poolt valmis tehtud komponentidest. Autor uurib, kuidas mõjutab paigaldatud komponendid rakenduse laadimiskiirust ja töövõimet. Samuti peetakse silmas ohtusid raamistikuga arendamises: rakenduse lahtisus-kinnisus, arhitektuur ja selle paindlikkus ja haldamine, raamistiku õppimise raskus, rakenduse testimine ning kui hästi on otsingumootoritega leitav. -

Node.Js License and Copyright Notice
Disclosure of Free and Open Source Software (“FOSS”) Components Node.js INTRODUCTION This document sets out the text required to be made available alongside the Node.js component included in Domino products (the “Software”) in accordance with applicable licence terms. This document is divided into two sections. • Section 1 sets out the licence text applicable to each FOSS component within the Software where the relevant licence requires that text to be made available. • Section 2 sets out the copyright notices applicable to each FOSS component within the Software where the relevant licence requires those notices to be provided and those notices are not otherwise provided as part of the source code made available in accordance with the paragraph below. Where a particular licence requires the source code of any FOSS components to be made available alongside the Software, that source code has been made available at https://www.dominoprinting.com/en-gb/legal-and-ip/open-source-licensing.aspx. Node.js is a trademark of Joyent, Inc. and is used with its permission. Domino Group companies are not endorsed by or affiliated with Joyent. SECTION 1: LICENCE TERMS Apache License 2.0 (Apache-2.0) Applicable components: _esm2015 , _esm5, atob 2.1.2, aws-sign2 0.7.0, browser-request 0.3.3, caja, caseless 0.12.0, clang-format 1.2.3, forever-agent 0.6.1, JSONStream 1.3.5, oauth-sign 0.9.0, qrcode-terminal 0.12.0, rc 1.2.8, request 2.88.2, sammy, spdx-correct 3.0.0, tslib 1.9.3, tunnel- agent 0.6.0, validate-npm-package-license 3.0.4, wasm-api, watch Apache License Version 2.0, January 2004 http://www.apache.org/licenses/ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION 1. -

Third Party Software Licensing Agreements RL6 6.8
Third Party Software Licensing Agreements RL6 6.8 Updated: April 16, 2019 www.rlsolutions.com m THIRD PARTY SOFTWARE LICENSING AGREEMENTS CONTENTS OPEN SOURCE LICENSES ................................................................................................................. 10 Apache v2 License ...................................................................................................................... 10 Apache License ................................................................................................................. 11 BSD License ................................................................................................................................ 14 .Net API for HL7 FHIR (fhir-net-api) .................................................................................. 15 ANTLR 3 C# Target ........................................................................................................... 16 JQuery Sparkline ............................................................................................................... 17 Microsoft Ajax Control Toolkit ............................................................................................ 18 Mvp.Xml ............................................................................................................................. 19 NSubstitute ........................................................................................................................ 20 Remap-istanbul ................................................................................................................