Ecosystems in Github and a Method for Ecosystem Identification Using
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
16 Inspiring Women Engineers to Watch
Hackbright Academy Hackbright Academy is the leading software engineering school for women founded in San Francisco in 2012. The academy graduates more female engineers than UC Berkeley and Stanford each year. https://hackbrightacademy.com 16 Inspiring Women Engineers To Watch Women's engineering school Hackbright Academy is excited to share some updates from graduates of the software engineering fellowship. Check out what these 16 women are doing now at their companies - and what languages, frameworks, databases and other technologies these engineers use on the job! Software Engineer, Aclima Tiffany Williams is a software engineer at Aclima, where she builds software tools to ingest, process and manage city-scale environmental data sets enabled by Aclima’s sensor networks. Follow her on Twitter at @twilliamsphd. Technologies: Python, SQL, Cassandra, MariaDB, Docker, Kubernetes, Google Cloud Software Engineer, Eventbrite 1 / 16 Hackbright Academy Hackbright Academy is the leading software engineering school for women founded in San Francisco in 2012. The academy graduates more female engineers than UC Berkeley and Stanford each year. https://hackbrightacademy.com Maggie Shine works on backend and frontend application development to make buying a ticket on Eventbrite a great experience. In 2014, she helped build a WiFi-enabled basal body temperature fertility tracking device at a hardware hackathon. Follow her on Twitter at @magksh. Technologies: Python, Django, Celery, MySQL, Redis, Backbone, Marionette, React, Sass User Experience Engineer, GoDaddy 2 / 16 Hackbright Academy Hackbright Academy is the leading software engineering school for women founded in San Francisco in 2012. The academy graduates more female engineers than UC Berkeley and Stanford each year. -

Automatic Generation of a 3D City Model
UNIVERSITY OF CASTILLA-LA MANCHA ESCUELA SUPERIOR DE INFORMÁTICA COMPUTER ENGINEERING DEGREE DEGREE FINAL PROJECT Automatic generation of a 3D city model David Murcia Pacheco June, 2017 AUTOMATIC GENERATION OF A 3D CITY MODEL Escuela Superior de Informática UNIVERSITY OF CASTILLA-LA MANCHA ESCUELA SUPERIOR DE INFORMÁTICA Information Technology and Systems SPECIFIC TECHNOLOGY OF COMPUTER ENGINEERING DEGREE FINAL PROJECT Automatic generation of a 3D city model Author: David Murcia Pacheco Director: Dr. Félix Jesús Villanueva Molina June, 2017 David Murcia Pacheco Ciudad Real – Spain E-mail: [email protected] Phone No.:+34 625 922 076 c 2017 David Murcia Pacheco Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled "GNU Free Documentation License". i TRIBUNAL: Presidente: Vocal: Secretario: FECHA DE DEFENSA: CALIFICACIÓN: PRESIDENTE VOCAL SECRETARIO Fdo.: Fdo.: Fdo.: ii Abstract HIS document collects all information related to the Degree Final Project (DFP) of Com- T puter Engineering Degree of the student David Murcia Pacheco, tutorized by Dr. Félix Jesús Villanueva Molina. This work has been developed during 2016 and 2017 in the Escuela Superior de Informática (ESI), in Ciudad Real, Spain. It is based in one of the proposed sub- jects by the faculty of this university for this year, called "Generación automática del modelo en 3D de una ciudad". -
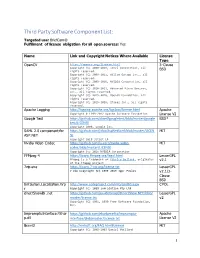
Third Party Software Component List: Targeted Use: Briefcam® Fulfillment of License Obligation for All Open Sources: Yes
Third Party Software Component List: Targeted use: BriefCam® Fulfillment of license obligation for all open sources: Yes Name Link and Copyright Notices Where Available License Type OpenCV https://opencv.org/license.html 3-Clause Copyright (C) 2000-2019, Intel Corporation, all BSD rights reserved. Copyright (C) 2009-2011, Willow Garage Inc., all rights reserved. Copyright (C) 2009-2016, NVIDIA Corporation, all rights reserved. Copyright (C) 2010-2013, Advanced Micro Devices, Inc., all rights reserved. Copyright (C) 2015-2016, OpenCV Foundation, all rights reserved. Copyright (C) 2015-2016, Itseez Inc., all rights reserved. Apache Logging http://logging.apache.org/log4cxx/license.html Apache Copyright © 1999-2012 Apache Software Foundation License V2 Google Test https://github.com/abseil/googletest/blob/master/google BSD* test/LICENSE Copyright 2008, Google Inc. SAML 2.0 component for https://github.com/jitbit/AspNetSaml/blob/master/LICEN MIT ASP.NET SE Copyright 2018 Jitbit LP Nvidia Video Codec https://github.com/lu-zero/nvidia-video- MIT codec/blob/master/LICENSE Copyright (c) 2016 NVIDIA Corporation FFMpeg 4 https://www.ffmpeg.org/legal.html LesserGPL FFmpeg is a trademark of Fabrice Bellard, originator v2.1 of the FFmpeg project 7zip.exe https://www.7-zip.org/license.txt LesserGPL 7-Zip Copyright (C) 1999-2019 Igor Pavlov v2.1/3- Clause BSD Infralution.Localization.Wp http://www.codeproject.com/info/cpol10.aspx CPOL f Copyright (C) 2018 Infralution Pty Ltd directShowlib .net https://github.com/pauldotknopf/DirectShow.NET/blob/ LesserGPL -

Alexander Vaos [email protected] - 754.281.9609 - Alexvaos.Com
SENIOR FullStack SOFTWARE ENGINEER Alexander Vaos [email protected] - 754.281.9609 - alexvaos.com PERSONA Portfolio My name is Alexander Vaos and I love changing the world. Resume alexvaos.com/resume I’ve worn nearly ever hat I could put on in the last 18 years. I truly love being a part of something WEBSITE alexvaos.com meaningful. github github.com/kriogenx0 linkedin linkedin.com/pub/alex-vaos I love every part of creating a product: starting from an abstract idea, working through the experience, writing up it’s features, designing it, architecting it, building the front-end and back-end, integrating with stackoverflow stackoverflow.com/users/327934/alex-v other apps, bringing it together, testing, and ending at a physical result that makes a difference in Behance behance.net/kriogenx someone’s life. At an early age, I pursued design and programming, eventually learning some of the other Flickr flickr.com/alexvaos components of a business: marketing, product management, business development, sales. I worked as a part of every company size, from startup to enterprise. I've learned the delicacy of a startup, and how essential ROI can be for the roadmap of any company. I'd like to make an impact and create products people love, use, and can learn things from. I'd like the change the world one step at a time. FULL-TIME POSITIONS 2015-2018 SENIOR FullSTack ENGINEER Medidata Mdsol.com Overseeing 8 codebases, front-end applications and API services. Configured countless new applications from scratch with Rails, Rack, Express (Node), and Roda, using React/Webpack for front-end. -

Alexander, Kleymenov
Alexander, Kleymenov Key Skills ▪ Ruby ▪ JavaScript ▪ C/C++ ▪ SQL ▪ PL/SQL ▪ XML ▪ UML ▪ Ruby on Rails ▪ EventMachine ▪ Sinatra ▪ JQuery ▪ ExtJS ▪ Databases: Oracle (9i,10g), MySQL, PostgreSQL, MS SQL ▪ noSQL: CouchDB, MongoDB ▪ Messaging: RabbitMQ ▪ Platforms: Linux, Solaris, MacOS X, Windows ▪ Testing: RSpec ▪ TDD, BDD ▪ SOA, OLAP, Data Mining ▪ Agile, Scrum Experience May 2017 – June 2018 Digitalkasten Internet GmbH (Germany, Berlin) Lead Developer B2B & B2C SaaS: Development from the scratch. Ruby, Ruby on Rails, Golang, Elasticsearch, Ruby, Ruby on Rails, Golang, Elasticsearch, Postgresql, Javascript, AngularJS 2 / Angular 5, Ionic 2 & 3, Apache Cordova, RabbitMQ, OpenStack January 2017 – April 2017 (project work) Stellenticket Gmbh (Germany, Berlin) Lead developer Application prototype development with Ruby, Ruby on Rails, Javascript, Backbone.js, Postgresql. September 2016 – December 2016 Part-time work & studying German in Goethe-Institut e.V. (Germany, Berlin) Freelancer & Student Full-stack developer and German A1. May 2016 – September 2016 Tridion Assets Management Gmbh (Germany, Berlin) Team Lead Development team managing. Develop and implement architecture of application HRLab (application for HRs). Software development trainings for team. Planning of software development and life cycle. Ruby, Ruby on Rails, Javascript, Backbone.js, Postgresql, PL/pgSQL, Golang, Redis, Salesforce API November 2015 – May 2016 (Germany, Berlin) Ecratum Gmbh Ruby, Ruby on Rails developer ERP/CRM - Application development with: Ruby 2, RoR4, PostgreSQL, Redis/Elastic, EventMachine, MessageBus, Puma, AWS/EC2, etc. April 2014 — November 2015 (Russia, Moscow - Australia, Melbourne - Munich, Germany - Berlin, Germany) Freelance/DHARMA Dev. Ruby, Ruby on Rails developer notarikon.net Application development with: Ruby 2, RoR 4, PostgreSQL, MongoDB, Javascript (CoffeeScript), AJAX, jQuery, Websockets, Redis + own project: http://featmeat.com – complex service for health control: trainings tracking and data providing to medical adviser. -

Magento on HHVM Speeding up Your Webshop with a Drop-In PHP Replacement
Magento on HHVM Speeding up your webshop with a drop-in PHP replacement. Daniel Sloof [email protected] What is HHVM? ● HipHop Virtual Machine ● Created by engineers at Facebook ● Essentially a reimplementation of PHP ● Originally translated PHP to C++, now translates PHP to bytecode ● Just-in-time compiler, turning generated bytecode into machine code ● In some cases 5 to 10 times faster than regular PHP So what’s the problem? ● HHVM not entirely compatible with PHP ● Magento’s PHP triggering many of these incompatibilities ● Choosing between ○ Forking Magento to work around HHVM ○ Fixing issues within the extensive HHVM C++ codebase Resulted in... fixing HHVM ● Already over 100 commits fixing Magento related HHVM bugs; ○ SimpleXML (majority of bugfixes) ○ sessions ○ number_format ○ __get and __set ○ many more... ● Most of these fixes already merged back into the official (github) repository ● Community Edition running (relatively) stable! Benchmarks Before we go to the results... ● Magento 1.8 with sample data ● Standard Apache2 / php-fpm / MySQL stack (with APC opcode cache). ● Standard HHVM configuration (repo-authoritative mode disabled, JIT enabled) ● Repo-authoritative mode has potential to increase performance by a large margin ● Tool of choice: siege Benchmarks: Response time Average across 50 requests Benchmarks: Transaction rate While increasing siege concurrency until avg. response time ~2 seconds What about <insert caching mechanism here>? ● HHVM does not get in the way ● Dynamic content still needs to be generated ● Replaces PHP - not Varnish, Redis, FPC, Block Cache, etc. ● As long as you are burning CPU cycles (always), you will benefit from HHVM ● Think about speeding up indexing, order placement, routing, etc. -

** OPEN SOURCE LIBRARIES USED in Tv.Verizon.Com/Watch
** OPEN SOURCE LIBRARIES USED IN tv.verizon.com/watch ------------------------------------------------------------ 02/27/2019 tv.verizon.com/watch uses Node.js 6.4 on the server side and React.js on the client- side. Both are Javascript frameworks. Below are the licenses and a list of the JS libraries being used. ** NODE.JS 6.4 ------------------------------------------------------------ https://github.com/nodejs/node/blob/master/LICENSE Node.js is licensed for use as follows: """ Copyright Node.js contributors. All rights reserved. Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. """ This license applies to parts of Node.js originating from the https://github.com/joyent/node repository: """ Copyright Joyent, Inc. and other Node contributors. -

| Jekyll Documentation Theme — Designers
Jekyll Documentation Theme for Designers version 3.0 Last generated: September 13, 2015 © 2015 Your company's copyright information... All rights reserved. No part of this book may be reproduced in any form or by any electronic or mechanical means, including information storage and retrieval systems, without written permission from the author, except in the case of a reviewer, who may quote brief passages embodied in critical articles or in a review. Trademarked names appear throughout this book. Rather than use a trademark symbol with every occurrence of a trademarked name, names are used in an editorial fashion, with no intention of infringement of the respective owner’s trademark. The information in this book is distributed on an “as is” basis, without warranty. Although every precaution has been taken in the preparation of this work, neither the author nor the publisher shall have any liability to any person or entity with respect to any loss or damage caused or alleged to be caused directly or indirectly by the information contained in this book. Jekyll Documentation Theme for Designers User Guide PDF last generated: September 13, 2015 Table of Contents Getting started Introduction .............................................................................................................................. 1 Getting started with this theme ................................................................................................ 3 Setting configuration options .................................................................................................. -

Oracle Spatial 11G Release 2 New Features Deep Dive Siva Ravada Director of Development, Oracle Spatial
Title of Presentation Oracle Spatial 11g Release 2 New Features Deep Dive Siva Ravada Director of Development, Oracle Spatial Michael Smith US Army Corps of Engineers Agenda • Introduction to Oracle Spatial <Insert Picture Here> • Spatial Engine • SQL Developer • GeoRaster • Network Data Model • Moving Objects • 3D Support Oracle Spatial Features – Oracle Locator: Feature of Oracle Database XE, SE, EE – Oracle Spatial: Priced option to HTTP Oracle Database EE Fusion Middleware – MapViewer*: Java application and map rendering feature of Fusion MapViewer Middleware – Bundled Map Content: Major roads, JDBC administrative boundaries (city, county, state, country) - worldwide Oracle Database coverage from Navteq Oracle Locator Oracle Spatial Bundled Map Content Supports all Geospatial Data types Polygons (admin, sales territories, Locations high risk zones) Networks (points of interest) (roads, utilities) Data Imagery 3D data type (satellite imagery) Topology (city models) (data provider) LIDAR Data Type TIN Data Type Open Platform for Leading Applications and Tools MapInfo Leica ADE Bentley Manifold Oracle Spatial 11g Enabled Applications Scrollable, Interactive Maps Spatial Web Services 3D, Point Clouds, and LIDAR Geocoding & Routing Oracle BI Dashboards Raster Imagery Spatial Engine Spatial on Exadata • We achieve performance improvements based on the exploitation of the processing power, bandwidth, and parallelism of the Exadata machine • Parallel query and partitioning help improve Spatial performance • All the row level functions are also parallel enabled to take advantage of parallel query • Speedups of up to 40 times (compared to a 1-core CPU box) for the typical SDO_ANYINTERACT spatial query • Spatial predicates are not currently pushed into the Exadata storage nodes 9 Spatial Index Parallel Creation on Exadata • Build a Local Spatial Index on Partitioned Table: each slave can build a different index partition in parallel. -

Distributed Programming with Ruby
DISTRIBUTED PROGRAMMING WITH RUBY Mark Bates Upper Saddle River, NJ • Boston • Indianapolis • San Francisco New York • Toronto • Montreal • London • Munich • Paris • Madrid Capetown • Sydney • Tokyo • Singapore • Mexico City Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the pub- lisher was aware of a trademark claim, the designations have been printed with initial Editor-in-Chief capital letters or in all capitals. Mark Taub The author and publisher have taken care in the preparation of this book, but make no Acquisitions Editor expressed or implied warranty of any kind and assume no responsibility for errors or Debra Williams Cauley omissions. No liability is assumed for incidental or consequential damages in connection Development Editor with or arising out of the use of the information or programs contained herein. Songlin Qiu The publisher offers excellent discounts on this book when ordered in quantity for bulk Managing Editor purchases or special sales, which may include electronic versions and/or custom covers Kristy Hart and content particular to your business, training goals, marketing focus, and branding Senior Project Editor interests. For more information, please contact: Lori Lyons U.S. Corporate and Government Sales Copy Editor 800-382-3419 Gayle Johnson [email protected] Indexer For sales outside the United States, please contact: Brad Herriman Proofreader International Sales Apostrophe Editing [email protected] Services Visit us on the web: informit.com/ph Publishing Coordinator Kim Boedigheimer Library of Congress Cataloging-in-Publication Data: Cover Designer Bates, Mark, 1976- Chuti Prasertsith Distributed programming with Ruby / Mark Bates. -

Gitlab Letsencrypt and Certbot
Gitlab and Certbot – Lets Encrypt SSL and HTTPS In this post we will talk about HTTPS and how to add it to your GitLab Pages site with Let's Encrypt. Why TLS/SSL? When discussing HTTPS, it's common to hear people saying that a static website doesn't need HTTPS, since it doesn't receive any POST requests, or isn't handling credit card transactions or any other secure request. But that's not the whole story. TLS (formerly SSL) is a security protocol that can be added to HTTP to increase the security of your website by: 1. properly authenticating yourself: the client can trust that you are really you. The TLS handshake that is made at the beginning of the connection ensures the client that no one is trying to impersonate you; 2. data integrity: this ensures that no one has tampered with the data in a request/response cycle; 3. encryption: this is the main selling point of TLS, but the other two are just as important. This protects the privacy of the communication between client and server. The TLS layer can be added to other protocols too, such as FTP (making it FTPS) or WebSockets (making ws://wss://). HTTPS Everywhere Nowadays, there is a strong push for using TLS on every website. The ultimate goal is to make the web safer, by adding those three components cited above to every website. The first big player was the HTTPS Everywhere browser extension. Google has also been using HTTPS compliance to better rank websites since 2014. TLS certificates In order to add TLS to HTTP, one would need to get a certificate, and until 2015, one would need to either pay for it or figure out how to do it with one of the available Certificate Authorities. -

The Rails™ 4 Way
Praise for The Rails Way For intermediates and above, I strongly recommend adding this title to your tech- nical bookshelf. There is simply no other Rails title on the market at this time that offers the technical depth of the framework than The Rails™ 3 Way. — Mike Riley, Dr. Dobb’s Journal I highly suggest you get this book. Software moves fast, especially the Rails API, but I feel this book has many core API and development concepts that will be useful for a while to come. — Matt Polito, software engineer and member of Chicago Ruby User Group This book should live on your desktop if you’re a Rails developer. It’s nearly perfect in my opinion. — Luca Pette, developer The Rails™ 3 Way is likely to take you from being a haphazard poke-a- stick- at- it programmer to a deliberate, skillful, productive, and confi dent RoR developer. — Katrina Owen, JavaRanch I can positively say that it’s the single best Rails book ever published to date. By a long shot. — Antonio Cangiano, software engineer and technical evangelist at IBM psn-fernandez-all.indb i 5/9/14 10:07 AM This book is a great crash course in Ruby on Rails! It doesn’t just document the features of Rails, it fi lters everything through the lens of an experienced Rails developer— so you come out a pro on the other side. — Dirk Elmendorf, cofounder of Rackspace Inc. and Rails developer The key to The Rails Way is in the title. It literally covers the “way” to do almost everything with Rails.