Detection and Identification of Software Encryption Solutions in NT-Based Microsoft Windows Operating Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
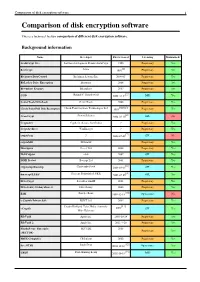
Comparison of Disk Encryption Software 1 Comparison of Disk Encryption Software
Comparison of disk encryption software 1 Comparison of disk encryption software This is a technical feature comparison of different disk encryption software. Background information Name Developer First released Licensing Maintained? ArchiCrypt Live Softwaredevelopment Remus ArchiCrypt 1998 Proprietary Yes [1] BestCrypt Jetico 1993 Proprietary Yes BitArmor DataControl BitArmor Systems Inc. 2008-05 Proprietary Yes BitLocker Drive Encryption Microsoft 2006 Proprietary Yes Bloombase Keyparc Bloombase 2007 Proprietary Yes [2] CGD Roland C. Dowdeswell 2002-10-04 BSD Yes CenterTools DriveLock CenterTools 2008 Proprietary Yes [3][4][5] Check Point Full Disk Encryption Check Point Software Technologies Ltd 1999 Proprietary Yes [6] CrossCrypt Steven Scherrer 2004-02-10 GPL No Cryptainer Cypherix (Secure-Soft India) ? Proprietary Yes CryptArchiver WinEncrypt ? Proprietary Yes [7] cryptoloop ? 2003-07-02 GPL No cryptoMill SEAhawk Proprietary Yes Discryptor Cosect Ltd. 2008 Proprietary Yes DiskCryptor ntldr 2007 GPL Yes DISK Protect Becrypt Ltd 2001 Proprietary Yes [8] cryptsetup/dmsetup Christophe Saout 2004-03-11 GPL Yes [9] dm-crypt/LUKS Clemens Fruhwirth (LUKS) 2005-02-05 GPL Yes DriveCrypt SecurStar GmbH 2001 Proprietary Yes DriveSentry GoAnywhere 2 DriveSentry 2008 Proprietary Yes [10] E4M Paul Le Roux 1998-12-18 Open source No e-Capsule Private Safe EISST Ltd. 2005 Proprietary Yes Dustin Kirkland, Tyler Hicks, (formerly [11] eCryptfs 2005 GPL Yes Mike Halcrow) FileVault Apple Inc. 2003-10-24 Proprietary Yes FileVault 2 Apple Inc. 2011-7-20 Proprietary -

Veracryptcrypt F R E E O P E N - S O U R C E O N - T H E - F L Y E N C R Y P T I O N User’S Guide
VERAVERACRYPTCRYPT F R E E O P E N - S O U R C E O N - T H E - F L Y E N C R Y P T I O N USER’S GUIDE veracrypt.codeplex.com Version Information VeraCrypt User’s Guide, version 1.19 Released by IDRIX on October 17th, 2016 Legal Notices THIS DOCUMENT IS PROVIDED "AS IS" WITHOUT WARRANTY OF ANY KIND, WHETHER EXPRESS, IMPLIED, OR STATUTORY. THE ENTIRE RISK AS TO THE QUALITY, CORRECTNESS, ACCURACY, OR COMPLETENESS OF THE CONTENT OF THIS DOCUMENT IS WITH YOU. THE CONTENT OF THIS DOCUMENT MAY BE INACCURATE, INCORRECT, INVALID, INCOMPLETE AND/OR MISLEADING. IN NO EVENT WILL ANY AUTHOR OF THE SOFTWARE OR DOCUMENTATION, OR ANY APPLICABLE COPYRIGHT OWNER, OR ANY OTHER PARTY WHO MAY COPY AND/OR (RE)DISTRIBUTE THIS SOFTWARE OR DOCUMENTATION, BE LIABLE TO YOU OR TO ANY OTHER PARTY FOR ANY DAMAGES, INCLUDING, BUT NOT LIMITED TO, ANY DIRECT, INDIRECT, GENERAL, SPECIAL, INCIDENTAL, PUNITIVE, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, CORRUPTION OR LOSS OF DATA, ANY LOSSES SUSTAINED BY YOU OR THIRD PARTIES, A FAILURE OF THIS SOFTWARE TO OPERATE WITH ANY OTHER PRODUCT, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES, OR BUSINESS INTERRUPTION), WHETHER IN CONTRACT, STRICT LIABILITY, TORT (INCLUDING, BUT NOT LIMITED TO, NEGLIGENCE) OR OTHERWISE, ARISING OUT OF THE USE, COPYING, MODIFICATION, OR (RE)DISTRIBUTION OF THIS SOFTWARE OR DOCUMENTATION (OR A PORTION THEREOF), OR INABILITY TO USE THIS SOFTWARE OR DOCUMENTATION, EVEN IF SUCH DAMAGES (OR THE POSSIBILITY OF SUCH DAMAGES) ARE/WERE PREDICTABLE OR KNOWN TO ANY (CO)AUTHOR, INTELLECTUAL-PROPERTY OWNER, OR ANY OTHER PARTY. -

Genetec Catalog
GENETEC CONFIDENTIAL Security Center SaaS SaaS Base Package Product Description MSRP (USD) Genetec Security Center SaaS Base Package. Includes 16 entities (cameras, readers, federated sites, intercoms), five (5) Security Desk client connection, five (5) Mobile client connections, five (5) Web client connections, Alarm Management, Advanced Reporting, System Partitioning, SCS-Base_1M $145.00 Incident Reports, and Dynamic Map Support for one tenant. Active Directory, Threat Level, Import Tool and Visitor Management modules are also included as well as Plan Manager for up to 25 entities, and Advanced Plan Manager for GIS Map servers, and Sipelia Base. Genetec Security Center SaaS Base Package. Includes 16 entities (cameras, readers, federated sites, intercoms), five (5) Security Desk client connection, five (5) Mobile client connections, five (5) Web client connections, Alarm Management, Advanced Reporting, System Partitioning, SCS-Base_1Y $1,595.00 Incident Reports, and Dynamic Map Support for one tenant. Active Directory, Threat Level, Import Tool and Visitor Management modules are also included as well as Plan Manager for up to 25 entities, and Advanced Plan Manager for GIS Map servers, and Sipelia Base. Genetec Security Center SaaS Base Video Package on- premises only. Includes five (5) Security Desk client connection, SCS-BaseVideo_1M five (5) Mobile client connections, five (5) Web client $0.00 connections, Alarm Management, Advanced Reporting, System Partitioning, Incident Reports. Genetec Security Center SaaS Base Video Package on- premises only. Includes five (5) Security Desk client connection, SCS-BaseVideo_1Y five (5) Mobile client connections, five (5) Web client $0.00 connections, Alarm Management, Advanced Reporting, System Partitioning, Incident Reports. Video Product Description MSRP (USD) SCS-1C_1M Subscription for 1 camera connection $11.00 SCS-1C_1Y Subscription for 1 camera connection $121.00 Yearly subscription to use the KiwiVision™ Privacy Protector™ SCS-OM-1PP_1M $10.00 module for one camera connection. -

Truecrypt.Org
TTRRUUEECCRRYYPPTT F R E E O P E N - S O U R C E O N - T H E - F L Y E N C R Y P T I O N USER’S GUIDE www.truecrypt.org Version Information TrueCrypt User’s Guide, version 7.1a Released by TrueCrypt Foundation on February 7, 2012 Legal Notices THIS DOCUMENT IS PROVIDED "AS IS" WITHOUT WARRANTY OF ANY KIND, WHETHER EXPRESS, IMPLIED, OR STATUTORY. THE ENTIRE RISK AS TO THE QUALITY, CORRECTNESS, ACCURACY, OR COMPLETENESS OF THE CONTENT OF THIS DOCUMENT IS WITH YOU. THE CONTENT OF THIS DOCUMENT MAY BE INACCURATE, INCORRECT, INVALID, INCOMPLETE AND/OR MISLEADING. IN NO EVENT WILL ANY AUTHOR OF THE SOFTWARE OR DOCUMENTATION, OR ANY APPLICABLE COPYRIGHT OWNER, OR ANY OTHER PARTY WHO MAY COPY AND/OR (RE)DISTRIBUTE THIS SOFTWARE OR DOCUMENTATION, BE LIABLE TO YOU OR TO ANY OTHER PARTY FOR ANY DAMAGES, INCLUDING, BUT NOT LIMITED TO, ANY DIRECT, INDIRECT, GENERAL, SPECIAL, INCIDENTAL, PUNITIVE, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, CORRUPTION OR LOSS OF DATA, ANY LOSSES SUSTAINED BY YOU OR THIRD PARTIES, A FAILURE OF THIS SOFTWARE TO OPERATE WITH ANY OTHER PRODUCT, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES, OR BUSINESS INTERRUPTION), WHETHER IN CONTRACT, STRICT LIABILITY, TORT (INCLUDING, BUT NOT LIMITED TO, NEGLIGENCE) OR OTHERWISE, ARISING OUT OF THE USE, COPYING, MODIFICATION, OR (RE)DISTRIBUTION OF THIS SOFTWARE OR DOCUMENTATION (OR A PORTION THEREOF), OR INABILITY TO USE THIS SOFTWARE OR DOCUMENTATION, EVEN IF SUCH DAMAGES (OR THE POSSIBILITY OF SUCH DAMAGES) ARE/WERE PREDICTABLE OR KNOWN TO ANY (CO)AUTHOR, INTELLECTUAL-PROPERTY OWNER, OR ANY OTHER PARTY. -
Too Much News
Security Now! Transcript of Episode #553 Page 1 of 44 Transcript of Episode #553 Too Much News Description: Leo and I discuss a VERY interesting week of news: The FBI dropping its case against Apple, claiming not to need them any longer; a distressing possible smartphone encryption law for California; TrueCrypt's origins; a Certificate Authority horror; more hospitals hit with ransomware; a bad flaw in the SMB protocol; finally some good news on the IoT front; GRC's new Never10 freeware; and a discussion of the monster PC I just built. High quality (64 kbps) mp3 audio file URL: http://media.GRC.com/sn/SN-553.mp3 Quarter size (16 kbps) mp3 audio file URL: http://media.GRC.com/sn/sn-553-lq.mp3 SHOW TEASE: It's time for Security Now!. We're going to talk security big-time. Lots of news this week. And we'll talk about Steve's new utility, Never10 - Never10 - and his brand new PC build, which is mindboggling. I asked him how much it cost. He said, "I don't know, I didn't bother to add it up." I wouldn't, if I were you, Steve. It's all next on Security Now!. Leo Laporte: This is Security Now! with Steve Gibson, Episode 553, recorded Tuesday, March 29th, 2016: Too Much News. It's time for Security Now!, the show where we cover your security and privacy online with the Explainer in Chief, Mr. Steve Gibson from GRC.com. And a happy day to you, Steve. I'm sorry I wasn't here last week, but I hear you and Father Robert Ballecer had a wonderful time together. -

VSI Alliancetm White Paper Technical Measures and Best Practices
VSI AllianceTM White Paper Technical Measures and Best Practices for Securing Proprietary Information Version 1.0 (IPPWP3 1.0) Issued by the Intellectual Property Protection Development Working Group November 2002 VSI Alliance (IPPWP3 1.0) NOT LEGAL ADVICE The discussions of the law in this document are not intended to be legal advice. This document is not to be used as a legal reference. Readers should refer to their own legal counsel for answers to questions concerning the law. Copyright 2002 by VSI Alliance, Inc. 15495 Los Gatos Boulevard, Suite #3 Los Gatos, California 95032, USA Phone: (408) 356-8800, Fax: 408-356-9018 http://www.vsi.org, [email protected] VSI Alliance is a trademark of the VSI Alliance, Inc. All other trademarks are the property of their respective owners. Please send comments and questions to: IP Protection Development Working Group (DWG), VSIA Ian R. Mackintosh Chair 3054 Three Springs Road, San Jose, CA 95140 408-406-3152, [email protected] Raymond Burkley Vice-Chair Burkley Associates, P. O. Box 496, Cupertino, CA 95015 408-735-1540, [email protected] VSI Alliance 115495 Los Gatos Blvd, Suite 3, Los Gatos, CA 95032 408-356-8800, info Copyright 2002 by the VSI Alliance, Inc. i All Rights Reserved. VSIA CONFIDENTIAL DOCUMENT VSI Alliance (IPPWP3 1.0) Copyright 2002 by the VSI Alliance, Inc. ii All Rights Reserved. VSIA CONFIDENTIAL DOCUMENT VSI Alliance (IPPWP3 1.0) Notice The document is provided by VSIA subject to a license agreement, which restricts how this document may be used. THIS DOCUMENT MAY NOT BE COPIED, DUPLICATED, OR OTHERWISE REPRODUCED. -

Truecrypt User Guide
TRUECRYPT F R E E O P E N - S O U R C E O N - T H E - F L Y E N C R Y P T I O N USER’S GUIDE www.truecrypt.org Version Information TrueCrypt User’s Guide, version 5.1a. Released March 17, 2008. Licensing Information By installing, running, using, copying, (re)distributing, and/or modifying TrueCrypt or a portion thereof you accept all terms, responsibilities and obligations contained in the TrueCrypt License the full text of which is contained in the file License.txt included in TrueCrypt binary and source code distribution packages. Copyright Information This software as a whole: Copyright © 2008 TrueCrypt Foundation. All rights reserved. Portions of this software: Copyright © 2003-2008 TrueCrypt Foundation. All rights reserved. Copyright © 1998-2000 Paul Le Roux. All rights reserved. Copyright © 1998-2008 Brian Gladman, Worcester, UK. All rights reserved. Copyright © 1995-1997 Eric Young. All rights reserved. Copyright © 2001 Markus Friedl. All rights reserved. Copyright © 2002-2004 Mark Adler. All rights reserved. For more information, please see the legal notices attached to parts of the source code. Trademark Information TrueCrypt and the TrueCrypt logos are trademarks of the TrueCrypt Foundation. Note: The goal is not to monetize the name or the product, but to protect the reputation of TrueCrypt, and to prevent support issues and other kinds of issues that might arise from the existence of similar products with the same or similar name. Even though TrueCrypt is a trademark, TrueCrypt is and will remain open-source and free software. All other trademarks are the sole property of their respective owners. -

March 2, 1901, Vol. 72, No. 1862
: 1 pimnrial 0mni£rna xmiti Qijotation Supplement (Monthly) Street Kailwai|5uppIement4iTiiAnnuaiii> Investors Supplement (Quarterly) Stale and C% Supplement ^xnnuai^ [Entered aooordlng to Act of Oongress, In the ye&t 1900, by the Wiu.iAi( B. Daha Ookpaht, in the office of the Librarian of GongreBs.] VOL. 72 SATURDAY. MARCH A 1901. NO. 18^)2 Week ending February 83 Clearings at— 1901. PUBLISHED WEEKLY. 1901. 1900. P. Cent. 1899. 1898. Termg of Subscription—Payable In Adyance 00 Boston 108 8S7,g38 98.628.086 --10-4 183 933.530 89.814.679 For One Year $10 -1-8 Six Months 6 00 Providence 5,560.500 5,662,100 5.861,500: 4,&S0.7C0 For Hartford 2,815,634, -22 2,424,045 Subscription (Including postage) 13 00 1,802.744 8 2,0^4.670 Bnropeau New HaT^en 1,165,021 1,570 513 -268 1,305.623 1.342.597 European Subsoriptlon Six Montne (Including postage) 7 50 SprlDKfleld l,li!4.2>!B 1,018.802! -HO-9 1.691,450 1,302,586 Annual Subscription In London (Including postage) M2 148 Worcester 1.255,455 1,034.874 -1-213 1,507.598] 1 202,0ilfl Portland 973.619 798,888 -<-22-8 1,287,453 BlxMos. do. do. do. Al lis. 1 081,248 Fall River 651,081 874,863 —24-9 1.88^,358 772.001 Above subscription Includes— Lowell 4B0.780 469.177 -H'8 731,133 540,861 New 374,589 869.429 -I-I-4 401,124 Thb Quotation bupplkment | stbeet Railway StrppLBMEirr Bedford 883,436 Holyoke 283 855 273,940 -|-3'4 270,000 The Investoks' Supplement | State and City Supplement 1 Total New Bnif. -

Security Now! #553Ана032916 Too Much News
Security Now! #553 032916 Too Much News This week on Security Now! ● U.S. Says It Has Unlocked iPhone Without Apple ● California Assembly Bill AB1681 ● Was TrueCrypt originally created by an international arms dealer? ● A major flaw in the StartSSL Certificate Authority ● Two more Hospitals hit with ransomware ● A problem found in the SAMBA protocol ● Finally, some good news on the IoT device setup front ● Announcing GRC's Never10 freeware ● A bit more about the new monster PC I built US Government Filing to Drop Case Against Apple Security News U.S. Says It Has Unlocked iPhone Without Apple http://www.nytimes.com/2016/03/29/technology/appleiphonefbijusticedepartmentcase.htm l The Justice Department said on Monday that it had found a way to unlock an iPhone without help from Apple, allowing the agency to withdraw its legal effort to compel the tech company to assist in a massshooting investigation. Yet law enforcement’s ability to now unlock an iPhone through an alternative method raises new uncertainties, including questions about the strength of security in Apple devices. The development also creates potential for new conflicts between the government and Apple about the method used to open the device and whether that technique will be disclosed. Lawyers for Apple have previously said the company would want to know the procedure used to crack open the smartphone, yet the government might classify the method. A staff attorney at the American Civil Liberties Union was quoted: “I would hope they would give that information to Apple so that it can patch any weaknesses, but if the government classifies the tool, that suggests it may not.” F.B.I. -

Firewalls and Virtual Private Networks Acknowledgements
Firewalls and Virtual Private Networks A thesis submitted in partial fulfilment of the requirements for the Degree of Master of Commerce in Computer Science in the University of Canterbury by B. A. Harris University of Canterbury 1998 Firewalls and Virtual Private Networks Acknowledgements Acknowledgements There are a great number of people that I wish to thank for helping me undertake this thesis. Perhaps I should start with my supervisor and friend, Ray Hunt, who has provided me with unwavering support, encouragement, and of course much needed criticism. I believe that without your help and enthusiasm this work would probably have never seen the light of day. Thank you. I am equally indebted to my fiancee Sharalie, who has stoically endured many months of separation while I pursued my dream. Your love and encouragement were given without hesitation, and for that I love you even more. I cannot go any further without acknowledging all of the support and encouragement given by my parents, sister, and future parents-in-law. Each of you have contributed in your own special way, and helped smooth a path that at times threatened to become very difficult indeed. There are a number of friends that I wish to thank because they have contributed significantly, in a variety of ways, to the completion of my thesis. So please bear with me - Matthew Brady for commanding and conquering my battles; Greg Slui and Rebecca Gilmore for being great friends and providing me with somewhere to go; Mark Snelling for inspiration and cryptographic support; Stephen Harvey for entertaining discussion and helping me understand public-key infrastructures; and Sylvester and Scooby-Doo for providing essential relaxation and escapism. -

Security Analysis of Truecrypt 7.0A with an Attack on the Keyfile Algorithm
Security Analysis of TrueCrypt 7.0a with an Attack on the Keyfile Algorithm Ubuntu Privacy Remix Team <[email protected]> August 14, 2011 Contents Preface.............................................................................................................................................1 1. Data of the Program.....................................................................................................................2 2. Remarks on Binary Packages of TrueCrypt 7.0a..........................................................................3 3. Compiling TrueCrypt 7.0a from Sources.......................................................................................3 Compiling TrueCrypt 7.0a on Linux..............................................................................................3 Compiling TrueCrypt 7.0a on Windows........................................................................................4 4. Methodology of Analysis...............................................................................................................5 5. The program tcanalyzer................................................................................................................6 6. Findings of Analysis......................................................................................................................7 The TrueCrypt License.................................................................................................................7 Website and Documentation of TrueCrypt...................................................................................7 -

Firewalls and Virtual Private Networks Acknowledgements
Firewalls and Virtual Private Networks A thesis submitted in partial fulfilment of the requirements for the Degree of Master of Commerce in Computer Science in the University of Canterbury by B. A. Harris University of Canterbury 1998 YSICAL 'l"NCj:S Firewalls and Virtual Private Networks Acknowledgements Acknowledgements There are a great number of people that I wish to thank for helping me undertake this thesis. Perhaps I should start with my supervisor and friend, Ray Hunt, who has provided me with unwavering support, encouragement, and of course much needed criticism. I believe that without your help and enthusiasm this work would probably have never seen the light of day. Thank you. I am equally indebted to my fiancee Sharalie, who has stoically endured many months of separation while I pursued my dream. Your love and encouragement were given without hesitation, and for that I love you even more. I cannot go any further without acknowledging all of the support and encouragement given by my parents, sister, and future parents-in-law. Each of you have contributed in your own special way, and helped smooth a path that at times threatened to become very difficult indeed. There are a number of friends that I wish to thank because they have contributed significantly, in a variety of ways, to the completion of my thesis. So please bear with me Matthew Brady for commanding and conquering my battles; Greg Slui and Rebecca Gilmore for being great friends and providing me with somewhere to go; Mark Snelling for inspiration and cryptographic support; Stephen Harvey for entertaining discussion and helping me understand public-key infrastructures; and Sylvester and Scooby-Doo for providing essential relaxation and escapism.