Semantically-Enriched Business Process Modeling and Management
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
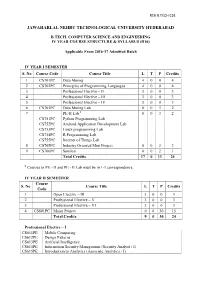
R16 B.TECH CSE IV Year Syllabus
R16 B.TECH CSE. JAWAHARLAL NEHRU TECHNOLOGICAL UNIVERSITY HYDERABAD B.TECH. COMPUTER SCIENCE AND ENGINEERING IV YEAR COURSE STRUCTURE & SYLLABUS (R16) Applicable From 2016-17 Admitted Batch IV YEAR I SEMESTER S. No Course Code Course Title L T P Credits 1 CS701PC Data Mining 4 0 0 4 2 CS702PC Principles of Programming Languages 4 0 0 4 3 Professional Elective – II 3 0 0 3 4 Professional Elective – III 3 0 0 3 5 Professional Elective – IV 3 0 0 3 6 CS703PC Data Mining Lab 0 0 3 2 7 PE-II Lab # 0 0 3 2 CS751PC Python Programming Lab CS752PC Android Application Development Lab CS753PC Linux programming Lab CS754PC R Programming Lab CS755PC Internet of Things Lab 8 CS705PC Industry Oriented Mini Project 0 0 3 2 9 CS706PC Seminar 0 0 2 1 Total Credits 17 0 11 24 # Courses in PE - II and PE - II Lab must be in 1-1 correspondence. IV YEAR II SEMESTER Course S. No Course Title L T P Credits Code 1 Open Elective – III 3 0 0 3 2 Professional Elective – V 3 0 0 3 3 Professional Elective – VI 3 0 0 3 4 CS801PC Major Project 0 0 30 15 Total Credits 9 0 30 24 Professional Elective – I CS611PE Mobile Computing CS612PE Design Patterns CS613PE Artificial Intelligence CS614PE Information Security Management (Security Analyst - I) CS615PE Introduction to Analytics (Associate Analytics - I) R16 B.TECH CSE. Professional Elective – II CS721PE Python Programming CS722PE Android Application Development CS723PE Linux Programming CS724PE R Programming CS725PE Internet of Things Professional Elective - III CS731PE Distributed Systems CS732PE Machine Learning CS733PE -

DRE) for Software
Exceeding 99% in Defect Removal Efficiency (DRE) for Software Draft 11.0 September 6, 2016 Capers Jones, VP and CTO, Namcook Analytics LLC Abstract Software quality depends upon two important variables. The first variable is that of “defect potentials” or the sum total of bugs likely to occur in requirements, architecture, design, code, documents, and “bad fixes” or new bugs in bug repairs. Defect potentials are measured using function point metrics, since “lines of code” cannot deal with requirements and design defects. (This paper uses IFPUG function points version 4.3. The newer SNAP metrics are only shown experimentally due to insufficient empirical quality data with SNAP as of 2016. However an experimental tool is included for calculating SNAP defects.) The second important measure is “defect removal efficiency (DRE)” or the percentage of bugs found and eliminated before release of software to clients. The metrics of Defect Potentials and Defect Removal Efficiency (DRE) were developed by IBM circa 1973 and are widely used by technology companies and also by insurance companies, banks, and other companies with large software organizations. The author’s Software Risk Master (SRM) estimating tool predicts defect potentials and defect removal efficiency (DRE) as standard quality outputs for all software projects. Web: www.Namcook.com Email: [email protected] Copyright © 2016 by Capers Jones. All rights reserved. 1 Introduction Defect potentials and defect removal efficiency (DRE) are useful quality metrics developed by IBM circa 1973 and widely used by technology companies as well as by banks, insurance companies, and other organizations with large software staffs. This combination of defect potentials using function points and defect removal efficiency (DRE) are the only accurate and effective measures for software quality. -

ITSSD Assessment of the New ISO 26000 Social Responsibility Standard
ITSSD Assessment of the new ISO 26000 Social Responsibility Standard December 2005 Preliminary Conclusions: 1. It may be possible to procedurally shape and/or delay the development of the ISO SR guidance standard at the national mirror and international levels. 2. It may be impossible to prevent the actual adoption of an SR standard at the DIS and FDIS stages, unless the ISO voting rules are first modified to reflect only one vote for the European Community as a whole through its regional standards representative (e.g., CEN), as opposed to twenty-five separate votes representing the national standards bodies of each of the EU member states. 3. It is likely to be difficult to reverse the new stakeholder engagement process that has been introduced at the ISO incident to the commencement of this SR standard initiative, though it may arguably be shaped by filing procedural objections, and by strengthening traditional ISO benchmarks for consensus. 4. The real challenge is to prevent the new process from being expanded institutionally to all of ISO’s technical standards work, and thereby from being incorporated within business contracts that reference or directly incorporate such standards as conditions of manufacture, sale, service, etc. This is likely to be quite difficult given the current efforts of governments, NGOs and UN agencies to incorporate sustainable development dimensions into all ISO technical standards. 5. Further study and analysis of the evolving ISO SR operating procedures, the multi-stakeholder engagement process, and the ISO’s general consensus procedures is necessary to determine the proper course of action and the appropriate actors with which/whom to collaborate. -

Opinions of Small and Medium UK Construction Companies On
Opinions of small and medium UK construction companies on environmental management systems Bailey, M, Booth, CA, Horry, R, Vidalakis, C, Mahamadu, A-M and Gyau, KAB http://dx.doi.org/10.1680/jmapl.19.00033 Title Opinions of small and medium UK construction companies on environmental management systems Authors Bailey, M, Booth, CA, Horry, R, Vidalakis, C, Mahamadu, A-M and Gyau, KAB Type Article URL This version is available at: http://usir.salford.ac.uk/id/eprint/56909/ Published Date 2021 USIR is a digital collection of the research output of the University of Salford. Where copyright permits, full text material held in the repository is made freely available online and can be read, downloaded and copied for non-commercial private study or research purposes. Please check the manuscript for any further copyright restrictions. For more information, including our policy and submission procedure, please contact the Repository Team at: [email protected]. Accepted manuscript doi: 10.1680/jmapl.19.00033 Accepted manuscript As a service to our authors and readers, we are putting peer-reviewed accepted manuscripts (AM) online, in the Ahead of Print section of each journal web page, shortly after acceptance. Disclaimer The AM is yet to be copyedited and formatted in journal house style but can still be read and referenced by quoting its unique reference number, the digital object identifier (DOI). Once the AM has been typeset, an ‘uncorrected proof’ PDF will replace the ‘accepted manuscript’ PDF. These formatted articles may still be corrected by the authors. During the Production process, errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal relate to these versions also. -

ISO 14000 Assessing Its Impact on Corporate Effectiveness and Efficiency
ISO 14000 Assessing Its Impact on Corporate Effectiveness and Efficiency Steven A. Melnyk Roger Calantone Rob Handfield R.L. (Lal) Tummala Gyula Vastag Timothy Hinds Robert Sroufe Frank Montabon Michigan State University Sime Curkovic Western Michigan University Contents Tables, Exhibits, Charts, and Appendices .................................................................... 4 Acknowledgments.......................................................................................................... 5 Executive Summary....................................................................................................... 6 Implications of the Study .............................................................................................. 7 Design of the Study........................................................................................................ 8 Overview .................................................................................................................... 8 The Large-Scale Survey.............................................................................................. 8 The Sample ............................................................................................................ 9 The Case Studies........................................................................................................ 9 The Sample for the Case Studies Phase ............................................................... 9 The Interview Protocol Described....................................................................... -

This Is Not a Complete Sample Paper
BCS Practitioner Certificate in Information Assurance Architecture Specimen Paper – This is not a complete sample paper. Attempt all 85 multiple-choice questions – 1 mark awarded to each question. Mark only one answer to each question. There are no trick questions. Section A – multiple-choice questions There are 60 questions for Section A, awarding 1 mark per question for a total of 60 points. Section B – Scenario based multi-choice questions There are 25 questions for Section B, over 5 scenarios, awarding 13 points per scenario, for a total of 65 points. Pass Mark: 81/125 65% This specimen paper has 30 questions in Section A with 30 points available for Section A and 3 scenarios with 15 questions in Section B with 39 points available. Therefore there are 69 points available for both sections. Specimen Paper Pass Mark: 45/69 65% Copying of this paper is expressly forbidden without the direct approval of BCS, The Chartered Institute for IT. Copyright © BCS 2014 Page 1 of 21 PCiAA Sample Paper A Version 1.0 August 2014 This page is intentionally blank. Section A Multiple-choice answers – 1 mark each NOTE: Choose only one answer per question 1 What is the correct ordering (Conceptual to Component) of the following artefacts for the SABSA Motivation (WHY) foci? a. Security Policies. b. Security Standards. c. Control Objectives. d. Security Rules, Practices and Procedures. A c, a, d and b. B a, c, b and d. C b, a, d and c. D c, b, a and d. 2 In the TOGAF Content MetaModel, under which viewpoint would you find the Business Principles, Objectives and Drivers? A Motivation. -

Parameterization, Analysis, and Risk Management in a Comprehensive Management System with Emphasis on Energy and Performance (ISO 50001: 2018)
energies Article Parameterization, Analysis, and Risk Management in a Comprehensive Management System with Emphasis on Energy and Performance (ISO 50001: 2018) P. Pablo Poveda-Orjuela 1,*, J. Carlos García-Díaz 2 , Alexander Pulido-Rojano 3 and Germán Cañón-Zabala 4 1 ASTEQ Technology, 53 Street No. 53-15, Barranquilla 080020, Colombia 2 Centre for Quality and Change Management, Universitat Politècnica de València, Camino de Vera, s/n. 46022 Valencia, Spain; [email protected] 3 Industrial Engineering Department, Universidad Simón Bolívar, Av. 59 No. 59-92, Barranquilla 080020, Colombia; [email protected] 4 QUARA Group, 157 Street No. 13 B-20, Bogotá 110121, Colombia; [email protected] * Correspondence: [email protected] or [email protected]; Tel.: +57-3008897111 Received: 7 September 2020; Accepted: 13 October 2020; Published: 26 October 2020 Abstract: The future of business development relies on the effective management of risks, opportunities, and energy and water resources. Here, we evaluate the application of best practices to identify, analyze, address, monitor, and control risks and opportunities (R/O) according to ISO 31000 and 50000. Furthermore, we shed light on tools, templates, ISO guides, and international documents that contribute to classifying, identifying, formulating control, and managing R/O parameterization in a comprehensive management system model, namely CMS QHSE3+, which consists of quality (Q), health and safety (HS), environmental management (E), energy efficiency (E2), and other risk components (+) that include comprehensive biosecurity and biosafety. By focusing on the deployment of R/O-based thinking (ROBT) at strategic and operational levels, we show vulnerability reduction in CMS QHSE3+ by managing energy, efficiency, and sustainability. -

Community-Driven Organisation of Metadata Schemas to Support FAIR Nanoscience Data
nanomaterials Article Metadata Stewardship in Nanosafety Research: Community-Driven Organisation of Metadata Schemas to Support FAIR Nanoscience Data Anastasios G. Papadiamantis 1,2,* , Frederick C. Klaessig 3 , Thomas E. Exner 4 , Sabine Hofer 5 , Norbert Hofstaetter 5 , Martin Himly 5 , Marc A. Williams 6, Philip Doganis 7 , Mark D. Hoover 8 , Antreas Afantitis 2 , Georgia Melagraki 2 , Tracy S. Nolan 9 , John Rumble 10,11 , Dieter Maier 12 and Iseult Lynch 1,* 1 School of Geography, Earth and Environmental Sciences, University of Birmingham, Birmingham B15 2TT, UK 2 Novamechanics Ltd., 1065 Nicosia, Cyprus; [email protected] (A.A.); [email protected] (G.M.) 3 Pennsylvania Bio Nano Systems, Doylestown, PA 18901, USA; [email protected] 4 Edelweiss Connect, CH-4057 Basel, Switzerland; [email protected] 5 Department of Biosciences, Paris Lodron University of Salzburg, 5020 Salzburg, Austria; [email protected] (S.H.); [email protected] (N.H.); [email protected] (M.H.) 6 U.S. Army Public Health Center (APHC), Aberdeen Proving Ground—South, Aberdeen, MD 21010, USA; [email protected] 7 School of Chemical Engineering, National Technical University of Athens, 157 80 Athens, Greece; [email protected] 8 Mark D Hoover LLC, Morgantown, WV 26505, USA; [email protected] 9 Department of Biomedical Informatics, University of Arkansas for Medical Sciences, Little Rock, AR 72205, USA; [email protected] 10 R&R Data Services, Gaithersburg, MD -

Iso 14000 Standards Environmental Management for the 21St Century
AC 1997-249: ISO 14000 Standards-Environmental Management for the 21st Century Marilyn Barger, Hillsborough Community College Page 2.266.1 Page © American Society for Engineering Education, 1997 Session 2251 ISO 14000 Standards- Environmental Management for the 21st Century Dr. Marilyn Barger, P.E . Department of Civil Engineering FAMU-FSU College of Engineering ISO 9000 series is the international standard for a quality control system that guarantees a least performance level for products and guidelines to achieve ISO certification. These have been in place for several years and have become widespread in the manufacturing, service, and product development businesses. ISO 14000 standards are patterned from the 9000 series, are expected to be issued within the next year, will encompass environmental management standards under three organizational elements and three additional product-oriented elements. The organizational elements to be included are: Environmental Management Systems, Environmental Auditing, and Environmental Performance. The three product-related elements will be: Life Cycle Analysis, Environmental Labeling; and Environmental Aspects of Product Standards. The basis for all of the international standards developed by ISO is the idea of quality management (QM). Successful application of any of the existing standards in the upcoming ISO 14000 series requires a firm understanding by the engineering and technical professions what these standards require. Taken to their ultimate conclusion, all ISO standards themselves provide the guidelines to achieving ISO certification, which in turn, characterizes the organization by the very standards it set to achieve by that certification. This paper will review the important aspects and the underlying philosophy of these standards, presenting the 9000 series as background for the new 14000 standards. -

Essays on Environmental Economics and Policy
University of Kentucky UKnowledge Theses and Dissertations--Agricultural Economics Agricultural Economics 2018 ESSAYS ON ENVIRONMENTAL ECONOMICS AND POLICY Mehdi Nemati University of Kentucky, [email protected] Author ORCID Identifier: https://orcid.org/0000-0002-4736-7489 Digital Object Identifier: https://doi.org/10.13023/etd.2018.232 Right click to open a feedback form in a new tab to let us know how this document benefits ou.y Recommended Citation Nemati, Mehdi, "ESSAYS ON ENVIRONMENTAL ECONOMICS AND POLICY" (2018). Theses and Dissertations--Agricultural Economics. 66. https://uknowledge.uky.edu/agecon_etds/66 This Doctoral Dissertation is brought to you for free and open access by the Agricultural Economics at UKnowledge. It has been accepted for inclusion in Theses and Dissertations--Agricultural Economics by an authorized administrator of UKnowledge. For more information, please contact [email protected]. STUDENT AGREEMENT: I represent that my thesis or dissertation and abstract are my original work. Proper attribution has been given to all outside sources. I understand that I am solely responsible for obtaining any needed copyright permissions. I have obtained needed written permission statement(s) from the owner(s) of each third-party copyrighted matter to be included in my work, allowing electronic distribution (if such use is not permitted by the fair use doctrine) which will be submitted to UKnowledge as Additional File. I hereby grant to The University of Kentucky and its agents the irrevocable, non-exclusive, and royalty-free license to archive and make accessible my work in whole or in part in all forms of media, now or hereafter known. -

Methods and Tools for Performance Assurance of Smart Manufacturing Systems
METHODS AND TOOLS FOR PERFORMANCE ASSURANCE OF SMART MANUFACTURING SYSTEMS Deogratias Kibira, K C Morris, and Senthilkumaran Kumaraguru ABSTRACT The emerging concept of smart manufacturing systems is defined in part by the introduction of new technologies that are promoting rapid and widespread information flow within the manufacturing system and surrounding its control. These systems can deliver unprecedented awareness, agility, productivity, and resilience within the production process by exploiting the ever-increasing availability of real-time manufacturing data. Optimized collection and analysis of this voluminous data and subsequent distribution of extracted information to guide decision- making throughout the enterprise necessitate, however, a complex and dynamic process. To establish and maintain confidence that smart manufacturing systems function as intended, performance assurance measures will be vital. The activities for performance assurance span manufacturing system design, operation, performance assessment, evaluation, analysis, decision making, and control. Changes may be needed for traditional approaches in these activities to address smart manufacturing systems. This paper reviews the current methods and tools used for establishing and maintaining required system performance. This paper then identifies trends in data and information systems, integration, performance measurement, analysis, and performance improvement that will be vital for assured performance of smart manufacturing systems. Finally, we analyze how those -

Best Practice Principles
BEST PRACTICE PRINCIPLES The Assurance Programme Requirements 2020 CONTENTS PREFACE 2 ABBREVIATIONS 3 A BUSINESS RESPONSIBILITIES 5 A.1 ETHICAL STANDARDS 5 A.2 COMMITMENT 6 A.3 BRIBERY, ANTI-CORRUPTION, FACILITATION PAYMENTS AND GIFTS 6 A.4 FINANCIAL OFFENCES 6 A.5 KIMBERLEY PROCESS AND SYSTEM OF WARRANTIES 7 A.6 SOURCING FROM CONFLICT-AFFECTED AND HIGH-RISK AREAS 8 A.7 PRODUCT SECURITY 17 A.8 DISCLOSURE 17 A.9 MELEE ASSURANCE PROTOCOL FOR SIGHTHOLDERS AND ACCREDITED BUYERS 21 A.10 SUPPLY CHAIN MANAGEMENT/BEST ENDEAVOURS 23 A.11 PROVENANCE CLAIMS 23 A.12 GRADING, ANALYSIS AND APPRAISAL 24 B SOCIAL RESPONSIBILITIES 25 B.1 EMPLOYMENT 25 B.2 HEALTH & SAFETY 26 B.3 NON-DISCRIMINATION AND DISCIPLINARY PRACTICES 28 B.4 CHILD LABOUR 29 B.5 FORCED LABOUR 30 B.6 HUMAN RIGHTS 30 B.7 SOURCING FROM ARTISANAL AND SMALL-SCALE MINING 32 C ENVIRONMENTAL RESPONSIBILITIES 33 C.1 BEST ENVIRONMENTAL PRACTICE AND THE REGULATORY FRAMEWORK 33 D MINING 34 D.1 EXTRACTIVE INDUSTRIES TRANSPARENCY INITIATIVE: 34 D.2 IMPACT ASSESSMENT 34 D.3 COMMUNITY ENGAGEMENT AND DEVELOPMENT 34 D.4 HEALTH & SAFETY EMERGENCY PROCEDURES 36 D.5 BIODIVERSITY 37 D.6 NATURAL RESOURCE MANAGEMENT AND ENVIRONMENTAL RISK 38 D.7 MERCURY 39 D.8 INDIGENOUS PEOPLES 39 D.9 ARTISANAL AND SMALL-SCALE MINING 40 D.10 SECURITY GUARDS 40 D.11 MINE CLOSURE PLANNING 40 D.12 SUSTAINABILITY REPORTING 41 E CORPORATE SOCIAL INVESTMENT AND BUSINESS IMPACT 42 F GOLD, PLATINUM GROUP METALS, SILVER AND COLOURED STONES 44 G INTEGRITY OF THE BPP PROGRAMME 44 PREFACE This document sets out the detailed requirements of the De Beers Group Best Practice Principles (BPPs).