DRE) for Software
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Use of Summation to Aggregate Software Metrics Hinders the Performance of Defect Prediction Models
IEEE TRANSACTIONS ON SOFTWARE ENGINEERING, VOL. XX, NO. XX, XXX 2016 1 The Use of Summation to Aggregate Software Metrics Hinders the Performance of Defect Prediction Models Feng Zhang, Ahmed E. Hassan, Member, IEEE, Shane McIntosh, Member, IEEE, and Ying Zou, Member, IEEE Abstract—Defect prediction models help software organizations to anticipate where defects will appear in the future. When training a defect prediction model, historical defect data is often mined from a Version Control System (VCS, e.g., Subversion), which records software changes at the file-level. Software metrics, on the other hand, are often calculated at the class- or method-level (e.g., McCabe’s Cyclomatic Complexity). To address the disagreement in granularity, the class- and method-level software metrics are aggregated to file-level, often using summation (i.e., McCabe of a file is the sum of the McCabe of all methods within the file). A recent study shows that summation significantly inflates the correlation between lines of code (Sloc) and cyclomatic complexity (Cc) in Java projects. While there are many other aggregation schemes (e.g., central tendency, dispersion), they have remained unexplored in the scope of defect prediction. In this study, we set out to investigate how different aggregation schemes impact defect prediction models. Through an analysis of 11 aggregation schemes using data collected from 255 open source projects, we find that: (1) aggregation schemes can significantly alter correlations among metrics, as well as the correlations between metrics and -

Software Maintainability a Brief Overview & Application to the LFEV 2015
Software Maintainability A Brief Overview & Application to the LFEV 2015 Adam I. Cornwell Lafayette College Department of Electrical & Computer Engineering Easton, Pennsylvania [email protected] Abstract — This paper gives a brief introduction on For “lexical level” approaches which base what software maintainability is, the various methods complexity on program code, the following which have been devised to quantify and measure software maintainability, its relevance to the ECE 492 measurands are typical: individual and average Senior Design course, and some practical lines of code; number of commented lines, implementation guidelines. executable statements, blank lines, tokens, and data declarations; source code readability, or the Keywords — Software Maintainability; Halstead ratio of LOC to commented LOC; Halstead Metrics; McCabe’s Cyclomatic complexity; radon Metrics, including Halstead Length, Volume, and Effort; McCabe’s Cyclomatic Complexity; the I. INTRODUCTION control structure nesting level; and the number of Software Maintainability is an important knots, or the number of times the control flow concept in the upkeep of long-term software crosses. The final measurand is not as useful with systems. According to the IEEE, software object oriented programming but can still be of maintainability is defined as “the ease with which some use. a software system or component can be modified to correct faults, improve performance or other “Psychological complexity” approaches measure attributes, or adapt to a changed environment difficulty and are based on understandability and [1].” Software Maintainability can be measured the user [3]. The nature of the file and the using various devised methods, although none difficulty experienced by those working with the have been conclusively shown to work in a large file are what contribute to these kinds of variety of software systems [6]. -

A Metrics-Based Software Maintenance Effort Model
A Metrics-Based Software Maintenance Effort Model Jane Huffman Hayes Sandip C. Patel Liming Zhao Computer Science Department Computer Science Department Computer Science Department Lab for Advanced Networking University of Louisville University of Kentucky University of Kentucky [email protected] [email protected] [email protected] (corresponding author) Abstract planning a new software development project. Albrecht introduced the notion of function points (FP) to estimate We derive a model for estimating adaptive software effort [1]. Mukhopadhyay [19] proposes early software maintenance effort in person hours, the Adaptive cost estimation based on requirements alone. Software Maintenance Effort Model (AMEffMo). A number of Life Cycle Management (SLIM) [23] is based on the metrics such as lines of code changed and number of Norden/Rayleigh function and is suitable for large operators changed were found to be strongly correlated projects. Shepperd et al. [27] argued that algorithmic cost to maintenance effort. The regression models performed models such as COCOMO and those based on function well in predicting adaptive maintenance effort as well as points suggested an approach based on using analogous provide useful information for managers and maintainers. projects to estimate the effort for a new project. In addition to the traditional off-the-self models such as 1. Introduction COCOMO, machine-learning methods have surfaced recently. In [17], Mair et al. compared machine-learning Software maintenance typically accounts for at least 50 methods in building software effort prediction systems. percent of the total lifetime cost of a software system [16]. There has also been some work toward applying fuzzy Schach et al. -
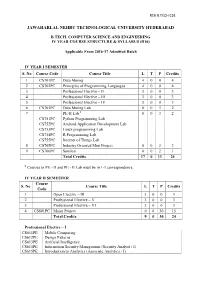
R16 B.TECH CSE IV Year Syllabus
R16 B.TECH CSE. JAWAHARLAL NEHRU TECHNOLOGICAL UNIVERSITY HYDERABAD B.TECH. COMPUTER SCIENCE AND ENGINEERING IV YEAR COURSE STRUCTURE & SYLLABUS (R16) Applicable From 2016-17 Admitted Batch IV YEAR I SEMESTER S. No Course Code Course Title L T P Credits 1 CS701PC Data Mining 4 0 0 4 2 CS702PC Principles of Programming Languages 4 0 0 4 3 Professional Elective – II 3 0 0 3 4 Professional Elective – III 3 0 0 3 5 Professional Elective – IV 3 0 0 3 6 CS703PC Data Mining Lab 0 0 3 2 7 PE-II Lab # 0 0 3 2 CS751PC Python Programming Lab CS752PC Android Application Development Lab CS753PC Linux programming Lab CS754PC R Programming Lab CS755PC Internet of Things Lab 8 CS705PC Industry Oriented Mini Project 0 0 3 2 9 CS706PC Seminar 0 0 2 1 Total Credits 17 0 11 24 # Courses in PE - II and PE - II Lab must be in 1-1 correspondence. IV YEAR II SEMESTER Course S. No Course Title L T P Credits Code 1 Open Elective – III 3 0 0 3 2 Professional Elective – V 3 0 0 3 3 Professional Elective – VI 3 0 0 3 4 CS801PC Major Project 0 0 30 15 Total Credits 9 0 30 24 Professional Elective – I CS611PE Mobile Computing CS612PE Design Patterns CS613PE Artificial Intelligence CS614PE Information Security Management (Security Analyst - I) CS615PE Introduction to Analytics (Associate Analytics - I) R16 B.TECH CSE. Professional Elective – II CS721PE Python Programming CS722PE Android Application Development CS723PE Linux Programming CS724PE R Programming CS725PE Internet of Things Professional Elective - III CS731PE Distributed Systems CS732PE Machine Learning CS733PE -

Empirical Evaluation of the Effectiveness and Reliability of Software Testing Adequacy Criteria and Reference Test Systems
Empirical Evaluation of the Effectiveness and Reliability of Software Testing Adequacy Criteria and Reference Test Systems Mark Jason Hadley PhD University of York Department of Computer Science September 2013 2 Abstract This PhD Thesis reports the results of experiments conducted to investigate the effectiveness and reliability of ‘adequacy criteria’ - criteria used by testers to determine when to stop testing. The research reported here is concerned with the empirical determination of the effectiveness and reliability of both tests sets that satisfy major general structural code coverage criteria and test sets crafted by experts for testing specific applications. We use automated test data generation and subset extraction techniques to generate multiple tests sets satisfying widely used coverage criteria (statement, branch and MC/DC coverage). The results show that confidence in the reliability of such criteria is misplaced. We also consider the fault-finding capabilities of three test suites created by the international community to serve to assure implementations of the Data Encryption Standard (a block cipher). We do this by means of mutation analysis. The results show that not all sets are mutation adequate but the test suites are generally highly effective. The block cipher implementations are also seen to be highly ‘testable’ (i.e. they do not mask faults). 3 Contents Abstract ............................................................................................................................ 3 Table of Tables ............................................................................................................... -

ITSSD Assessment of the New ISO 26000 Social Responsibility Standard
ITSSD Assessment of the new ISO 26000 Social Responsibility Standard December 2005 Preliminary Conclusions: 1. It may be possible to procedurally shape and/or delay the development of the ISO SR guidance standard at the national mirror and international levels. 2. It may be impossible to prevent the actual adoption of an SR standard at the DIS and FDIS stages, unless the ISO voting rules are first modified to reflect only one vote for the European Community as a whole through its regional standards representative (e.g., CEN), as opposed to twenty-five separate votes representing the national standards bodies of each of the EU member states. 3. It is likely to be difficult to reverse the new stakeholder engagement process that has been introduced at the ISO incident to the commencement of this SR standard initiative, though it may arguably be shaped by filing procedural objections, and by strengthening traditional ISO benchmarks for consensus. 4. The real challenge is to prevent the new process from being expanded institutionally to all of ISO’s technical standards work, and thereby from being incorporated within business contracts that reference or directly incorporate such standards as conditions of manufacture, sale, service, etc. This is likely to be quite difficult given the current efforts of governments, NGOs and UN agencies to incorporate sustainable development dimensions into all ISO technical standards. 5. Further study and analysis of the evolving ISO SR operating procedures, the multi-stakeholder engagement process, and the ISO’s general consensus procedures is necessary to determine the proper course of action and the appropriate actors with which/whom to collaborate. -

Opinions of Small and Medium UK Construction Companies On
Opinions of small and medium UK construction companies on environmental management systems Bailey, M, Booth, CA, Horry, R, Vidalakis, C, Mahamadu, A-M and Gyau, KAB http://dx.doi.org/10.1680/jmapl.19.00033 Title Opinions of small and medium UK construction companies on environmental management systems Authors Bailey, M, Booth, CA, Horry, R, Vidalakis, C, Mahamadu, A-M and Gyau, KAB Type Article URL This version is available at: http://usir.salford.ac.uk/id/eprint/56909/ Published Date 2021 USIR is a digital collection of the research output of the University of Salford. Where copyright permits, full text material held in the repository is made freely available online and can be read, downloaded and copied for non-commercial private study or research purposes. Please check the manuscript for any further copyright restrictions. For more information, including our policy and submission procedure, please contact the Repository Team at: [email protected]. Accepted manuscript doi: 10.1680/jmapl.19.00033 Accepted manuscript As a service to our authors and readers, we are putting peer-reviewed accepted manuscripts (AM) online, in the Ahead of Print section of each journal web page, shortly after acceptance. Disclaimer The AM is yet to be copyedited and formatted in journal house style but can still be read and referenced by quoting its unique reference number, the digital object identifier (DOI). Once the AM has been typeset, an ‘uncorrected proof’ PDF will replace the ‘accepted manuscript’ PDF. These formatted articles may still be corrected by the authors. During the Production process, errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal relate to these versions also. -

ISO 14000 Assessing Its Impact on Corporate Effectiveness and Efficiency
ISO 14000 Assessing Its Impact on Corporate Effectiveness and Efficiency Steven A. Melnyk Roger Calantone Rob Handfield R.L. (Lal) Tummala Gyula Vastag Timothy Hinds Robert Sroufe Frank Montabon Michigan State University Sime Curkovic Western Michigan University Contents Tables, Exhibits, Charts, and Appendices .................................................................... 4 Acknowledgments.......................................................................................................... 5 Executive Summary....................................................................................................... 6 Implications of the Study .............................................................................................. 7 Design of the Study........................................................................................................ 8 Overview .................................................................................................................... 8 The Large-Scale Survey.............................................................................................. 8 The Sample ............................................................................................................ 9 The Case Studies........................................................................................................ 9 The Sample for the Case Studies Phase ............................................................... 9 The Interview Protocol Described....................................................................... -

SOFTWARE TESTING Aarti Singh
© November 2015 | IJIRT | Volume 2 Issue 6 | ISSN: 2349-6002 SOFTWARE TESTING Aarti Singh ABSTRACT:- Software testing is an investigation can be installed and run in its conducted to provide stakeholders with intended environments, and information about the quality of the product or achieves the general result its stakeholders service under test Software testing can also desire. provide an objective, independent view of Software testing can be conducted as soon as thesoftware to allow the business to appreciate executable software (even if partially complete) and understand the risks of software exists. The overall approach to software implementation.In this paper we will discuss development often determines when and how testing about testing levels suct as alpha testing , beta is conducted. For example, in a phased process, most testing, unit testing , integrity testing, testing testing occurs after system requirements have been cycle and their requirement n comparison defined and then implemented in testable programs. between varius testing such as static and dynamic HISTORY: testing. The separation of debugging from testing was initially introduced by Glenford J. Myers in INTRODUCTION: 1979.[] Although his attention was on breakage Software testing involves the execution of a testing ("a successful test is one that finds a bug) it software component or system component to illustrated the desire of the software engineering evaluate one or more properties of interest. In community to separate fundamental development general, these -

This Is Not a Complete Sample Paper
BCS Practitioner Certificate in Information Assurance Architecture Specimen Paper – This is not a complete sample paper. Attempt all 85 multiple-choice questions – 1 mark awarded to each question. Mark only one answer to each question. There are no trick questions. Section A – multiple-choice questions There are 60 questions for Section A, awarding 1 mark per question for a total of 60 points. Section B – Scenario based multi-choice questions There are 25 questions for Section B, over 5 scenarios, awarding 13 points per scenario, for a total of 65 points. Pass Mark: 81/125 65% This specimen paper has 30 questions in Section A with 30 points available for Section A and 3 scenarios with 15 questions in Section B with 39 points available. Therefore there are 69 points available for both sections. Specimen Paper Pass Mark: 45/69 65% Copying of this paper is expressly forbidden without the direct approval of BCS, The Chartered Institute for IT. Copyright © BCS 2014 Page 1 of 21 PCiAA Sample Paper A Version 1.0 August 2014 This page is intentionally blank. Section A Multiple-choice answers – 1 mark each NOTE: Choose only one answer per question 1 What is the correct ordering (Conceptual to Component) of the following artefacts for the SABSA Motivation (WHY) foci? a. Security Policies. b. Security Standards. c. Control Objectives. d. Security Rules, Practices and Procedures. A c, a, d and b. B a, c, b and d. C b, a, d and c. D c, b, a and d. 2 In the TOGAF Content MetaModel, under which viewpoint would you find the Business Principles, Objectives and Drivers? A Motivation. -

Lightweight Requirements Engineering Metrics Designing And
Universiteit Leiden ICT in Business and the Public Sector Lightweight Requirements Engineering Metrics Designing and evaluating requirements engineering metrics for software development in complex IT environments – Case study Name: Jenny Yung Student-no: s0952249 Date: 18/04/2019 1st supervisor: Werner Heijstek 2nd supervisor: Guus Ramackers Pagina 1 van 83 Abstract The software development industry is relatively young and has matured considerably in the past 15 years. With several major transformations, the industry continues to seek ways to improve their delivery. A while ago, the waterfall method was the standard option for software development projects. Today, agile methodology is used more frequently. New development engineering practices are developed like standardization, continuous integration or continuous delivery. However, the consensus of being predictable and repeatable is not yet there. Agile software development and delivery are still not sufficiently reliable, resulting in expensive and unpredictable projects. In this thesis, measurements in requirements engineering are introduced. This paper presents a maturity model to assess the requirements engineering in complex IT environments. Companies strive to improve their software production and delivery, and the study aims to find a lightweight requirements metric method. The method is compared with a library of abstract metric models. The case study is performed at three different companies, and experts evaluated the conceptual metric system. As a result, a Requirements Engineering Maturity scan (REMS) is created. The tool suggests appropriate generic requirements metrics to deal with the encountered project. The paper concludes a review with related work and a discussion of the prospects for REMS. Keywords: Requirements Engineering • Quality Measurements • Metrics • ISO/IEC 9126 • Agile Methodology • Requirements Engineering Maturity Scan • Complex IT Infrastructure • Pagina 2 van 83 Acknowledgement Anyone writing a thesis will tell you it is a lot of work, and they are right. -

Understanding ROI Metrics for Software Test Automation
University of South Florida Scholar Commons Graduate Theses and Dissertations Graduate School 2005 Understanding ROI Metrics for Software Test Automation Naveen Jayachandran University of South Florida Follow this and additional works at: https://scholarcommons.usf.edu/etd Part of the American Studies Commons Scholar Commons Citation Jayachandran, Naveen, "Understanding ROI Metrics for Software Test Automation" (2005). Graduate Theses and Dissertations. https://scholarcommons.usf.edu/etd/2938 This Thesis is brought to you for free and open access by the Graduate School at Scholar Commons. It has been accepted for inclusion in Graduate Theses and Dissertations by an authorized administrator of Scholar Commons. For more information, please contact [email protected]. Understanding ROI Metrics for Software Test Automation by Naveen Jayachandran A thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in Computer Science Department of Computer Science and Engineering College of Engineering University of South Florida Co-Major Professor: Dewey Rundus, Ph.D. Co-Major Professor: Alan Hevner, Ph.D. Member: Rafael Perez, Ph.D. Date of Approval: June 2, 2005 Keywords: Return on investment metrics, automated testing feasibility, manual vs. automated testing, software quality assurance, regression testing, repetitive testing © Copyright 2005, Naveen Jayachandran Dedication To my Parents, Suja, Rocky and Reemo. Acknowledgements I would like to thank my major professors Dr. Alan Hevner and Dr. Dewey Rundus for recognizing and encouraging my interest, giving me this opportunity and providing constant support for my research. I have gained immensely from this experience enabling me to truly appreciate the saying – ‘The journey is more important than the destination’.