Studies on the Accuracy of Numerical Operations with Embedded Cpus
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Thermal Interface Material Comparison: Thermal Pads Vs
Thermal Interface Material Comparison: Thermal Pads vs. Thermal Grease Publication # 26951 Revision: 3.00 Issue Date: April 2004 © 2004 Advanced Micro Devices, Inc. All rights reserved. The contents of this document are provided in connection with Advanced Micro Devices, Inc. (“AMD”) products. AMD makes no representations or warranties with respect to the accuracy or completeness of the contents of this publication and reserves the right to make changes to specifications and product descriptions at any time without notice. No license, whether express, implied, arising by estoppel, or otherwise, to any intellectual property rights are granted by this publication. Except as set forth in AMD’s Standard Terms and Conditions of Sale, AMD assumes no liability whatsoever, and disclaims any express or implied warranty, relating to its products including, but not limited to, the implied warranty of merchantability, fitness for a particular purpose, or infringement of any intellectual property right. AMD’s products are not designed, intended, authorized or warranted for use as components in systems intended for surgical implant into the body, or in other applications intended to support or sustain life, or in any other application in which the failure of AMD’s product could create a situation where personal injury, death, or severe property or environmental damage may occur. AMD reserves the right to discontinue or make changes to its products at any time without notice. Trademarks AMD, the AMD Arrow logo, AMD Athlon, AMD Duron, AMD Opteron and combinations thereof, are trademarks of Advanced Micro Devices, Inc. Other product names used in this publication are for identification purposes only and may be trademarks of their respective companies. -

2021 User Guide
i Pro Fortran Linux Absoft Pro Fortran User Guide Absoft Fortran Linux Fortran User Guide 5119 Highland Road, PMB 398 Waterford, MI 48327 U.S.A. Tel (248) 220-1190 Fax (248) 220-1194 [email protected] All rights reserved. No part of this publication may be reproduced or used in any form by any means, without the prior written permission of Absoft Corporation. THE INFORMATION CONTAINED IN THIS PUBLICATION IS BELIEVED TO BE ACCURATE AND RELIABLE. HOWEVER, ABSOFT CORPORATION MAKES NO REPRESENTATION OF WARRANTIES WITH RESPECT TO THE PROGRAM MATERIAL DESCRIBED HEREIN AND SPECIFICALLY DISCLAIMS ANY IMPLIED WARRANTIES OF MERCHANTABILITY OR FITNESS FOR ANY PARTICULAR PURPOSE. FURTHER, ABSOFT RESERVES THE RIGHT TO REVISE THE PROGRAM MATERIAL AND MAKE CHANGES THEREIN FROM TIME TO TIME WITHOUT OBLIGATION TO NOTIFY THE PURCHASER OF THE REVISION OR CHANGES. IN NO EVENT SHALL ABSOFT BE LIABLE FOR ANY INCIDENTAL, INDIRECT, SPECIAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE PURCHASER'S USE OF THE PROGRAM MATERIAL. U.S. GOVERNMENT RESTRICTED RIGHTS — The software and documentation are provided with RESTRICTED RIGHTS. Use, duplication, or disclosure by the Government is subject to restrictions set forth in subparagraph (c) (1) (ii) of the Rights in Technical Data and Computer Software clause at 252.227-7013. The contractor is Absoft Corporation, 2111 Cass Lake Rd. Ste 102, Keego Harbor, Michigan 48320. ABSOFT CORPORATION AND ITS LICENSOR(S) MAKE NO WARRANTIES, EXPRESS OR IMPLIED, INCLUDING WITHOUT LIMITATION THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE, REGARDING THE SOFTWARE. ABSOFT AND ITS LICENSOR(S) DO NOT WARRANT, GUARANTEE OR MAKE ANY REPRESENTATIONS REGARDING THE USE OR THE RESULTS OF THE USE OF THE SOFTWARE IN TERMS OF ITS CORRECTNESS, ACCURACY, RELIABILITY, CURRENTNESS, OR OTHERWISE. -

User's Manual User's Manual
User’s Manual (English Edition) Intel Pentium 4 Socket 478 CPU AMD Athlon/ Duron/Athlon XP Socket 462 CPU AMD Athlon 64 Socket 754 CPU ZM-WB2 Gold * Please read before installation http://www.zalman.co.kr http://www.zalmanusa.com 1. Features 1) Gold plated pure copper base maximizes cooling performance and prevents CPU blocks from galvanic corrosion 2) Intel Pentium 4 (Socket 478), AMD Athlon/Duron/Athlon XP (Socket 462),Athlon 64 (Socket 754) compatible design for broad compatibility. 3) Three types of compression fitting are offered for use with water tubes (8X10mm,8X11mm,10X13mm) * Zalman Tech. Co., Ltd. is not responsible for any damage resulting from CPU OVERCLOCKING. 2. Specifications Part No Part name Q’ ty Weight (g) Use 1 CPU block 1 447.0 CPU mountimg 2 Hand screw 2 8.0 Clip mountimg 3 Thermal grease 1 1.8 Apply to cpu core 4 Clip 1 9.6 CPU block mountimg 5 User’s manual 1 6 Clip supports 2 8.2 Socket 478 7 Clip supports A 2 5.0 Socket 462 8 Clip supports B 2 5.0 Socket 462 9 Bolts 4 0.8 Clip supports, A, B-type 10 Paper washer 1 set 7, 8 mountimg 11 Nipple 2 6.2 Socket 754 mountimg 12 Back plate 60.0 Socket 754 mountimg Fitting to 13 Fitting 3 set 8 x 10mm, 8 x 11mm, 10 x 13mm tubes NOTE 1) The maximum weight for the cooler is specified as 450g/450g/300g for socket 478/754/462 respectively. Special care should be taken when moving a computer equipped with a cooler which exceeds the relevant weight limit. -

System Management BIOS (SMBIOS) Reference 6 Specification
1 2 Document Number: DSP0134 3 Date: 2011-01-26 4 Version: 2.7.1 5 System Management BIOS (SMBIOS) Reference 6 Specification 7 Document Type: Specification 8 Document Status: DMTF Standard 9 Document Language: en-US 10 System Management BIOS (SMBIOS) Reference Specification DSP0134 11 Copyright Notice 12 Copyright © 2000, 2002, 2004–2011 Distributed Management Task Force, Inc. (DMTF). All rights 13 reserved. 14 DMTF is a not-for-profit association of industry members dedicated to promoting enterprise and systems 15 management and interoperability. Members and non-members may reproduce DMTF specifications and 16 documents, provided that correct attribution is given. As DMTF specifications may be revised from time to 17 time, the particular version and release date should always be noted. 18 Implementation of certain elements of this standard or proposed standard may be subject to third party 19 patent rights, including provisional patent rights (herein "patent rights"). DMTF makes no representations 20 to users of the standard as to the existence of such rights, and is not responsible to recognize, disclose, 21 or identify any or all such third party patent right, owners or claimants, nor for any incomplete or 22 inaccurate identification or disclosure of such rights, owners or claimants. DMTF shall have no liability to 23 any party, in any manner or circumstance, under any legal theory whatsoever, for failure to recognize, 24 disclose, or identify any such third party patent rights, or for such party’s reliance on the standard or 25 incorporation -

Exploded View Processor Compatibility
One or more Patents pending This product is intended for expert users. Please consult with a qualified technician for installation. Improper installation may result in damage to your components. Swiftech™ assumes no liability whatsoever, expressed or implied, for the use of these products, nor their installation. The following instructions are subject to change without notice. Please visit our web site at www.swiftnets.com for updates. Figure 1 – Exploded View Processor compatibility Intel® Pentium® 4, D, Celeron Socket 478 Socket 775 Xeon™ (socket 603 and 604) 400 & 533 Mhz FSB 800 Mhz FSB (Nocona) – Hardware sold separately AMD® Athlon XP, MP, Duron, Sempron, socket 462 Athlon 64, Sempron, Socket 754 Opteron, socket 939, 940 Athlon 64, FX, X2, socket AM2 Intel® Xeon “Nocona” 800 Mhz FSB hold-down hardware sold separately Part # AP-NOC Copyright Swiftech 2005 – All rights reserved – Last revision date: 6-12-06 – One or more Patents Pending Rouchon Industries, Inc., dba Swiftech – 1703 E. 28th Street, Signal Hill, CA 90755 – Tel. 562-595-8009 – Fax 562-595-8769 - E Mail: [email protected] – URL: http://www.swiftnets.com - Information subject to change without notice Packing List COMPONENT ID COMPONENT DESCRIPTION QTY USAGE BHSC006C0-007SS 6-32 X 7/16 BUT HD CAP SS 4.00 WATER-BLOCK ASSEMBLY O-RING 3/32 B1000-133 O-RING 3/32 X 1 13/1 1.00 WATER-BLOCK ASSEMBLY APOGEE-H APOGEE WATERBLOCK HOUSING 1.00 WATER-BLOCK ASSEMBLY APOGEE-BRKT APOGEE HOLD-DOWN PLATE 1.00 WATER-BLOCK ASSEMBLY APOGEE-BP APOGEE BASE PLATE 1.00 WATER-BLOCK ASSEMBLY B1000-2.5X50 BUNA-N 70D BLACK O-RING 2.00 FITTINGS PM4S-6BN 1/4" - 1/8 NPSM TO 3/8" ID 2.00 FITTINGS PM4S-8BN 1/4" - 1/8 NPSM TO 1/2 ID 2.00 FITTINGS 22HC04688 15/32" HOSE CLAMP 2.00 FITTINGS 22HC0672B 43/64" PREMIUM HOSE CLAMP 2.00 FITTINGS SPRING6 SPRING FOR MCW6000-775 4.00 COMMON HARDWARE 6-32 HEX CAP 6-32 ACRON NUT 4.00 COMMON HARDWARE 12SWS0444 NYLON SHOULDER WASHER 8.00 COMMON HARDWARE LOCKWASHER6 LOCK WASHER #6 6.00 COMMON HARDWARE FW140X250X0215FB BLK BLACK FIBER WASHER .140X.250X. -

AMD's Early Processor Lines, up to the Hammer Family (Families K8
AMD’s early processor lines, up to the Hammer Family (Families K8 - K10.5h) Dezső Sima October 2018 (Ver. 1.1) Sima Dezső, 2018 AMD’s early processor lines, up to the Hammer Family (Families K8 - K10.5h) • 1. Introduction to AMD’s processor families • 2. AMD’s 32-bit x86 families • 3. Migration of 32-bit ISAs and microarchitectures to 64-bit • 4. Overview of AMD’s K8 – K10.5 (Hammer-based) families • 5. The K8 (Hammer) family • 6. The K10 Barcelona family • 7. The K10.5 Shanghai family • 8. The K10.5 Istambul family • 9. The K10.5-based Magny-Course/Lisbon family • 10. References 1. Introduction to AMD’s processor families 1. Introduction to AMD’s processor families (1) 1. Introduction to AMD’s processor families AMD’s early x86 processor history [1] AMD’s own processors Second sourced processors 1. Introduction to AMD’s processor families (2) Evolution of AMD’s early processors [2] 1. Introduction to AMD’s processor families (3) Historical remarks 1) Beyond x86 processors AMD also designed and marketed two embedded processor families; • the 2900 family of bipolar, 4-bit slice microprocessors (1975-?) used in a number of processors, such as particular DEC 11 family models, and • the 29000 family (29K family) of CMOS, 32-bit embedded microcontrollers (1987-95). In late 1995 AMD cancelled their 29K family development and transferred the related design team to the firm’s K5 effort, in order to focus on x86 processors [3]. 2) Initially, AMD designed the Am386/486 processors that were clones of Intel’s processors. -

SMBIOS Specification
1 2 Document Identifier: DSP0134 3 Date: 2019-10-31 4 Version: 3.4.0a 5 System Management BIOS (SMBIOS) Reference 6 Specification Information for Work-in-Progress version: IMPORTANT: This document is not a standard. It does not necessarily reflect the views of the DMTF or its members. Because this document is a Work in Progress, this document may still change, perhaps profoundly and without notice. This document is available for public review and comment until superseded. Provide any comments through the DMTF Feedback Portal: http://www.dmtf.org/standards/feedback 7 Supersedes: 3.3.0 8 Document Class: Normative 9 Document Status: Work in Progress 10 Document Language: en-US 11 System Management BIOS (SMBIOS) Reference Specification DSP0134 12 Copyright Notice 13 Copyright © 2000, 2002, 2004–2019 DMTF. All rights reserved. 14 DMTF is a not-for-profit association of industry members dedicated to promoting enterprise and systems 15 management and interoperability. Members and non-members may reproduce DMTF specifications and 16 documents, provided that correct attribution is given. As DMTF specifications may be revised from time to 17 time, the particular version and release date should always be noted. 18 Implementation of certain elements of this standard or proposed standard may be subject to third party 19 patent rights, including provisional patent rights (herein "patent rights"). DMTF makes no representations 20 to users of the standard as to the existence of such rights, and is not responsible to recognize, disclose, 21 or identify any or all such third party patent right, owners or claimants, nor for any incomplete or 22 inaccurate identification or disclosure of such rights, owners or claimants. -

Lista Sockets.Xlsx
Data de Processadores Socket Número de pinos lançamento compatíveis Socket 0 168 1989 486 DX 486 DX 486 DX2 Socket 1 169 ND 486 SX 486 SX2 486 DX 486 DX2 486 SX Socket 2 238 ND 486 SX2 Pentium Overdrive 486 DX 486 DX2 486 DX4 486 SX Socket 3 237 ND 486 SX2 Pentium Overdrive 5x86 Socket 4 273 março de 1993 Pentium-60 e Pentium-66 Pentium-75 até o Pentium- Socket 5 320 março de 1994 120 486 DX 486 DX2 486 DX4 Socket 6 235 nunca lançado 486 SX 486 SX2 Pentium Overdrive 5x86 Socket 463 463 1994 Nx586 Pentium-75 até o Pentium- 200 Pentium MMX K5 Socket 7 321 junho de 1995 K6 6x86 6x86MX MII Slot 1 Pentium II SC242 Pentium III (Cartucho) 242 maio de 1997 Celeron SEPP (Cartucho) K6-2 Socket Super 7 321 maio de 1998 K6-III Celeron (Socket 370) Pentium III FC-PGA Socket 370 370 agosto de 1998 Cyrix III C3 Slot A 242 junho de 1999 Athlon (Cartucho) Socket 462 Athlon (Socket 462) Socket A Athlon XP 453 junho de 2000 Athlon MP Duron Sempron (Socket 462) Socket 423 423 novembro de 2000 Pentium 4 (Socket 423) PGA423 Socket 478 Pentium 4 (Socket 478) mPGA478B Celeron (Socket 478) 478 agosto de 2001 Celeron D (Socket 478) Pentium 4 Extreme Edition (Socket 478) Athlon 64 (Socket 754) Socket 754 754 setembro de 2003 Sempron (Socket 754) Socket 940 940 setembro de 2003 Athlon 64 FX (Socket 940) Athlon 64 (Socket 939) Athlon 64 FX (Socket 939) Socket 939 939 junho de 2004 Athlon 64 X2 (Socket 939) Sempron (Socket 939) LGA775 Pentium 4 (LGA775) Pentium 4 Extreme Edition Socket T (LGA775) Pentium D Pentium Extreme Edition Celeron D (LGA 775) 775 agosto de -

Fact Sheet Overview the Microsoft® Windows® XP Operating System
Fact Sheet Overview The Microsoft® Windows® XP operating system remains at the center of the ongoing evolution of the personal computer, enabling users to experience the power of the PC in new ways. In spite of these advances, millions of individuals still have not experienced even the most basic benefits of the personal computer or accessed the world of social and economic benefits that computer technology can make possible. In an effort to provide an affordable and simple introduction to personal computing, and as a result of ongoing collaborations with governments on PC access programs and increasing digital inclusion, Microsoft Corp. has developed a pilot offering, called Windows XP Starter Edition, designed for first-time desktop PC users in developing technology markets. Microsoft Windows XP Starter Edition is designed to offer an affordable and easy-to-use entry point to the Windows family of products that is tailored to local markets, in local languages, and is compatible with a wide range of Windows-based applications and devices. Windows XP Starter Edition local language versions will be available initially in Thailand, Malaysia, Indonesia, Russia and India. In line with Microsoft's other initiatives to enable digital skills training and access to technology, including the Local Language Program, Partners in Learning, and Unlimited Potential, the Microsoft Windows XP Starter Edition Pilot Program supports the company's long-term vision for the global marketplace, empowering even more people to achieve their fullest potential. Windows XP Starter Edition Features Windows XP Starter Edition balances the needs of first-time PC users in developing technology markets by delivering proven Microsoft technology at a more affordable price. -

Intel MMX.Pdf
Intel vs AMD By Carrie Pipkin: Introduction and History Ramiro Bolanos : Intel and VIA chipsets Dan Hepp: VIA and AMD chipsets, Conclusion 11 Part 1: Comparative History Generally Intel has been the dominant producer of microprocessor chips AMD has proven to be a fierce competitor Competition stimulated the industry by producing new and innovative microprocessors In the mid nineties Intel begins to face true competition 22 Comparative History ƛƛ8028680286 chip 1980ƞs1980ƞs--IntelIntel was the only true producer of marketable computer chips 19821982--introduceintroduce 80286 286 was able to run software of its prior microprocessor 33 Comparative History ƛƛ8028680286 chip Within 6 years, 15 million 286ƞs are installed around the world Intel contracts third party companies to produce 286ƞs and variants AMD was one of these third party companies AMD became very efficient and capable of being its own producer of microprocessors 44 Comparative History ƛƛ386386 chip 1985, Intel releases its 3232--bitbit 386 microprocessor. Faster and capable of multitasking AMD, under licensed production, produces 386 chips allowing Intel to meet market demands 55 Comparative History ƛƛ386386 chip During the reign of the 386, AMD decides to produce its own CPU. 19871987--AMDAMD began legal arbitration over rights to produce their own chips. After 5 years of battle, the courts sided with AMD. 66 Comparative History --486486 chip 19891989--IntelIntel releases its 486DX. Allowed point and clicking Initially twice as fast as its predecessor. -

Measuring Consumer Welfare in the CPU Market
Measuring Consumer Welfare in the CPU Market. Minjae Song∗ Department of Economics, Harvard University [email protected] October, 2002 Abstract The personal computer Central Processing Unit (CPU) has undergone a dramatic improve- ment in quality, accompanied by an equally remarkable drop in prices in the 1990s. How have these developments in the CPU market affected consumer welfare? This paper estimates de- mand for CPUs and measures consumer welfare. The model is based on a quasilinear utility function with one random variable. The model does not have the idiosyncratic logit error term, so that consumer welfare directly reflects consumers’ valuation of product characteristics. Wel- fare calculations show that consumer surplus makes up approximately 90% of the total social surplus and that a large part of the welfare gains comes from the introduction of new products. Similar results are found when the model is extended to include two random coefficients without the idiosyncratic logit error term - the pure characteristics demand model. Simulation results show how “quality competition" among firms can generate a large gap between the reservation and actual prices. ∗I especially thank Ariel Pakes, Gary Chamberlain, and Dale Jorgenson for their valuable advice and support. I also thank John Asker, Steve Berry, Liran Einav, Gautam Gowrisankaran, Matthew Gentzkow, Jason Hwang, Markus Mobius, Julie Mortimer, Amil Petrin and seminar participants at Harvard University for their helpful comments. I am grateful to Steve Berry and Ariel Pakes for sharing their search algorithm used to do a robustness test on the model specification. All errors are mine. 1 1Introduction The past decade has seen a dramatic improvement in performance of the personal computer Cen- tral Processing Unit (CPU).1 Rapid advances in manufacturing technology have allowed a new generation of products to emerge every two to three years. -
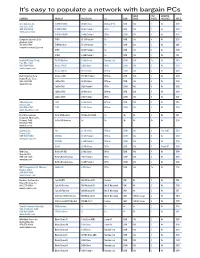
It's Easy to Populate a Network with Bargain
It’s easy to populate a network with bargain PCs HARD USB MONITOR COMPANY PRODUCT PROCESSOR 0S RAM DRIVE PORTS INCLUDED PRICE Acer America Inc. Sd APSD-U-C1800 1.8-GHz Celeron Windows XP Pro 128M 20G 4 No $539 San Jose, Calif. 408-432-6200 Sd APSD-U-N1801 1.8-GHz Pentium 4 XP Pro 128M 40G 4 No $620 www.acer.com/us SP APSP-U-N2400 2.4-GHz Pentium 4 XP Pro 256M 40G 4 No $573 Computer Systems 2 Go Z4 H15 1.5-GHz Pentium 4 No 128M 10G 4 No $376 Anaheim, Calif. 714-282-0799 Z4 H00 Barebone 1.5-GHz Pentium 4 No 128M 40G 4 No $406 computersystems2go.com Z4 H18 1.8-GHz Pentium 4 No 128M 10G 4 No $398 Z4 H24 2.4-GHz Pentium 4 No 128M 10G 4 No $431 Hewlett-Packard Corp. EVO 310 Mini Tower 2.8-GHz Celeron Mandrake Linux 256M 80G Yes No $704 Palo Alto, Calif. 800-888-0262 Presario S3000V 2-GHz Celeron XP Pro 256M 40G 2 No $378 www.compaq.com Presario S3000nx 1.67-GHz Athlon XP Home 256M 40G 6 No $449 Dell Computer Corp. Dimension 4550 2.53-GHz Pentium 4 XP Home 128M 60G 6 No $699 Round Rock, Texas 800-953-1401 OptiPlex GX60 1.8-GHz Celeron XP Home 128M 20G 6 No $399 www.dell.com OptiPlex GX60 2-GHz Pentium 4 XP Pro 256M 40G 6 No $926 OptiPlex GX260 1.8-GHz Celeron XP Home 128M 20G 6 No $449 OptiPlex SX260 2-GHz Pentium 4 XP Pro 256M 40G 6 No $549 eMachines Inc.