Vignette for Fletcher2013b: Master Regulators of FGFR2 Signalling and Breast Cancer Risk
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Analysis of Trans Esnps Infers Regulatory Network Architecture
Analysis of trans eSNPs infers regulatory network architecture Anat Kreimer Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Graduate School of Arts and Sciences COLUMBIA UNIVERSITY 2014 © 2014 Anat Kreimer All rights reserved ABSTRACT Analysis of trans eSNPs infers regulatory network architecture Anat Kreimer eSNPs are genetic variants associated with transcript expression levels. The characteristics of such variants highlight their importance and present a unique opportunity for studying gene regulation. eSNPs affect most genes and their cell type specificity can shed light on different processes that are activated in each cell. They can identify functional variants by connecting SNPs that are implicated in disease to a molecular mechanism. Examining eSNPs that are associated with distal genes can provide insights regarding the inference of regulatory networks but also presents challenges due to the high statistical burden of multiple testing. Such association studies allow: simultaneous investigation of many gene expression phenotypes without assuming any prior knowledge and identification of unknown regulators of gene expression while uncovering directionality. This thesis will focus on such distal eSNPs to map regulatory interactions between different loci and expose the architecture of the regulatory network defined by such interactions. We develop novel computational approaches and apply them to genetics-genomics data in human. We go beyond pairwise interactions to define network motifs, including regulatory modules and bi-fan structures, showing them to be prevalent in real data and exposing distinct attributes of such arrangements. We project eSNP associations onto a protein-protein interaction network to expose topological properties of eSNPs and their targets and highlight different modes of distal regulation. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Supplemental Materials ZNF281 Enhances Cardiac Reprogramming
Supplemental Materials ZNF281 enhances cardiac reprogramming by modulating cardiac and inflammatory gene expression Huanyu Zhou, Maria Gabriela Morales, Hisayuki Hashimoto, Matthew E. Dickson, Kunhua Song, Wenduo Ye, Min S. Kim, Hanspeter Niederstrasser, Zhaoning Wang, Beibei Chen, Bruce A. Posner, Rhonda Bassel-Duby and Eric N. Olson Supplemental Table 1; related to Figure 1. Supplemental Table 2; related to Figure 1. Supplemental Table 3; related to the “quantitative mRNA measurement” in Materials and Methods section. Supplemental Table 4; related to the “ChIP-seq, gene ontology and pathway analysis” and “RNA-seq” and gene ontology analysis” in Materials and Methods section. Supplemental Figure S1; related to Figure 1. Supplemental Figure S2; related to Figure 2. Supplemental Figure S3; related to Figure 3. Supplemental Figure S4; related to Figure 4. Supplemental Figure S5; related to Figure 6. Supplemental Table S1. Genes included in human retroviral ORF cDNA library. Gene Gene Gene Gene Gene Gene Gene Gene Symbol Symbol Symbol Symbol Symbol Symbol Symbol Symbol AATF BMP8A CEBPE CTNNB1 ESR2 GDF3 HOXA5 IL17D ADIPOQ BRPF1 CEBPG CUX1 ESRRA GDF6 HOXA6 IL17F ADNP BRPF3 CERS1 CX3CL1 ETS1 GIN1 HOXA7 IL18 AEBP1 BUD31 CERS2 CXCL10 ETS2 GLIS3 HOXB1 IL19 AFF4 C17ORF77 CERS4 CXCL11 ETV3 GMEB1 HOXB13 IL1A AHR C1QTNF4 CFL2 CXCL12 ETV7 GPBP1 HOXB5 IL1B AIMP1 C21ORF66 CHIA CXCL13 FAM3B GPER HOXB6 IL1F3 ALS2CR8 CBFA2T2 CIR1 CXCL14 FAM3D GPI HOXB7 IL1F5 ALX1 CBFA2T3 CITED1 CXCL16 FASLG GREM1 HOXB9 IL1F6 ARGFX CBFB CITED2 CXCL3 FBLN1 GREM2 HOXC4 IL1F7 -

Datasheet A11267-1 Anti-ZNF318 Antibody
Product datasheet Anti-ZNF318 Antibody Catalog Number: A11267-1 BOSTER BIOLOGICAL TECHNOLOGY Special NO.1, International Enterprise Center, 2nd Guanshan Road, Wuhan, China Web: www.boster.com.cn Phone: +86 27 67845390 Fax: +86 27 67845390 Email: [email protected] Basic Information Product Name Anti-ZNF318 Antibody Gene Name ZNF318 Source Rabbit IgG Species Reactivity human, rat Tested Application WB, FCM, Direct ELISA Contents 500 ug/ml antibody with PBS ,0.02% NaN3 , 1 mg BSA and 50% glycerol. Immunogen E.coli-derived human ZNF318 recombinant protein (Position: E680-Q1197). Purification Immunogen affinity purified. Observed MW 290KD Dilution Ratios Western blot: 1:500-2000 Flow cytometry (FCM): 1-3μg/1x106 cells Direct ELISA: 1:100-1000 Storage 12 months from date of receipt,-20℃ as supplied.6 months 2 to 8℃ after reconstitution. Avoid repeated freezing and thawing Background Information Zinc finger protein 318 is a protein that in humans is encoded by the ZNF318 gene. ZNF318 encodes a nuclear protein with a zinc finger motif of the Cys2-His2 type that is a novel corepressor of androgen receptor (AR). Reference Anti-ZNF318 Antibody被引用在0文献中。 暂无引用 FOR RESEARCH USE ONLY. NOT FOR DIAGNOSTIC AND CLINICAL USE. 1 Product datasheet Anti-ZNF318 Antibody Catalog Number: A11267-1 BOSTER BIOLOGICAL TECHNOLOGY Special NO.1, International Enterprise Center, 2nd Guanshan Road, Wuhan, China Web: www.boster.com.cn Phone: +86 27 67845390 Fax: +86 27 67845390 Email: [email protected] Selected Validation Data Figure 1. Western blot Figure 2. Flow cytometry analysis of anti- ZNF318 analysis of A431 cell Antibody (A11267-1). -

The Relevance of Clinical, Genetic and Serological Markers
AUTREV-01901; No of Pages 18 Autoimmunity Reviews xxx (2016) xxx–xxx Contents lists available at ScienceDirect Autoimmunity Reviews journal homepage: www.elsevier.com/locate/autrev Review Cardiovascular risk assessment in patients with rheumatoid arthritis: The relevance of clinical, genetic and serological markers Raquel López-Mejías a, Santos Castañeda b, Carlos González-Juanatey c,AlfonsoCorralesa, Iván Ferraz-Amaro d, Fernanda Genre a, Sara Remuzgo-Martínez a, Luis Rodriguez-Rodriguez e, Ricardo Blanco a,JavierLlorcaf, Javier Martín g, Miguel A. González-Gay a,h,i,⁎ a Epidemiology, Genetics and Atherosclerosis Research Group on Systemic Inflammatory Diseases, Rheumatology Division, IDIVAL, Santander, Spain b Division of Rheumatology, Hospital Universitario la Princesa, IIS-IPrincesa, Madrid, Spain c Division of Cardiology, Hospital Lucus Augusti, Lugo, Spain d Rheumatology Division, Hospital Universitario de Canarias, Santa Cruz de Tenerife, Spain e Division of Rheumatology, Hospital Clínico San Carlos, Madrid, Spain f Division of Epidemiology and Computational Biology, School of Medicine, University of Cantabria, and CIBER Epidemiología y Salud Pública (CIBERESP), IDIVAL, Santander, Spain g Institute of Parasitology and Biomedicine López-Neyra, IPBLN-CSIC, Granada, Spain h School of Medicine, University of Cantabria, Santander, Spain i Cardiovascular Pathophysiology and Genomics Research Unit, School of Physiology, Faculty of Health Sciences, University of the Witwatersrand, Johannesburg, South Africa article info abstract Article history: Cardiovascular disease (CV) is the most common cause of premature mortality in patients with rheumatoid ar- Received 7 July 2016 thritis (RA). This is the result of an accelerated atherosclerotic process. Adequate CV risk stratification has special Accepted 9 July 2016 relevance in RA to identify patients at risk of CV disease. -

Transcription of Platelet-Derived Growth Factor Receptor a in Leydig Cells Involves Specificity Protein 1 and 3
125 Transcription of platelet-derived growth factor receptor a in Leydig cells involves specificity protein 1 and 3 Francis Bergeron1, Edward T Bagu1 and Jacques J Tremblay1,2 1Reproduction, Perinatal and Child Health, CHUQ Research Centre, CHUL Room T1-49, 2705 Laurier Boulevard, Que´bec, Que´bec, Canada G1V 4G2 2Department of Obstetrics and Gynecology, Faculty of Medicine, Centre for Research in Biology of Reproduction, Universite´ Laval, Que´bec, Que´bec, Canada G1V 0A6 (Correspondence should be addressed to J J Tremblay; Email: [email protected]) Abstract Platelet-derived growth factor (PDGF) A is secreted by Sertoli cells and acts on Leydig precursor cells, which express the receptor PDGFRA, triggering their differentiation into steroidogenically active Leydig cells. There is, however, no information regarding the molecular mechanisms that govern Pdgfra expression in Leydig cells. In this study, we isolated and characterized a 2.2 kb fragment of the rat Pdgfra 50-flanking sequence in the TM3 Leydig cell line, which endogenously expresses Pdgfra. A series of 50 progressive deletions of the Pdgfra promoter was generated and transfected in TM3 cells. Using this approach, two regions (K183/K154 and K154/K105), each conferring 46% of Pdgfra promoter activity, were identified. To better define the regulatory elements, trinucleotide mutations spanning the K154/K105 region were introduced by site-directed mutagenesis in the context of the K2.2kb Pdgfra promoter. Mutations that altered the TCCGAGGGAAAC sequence at K138 bp significantly decreased Pdgfra promoter activity in TM3 cells. Several proteins from TM3 nuclear extracts were found to bind to this G(C/A) motif in electromobility shift assay. -

1,25 Dihydroxyvitamin D-Mediated Orchestration of Anticancer
Kovalenko et al. BMC Genomics 2010, 11:26 http://www.biomedcentral.com/1471-2164/11/26 RESEARCH ARTICLE Open Access 1,25 dihydroxyvitamin D-mediated orchestration of anticancer, transcript-level effects in the immortalized, non-transformed prostate epithelial cell line, RWPE1 Pavlo L Kovalenko1, Zhentao Zhang1, Min Cui1, Steve K Clinton2, James C Fleet1* Abstract Background: Prostate cancer is the second leading cause of cancer mortality among US men. Epidemiological evidence suggests that high vitamin D status protects men from prostate cancer and the active form of vitamin D, 1a,25 dihydroxyvitamin D3 (1,25(OH)2D) has anti-cancer effects in cultured prostate cells. Still, the molecular mechanisms and the gene targets for vitamin D-mediated prostate cancer prevention are unknown. Results: We examined the effect of 1,25(OH)2D (+/- 100 nM, 6, 24, 48 h) on the transcript profile of proliferating RWPE1 cells, an immortalized, non-tumorigenic prostate epithelial cell line that is growth arrested by 1,25(OH)2D (Affymetrix U133 Plus 2.0, n = 4/treatment per time and dose). Our analysis revealed many transcript level changes at a 5% false detection rate: 6 h, 1571 (61% up), 24 h, 1816 (60% up), 48 h, 3566 (38% up). 288 transcripts were regulated similarly at all time points (182 up, 80 down) and many of the promoters for these transcripts contained putative vitamin D response elements. Functional analysis by pathway or Gene Set Analysis revealed early suppression of WNT, Notch, NF-kB, and IGF1 signaling. Transcripts related to inflammation were suppressed at 6 h (e.g. -

Association of Gene Ontology Categories with Decay Rate for Hepg2 Experiments These Tables Show Details for All Gene Ontology Categories
Supplementary Table 1: Association of Gene Ontology Categories with Decay Rate for HepG2 Experiments These tables show details for all Gene Ontology categories. Inferences for manual classification scheme shown at the bottom. Those categories used in Figure 1A are highlighted in bold. Standard Deviations are shown in parentheses. P-values less than 1E-20 are indicated with a "0". Rate r (hour^-1) Half-life < 2hr. Decay % GO Number Category Name Probe Sets Group Non-Group Distribution p-value In-Group Non-Group Representation p-value GO:0006350 transcription 1523 0.221 (0.009) 0.127 (0.002) FASTER 0 13.1 (0.4) 4.5 (0.1) OVER 0 GO:0006351 transcription, DNA-dependent 1498 0.220 (0.009) 0.127 (0.002) FASTER 0 13.0 (0.4) 4.5 (0.1) OVER 0 GO:0006355 regulation of transcription, DNA-dependent 1163 0.230 (0.011) 0.128 (0.002) FASTER 5.00E-21 14.2 (0.5) 4.6 (0.1) OVER 0 GO:0006366 transcription from Pol II promoter 845 0.225 (0.012) 0.130 (0.002) FASTER 1.88E-14 13.0 (0.5) 4.8 (0.1) OVER 0 GO:0006139 nucleobase, nucleoside, nucleotide and nucleic acid metabolism3004 0.173 (0.006) 0.127 (0.002) FASTER 1.28E-12 8.4 (0.2) 4.5 (0.1) OVER 0 GO:0006357 regulation of transcription from Pol II promoter 487 0.231 (0.016) 0.132 (0.002) FASTER 6.05E-10 13.5 (0.6) 4.9 (0.1) OVER 0 GO:0008283 cell proliferation 625 0.189 (0.014) 0.132 (0.002) FASTER 1.95E-05 10.1 (0.6) 5.0 (0.1) OVER 1.50E-20 GO:0006513 monoubiquitination 36 0.305 (0.049) 0.134 (0.002) FASTER 2.69E-04 25.4 (4.4) 5.1 (0.1) OVER 2.04E-06 GO:0007050 cell cycle arrest 57 0.311 (0.054) 0.133 (0.002) -

Supp Material.Pdf
Simon et al. Supplementary information: Table of contents p.1 Supplementary material and methods p.2-4 • PoIy(I)-poly(C) Treatment • Flow Cytometry and Immunohistochemistry • Western Blotting • Quantitative RT-PCR • Fluorescence In Situ Hybridization • RNA-Seq • Exome capture • Sequencing Supplementary Figures and Tables Suppl. items Description pages Figure 1 Inactivation of Ezh2 affects normal thymocyte development 5 Figure 2 Ezh2 mouse leukemias express cell surface T cell receptor 6 Figure 3 Expression of EZH2 and Hox genes in T-ALL 7 Figure 4 Additional mutation et deletion of chromatin modifiers in T-ALL 8 Figure 5 PRC2 expression and activity in human lymphoproliferative disease 9 Figure 6 PRC2 regulatory network (String analysis) 10 Table 1 Primers and probes for detection of PRC2 genes 11 Table 2 Patient and T-ALL characteristics 12 Table 3 Statistics of RNA and DNA sequencing 13 Table 4 Mutations found in human T-ALLs (see Fig. 3D and Suppl. Fig. 4) 14 Table 5 SNP populations in analyzed human T-ALL samples 15 Table 6 List of altered genes in T-ALL for DAVID analysis 20 Table 7 List of David functional clusters 31 Table 8 List of acquired SNP tested in normal non leukemic DNA 32 1 Simon et al. Supplementary Material and Methods PoIy(I)-poly(C) Treatment. pIpC (GE Healthcare Lifesciences) was dissolved in endotoxin-free D-PBS (Gibco) at a concentration of 2 mg/ml. Mice received four consecutive injections of 150 μg pIpC every other day. The day of the last pIpC injection was designated as day 0 of experiment. -
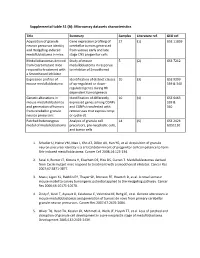
Supplemental Table S1 (A): Microarray Datasets Characteristics
Supplemental table S1 (A): Microarray datasets characteristics Title Summary Samples Literature ref. GEO ref. Acquisition of granule Gene expression profiling of 27 (1) GSE 11859 neuron precursor identity cerebellar tumors generated and Hedgehog‐induced from various early and late medulloblastoma in mice. stage CNS progenitor cells Medulloblastomas derived Study of mouse 5 (2) GSE 7212 from Cxcr6 mutant mice medulloblastoma in response respond to treatment with to inhibitor of Smoothened a Smoothened inhibitor Expression profiles of Identification of distinct classes 10 (3) GSE 9299 mouse medulloblastoma of up‐regulated or down‐ 339 & 340 regulated genes during Hh dependent tumorigenesis Genetic alterations in Identification of differently 10 (4) GSE 6463 mouse medulloblastomas expressed genes among CGNPs 339 & and generation of tumors and CGNPs transfected with 340 from cerebellar granule retroviruses that express nmyc neuron precursors or cyclin‐d1 Patched heterozygous Analysis of granule cell 14 (5) GSE 2426 model of medulloblastoma precursors, pre‐neoplastic cells, GDS1110 and tumor cells 1. Schuller U, Heine VM, Mao J, Kho AT, Dillon AK, Han YG, et al. Acquisition of granule neuron precursor identity is a critical determinant of progenitor cell competence to form Shh‐induced medulloblastoma. Cancer Cell 2008;14:123‐134. 2. Sasai K, Romer JT, Kimura H, Eberhart DE, Rice DS, Curran T. Medulloblastomas derived from Cxcr6 mutant mice respond to treatment with a smoothened inhibitor. Cancer Res 2007;67:3871‐3877. 3. Mao J, Ligon KL, Rakhlin EY, Thayer SP, Bronson RT, Rowitch D, et al. A novel somatic mouse model to survey tumorigenic potential applied to the Hedgehog pathway. Cancer Res 2006;66:10171‐10178. -

Supplementary Table S4. FGA Co-Expressed Gene List in LUAD
Supplementary Table S4. FGA co-expressed gene list in LUAD tumors Symbol R Locus Description FGG 0.919 4q28 fibrinogen gamma chain FGL1 0.635 8p22 fibrinogen-like 1 SLC7A2 0.536 8p22 solute carrier family 7 (cationic amino acid transporter, y+ system), member 2 DUSP4 0.521 8p12-p11 dual specificity phosphatase 4 HAL 0.51 12q22-q24.1histidine ammonia-lyase PDE4D 0.499 5q12 phosphodiesterase 4D, cAMP-specific FURIN 0.497 15q26.1 furin (paired basic amino acid cleaving enzyme) CPS1 0.49 2q35 carbamoyl-phosphate synthase 1, mitochondrial TESC 0.478 12q24.22 tescalcin INHA 0.465 2q35 inhibin, alpha S100P 0.461 4p16 S100 calcium binding protein P VPS37A 0.447 8p22 vacuolar protein sorting 37 homolog A (S. cerevisiae) SLC16A14 0.447 2q36.3 solute carrier family 16, member 14 PPARGC1A 0.443 4p15.1 peroxisome proliferator-activated receptor gamma, coactivator 1 alpha SIK1 0.435 21q22.3 salt-inducible kinase 1 IRS2 0.434 13q34 insulin receptor substrate 2 RND1 0.433 12q12 Rho family GTPase 1 HGD 0.433 3q13.33 homogentisate 1,2-dioxygenase PTP4A1 0.432 6q12 protein tyrosine phosphatase type IVA, member 1 C8orf4 0.428 8p11.2 chromosome 8 open reading frame 4 DDC 0.427 7p12.2 dopa decarboxylase (aromatic L-amino acid decarboxylase) TACC2 0.427 10q26 transforming, acidic coiled-coil containing protein 2 MUC13 0.422 3q21.2 mucin 13, cell surface associated C5 0.412 9q33-q34 complement component 5 NR4A2 0.412 2q22-q23 nuclear receptor subfamily 4, group A, member 2 EYS 0.411 6q12 eyes shut homolog (Drosophila) GPX2 0.406 14q24.1 glutathione peroxidase -

An Integrative Systems Biology Approach Identifies Molecular
Journal of Clinical Medicine Article An Integrative Systems Biology Approach Identifies Molecular Signatures Associated with Gallbladder Cancer Pathogenesis Nabanita Roy 1 , Mrinmoy Kshattry 1, Susmita Mandal 2, Mohit Kumar Jolly 2 , Dhruba Kumar Bhattacharyya 3 and Pankaj Barah 1,* 1 Department of Molecular Biology and Biotechnology, Tezpur University, Sonitpur 784028, India; [email protected] (N.R.); [email protected] (M.K.) 2 Centre for BioSystems Science and Engineering, Indian Institute of Science, Bangalore 560012, India; [email protected] (S.M.); [email protected] (M.K.J.) 3 Department of Computer Science and Engineering, Tezpur University, Sonitpur 784028, India; [email protected] * Correspondence: [email protected]; Tel.: +91-3712-27-5415 Abstract: Gallbladder cancer (GBC) has a lower incidence rate among the population relative to other cancer types but is a major contributor to the total number of biliary tract system cancer cases. GBC is distinguished from other malignancies by its high mortality, marked geographical variation and poor prognosis. To date no systemic targeted therapy is available for GBC. The main objective of this study is to determine the molecular signatures correlated with GBC development using integrative systems level approaches. We performed analysis of publicly available transcriptomic data to identify differentially regulated genes and pathways. Differential co-expression network analysis and transcriptional regulatory network analysis was performed to identify hub genes and Citation: Roy, N.; Kshattry, M.; hub transcription factors (TFs) associated with GBC pathogenesis and progression. Subsequently, we Mandal, S.; Jolly, M.K.; Bhattacharyya, assessed the epithelial-mesenchymal transition (EMT) status of the hub genes using a combination D.K.; Barah, P.