Pubh 7405: BIOSTATISTICS: REGRESSION
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
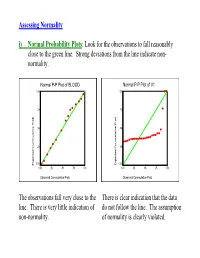
Assessing Normality I) Normal Probability Plots : Look for The
Assessing Normality i) Normal Probability Plots: Look for the observations to fall reasonably close to the green line. Strong deviations from the line indicate non- normality. Normal P-P Plot of BLOOD Normal P-P Plot of V1 1.00 1.00 .75 .75 .50 .50 .25 .25 0.00 0.00 Expected Cummulative Prob Expected Cummulative Expected Cummulative Prob Expected Cummulative 0.00 .25 .50 .75 1.00 0.00 .25 .50 .75 1.00 Observed Cummulative Prob Observed Cummulative Prob The observations fall very close to the There is clear indication that the data line. There is very little indication of do not follow the line. The assumption non-normality. of normality is clearly violated. ii) Histogram: Look for a “bell-shape”. Severe skewness and/or outliers are indications of non-normality. 5 16 14 4 12 10 3 8 2 6 4 1 Std. Dev = 60.29 Std. Dev = 992.11 2 Mean = 274.3 Mean = 573.1 0 N = 20.00 0 N = 25.00 150.0 200.0 250.0 300.0 350.0 0.0 1000.0 2000.0 3000.0 4000.0 175.0 225.0 275.0 325.0 375.0 500.0 1500.0 2500.0 3500.0 4500.0 BLOOD V1 Although the histogram is not perfectly There is a clear indication that the data symmetric and bell-shaped, there is no are right-skewed with some strong clear violation of normality. outliers. The assumption of normality is clearly violated. Caution: Histograms are not useful for small sample sizes as it is difficult to get a clear picture of the distribution. -

Applied Biostatistics Mean and Standard Deviation the Mean the Median Is Not the Only Measure of Central Value for a Distribution
Health Sciences M.Sc. Programme Applied Biostatistics Mean and Standard Deviation The mean The median is not the only measure of central value for a distribution. Another is the arithmetic mean or average, usually referred to simply as the mean. This is found by taking the sum of the observations and dividing by their number. The mean is often denoted by a little bar over the symbol for the variable, e.g. x . The sample mean has much nicer mathematical properties than the median and is thus more useful for the comparison methods described later. The median is a very useful descriptive statistic, but not much used for other purposes. Median, mean and skewness The sum of the 57 FEV1s is 231.51 and hence the mean is 231.51/57 = 4.06. This is very close to the median, 4.1, so the median is within 1% of the mean. This is not so for the triglyceride data. The median triglyceride is 0.46 but the mean is 0.51, which is higher. The median is 10% away from the mean. If the distribution is symmetrical the sample mean and median will be about the same, but in a skew distribution they will not. If the distribution is skew to the right, as for serum triglyceride, the mean will be greater, if it is skew to the left the median will be greater. This is because the values in the tails affect the mean but not the median. Figure 1 shows the positions of the mean and median on the histogram of triglyceride. -

Chapter 4: Model Adequacy Checking
Chapter 4: Model Adequacy Checking In this chapter, we discuss some introductory aspect of model adequacy checking, including: • Residual Analysis, • Residual plots, • Detection and treatment of outliers, • The PRESS statistic • Testing for lack of fit. The major assumptions that we have made in regression analysis are: • The relationship between the response Y and the regressors is linear, at least approximately. • The error term ε has zero mean. • The error term ε has constant varianceσ 2 . • The errors are uncorrelated. • The errors are normally distributed. Assumptions 4 and 5 together imply that the errors are independent. Recall that assumption 5 is required for hypothesis testing and interval estimation. Residual Analysis: The residuals , , , have the following important properties: e1 e2 L en (a) The mean of is 0. ei (b) The estimate of population variance computed from the n residuals is: n n 2 2 ∑()ei−e ∑ei ) 2 = i=1 = i=1 = SS Re s = σ n − p n − p n − p MS Re s (c) Since the sum of is zero, they are not independent. However, if the number of ei residuals ( n ) is large relative to the number of parameters ( p ), the dependency effect can be ignored in an analysis of residuals. Standardized Residual: The quantity = ei ,i = 1,2, , n , is called d i L MS Re s standardized residual. The standardized residuals have mean zero and approximately unit variance. A large standardized residual ( > 3 ) potentially indicates an outlier. d i Recall that e = (I − H )Y = (I − H )(X β + ε )= (I − H )ε Therefore, / Var()e = var[]()I − H ε = (I − H )var(ε )(I −H ) = σ 2 ()I − H . -

Outlier Detection and Influence Diagnostics in Network Meta- Analysis
Outlier detection and influence diagnostics in network meta- analysis Hisashi Noma, PhD* Department of Data Science, The Institute of Statistical Mathematics, Tokyo, Japan ORCID: http://orcid.org/0000-0002-2520-9949 Masahiko Gosho, PhD Department of Biostatistics, Faculty of Medicine, University of Tsukuba, Tsukuba, Japan Ryota Ishii, MS Biostatistics Unit, Clinical and Translational Research Center, Keio University Hospital, Tokyo, Japan Koji Oba, PhD Interfaculty Initiative in Information Studies, Graduate School of Interdisciplinary Information Studies, The University of Tokyo, Tokyo, Japan Toshi A. Furukawa, MD, PhD Departments of Health Promotion and Human Behavior, Kyoto University Graduate School of Medicine/School of Public Health, Kyoto, Japan *Corresponding author: Hisashi Noma Department of Data Science, The Institute of Statistical Mathematics 10-3 Midori-cho, Tachikawa, Tokyo 190-8562, Japan TEL: +81-50-5533-8440 e-mail: [email protected] Abstract Network meta-analysis has been gaining prominence as an evidence synthesis method that enables the comprehensive synthesis and simultaneous comparison of multiple treatments. In many network meta-analyses, some of the constituent studies may have markedly different characteristics from the others, and may be influential enough to change the overall results. The inclusion of these “outlying” studies might lead to biases, yielding misleading results. In this article, we propose effective methods for detecting outlying and influential studies in a frequentist framework. In particular, we propose suitable influence measures for network meta-analysis models that involve missing outcomes and adjust the degree of freedoms appropriately. We propose three influential measures by a leave-one-trial-out cross-validation scheme: (1) comparison-specific studentized residual, (2) relative change measure for covariance matrix of the comparative effectiveness parameters, (3) relative change measure for heterogeneity covariance matrix. -

Residuals, Part II
Biostatistics 650 Mon, November 5 2001 Residuals, Part II Key terms External Studentization Outliers Added Variable Plot — Partial Regression Plot Partial Residual Plot — Component Plus Residual Plot Key ideas/results ¢ 1. An external estimate of ¡ comes from refitting the model without observation . Amazingly, it has an easy formula: £ ¦!¦ ¦ £¥¤§¦©¨ "# 2. Externally Studentized Residuals $ ¦ ¦©¨ ¦!¦)( £¥¤§¦&% ' Ordinary residuals standardized with £*¤§¦ . Also known as R-Student. 3. Residual Taxonomy Names Definition Distribution ¦!¦ ¦+¨-,¥¦ ,0¦ 1 Ordinary ¡ 5 /. &243 ¦768¤§¦©¨ ¦ ¦!¦ 1 ¦!¦ PRESS ¡ &243 9' 5 $ Studentized ¦©¨ ¦ £ ¦!¦ ¤0> % = Internally Studentized : ;<; $ $ Externally Studentized ¦+¨ ¦ £?¤§¦ ¦!¦ ¤0>¤A@ % R-Student = 4. Outliers are unusually large observations, due to an unmodeled shift or an (unmodeled) increase in variance. 5. Outliers are not necessarily bad points; they simply are not consistent with your model. They may posses valuable information about the inadequacies of your model. 1 PRESS Residuals & Studentized Residuals Recall that the PRESS residual has a easy computation form ¦ ¦©¨ PRESS ¦!¦ ( ¦!¦ It’s easy to show that this has variance ¡ , and hence a standardized PRESS residual is 9 ¦ ¦ ¦!¦ ¦ PRESS ¨ ¨ ¨ ¦ : £ ¦!¦ £ ¦!¦ £ ¦ ¦ % % % ' When we standardize a PRESS residual we get the studentized residual! This is very informa- ,¥¦ ¦ tive. We understand the PRESS residual to be the residual at ¦ if we had omitted from the 3 model. However, after adjusting for it’s variance, we get the same thing as a studentized residual. Hence the standardized residual can be interpreted as a standardized PRESS residual. Internal vs External Studentization ,*¦ ¦ The PRESS residuals remove the impact of point ¦ on the fit at . But the studentized 3 ¢ ¦ ¨ ¦ £?% ¦!¦ £ residual : can be corrupted by point by way of ; a large outlier will inflate the residual mean square, and hence £ . -

Chapter 39 Fit Analyses
Chapter 39 Fit Analyses Chapter Table of Contents STATISTICAL MODELS ............................568 LINEAR MODELS ...............................569 GENERALIZED LINEAR MODELS .....................572 The Exponential Family of Distributions ....................572 LinkFunction..................................573 The Likelihood Function and Maximum-Likelihood Estimation . .....574 ScaleParameter.................................576 Goodness of Fit .................................576 Quasi-Likelihood Functions ..........................577 NONPARAMETRIC SMOOTHERS ......................580 SmootherDegreesofFreedom.........................581 SmootherGeneralizedCrossValidation....................582 VARIABLES ...................................583 METHOD .....................................585 OUTPUT .....................................587 TABLES ......................................590 ModelInformation...............................590 ModelEquation.................................590 X’X Matrix . .................................591 SummaryofFitforLinearModels.......................592 SummaryofFitforGeneralizedLinearModels................593 AnalysisofVarianceforLinearModels....................594 AnalysisofDevianceforGeneralizedLinearModels.............595 TypeITests...................................595 TypeIIITests..................................597 ParameterEstimatesforLinearModels....................599 ParameterEstimatesforGeneralizedLinearModels..............601 C.I.forParameters...............................602 Collinearity -

Random Variables and Applications
Random Variables and Applications OPRE 6301 Random Variables. As noted earlier, variability is omnipresent in the busi- ness world. To model variability probabilistically, we need the concept of a random variable. A random variable is a numerically valued variable which takes on different values with given probabilities. Examples: The return on an investment in a one-year period The price of an equity The number of customers entering a store The sales volume of a store on a particular day The turnover rate at your organization next year 1 Types of Random Variables. Discrete Random Variable: — one that takes on a countable number of possible values, e.g., total of roll of two dice: 2, 3, ..., 12 • number of desktops sold: 0, 1, ... • customer count: 0, 1, ... • Continuous Random Variable: — one that takes on an uncountable number of possible values, e.g., interest rate: 3.25%, 6.125%, ... • task completion time: a nonnegative value • price of a stock: a nonnegative value • Basic Concept: Integer or rational numbers are discrete, while real numbers are continuous. 2 Probability Distributions. “Randomness” of a random variable is described by a probability distribution. Informally, the probability distribution specifies the probability or likelihood for a random variable to assume a particular value. Formally, let X be a random variable and let x be a possible value of X. Then, we have two cases. Discrete: the probability mass function of X specifies P (x) P (X = x) for all possible values of x. ≡ Continuous: the probability density function of X is a function f(x) that is such that f(x) h P (x < · ≈ X x + h) for small positive h. -

Linear Regression Diagnostics*
LIBRARY OF THE MASSACHUSETTS INSTITUTE OF TECHNOLOGY WORKING PAPER ALFRED P. SLOAN SCHOOL OF MANAGEMENT LINEAR REGRESSION DIAGNOSTICS* Soy E. Welsch and Edwin Kuh Massachusetts Institute of Technology and NBER Computer Research Center WP 923-77 April 1977 MASSACHUSETTS INSTITUTE OF TECHNOLOGY 50 MEMORIAL DRIVE CAMBRIDGE, MASSACHUSETTS 02139 ^ou to divest? access to expanded sub-regional markets possibility of royalty payments to parent access to local long term capital advantages given to a SAICA (i.e., reduce LINEAR REGRESSION DIAGNOSTICS^ Roy E. Welsch and Edwin Kuh Massachusetts Institute of Technology and NBER Computer Research Center WP 923-77 April 1977 *Me are indebted to the National Science Foundation for supporting this research under Grant SOC76-143II to the NBER Computer Research Center. - , ABSTFACT This paper atxeT.pts to provide the user of linear multiple regression with a batter;/ of iiagncstic tools to determine which, if any, data points have high leverage or irifluerice on the estimation process and how these pcssidly iiscrepar.t iata points -differ from the patterns set by the majority of the data. Tr.e point of viev; taken is that when diagnostics indicate the presence of anomolous data, the choice is open as to whether these data are in fact -unus-ual and helprul, or possioly hannful and thus in need of modifica- tions or deletion. The methodology/ developed depends on differences, derivatives, and decompositions of basic re:gressicn statistics. Th.ere is also a discussion of hov; these tecr-niques can be used with robust and ridge estimators, r^i exarripls is given showing the use of diagnostic methods in the estimation of a cross cou.ntr>' savir.gs rate model. -

Calculating Variance and Standard Deviation
VARIANCE AND STANDARD DEVIATION Recall that the range is the difference between the upper and lower limits of the data. While this is important, it does have one major disadvantage. It does not describe the variation among the variables. For instance, both of these sets of data have the same range, yet their values are definitely different. 90, 90, 90, 98, 90 Range = 8 1, 6, 8, 1, 9, 5 Range = 8 To better describe the variation, we will introduce two other measures of variation—variance and standard deviation (the variance is the square of the standard deviation). These measures tell us how much the actual values differ from the mean. The larger the standard deviation, the more spread out the values. The smaller the standard deviation, the less spread out the values. This measure is particularly helpful to teachers as they try to find whether their students’ scores on a certain test are closely related to the class average. To find the standard deviation of a set of values: a. Find the mean of the data b. Find the difference (deviation) between each of the scores and the mean c. Square each deviation d. Sum the squares e. Dividing by one less than the number of values, find the “mean” of this sum (the variance*) f. Find the square root of the variance (the standard deviation) *Note: In some books, the variance is found by dividing by n. In statistics it is more useful to divide by n -1. EXAMPLE Find the variance and standard deviation of the following scores on an exam: 92, 95, 85, 80, 75, 50 SOLUTION First we find the mean of the data: 92+95+85+80+75+50 477 Mean = = = 79.5 6 6 Then we find the difference between each score and the mean (deviation). -

Studentized Residuals
CHECKING ASSUMPTIONS/CONDITIONS AND FIXING PROBLEMS Recall, linear model is: YXiii01 where we assume: E{ε} = 0, Variance of the “errors” = σ2{ε} = σ2, same value at any X Sometimes assume errors are normally distributed (“normal errors” model). ˆ After we fit the model using data, the residuals eYYiii will be useful for checking the assumptions and conditions. But what is a large residual? If discussing GPA, 0.5 could be large but if discussion SAT scores (possible scores of 200 to 800), 0.5 would be tiny. Need to create equivalent of a z-score. Recall estimate of σ is sMSE * e i e i “Semi-studentized” residuals (p. 103) MSE Note these are called standardized residuals in R. Later, will learn another version, which R calls studentized residuals. Assumptions in the Normal Linear Regression Model A1: There is a linear relationship between X and Y. A2: The error terms (and thus the Y’s at each X) have constant variance. A3: The error terms are independent. A4: The error terms (and thus the Y’s at each X) are normally distributed. Note: In practice, we are looking for a fairly symmetric distribution with no major outliers. Other things to check (Questions to ask): Q5: Are there any major outliers in the data (X, or combination of (X,Y))? Q6: Are there other possible predictors that should be included in the model? Applet for illustrating the effect of outliers on the regression line and correlation: http://illuminations.nctm.org/LessonDetail.aspx?ID=L455 Useful Plots for Checking Assumptions and Answering These Questions Reminders: ˆ Residual -

4. Descriptive Statistics
4. Descriptive statistics Any time that you get a new data set to look at one of the first tasks that you have to do is find ways of summarising the data in a compact, easily understood fashion. This is what descriptive statistics (as opposed to inferential statistics) is all about. In fact, to many people the term “statistics” is synonymous with descriptive statistics. It is this topic that we’ll consider in this chapter, but before going into any details, let’s take a moment to get a sense of why we need descriptive statistics. To do this, let’s open the aflsmall_margins file and see what variables are stored in the file. In fact, there is just one variable here, afl.margins. We’ll focus a bit on this variable in this chapter, so I’d better tell you what it is. Unlike most of the data sets in this book, this is actually real data, relating to the Australian Football League (AFL).1 The afl.margins variable contains the winning margin (number of points) for all 176 home and away games played during the 2010 season. This output doesn’t make it easy to get a sense of what the data are actually saying. Just “looking at the data” isn’t a terribly effective way of understanding data. In order to get some idea about what the data are actually saying we need to calculate some descriptive statistics (this chapter) and draw some nice pictures (Chapter 5). Since the descriptive statistics are the easier of the two topics I’ll start with those, but nevertheless I’ll show you a histogram of the afl.margins data since it should help you get a sense of what the data we’re trying to describe actually look like, see Figure 4.2. -

Boxplots for Grouped and Clustered Data in Toxicology
Penultimate version. If citing, please refer instead to the published version in Archives of Toxicology, DOI: 10.1007/s00204-015-1608-4. Boxplots for grouped and clustered data in toxicology Philip Pallmann1, Ludwig A. Hothorn2 1 Department of Mathematics and Statistics, Lancaster University, Lancaster LA1 4YF, UK, Tel.: +44 (0)1524 592318, [email protected] 2 Institute of Biostatistics, Leibniz University Hannover, 30419 Hannover, Germany Abstract The vast majority of toxicological papers summarize experimental data as bar charts of means with error bars. While these graphics are easy to generate, they often obscure essen- tial features of the data, such as outliers or subgroups of individuals reacting differently to a treatment. Especially raw values are of prime importance in toxicology, therefore we argue they should not be hidden in messy supplementary tables but rather unveiled in neat graphics in the results section. We propose jittered boxplots as a very compact yet comprehensive and intuitively accessible way of visualizing grouped and clustered data from toxicological studies together with individual raw values and indications of statistical significance. A web application to create these plots is available online. Graphics, statistics, R software, body weight, micronucleus assay 1 Introduction Preparing a graphical summary is usually the first if not the most important step in a data analysis procedure, and it can be challenging especially with many-faceted datasets as they occur frequently in toxicological studies. However, even in simple experimental setups many researchers have a hard time presenting their results in a suitable manner. Browsing recent volumes of this journal, we have realized that the least favorable ways of displaying toxicological data appear to be the most popular ones (according to the number of publications that use them).