DRAM Parameters
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Modeling System Signal Integrity Uncertainty Considerations
WHITE PAPER Intel® FPGA Modeling System Signal Integrity Uncertainty Considerations Authors Abstract Ravindra Gali This white paper describes signal integrity (SI) mechanisms that cause system-level High-Speed I/O Applications timing uncertainty and how these mechanisms are modeled in the Intel® Quartus® Engineering, Intel® Corporation Prime software Timing Analyzer to achieve timing closure for external memory interface designs. Zhi Wong By using the Intel Quartus Prime software to achieve timing closure for external High-Speed I/O Applications memory interfaces, a designer does not need to allocate a separate SI timing Engineering, Intel Corporation budget to account for simultaneous switching output (SSO), simultaneous Navid Azizi switching input (SSI), intersymbol interference (ISI), and board-level crosstalk for Software Engineeringr flip-chip device families such as Stratix® IV and Arria® II FPGAs for typical user Intel Corporation implementation of external memory interfaces following good board design practices. John Oh High-Speed I/O Applications Introduction Engineering, Intel Corporation The widening performance gap between FPGAs, microprocessors, and memory Arun VR devices, along with the growth of memory-intensive applications, are driving the Memory I/O Applications Engineering, need for faster memory technologies. This push to higher bandwidths has been Intel Corporation accompanied by an increase in the signal count and the signaling rates of FPGAs and memory devices. In order to attain faster bandwidths, device makers continue to reduce the supply voltage. Initially, industry-standard DIMMs operated at 5 V. However, due to improvements in DRAM storage density, the operating voltage was decreased to 3.3 V (SDR), then to 2.5V (DDR), 1.8 V (DDR2), 1.5 V (DDR3), and 1.35 V (DDR3) to allow the memory to run faster and consume less power. -
2GB DDR3 SDRAM 72Bit SO-DIMM
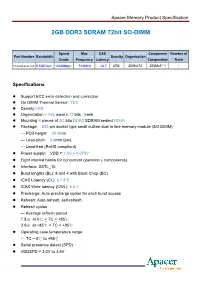
Apacer Memory Product Specification 2GB DDR3 SDRAM 72bit SO-DIMM Speed Max CAS Component Number of Part Number Bandwidth Density Organization Grade Frequency Latency Composition Rank 0C 78.A2GCB.AF10C 8.5GB/sec 1066Mbps 533MHz CL7 2GB 256Mx72 256Mx8 * 9 1 Specifications z Support ECC error detection and correction z On DIMM Thermal Sensor: YES z Density:2GB z Organization – 256 word x 72 bits, 1rank z Mounting 9 pieces of 2G bits DDR3 SDRAM sealed FBGA z Package: 204-pin socket type small outline dual in line memory module (SO-DIMM) --- PCB height: 30.0mm --- Lead pitch: 0.6mm (pin) --- Lead-free (RoHS compliant) z Power supply: VDD = 1.5V + 0.075V z Eight internal banks for concurrent operation ( components) z Interface: SSTL_15 z Burst lengths (BL): 8 and 4 with Burst Chop (BC) z /CAS Latency (CL): 6,7,8,9 z /CAS Write latency (CWL): 5,6,7 z Precharge: Auto precharge option for each burst access z Refresh: Auto-refresh, self-refresh z Refresh cycles --- Average refresh period 7.8㎲ at 0℃ < TC < +85℃ 3.9㎲ at +85℃ < TC < +95℃ z Operating case temperature range --- TC = 0℃ to +95℃ z Serial presence detect (SPD) z VDDSPD = 3.0V to 3.6V Apacer Memory Product Specification Features z Double-data-rate architecture; two data transfers per clock cycle. z The high-speed data transfer is realized by the 8 bits prefetch pipelined architecture. z Bi-directional differential data strobe (DQS and /DQS) is transmitted/received with data for capturing data at the receiver. z DQS is edge-aligned with data for READs; center aligned with data for WRITEs. -

Different Types of RAM RAM RAM Stands for Random Access Memory. It Is Place Where Computer Stores Its Operating System. Applicat
Different types of RAM RAM RAM stands for Random Access Memory. It is place where computer stores its Operating System. Application Program and current data. when you refer to computer memory they mostly it mean RAM. The two main forms of modern RAM are Static RAM (SRAM) and Dynamic RAM (DRAM). DRAM memories (Dynamic Random Access Module), which are inexpensive . They are used essentially for the computer's main memory SRAM memories(Static Random Access Module), which are fast and costly. SRAM memories are used in particular for the processer's cache memory. Early memories existed in the form of chips called DIP (Dual Inline Package). Nowaday's memories generally exist in the form of modules, which are cards that can be plugged into connectors for this purpose. They are generally three types of RAM module they are 1. DIP 2. SIMM 3. DIMM 4. SDRAM 1. DIP(Dual In Line Package) Older computer systems used DIP memory directely, either soldering it to the motherboard or placing it in sockets that had been soldered to the motherboard. Most memory chips are packaged into small plastic or ceramic packages called dual inline packages or DIPs . A DIP is a rectangular package with rows of pins running along its two longer edges. These are the small black boxes you see on SIMMs, DIMMs or other larger packaging styles. However , this arrangment caused many problems. Chips inserted into sockets suffered reliability problems as the chips would (over time) tend to work their way out of the sockets. 2. SIMM A SIMM, or single in-line memory module, is a type of memory module containing random access memory used in computers from the early 1980s to the late 1990s . -

Product Guide SAMSUNG ELECTRONICS RESERVES the RIGHT to CHANGE PRODUCTS, INFORMATION and SPECIFICATIONS WITHOUT NOTICE
May. 2018 DDR4 SDRAM Memory Product Guide SAMSUNG ELECTRONICS RESERVES THE RIGHT TO CHANGE PRODUCTS, INFORMATION AND SPECIFICATIONS WITHOUT NOTICE. Products and specifications discussed herein are for reference purposes only. All information discussed herein is provided on an "AS IS" basis, without warranties of any kind. This document and all information discussed herein remain the sole and exclusive property of Samsung Electronics. No license of any patent, copyright, mask work, trademark or any other intellectual property right is granted by one party to the other party under this document, by implication, estoppel or other- wise. Samsung products are not intended for use in life support, critical care, medical, safety equipment, or similar applications where product failure could result in loss of life or personal or physical harm, or any military or defense application, or any governmental procurement to which special terms or provisions may apply. For updates or additional information about Samsung products, contact your nearest Samsung office. All brand names, trademarks and registered trademarks belong to their respective owners. © 2018 Samsung Electronics Co., Ltd. All rights reserved. - 1 - May. 2018 Product Guide DDR4 SDRAM Memory 1. DDR4 SDRAM MEMORY ORDERING INFORMATION 1 2 3 4 5 6 7 8 9 10 11 K 4 A X X X X X X X - X X X X SAMSUNG Memory Speed DRAM Temp & Power DRAM Type Package Type Density Revision Bit Organization Interface (VDD, VDDQ) # of Internal Banks 1. SAMSUNG Memory : K 8. Revision M: 1st Gen. A: 2nd Gen. 2. DRAM : 4 B: 3rd Gen. C: 4th Gen. D: 5th Gen. -

Dual-DIMM DDR2 and DDR3 SDRAM Board Design Guidelines, External
5. Dual-DIMM DDR2 and DDR3 SDRAM Board Design Guidelines June 2012 EMI_DG_005-4.1 EMI_DG_005-4.1 This chapter describes guidelines for implementing dual unbuffered DIMM (UDIMM) DDR2 and DDR3 SDRAM interfaces. This chapter discusses the impact on signal integrity of the data signal with the following conditions in a dual-DIMM configuration: ■ Populating just one slot versus populating both slots ■ Populating slot 1 versus slot 2 when only one DIMM is used ■ On-die termination (ODT) setting of 75 Ω versus an ODT setting of 150 Ω f For detailed information about a single-DIMM DDR2 SDRAM interface, refer to the DDR2 and DDR3 SDRAM Board Design Guidelines chapter. DDR2 SDRAM This section describes guidelines for implementing a dual slot unbuffered DDR2 SDRAM interface, operating at up to 400-MHz and 800-Mbps data rates. Figure 5–1 shows a typical DQS, DQ, and DM signal topology for a dual-DIMM interface configuration using the ODT feature of the DDR2 SDRAM components. Figure 5–1. Dual-DIMM DDR2 SDRAM Interface Configuration (1) VTT Ω RT = 54 DDR2 SDRAM DIMMs (Receiver) Board Trace FPGA Slot 1 Slot 2 (Driver) Board Trace Board Trace Note to Figure 5–1: (1) The parallel termination resistor RT = 54 Ω to VTT at the FPGA end of the line is optional for devices that support dynamic on-chip termination (OCT). © 2012 Altera Corporation. All rights reserved. ALTERA, ARRIA, CYCLONE, HARDCOPY, MAX, MEGACORE, NIOS, QUARTUS and STRATIX words and logos are trademarks of Altera Corporation and registered in the U.S. Patent and Trademark Office and in other countries. -

Access Order and Effective Bandwidth for Streams on a Direct Rambus Memory Sung I
Access Order and Effective Bandwidth for Streams on a Direct Rambus Memory Sung I. Hong, Sally A. McKee†, Maximo H. Salinas, Robert H. Klenke, James H. Aylor, Wm. A. Wulf Dept. of Electrical and Computer Engineering †Dept. of Computer Science University of Virginia University of Utah Charlottesville, VA 22903 Salt Lake City, Utah 84112 Abstract current DRAM page forces a new page to be accessed. The Processor speeds are increasing rapidly, and memory speeds are overhead time required to do this makes servicing such a request not keeping up. Streaming computations (such as multi-media or significantly slower than one that hits the current page. The order of scientific applications) are among those whose performance is requests affects the performance of all such components. Access most limited by the memory bottleneck. Rambus hopes to bridge the order also affects bus utilization and how well the available processor/memory performance gap with a recently introduced parallelism can be exploited in memories with multiple banks. DRAM that can deliver up to 1.6Gbytes/sec. We analyze the These three observations — the inefficiency of traditional, performance of these interesting new memory devices on the inner dynamic caching for streaming computations; the high advertised loops of streaming computations, both for traditional memory bandwidth of Direct Rambus DRAMs; and the order-sensitive controllers that treat all DRAM transactions as random cacheline performance of modern DRAMs — motivated our investigation of accesses, and for controllers augmented with streaming hardware. a hardware streaming mechanism that dynamically reorders For our benchmarks, we find that accessing unit-stride streams in memory accesses in a Rambus-based memory system. -

Baby Steps to Our Future by Ron Fenley
Baby Steps to our Future by Ron Fenley Memory – Past, Present and Future, Part 2 of 3 Memories,… food for the EGO. Manifestation of memories into self-esteem, honor, dignity and many other traits characterize the individual. Obviously, memories are stored in the brain and scientist have identified, subdivided, labeled and compartmentalized the brain in many functional regions. Computer memory like human memory manifests it presents in different ways to perform a variety of functions; and computer memory has been divided into partitions, subsystems and specialization. Although the memory in today’s computers have not been programmed with personality traits, some PC systems do demonstrate personality disorders, particularly the one this article was written with. There is an abundance of terms that have been used to describe or label computer memory functions, features and attributes. Some terms apply to the hardware technology, some terms apply to the packing of these chips and others apply to the memory usage or memory systems within the computer. Collectively, all of these terms may be confusing and to help sort out and clarify these labels we will look at how these items have been applied to computer memory. To simplify this task, the effort will be divided into the following 5 areas: packing, parity & ECC, buffered/non-buffered, systems and labels. MEMORY PACKAGING Just as memory technology has evolved so has memory packaging. Shown below is a table of the different form factors (packaging) that has been used in memory deployment over -

Micron Technology Inc
MICRON TECHNOLOGY INC FORM 10-K (Annual Report) Filed 10/26/10 for the Period Ending 09/02/10 Address 8000 S FEDERAL WAY PO BOX 6 BOISE, ID 83716-9632 Telephone 2083684000 CIK 0000723125 Symbol MU SIC Code 3674 - Semiconductors and Related Devices Industry Semiconductors Sector Technology Fiscal Year 03/10 http://www.edgar-online.com © Copyright 2010, EDGAR Online, Inc. All Rights Reserved. Distribution and use of this document restricted under EDGAR Online, Inc. Terms of Use. UNITED STATES SECURITIES AND EXCHANGE COMMISSION Washington, D.C. 20549 FORM 10-K (Mark One) ANNUAL REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 For the fiscal year ended September 2, 2010 OR TRANSITION REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 For the transition period from to Commission file number 1-10658 Micron Technology, Inc. (Exact name of registrant as specified in its charter) Delaware 75 -1618004 (State or other jurisdiction of (IRS Employer incorporation or organization) Identification No.) 8000 S. Federal Way, Boise, Idaho 83716 -9632 (Address of principal executive offices) (Zip Code) Registrant ’s telephone number, including area code (208) 368 -4000 Securities registered pursuant to Section 12(b) of the Act: Title of each class Name of each exchange on which registered Common Stock, par value $.10 per share NASDAQ Global Select Market Securities registered pursuant to Section 12(g) of the Act: None (Title of Class) Indicate by check mark if the registrant is a well-known seasoned issuer, as defined in Rule 405 of the Securities Act. -

AN 436: Using DDR3 SDRAM in Stratix III and Stratix IV Devices.Pdf
AN 436: Using DDR3 SDRAM in Stratix III and Stratix IV Devices © November 2008 AN-436-4.0 Introduction DDR3 SDRAM is the latest generation of DDR SDRAM technology, with improvements that include lower power consumption, higher data bandwidth, enhanced signal quality with multiple on-die termination (ODT) selection and output driver impedance control. DDR3 SDRAM brings higher memory performance to a broad range of applications, such as PCs, embedded processor systems, image processing, storage, communications, and networking. Although DDR2 SDRAM is currently the more popular SDRAM, to save system power and increase system performance you should consider using DDR3 SDRAM. DDR3 SDRAM offers lower power by using 1.5 V for the supply and I/O voltage compared to the 1.8-V supply and I/O voltage used by DDR2 SDRAM. DDR3 SDRAM also has better maximum throughput compared to DDR2 SDRAM by increasing the data rate per pin and the number of banks (8 banks are standard). 1 The Altera® ALTMEMPHY megafunction and DDR3 SDRAM high-performance controller only support local interfaces running at half the rate of the memory interface. Altera Stratix® III and Stratix IV devices support DDR3 SDRAM interfaces with dedicated DQS, write-, and read-leveling circuitry. Table 1 displays the maximum clock frequency for DDR3 SDRAM in Stratix III devices. Table 1. DDR3 SDRAM Maximum Clock Frequency Supported in Stratix III Devices (Note 1), (2) Speed Grade fMAX (MHz) –2 533 (3) –3 and I3 400 –4, 4L, and I4L at 1.1 V 333 (4), (5) –4, 4L, and I4L at 0.9 V Not supported Notes to Table 1: (1) Numbers are preliminary until characterization is final. -

High Bandwidth Memory for Graphics Applications Contents
High Bandwidth Memory for Graphics Applications Contents • Differences in Requirements: System Memory vs. Graphics Memory • Timeline of Graphics Memory Standards • GDDR2 • GDDR3 • GDDR4 • GDDR5 SGRAM • Problems with GDDR • Solution ‐ Introduction to HBM • Performance comparisons with GDDR5 • Benchmarks • Hybrid Memory Cube Differences in Requirements System Memory Graphics Memory • Optimized for low latency • Optimized for high bandwidth • Short burst vector loads • Long burst vector loads • Equal read/write latency ratio • Low read/write latency ratio • Very general solutions and designs • Designs can be very haphazard Brief History of Graphics Memory Types • Ancient History: VRAM, WRAM, MDRAM, SGRAM • Bridge to modern times: GDDR2 • The first modern standard: GDDR4 • Rapidly outclassed: GDDR4 • Current state: GDDR5 GDDR2 • First implemented with Nvidia GeForce FX 5800 (2003) • Midway point between DDR and ‘true’ DDR2 • Stepping stone towards DDR‐based graphics memory • Second‐generation GDDR2 based on DDR2 GDDR3 • Designed by ATI Technologies , first used by Nvidia GeForce FX 5700 (2004) • Based off of the same technological base as DDR2 • Lower heat and power consumption • Uses internal terminators and a 32‐bit bus GDDR4 • Based on DDR3, designed by Samsung from 2005‐2007 • Introduced Data Bus Inversion (DBI) • Doubled prefetch size to 8n • Used on ATI Radeon 2xxx and 3xxx, never became commercially viable GDDR5 SGRAM • Based on DDR3 SDRAM memory • Inherits benefits of GDDR4 • First used in AMD Radeon HD 4870 video cards (2008) • Current -

DDR400/333/266, Dual DDR, RDRAM 16 Bit and 32 Bit, SDRAM
Ace’s Hardware Granite Bay: Memory Technology Shootout Granite Bay: Memory Technology Shootout By Johan De Gelas – December 2002 Dual-Channel DDR SDRAM Arrives for the Pentium 4 DDR400/333/266, Dual DDR, RDRAM 16 bit and 32 bit, SDRAM... almost every memory technology on the market is available for the Pentium 4 platform. One of our previous technical articles discussed the advantages and disadvantages of the different architectures of Rambus and SDRAM based memory technology such as DDR and DDR-II. In this article, we will investigate how the different memory technologies and their supporting chipsets compare on the test bench. The following motherboards were tested: • The ASUS P4T533 features the i850E chipset and 32 bit RDRAM • The ASUS P4T533-C comes with the same chipset but uses two channels of 16 bit RIMMs • The MSI 648 Max comes with SIS 648 chipset which unofficially supports DDR400 • The MSI i845PE comes with Intel's newest i845 chipset, which officially support DDR333 • The Tyan Trinity 7205 and MSI GNB Max feature the Dual DDR266 Granite Bay chipset We are well aware that there have already many tests with Pentium 4 chipsets, Granite Bay included. So why bother to publish another on Ace’s Hardware? The focus of this article is on the memory technology supported by these chipsets. This article will offer you a insight in how the different memory technologies compare in a wide variety of applications. We'll investigate in depth what the advantages and disadvantages are of each memory technology and try to find out what are the reasons behind this. -

Chang-Hong Wu Distinguished Engineer, Juniper Networks the INTERNET EXPLOSION
ASICS: THE HEART OF MODERN ROUTERS Chang-Hong Wu Distinguished Engineer, Juniper Networks THE INTERNET EXPLOSION # Web Sites 130EB/yr Internet Capacity 162M # Connected Devices 1B Total Digitized Information 420EB # Google Searches/Month 100M 31B/mo 12EB/yr 40M 110EB 4PB/yr 60PB/yr 9.5M 160M 25M 33K 1 1.7M 2.7B/mo 1988 1993 1998 2003 2008 Exponential growth, no matter how you measure it! The clearest indication of value delivered to end-users 2 Copyright © 2010 Juniper Networks, Inc. DRIVING FORCE BEHIND EXPONENTIAL GROWTH C S C S N C S Information N System N Digital Stored Pipelining Microprocessor Multi-core Computing Program Computing Digital Circuit Packet TCP/IP Transmission Switching Switching HPN Networking Flash Digital Core Disk DRAM Storage Memory Storage 3 Copyright © 2010 Juniper Networks, Inc. COMPUTER PERFORMANCE: 1988-2008 228 500,000 X over 20 years 226 224 222 220 218 System CAGR: 1.9x /year 216 214 12 2 Super Computers 210 28 26 Megahertz Megahertz / MFlops 24 Microprocessor CAGR: 1.3x /year 22 20 „88 „89 „90 „91 „92 „93 „94 „95 „96 „97 „98 „99 „00 „01 „02 „03 „04 „05 „06 „07 „08 4 Copyright © 2010 Juniper Networks, Inc. ROUTER PERFORMANCE 1988 – 2008 1000,000 X over 20 years (2x /year) 224 Post-ASIC era: 2.2x /year TX T1600 222 220 T640 M160 218 Pre-ASIC era: 1.6x /year M40 216 214 212 Interface CAGR: 1.7x /year 210 28 26 Megabits per second 24 22 20 „88 „89 „90 „91 „92 „93 „94 „95 „96 „97 „98 „99 „00 „01 „02 „03 „04 „05 „06 „07 „08 5 Copyright © 2010 Juniper Networks, Inc.