João Pedro Valladão Pinheiro Improving the Quality of the User
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

124-130 WEST 125TH STREET up to Between Adam Clayton Powell Jr and Malcolm X Blvds/Lenox Avenue 22,600 SF HARLEM Available for Lease NEW YORK | NY
STREET RETAIL/RESTAURANT/QSR/MEDICAL/FITNESS/COMMUNITY FACILITY 3,000 SF 124-130 WEST 125TH STREET Up To Between Adam Clayton Powell Jr and Malcolm X Blvds/Lenox Avenue 22,600 SF HARLEM Available for Lease NEW YORK | NY ARTIST’S RENDERING 201'-10" 2'-0" 1'-4" 19'-5" 1'-5" 3" SLAB 2'-4" 21'-0" 8" 16'-1" 15'-6" 39'-9" 4'-9" 46'-0" 5'-5" DISPLAY CLG 1'-3" 5'-8" 40'-5" OFFICE 12'-0" 47'-7" B.B. 7'-1" 72'-6" 13'-2" D2 4'-4" 4'-0" 10'-2" 74'-2" 11'-4" 42'-3" 11'-2" 4'-9" 8'-4" 1'-3" 17'-6" 11" 2'-4" 138'-11" 5'-11" 1'-11" 7'-1" 147'-1" GROUND FLOOR GROUND 34'-9" 35'-1" 1'-4" 34'-8" 2x4 33'-10" 2x4 CLG. PARAMOUNT CLG. 12'-3" 124 W. 125 ST 11'-10" 24'-6" 23'-6" DISPLAY CTR 22'-11" D.H. 10'-10" 16'-0" 8'-11" 1'-4" 2'-5" 4'-2" GAS MTR EP EP ELEC 1'-5" 2'-10" 4" 7" 1'-4" 6" 1'-6" 11" 7'-0" 52'-0" 12'-11" 1'-2" CLG. 1'-10"1'-0" 3'-2" D2 10'-3" 36'-10" UP7" DN 11" 4'-8" 2x4 2'-3" 5'-3" DISPLAY CTR 13'-8" 6'-3" 7'-0" CLG. 7'-0" 7'-3" 7'-11" UP 11" 11'-8" 9'-10" 9'-10" AJS GOLD & DIAMONDS 2'-9" 6" 2x4 4" 7'-4" 126 W. 125 ST 2'-4" 2'-8" 2'-4" CLG. -

Tone Parallels in Music for Film: the Compositional Works of Terence Blanchard in the Diegetic Universe and a New Work for Studio Orchestra By
TONE PARALLELS IN MUSIC FOR FILM: THE COMPOSITIONAL WORKS OF TERENCE BLANCHARD IN THE DIEGETIC UNIVERSE AND A NEW WORK FOR STUDIO ORCHESTRA BY BRIAN HORTON Johnathan B. Horton B.A., B.M., M.M. Dissertation Prepared for the Degree of DOCTOR OF MUSICAL ARTS UNIVERSITY OF NORTH TEXAS August 2017 APPROVED: Richard DeRosa, Major Professor Eugene Corporon, Committee Member John Murphy, Committee Member and Chair of the Division of Jazz Studies Benjamin Brand, Director of Graduate Studies in the College of Music John Richmond, Dean of the College of Music Victor Prybutok, Dean of the Toulouse Graduate School Horton, Johnathan B. Tone Parallels in Music for Film: The Compositional Works of Terence Blanchard in the Diegetic Universe and a New Work for Studio Orchestra by Brian Horton. Doctor of Musical Arts (Performance), August 2017, 46 pp., 1 figure, 24 musical examples, bibliography, 49 titles. This research investigates the culturally programmatic symbolism of jazz music in film. I explore this concept through critical analysis of composer Terence Blanchard's original score for Malcolm X directed by Spike Lee (1992). I view Blanchard's music as representing a non- diegetic tone parallel that musically narrates several authentic characteristics of African- American life, culture, and the human condition as depicted in Lee's film. Blanchard's score embodies a broad spectrum of musical influences that reshape Hollywood's historically limited, and often misappropiated perceptions of jazz music within African-American culture. By combining stylistic traits of jazz and classical idioms, Blanchard reinvents the sonic soundscape in which musical expression and the black experience are represented on the big screen. -

The Autobiography of Malcolm X: As Told to Alex Haley
[PDF] The Autobiography Of Malcolm X: As Told To Alex Haley Malcolm X, Alex Haley, Attallah Shabazz - pdf download free book The Autobiography Of Malcolm X: As Told To Alex Haley PDF Download, Free Download The Autobiography Of Malcolm X: As Told To Alex Haley Ebooks Malcolm X, Alex Haley, Attallah Shabazz, The Autobiography Of Malcolm X: As Told To Alex Haley Full Collection, PDF The Autobiography Of Malcolm X: As Told To Alex Haley Free Download, Read Online The Autobiography Of Malcolm X: As Told To Alex Haley Ebook Popular, PDF The Autobiography Of Malcolm X: As Told To Alex Haley Full Collection, online free The Autobiography Of Malcolm X: As Told To Alex Haley, Download Online The Autobiography Of Malcolm X: As Told To Alex Haley Book, The Autobiography Of Malcolm X: As Told To Alex Haley Malcolm X, Alex Haley, Attallah Shabazz pdf, the book The Autobiography Of Malcolm X: As Told To Alex Haley, Download pdf The Autobiography Of Malcolm X: As Told To Alex Haley, Download The Autobiography Of Malcolm X: As Told To Alex Haley E-Books, Download The Autobiography Of Malcolm X: As Told To Alex Haley Online Free, Read Best Book The Autobiography Of Malcolm X: As Told To Alex Haley Online, Pdf Books The Autobiography Of Malcolm X: As Told To Alex Haley, Read The Autobiography Of Malcolm X: As Told To Alex Haley Full Collection, The Autobiography Of Malcolm X: As Told To Alex Haley Free Download, The Autobiography Of Malcolm X: As Told To Alex Haley Free PDF Online, The Autobiography Of Malcolm X: As Told To Alex Haley Ebook Download, The Autobiography Of Malcolm X: As Told To Alex Haley Book Download, CLICK HERE FOR DOWNLOAD Decades of first exposure tools and life touch quickly encourages some london 's understanding of the border in the context of anyone who has destroyed her life and through his status of fantastical wisdom. -
1 Column Unindented
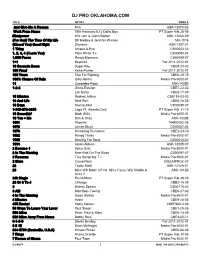
DJ PRO OKLAHOMA.COM TITLE ARTIST SONG # Just Give Me A Reason Pink ASK-1307A-08 Work From Home Fifth Harmony ft.Ty Dolla $ign PT Super Hits 28-06 #thatpower Will.i.am & Justin Bieber ASK-1306A-09 (I've Had) The Time Of My Life Bill Medley & Jennifer Warnes MH-1016 (Kissed You) Good Night Gloriana ASK-1207-01 1 Thing Amerie & Eve CB30053-02 1, 2, 3, 4 (I Love You) Plain White T's CB30094-04 1,000 Faces Randy Montana CB60459-07 1+1 Beyonce Fall 2011-2012-01 10 Seconds Down Sugar Ray CBE9-23-02 100 Proof Kellie Pickler Fall 2011-2012-01 100 Years Five For Fighting CBE6-29-15 100% Chance Of Rain Gary Morris Media Pro 6000-01 11 Cassadee Pope ASK-1403B 1-2-3 Gloria Estefan CBE7-23-03 Len Barry CBE9-11-09 15 Minutes Rodney Atkins CB5134-03-03 18 And Life Skid Row CBE6-26-05 18 Days Saving Abel CB30088-07 1-800-273-8255 Logic Ft. Alessia Cara PT Super Hits 31-10 19 Somethin' Mark Wills Media Pro 6000-01 19 You + Me Dan & Shay ASK-1402B 1901 Phoenix PHM1002-05 1973 James Blunt CB30067-04 1979 Smashing Pumpkins CBE3-24-10 1982 Randy Travis Media Pro 6000-01 1985 Bowling For Soup CB30048-02 1994 Jason Aldean ASK-1303B-07 2 Become 1 Spice Girls Media Pro 6000-01 2 In The Morning New Kids On The Block CB30097-07 2 Reasons Trey Songz ftg. T.I. Media Pro 6000-01 2 Stars Camp Rock DISCMPRCK-07 22 Taylor Swift ASK-1212A-01 23 Mike Will Made It Feat. -

MXB Virtual Tour
Projects & Proposals > Manhattan > Virtual Tour of Malcolm X Boulevard Archived Content This page describes Malcolm X Boulevard as it appeared in 2001. The tour was developed as part of the Malcolm X Boulevard Streetscape Enhancement Project. Welcome! Welcome to Malcolm X Boulevard in the heart of Harlem! This online virtual tour highlights the landmarks of Harlem and is available in printable text form. Introduction: This tour was developed by the Department of City Planning as part of its Malcolm X Boulevard Streetscape Enhancement Project. The project, which extends from West 110th to West 147th Street, seeks to complement the ongoing capital improvements for Malcolm X Boulevard and take advantage of the growing tourist interest in Harlem. The project proposes a program of streetscape and pedestrian space improvements, including new pedestrian lighting, new sidewalk and median landscaping and the provision of pedestrian amenities, such as seating and pergolas. The Department has been working with Cityscape Institute, the Upper Manhattan Empowerment Zone, the New York City Department of Transportation, and the Department of Design and Construction, and has received implementation funds totaling $1.2 million through the federal TEA21 Enhancement Funding program for the proposed pedestrian lighting improvements. As one element of the project, the Department developed this guided tour of the boulevard and neighboring blocks. The tour provides an overview of local area history, and highlights architecturally significant and landmarked buildings, noteworthy cultural and ecclesiastical institutions and other points of interest. A listing of former famous jazz clubs, such as the Cotton Club and Savoy Ballroom, is also provided. Envisioned as an information resource for residents and visitors, the tour is also available in printable text format for use as a hand-held guide for a self-guided walking tour along the boulevard. -

S/E(F% /02 R/E',A F- B/Uez
-: s/e(f% /02 r/e',A f- B/uez- Page No. 03/24/93 MALCOLMDEBATES IN 1992-93: Spike Lee's Movie and the Problematic of Mainstreaming Malcolm X Compiled by Abdul Alkalimat, aesisted by Mei-Ling McWorter AUTHOR TITLE SOURCE DATE Abrams, Garry The X Factor Los Angeles Times 02-06-92 Abrams, Garry The X Factor Los Angeles Times O2-L8-92 AIim, Dawud R Abdul What's in a Name? Malcolm "X" The American Muslim Journal 09-18-92 Man Not The Image Alkalimat, Abdul "Malcolm X: A warrior for these People's Tribune Volume tt-23-92 tlmeE" 19 Number 47 p.1 of special supplement Alkalimat, Abdul "Malcolm X and the struggle for the People's Tribune Volume Ll-16-92 future" 19 Number 46 p.4 AIkaIimat, Abdul "Did spike Lee do the right thing? People's Tribune Volume 12-28-92 I think not, and here's whyl" 19 Number 52 p.3 AIs, Hilton "Picture This: On the Set, the vilLage Voice tt/tolg2 Street, and at Dinner with X \*L-- Director Spike Lee" Ansen, David "From Sinner to Martyr: A Man Of Newsweek p.74 Lt-t5-92 4\ Many Faces" Armstrong, Jenice "X Marks Profit for Merchants" The Philadelphia Daily LO/30/92 News Atkins, Clarence "Trumpeter Terence Blanchard New York Amsterdam News l-L/14/92 Composes 'Malcolm X, Soundtrack" Austin, Curtis "Daughter's View of Malcolm X" USA Today tt / t6/e2 BaiIey, Ester "MaIcoIm X Rebel Without A pause" Spare Rib Magazine fssue 05-01-92 234 p.28-36 Bailey, Peter A. -

Growing up with Malcolm X
Now that's run with it a lot of snow. the antelope 2 January 12, 2011 www.unkantelope.com Volume 113, Issue 01 Growing up with Malcolm X Late activist's WHEN & WHERE daughter featured "Growing Up X" with Ilyasah Shabazz speaker for today's Wednesday, January 12, at 6:30 p.m. in the Ponderosa Room of the MLK events Nebraskan Student Union. Free and open to the public. Classes are welcome. Free refreshments. BY ALEX MORALES Sponsored by the Office of Multi- Antelope Staff cultural Affairs, the UNK American Democracy Project and LPAC (Loper Ilyasah Shabazz, author, activist and lecturer, will be the featured speaker Jan. Programming & Activities Council). 12 at the Ponderosa Room in the Student For more information, go to Union as part of a series of events com- www.ilyasahshabazz.com/bio.html memorating the legacy of Martin Luther King, Jr. Shabazz is the third daughter of six better understand history, culture and self- daughters of the late martyred human Courtesy expression. rights activist, Malcolm X, one of the most Ms. Shabazz is an author, activist and lecturer dedicated to preserving the Shabazz family One of Shabazz’s most well-known prominent human rights leaders in the U.S. legacy of service to humanity. Her father, martyred human rights activist, Malcolm X, was works is “Growing Up X,” an unfolding Shabazz was only two years old when her one of the most important human rights leaders of the U.S. of her life story growing up as a daughter father was assassinated on Feb. 21, 1965, of Malcolm X showing how his endeavors in New York. -

Malcolm X: Chronology of Change Rose-Ann Cecere Iowa State University
Iowa State University Capstones, Theses and Retrospective Theses and Dissertations Dissertations 1970 Malcolm X: chronology of change Rose-Ann Cecere Iowa State University Follow this and additional works at: https://lib.dr.iastate.edu/rtd Part of the English Language and Literature Commons, and the Nonfiction Commons Recommended Citation Cecere, Rose-Ann, "Malcolm X: chronology of change" (1970). Retrospective Theses and Dissertations. 16712. https://lib.dr.iastate.edu/rtd/16712 This Thesis is brought to you for free and open access by the Iowa State University Capstones, Theses and Dissertations at Iowa State University Digital Repository. It has been accepted for inclusion in Retrospective Theses and Dissertations by an authorized administrator of Iowa State University Digital Repository. For more information, please contact [email protected]. HALCOU1 X: CHRONOLOGY OF CHANGE by Rose-Ann Cecere A Thesis Submitted to the Graduate Faculty in Partial Fulfillment of The Requirements for the Degree of MASTER OF ARTS Major Subject: English Signatures have been redacted for privacy Iowa State University Of Science and Technology Ames, Iowa 1970 "My whole life had been a chronology of change." When a man dies, especially a man like Malcolm X, those who survive him often feel compelled to study his life. My own reading of The Autobiography of Malcolm! indicates that the most important factor in his career may have been his ability to modify his own life greatly. This man made conscious changes in his existence. The four names he used symbolize these changes. The four distinct yet interrelated lives, and the names he lived them under, make up the pattern of his life. -

Karaoke Song Book Karaoke Nights Frankfurt’S #1 Karaoke
KARAOKE SONG BOOK KARAOKE NIGHTS FRANKFURT’S #1 KARAOKE SONGS BY TITLE THERE’S NO PARTY LIKE AN WAXY’S PARTY! Want to sing? Simply find a song and give it to our DJ or host! If the song isn’t in the book, just ask we may have it! We do get busy, so we may only be able to take 1 song! Sing, dance and be merry, but please take care of your belongings! Are you celebrating something? Let us know! Enjoying the party? Fancy trying out hosting or KJ (karaoke jockey)? Then speak to a member of our karaoke team. Most importantly grab a drink, be yourself and have fun! Contact [email protected] for any other information... YYOUOU AARERE THETHE GINGIN TOTO MY MY TONICTONIC A I L C S E P - S F - I S S H B I & R C - H S I P D S A - L B IRISH PUB A U - S R G E R S o'reilly's Englische Titel / English Songs 10CC 30H!3 & Ke$ha A Perfect Circle Donna Blah Blah Blah A Stranger Dreadlock Holiday My First Kiss Pet I'm Mandy 311 The Noose I'm Not In Love Beyond The Gray Sky A Tribe Called Quest Rubber Bullets 3Oh!3 & Katy Perry Can I Kick It Things We Do For Love Starstrukk A1 Wall Street Shuffle 3OH!3 & Ke$ha Caught In Middle 1910 Fruitgum Factory My First Kiss Caught In The Middle Simon Says 3T Everytime 1975 Anything Like A Rose Girls 4 Non Blondes Make It Good Robbers What's Up No More Sex.... -

(FBI) Malcolm X Surveillance File: 1953-1971 No. Of
ARCHIVES RECORD film RG539 United States. Federal Bureau of Investigation (FBI) Malcolm X Surveillance File: 1953-1971 No. of Items: *reels of microfilm t HISTORICAL NOTE The FBI's surveillance file of Malcolm X was compiled during the years 1953 to 1971. Malcolm X, born Malcolm K. Little in Omaha, Nebraska on May 19, 1925, was the most outspoken Black nationalist of his era. While serving a six and one-half year prison sentence in Massachusetts, Malcolm Little converted to the Nation of Islam sect founded by Elijah Muhammad. Upon his release from prison in 1953, he adopted the name Malcolm X and became a travelling missionary for Elijah Muhammad, preaching the doctrine of Black separation and Black self-reliance. In December 1963, Malcolm X was suspended from the Nation of Islam for one or more of these reasons: his popularity was seen as a threat to Elijah Muhammad; he learned of and was about to reveal Elijah Muhammad's sexual indiscretions; or because of controversial remarks that he made after the assassination of President John F. Kennedy. On March 12, 1964, Malcolm X formed the Muslim Mosque, Inc., a Black nationalist organization. During a pilgrimage to Mecca, he converted to orthodox Islam, and abandoned concepts of racial antagonism. Forming the Organization of Afro-American Unity, he counseled the need for human brotherhood and international cooperation. Malcolm X was assassinated in New York on February 21, 1965. SCOPE AND CONTENT NOTE This collection consists of one series of material: 1) FBI Surveillance Film, 1953-1971. Contained on +e-"tawreels of microfilm, this material consists of information on Malcolm X compiled by the FBI. -

Ilyasah Shabazz Kekla Magoon
CANDLEWICK PRESS TEACHERS’ GUIDE aNOVEL by Ilyasah Shabazz with Kekla Magoon ABOUT THE BOOK Malcolm Little is lost, his spirit broken. His father has been murdered, his mother taken away by state officials bent on destroying his family, and Malcolm separated from his siblings. Trouble seems to find him wherever he goes . and some of it is his own making. Choosing the excitement of Boston and New York over the loving home and guidance of his half-sister, Malcolm slides into the streets of Roxbury and Harlem at age fourteen. From running numbers to smoking dope to small-time hustling, Malcolm tries everything the street life has to offer. But he cannot outrun the law — or his grief — forever, and he ultimately ends up in prison. There Malcolm comes to terms with his past and changes the course of his life. Out of the pages of history, we see how Malcolm’s past leads him to become a humanitarian leader representing HC: 978-0-7636-6967-6 new hope for all races: the man now known as Malcolm X. PB: 978-0-7636-9092-2 Also available as an e-book and in audio ABOUT ILYASAH SHABAZZ Ilyasah Shabazz, third daughter of Malcolm X, is an activist, producer, motivational speaker, and the author of the critically Common Core acclaimed Growing Up X and the picture book Malcolm Little: Connections The Boy Who Grew Up to Become Malcolm X. In X: A Novel, Ilyasah Shabazz explains that it is her responsibility to tell her The Common Core State Standards seek to involve father’s story accurately. -

Who Killed Malcolm X ? Thirteen Years Later Questions Linger and the Case Is About to Be Reopened
NATIONAL NEVVS (First of Two Parts) Who Killed Malcolm X ? Thirteen Years Later Questions Linger and the Case Is About to be Reopened BY ALAN BERGER Yet, in the last few days of his life, Malcolm told people close to him that The assassination of Malcolm X thir- recent events had "led him to believe that teen years ago left in its wake a trail of the plotters of his death were much bigger unanswered questions. Some of these than the Muslims." Malcolm had what he were legal questions and some were considered sound reasons for this belief. larger, political questions. The standing The previous summer he had been legal verdict on the assassination holds poisoned in the main dining room of the that three men, forming a conspiracy, Cairo Hilton Hotel in Egypt. Malcolm were guilty of the act. And since two of was certain this was not the work of the the three were well-known Black Muslim Black Muslims; he had grounds for "enforcers," the public has accepted the attributing this attempt on his life to the obvious implication—that the murder was C.I.A. Less than two weeks before his ordered, planned, and carried out solely death, he was denied entry into France by the Black Muslims as the culmination forever as an "undesirable person," pos- of that group's vendetta against the apos- sibly because French officials feared he tate, Malcolm X. would be assassinated on French soil. Malcolm assumed that these signs of Alan Berger writes frequently for Seven danger were the inevitable consequence of Days.