LINGUISTICS: an INTRODUCTION Chapter 3: Phonology Sarah G
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
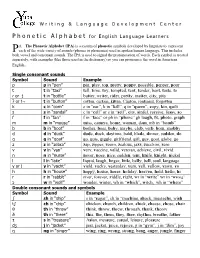
Writing & Language Development Center Phonetic Alphabet for English Language Learners Pin, Play, Top, Pretty, Poppy, Possibl
Writing & Language Development Center Phonetic Alphabet f o r English Language Learners A—The Phonetic Alphabet (IPA) is a system of phonetic symbols developed by linguists to represent P each of the wide variety of sounds (phones or phonemes) used in spoken human language. This includes both vowel and consonant sounds. The IPA is used to signal the pronunciation of words. Each symbol is treated separately, with examples (like those used in the dictionary) so you can pronounce the word in American English. Single consonant sounds Symbol Sound Example p p in “pen” pin, play, top, pretty, poppy, possible, pepper, pour t t in “taxi” tell, time, toy, tempted, tent, tender, bent, taste, to ɾ or ţ t in “bottle” butter, writer, rider, pretty, matter, city, pity ʔ or t¬ t in “button” cotton, curtain, kitten, Clinton, continent, forgotten k c in “corn” c in “car”, k in “kill”, q in “queen”, copy, kin, quilt s s in “sandal” c in “cell” or s in “sell”, city, sinful, receive, fussy, so f f in “fan” f in “face” or ph in “phone” gh laugh, fit, photo, graph m m in “mouse” miss, camera, home, woman, dam, mb in “bomb” b b in “boot” bother, boss, baby, maybe, club, verb, born, snobby d d in “duck” dude, duck, daytime, bald, blade, dinner, sudden, do g g in “goat” go, guts, giggle, girlfriend, gift, guy, goat, globe, go z z in “zebra” zap, zipper, zoom, zealous, jazz, zucchini, zero v v in “van” very, vaccine, valid, veteran, achieve, civil, vivid n n in “nurse” never, nose, nice, sudden, tent, knife, knight, nickel l l in “lake” liquid, laugh, linger, -

Part 1: Introduction to The
PREVIEW OF THE IPA HANDBOOK Handbook of the International Phonetic Association: A guide to the use of the International Phonetic Alphabet PARTI Introduction to the IPA 1. What is the International Phonetic Alphabet? The aim of the International Phonetic Association is to promote the scientific study of phonetics and the various practical applications of that science. For both these it is necessary to have a consistent way of representing the sounds of language in written form. From its foundation in 1886 the Association has been concerned to develop a system of notation which would be convenient to use, but comprehensive enough to cope with the wide variety of sounds found in the languages of the world; and to encourage the use of thjs notation as widely as possible among those concerned with language. The system is generally known as the International Phonetic Alphabet. Both the Association and its Alphabet are widely referred to by the abbreviation IPA, but here 'IPA' will be used only for the Alphabet. The IPA is based on the Roman alphabet, which has the advantage of being widely familiar, but also includes letters and additional symbols from a variety of other sources. These additions are necessary because the variety of sounds in languages is much greater than the number of letters in the Roman alphabet. The use of sequences of phonetic symbols to represent speech is known as transcription. The IPA can be used for many different purposes. For instance, it can be used as a way to show pronunciation in a dictionary, to record a language in linguistic fieldwork, to form the basis of a writing system for a language, or to annotate acoustic and other displays in the analysis of speech. -

An Acoustic Account of the Allophonic Realization of /T/ Amber King St
Linguistic Portfolios Volume 1 Article 12 2012 An Acoustic Account of the Allophonic Realization of /T/ Amber King St. Cloud State University Ettien Koffi St. Cloud State University Follow this and additional works at: https://repository.stcloudstate.edu/stcloud_ling Part of the Applied Linguistics Commons Recommended Citation King, Amber and Koffi, Ettien (2012) "An Acoustic Account of the Allophonic Realization of /T/," Linguistic Portfolios: Vol. 1 , Article 12. Available at: https://repository.stcloudstate.edu/stcloud_ling/vol1/iss1/12 This Article is brought to you for free and open access by theRepository at St. Cloud State. It has been accepted for inclusion in Linguistic Portfolios by an authorized editor of theRepository at St. Cloud State. For more information, please contact [email protected]. King and Koffi: An Acoustic Account of the Allophonic Realization of /T/ AN ACOUSTIC ACCOUNT OF THE ALLOPHONIC REALIZATIONS OF /T/ AMBER KING AND ETTIEN KOFFI 1.0 Introduction This paper is a laboratory phonology account of the different pronunciations of the phoneme /t/. Laboratory phonology is a relatively new analytical tool that is being used to validate and verify claims made by phonologists about the pronunciation of sounds. It is customary for phonologists to predict on the basis of auditory impressions and intuition alone that allophones exist for such and such phonemes. An allophone is defined as different realizations of the same phoneme based on the environments in which it occurs. For instance, it has been proposed that the phoneme /t/ has anywhere from four to eight allophones in General American English (GAE). To verify this claim Amber, one of the co-author of this paper recorded herself saying the words <still>, <Tim>, <kit>, <bitter>, <kitten>, <winter>, <fruition>, <furniture>, and <listen>. -

Phonemic Instability: a Butterfly Effect
PHONEMIC INSTABILITY: A BUTTERFLY EFFECT PAROMA SANYAL REENA ASHEM Indian Institute of Technology-Delhi, India 1xxIntroduction Can an imperceptibly tiny change in the relative ranking of a markedness constraint lead to phonemic instability and ultimately sound change in a language? In this paper we predict that this could indeed be the case when the phonological processes that take place within a certain morpho-phonological domain result in a particular phoneme being reinterpreted as marked by new learners of the language. According to McCarthy and Prince (1994), The Emergence of the Unmarked is a generalization about markedness constraints that are otherwise invisible in a language becoming visible in certain marked domains. While a markedness constraint C 'in the language as a whole, may be roundly violated, but in a particular domain it is obeyed exactly.' Now imagine the scenario where a markedness constraint C is ranked so low in the language that it is invisible for all practical purposes. However, when the satisfaction of a complex set of well-formedness constraints within a marked domain coincides with a systematic violation of C, it is possible for new learners of the language to re-rank C higher in the language. Thus the surface realization of phonological well-formedness conditions, if coincidentally localized to particular phonemes, rather than being distributed over a range of environments, could trigger phonemic instability and eventual sound change in the language. The Tibeto-Burman language Meiteilon, spoken in the state of Manipur in India, we claim, has a similar reanalysis taking place in its current phonological grammar. Meiteilon, like most other Tibeto-Burman languages of the region has rich inflectional morphology that attaches as suffixes to monosyllabic nominal or verbal roots. -

Introductory Phonology
3 More on Phonemes 3.1 Phonemic Analysis and Writing The question of phonemicization is in principle independent from the question of writing; that is, there is no necessary connection between letters and phonemes. For example, the English phoneme /e}/ can be spelled in quite a few ways: say /se}/, Abe /e}b/, main /me}n/, beige /be}è/, reggae /cryge}/, H /e}tà/. Indeed, there are languages (for example, Mandarin Chinese) that are written with symbols that do not correspond to phonemes at all. Obviously, there is at least a loose connection between alphabetic letters and phonemes: the designers of an alphabet tend to match up the written symbols with the phonemes of a language. Moreover, the conscious intuitions of speakers about sounds tend to be heavily influenced by their knowledge of spelling – after all, most literate speakers receive extensive training in how to spell during child- hood, but no training at all in phonology. Writing is prestigious, and our spoken pronunciations are sometimes felt to be imperfect realizations of what is written. This is reflected in the common occur- rence of spelling pronunciations, which are pronunciations that have no historical basis, but which arise as attempts to mimic the spelling, as in often [cÑftvn] or palm [pwlm]. In contrast, most linguists feel that spoken language is primary, and that written language is a derived system, which is mostly parasitic off the spoken language and is often rather artificial in character. Some reasons that support this view are that spoken language is far older than writing, it is acquired first and with greater ease by children, and it is the common property of our species, rather than of just an educated subset of it. -

Velar Segments in Old English and Old Irish
In: Jacek Fisiak (ed.) Proceedings of the Sixth International Conference on Historical Linguistics. Amsterdam: John Benjamins, 1985, 267-79. Velar segments in Old English and Old Irish Raymond Hickey University of Bonn The purpose of this paper is to look at a section of the phoneme inventories of the oldest attested stage of English and Irish, velar segments, to see how they are manifested phonetically and to consider how they relate to each other on the phonological level. The reason I have chosen to look at two languages is that it is precisely when one compares two language systems that one notices that structural differences between languages on one level will be correlated by differences on other levels demonstrating their interrelatedness. Furthermore it is necessary to view segments on a given level in relation to other segments. The group under consideration here is just one of several groups. Velar segments viewed within the phonological system of both Old English and Old Irish cor relate with three other major groups, defined by place of articulation: palatals, dentals, and labials. The relationship between these groups is not the same in each language for reasons which are morphological: in Old Irish changes in grammatical category are frequently indicated by palatalizing a final non-palatal segment (labial, dental, or velar). The same function in Old English is fulfilled by suffixes and /or prefixes. This has meant that for Old English the phonetically natural and lower-level alternation of velar elements with palatal elements in a palatal environ ment was to be found whereas in Old Irish this alternation had been denaturalized and had lost its automatic character. -

Comparative Analysis of American English and Mexican Spanish Consonants for Computer Assisted Pronunciation Training*
REVISTA SIGNOS. ESTUDIOS DE LINGÜÍSTICA ISSN 0718-0934 © 2017 PUCV, Chile DOI: 10.4067/S0718-09342017000200195 50(94) 195-216 Comparative analysis of American English and Mexican Spanish consonants for Computer Assisted Pronunciation Training* Análisis comparativo de las consonantes del inglés americano y español mexicano para la enseñanza de la pronunciación del inglés asistida por computadora Olga Kolesnikova INSTITUTO POLITÉCNICO NACIONAL MÉXICO [email protected] Recibido: 17-X-2014 / Aceptado: 30-VIII-2016 Abstract The objective of this work is two-fold. Firstly, we aim at detecting similarities and differences between the consonant systems of two languages, namely, American English and Mexican Spanish. To achieve this, we perform a theoretic comparative analysis of consonants of the two languages at the level of both phonemes and allophones. Secondly, a possible practical usage of our results is considered; therefore, as an example of an application, we consider computer-assisted pronunciation training (CAPT) for teaching American English pronunciation to Mexican Spanish speakers. In particular, we took advantage of the results of our analysis to define some hypothetic error patterns which can be used as a starting point for diagnosing possible mispronunciations, their posterior verification, and adjustment taking into account the principles of phonotactics and empirical phonetic analysis of the English learners’ speech. The latter will result in error rules to be applied in a CAPT system for error identification and generation of appropriate corrective feedback. An adequate choice of correcting techniques will improve English pronunciation acquisition and help learners to develop less accented speech. Also, similarities found between the two consonant systems make it possible to organize and present the pronunciation teaching material using a stress-free method of helping learners to adjust their speech organs to new sounds building on the phonetic habits of their first language. -

Studies in African Linguistics Volume 21, Number 3, December 1990
Studies in African Linguistics Volume 21, Number 3, December 1990 CONTEXTUAL LABIALIZATION IN NA WURI* Roderic F. Casali Ghana Institute of Linguistics Literacy and Bible Translation and UCLA A spectrographic investigation into the non-contrastive labialization of consonants before round vowels in Nawuri (a Kwa language of Ghana) sup ports the notion that this labialization is the result of a phonological, feature spreading rule and not simply an automatic transitional process. This as sumption is further warranted in that it allows for a more natural treatment of some other phonological processes in the language. The fact that labial ization before round vowels is generally not very audible is explained in terms of a principle of speech perception. A final topic addressed is the question of why (both in Nawuri and apparently in a number of other Ghanaian languages as well) contextual labialization does tend to be more perceptible in certain restricted environments. o. Introduction This paper deals with the allophonic labialization of consonants before round vowels in Nawuri, a Kwa language of Ghana.! While such labialization is gener ally not very audible, spectrographic evidence suggests that it is strongly present, * The spectrograms in this study were produced at the phonetics lab of the University of Texas at Arlington using equipment provided through a grant of the Permanent University Fund of the University of Texas system. I would like to thank the following people for their valuable comments and suggestions: Joan Baart, Don Burquest, Mike Cahill, Jerry Edmondson, Norris McKinney, Bob Mugele, Tony Naden, and Keith Snider. I would also like to express my appreciation to Russell Schuh and an anonymous referee for this journal for their helpful criticism of an earlier version, and to Mary Steele for some helpful discussion concerning labialization in Konkomba. -

FACTORS AFFECTING PROFICIENCY AMONG GUJARATI HERITAGE LANGUAGE LEARNERS on THREE CONTINENTS a Dissertation Submitted to the Facu
FACTORS AFFECTING PROFICIENCY AMONG GUJARATI HERITAGE LANGUAGE LEARNERS ON THREE CONTINENTS A Dissertation submitted to the Faculty of the Graduate School of Arts and Sciences of Georgetown University in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Linguistics By Sheena Shah, M.S. Washington, DC May 14, 2013 Copyright 2013 by Sheena Shah All Rights Reserved ii FACTORS AFFECTING PROFICIENCY AMONG GUJARATI HERITAGE LANGUAGE LEARNERS ON THREE CONTINENTS Sheena Shah, M.S. Thesis Advisors: Alison Mackey, Ph.D. Natalie Schilling, Ph.D. ABSTRACT This dissertation examines the causes behind the differences in proficiency in the North Indian language Gujarati among heritage learners of Gujarati in three diaspora locations. In particular, I focus on whether there is a relationship between heritage language ability and ethnic and cultural identity. Previous studies have reported divergent findings. Some have found a positive relationship (e.g., Cho, 2000; Kang & Kim, 2011; Phinney, Romero, Nava, & Huang, 2001; Soto, 2002), whereas others found no correlation (e.g., C. L. Brown, 2009; Jo, 2001; Smolicz, 1992), or identified only a partial relationship (e.g., Mah, 2005). Only a few studies have addressed this question by studying one community in different transnational locations (see, for example, Canagarajah, 2008, 2012a, 2012b). The current study addresses this matter by examining data from members of the same ethnic group in similar educational settings in three multi-ethnic and multilingual cities. The results of this study are based on a survey consisting of questionnaires, semi-structured interviews, and proficiency tests with 135 participants. Participants are Gujarati heritage language learners from the U.K., Singapore, and South Africa, who are either current students or recent graduates of a Gujarati School. -

Phones and Phonemes
NLPA-Phon1 (4/10/07) © P. Coxhead, 2006 Page 1 Natural Language Processing & Applications Phones and Phonemes 1 Phonemes If we are to understand how speech might be generated or recognized by a computer, we need to study some of the underlying linguistic theory. The aim here is to UNDERSTAND the theory rather than memorize it. I’ve tried to reduce and simplify as much as possible without serious inaccuracy. Speech consists of sequences of sounds. The use of an instrument (such as a speech spectro- graph) shows that most of normal speech consists of continuous sounds, both within words and across word boundaries. Speakers of a language can easily dissect its continuous sounds into words. With more difficulty, they can split words into component sounds, or ‘segments’. However, it is not always clear where to stop splitting. In the word strip, for example, should the sound represented by the letters str be treated as a unit, be split into the two sounds represented by st and r, or be split into the three sounds represented by s, t and r? One approach to isolating component sounds is to look for ‘distinctive unit sounds’ or phonemes.1 For example, three phonemes can be distinguished in the word cat, corresponding to the letters c, a and t (but of course English spelling is notoriously non- phonemic so correspondence of phonemes and letters should not be expected). How do we know that these three are ‘distinctive unit sounds’ or phonemes of the English language? NOT from the sounds themselves. A speech spectrograph will not show a neat division of the sound of the word cat into three parts. -

English Teachers' Mastery of the English Aspiration And
Arina Isti’anah - English Teachers’ Mastery of the English Aspiration and Stress Rules ENGLISH TEACHERS’ MASTERY OF THE ENGLISH ASPIRATION AND STRESS RULES Arina Isti’anah Sanata Dharma University [email protected] Abstract This paper tries to observe the English teachers’ awareness and representation of the English aspiration and stress rules. The research purposes to find out whether or not the teachers are aware of the English aspiration and stress rules, and to find out how the teachers represent the English aspiration and stress rules. Based on the analysis, it can be concluded that the teachers’ awareness of the English aspiration and stress rules is very low. It is indicated with the percentage which equals to 44% and 48% for English aspiration and stress rules. In representing the English aspiration and stress rules, the teachers face the problems in producing aspiration in the pronunciation, placing the right stress and pronouncing three and four X in the coda position. There are two reasons affecting the teachers’ awareness of the English aspiration and stress rules namely exposure and L1 influence. Artikel ini bertujuan untuk meneliti kesadaran dan representasi aturan aspirasi dan tekanan oleh guru bahasa Inggris. Penelitian ini bertujuan untuk menjelaskan apakah guru bahasa Inggris mempunyai kesadaran atas aturan aspirasi dan tekanan dalam bahasa Inggris, dan untuk menunjukkan bagaimana guru Bahasa Inggris mewujudkan aturan aspirasi dan tekanan dalam pelafalan mereka. Berdasarkan analisis yang dilakukan, dapat disimpulkan bahwa kesadaran guru Bahasa Inggris atas aturan aspirasi dan tekanan dalam Bahasa Inggris masih sangat rendah. Hal tersebut ditunjukkan oleh rendahnya prosentase dalam perwujudan aturan aspirasi dan tekanan: 44% dan 48%. -

A Deep Generative Model of Vowel Formant Typology
A Deep Generative Model of Vowel Formant Typology Ryan Cotterell and Jason Eisner Department of Computer Science Johns Hopkins University, Baltimore MD, 21218 ryan.cotterell,eisner @jhu.edu { } Abstract and its goal should be the construction of a univer- sal prior over potential languages. A probabilistic What makes some types of languages more approach does not rule out linguistic systems com- probable than others? For instance, we know pletely (as long as one’s theoretical formalism can that almost all spoken languages contain the vowel phoneme /i/; why should that be? The describe them at all), but it can position phenomena field of linguistic typology seeks to answer on a scale from very common to very improbable. these questions and, thereby, divine the mech- Probabilistic modeling also provides a discipline anisms that underlie human language. In our for drawing conclusions from sparse data. While work, we tackle the problem of vowel system we know of over 7000 human languages, we have typology, i.e., we propose a generative proba- some sort of linguistic analysis for only 2300 of bility model of which vowels a language con- them (Comrie et al., 2013), and the dataset used in tains. In contrast to previous work, we work di- rectly with the acoustic information—the first this paper (Becker-Kristal, 2010) provides simple two formant values—rather than modeling dis- vowel data for fewer than 250 languages. crete sets of phonemic symbols (IPA). We de- Formants are the resonant frequencies of the hu- velop a novel generative probability model and man vocal tract during the production of speech report results based on a corpus of 233 lan- sounds.