1 Video Signal Processors
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Reviving the Development of Openchrome
Reviving the Development of OpenChrome Kevin Brace OpenChrome Project Maintainer / Developer XDC2017 September 21st, 2017 Outline ● About Me ● My Personal Story Behind OpenChrome ● Background on VIA Chrome Hardware ● The History of OpenChrome Project ● Past Releases ● Observations about Standby Resume ● Developmental Philosophy ● Developmental Challenges ● Strategies for Further Development ● Future Plans 09/21/2017 XDC2017 2 About Me ● EE (Electrical Engineering) background (B.S.E.E.) who specialized in digital design / computer architecture in college (pretty much the only undergraduate student “still” doing this stuff where I attended college) ● Graduated recently ● First time conference presenter ● Very experienced with Xilinx FPGA (Spartan-II through 7 Series FPGA) ● Fluent in Verilog / VHDL design and verification ● Interest / design experience with external communication interfaces (PCI / PCIe) and external memory interfaces (SDRAM / DDR3 SDRAM) ● Developed a simple DMA engine for PCI I/F validation w/Windows WDM (Windows Driver Model) kernel device driver ● Almost all the knowledge I have is self taught (university engineering classes were not very useful) 09/21/2017 XDC2017 3 Motivations Behind My Work ● General difficulty in obtaining meaningful employment in the digital hardware design field (too many students in the field, difficulty obtaining internship, etc.) ● Collects and repairs abandoned computer hardware (It’s like rescuing puppies!) ● Owns 100+ desktop computers and 20+ laptop computers (mostly abandoned old stuff I -

GPU Developments 2018
GPU Developments 2018 2018 GPU Developments 2018 © Copyright Jon Peddie Research 2019. All rights reserved. Reproduction in whole or in part is prohibited without written permission from Jon Peddie Research. This report is the property of Jon Peddie Research (JPR) and made available to a restricted number of clients only upon these terms and conditions. Agreement not to copy or disclose. This report and all future reports or other materials provided by JPR pursuant to this subscription (collectively, “Reports”) are protected by: (i) federal copyright, pursuant to the Copyright Act of 1976; and (ii) the nondisclosure provisions set forth immediately following. License, exclusive use, and agreement not to disclose. Reports are the trade secret property exclusively of JPR and are made available to a restricted number of clients, for their exclusive use and only upon the following terms and conditions. JPR grants site-wide license to read and utilize the information in the Reports, exclusively to the initial subscriber to the Reports, its subsidiaries, divisions, and employees (collectively, “Subscriber”). The Reports shall, at all times, be treated by Subscriber as proprietary and confidential documents, for internal use only. Subscriber agrees that it will not reproduce for or share any of the material in the Reports (“Material”) with any entity or individual other than Subscriber (“Shared Third Party”) (collectively, “Share” or “Sharing”), without the advance written permission of JPR. Subscriber shall be liable for any breach of this agreement and shall be subject to cancellation of its subscription to Reports. Without limiting this liability, Subscriber shall be liable for any damages suffered by JPR as a result of any Sharing of any Material, without advance written permission of JPR. -

EDN Magazine, December 17, 2004 (.Pdf)
ᮋ HE BEST 100 PRODUCTS OF 2004 encompass a range of architectures and technologies Tand a plethora of categories—from analog ICs to multimedia to test-and-measurement tools. All are innovative, but, of the thousands that manufacturers announce each year and the hundreds that EDN reports on, only about 100 hot products make our readers re- ally sit up and take notice. Here are the picks from this year's crop. We present the basic info here. To get the whole scoop and find out why these products are so compelling, go to the Web version of this article on our Web site at www.edn.com. There, you'll find links to the full text of the articles that cover these products' dazzling features. ANALOG ICs Power Integrations COMMUNICATIONS NetLogic Microsystems Analog Devices LNK306P Atheros Communications NSE5512GLQ network AD1954 audio DAC switching power converter AR5005 Wi-Fi chip sets search engine www.analog.com www.powerint.com www.atheros.com www.netlogicmicro.com D2Audio Texas Instruments Fulcrum Microsystems Parama Networks XR125 seven-channel VCA8613 FM1010 six-port SPI-4,2 PNI8040 add-drop module eight-channel VGA switch chip multiplexer www.d2audio.com www.ti.com www.fulcrummicro.com www.paramanet.com International Rectifier Wolfson Microelectronics Motia PMC-Sierra IR2520D CFL ballast WM8740 audio DAC Javelin smart-antenna IC MSP2015, 2020, 4000, and power controller www.wolfsonmicro.com www.motia.com 5000 VoIP gateway chips www.irf.com www.pmc-sierra.com www.edn.com December 17, 2004 | edn 29 100 Texas Instruments Intel DISCRETE SEMICONDUCTORS -

Program Review Department of Computer Science
PROGRAM REVIEW DEPARTMENT OF COMPUTER SCIENCE UNIVERSITY OF NORTH CAROLINA AT CHAPEL HILL JANUARY 13-15, 2009 TABLE OF CONTENTS 1 Introduction............................................................................................................................. 1 2 Program Overview.................................................................................................................. 2 2.1 Mission........................................................................................................................... 2 2.2 Demand.......................................................................................................................... 3 2.3 Interdisciplinary activities and outreach ........................................................................ 5 2.4 Inter-institutional perspective ........................................................................................ 6 2.5 Previous evaluations ...................................................................................................... 6 3 Curricula ................................................................................................................................. 8 3.1 Undergraduate Curriculum ............................................................................................ 8 3.1.1 Bachelor of Science ................................................................................................. 10 3.1.2 Bachelor of Arts (proposed) ................................................................................... -

Linux Hardware Compatibility HOWTO
Linux Hardware Compatibility HOWTO Steven Pritchard Southern Illinois Linux Users Group [email protected] 3.1.5 Copyright © 2001−2002 by Steven Pritchard Copyright © 1997−1999 by Patrick Reijnen 2002−03−28 This document attempts to list most of the hardware known to be either supported or unsupported under Linux. Linux Hardware Compatibility HOWTO Table of Contents 1. Introduction.....................................................................................................................................................1 1.1. Notes on binary−only drivers...........................................................................................................1 1.2. Notes on commercial drivers............................................................................................................1 1.3. System architectures.........................................................................................................................1 1.4. Related sources of information.........................................................................................................2 1.5. Known problems with this document...............................................................................................2 1.6. New versions of this document.........................................................................................................2 1.7. Feedback and corrections..................................................................................................................3 1.8. Acknowledgments.............................................................................................................................3 -

Computer Architectures an Overview
Computer Architectures An Overview PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 25 Feb 2012 22:35:32 UTC Contents Articles Microarchitecture 1 x86 7 PowerPC 23 IBM POWER 33 MIPS architecture 39 SPARC 57 ARM architecture 65 DEC Alpha 80 AlphaStation 92 AlphaServer 95 Very long instruction word 103 Instruction-level parallelism 107 Explicitly parallel instruction computing 108 References Article Sources and Contributors 111 Image Sources, Licenses and Contributors 113 Article Licenses License 114 Microarchitecture 1 Microarchitecture In computer engineering, microarchitecture (sometimes abbreviated to µarch or uarch), also called computer organization, is the way a given instruction set architecture (ISA) is implemented on a processor. A given ISA may be implemented with different microarchitectures.[1] Implementations might vary due to different goals of a given design or due to shifts in technology.[2] Computer architecture is the combination of microarchitecture and instruction set design. Relation to instruction set architecture The ISA is roughly the same as the programming model of a processor as seen by an assembly language programmer or compiler writer. The ISA includes the execution model, processor registers, address and data formats among other things. The Intel Core microarchitecture microarchitecture includes the constituent parts of the processor and how these interconnect and interoperate to implement the ISA. The microarchitecture of a machine is usually represented as (more or less detailed) diagrams that describe the interconnections of the various microarchitectural elements of the machine, which may be everything from single gates and registers, to complete arithmetic logic units (ALU)s and even larger elements. -

The Opengl ES Shading Language
The OpenGL ES® Shading Language Language Version: 3.00 Document Revision: 6 29 January 2016 Editor: Robert J. Simpson, Qualcomm OpenGL GLSL editor: John Kessenich, LunarG GLSL version 1.1 Authors: John Kessenich, Dave Baldwin, Randi Rost Copyright © 2008-2016 The Khronos Group Inc. All Rights Reserved. This specification is protected by copyright laws and contains material proprietary to the Khronos Group, Inc. It or any components may not be reproduced, republished, distributed, transmitted, displayed, broadcast, or otherwise exploited in any manner without the express prior written permission of Khronos Group. You may use this specification for implementing the functionality therein, without altering or removing any trademark, copyright or other notice from the specification, but the receipt or possession of this specification does not convey any rights to reproduce, disclose, or distribute its contents, or to manufacture, use, or sell anything that it may describe, in whole or in part. Khronos Group grants express permission to any current Promoter, Contributor or Adopter member of Khronos to copy and redistribute UNMODIFIED versions of this specification in any fashion, provided that NO CHARGE is made for the specification and the latest available update of the specification for any version of the API is used whenever possible. Such distributed specification may be reformatted AS LONG AS the contents of the specification are not changed in any way. The specification may be incorporated into a product that is sold as long as such product includes significant independent work developed by the seller. A link to the current version of this specification on the Khronos Group website should be included whenever possible with specification distributions. -

Semiconductor Industry Merger and Acquisition Activity from an Intellectual Property and Technology Maturity Perspective
Semiconductor Industry Merger and Acquisition Activity from an Intellectual Property and Technology Maturity Perspective by James T. Pennington B.S. Mechanical Engineering (2011) University of Pittsburgh Submitted to the System Design and Management Program in Partial Fulfillment of the Requirements for the Degree of Master of Science in Engineering and Management at the Massachusetts Institute of Technology September 2020 © 2020 James T. Pennington All rights reserved The author hereby grants to MIT permission to reproduce and to distribute publicly paper and electronic copies of this thesis document in whole or in part in any medium now known or hereafter created. Signature of Author ____________________________________________________________________ System Design and Management Program August 7, 2020 Certified by __________________________________________________________________________ Bruce G. Cameron Thesis Supervisor System Architecture Group Director in System Design and Management Accepted by __________________________________________________________________________ Joan Rubin Executive Director, System Design & Management Program THIS PAGE INTENTIALLY LEFT BLANK 2 Semiconductor Industry Merger and Acquisition Activity from an Intellectual Property and Technology Maturity Perspective by James T. Pennington Submitted to the System Design and Management Program on August 7, 2020 in Partial Fulfillment of the Requirements for the Degree of Master of Science in System Design and Management ABSTRACT A major method of acquiring the rights to technology is through the procurement of intellectual property (IP), which allow companies to both extend their technological advantage while denying it to others. Public databases such as the United States Patent and Trademark Office (USPTO) track this exchange of technology rights. Thus, IP can be used as a public measure of value accumulation in the form of technology rights. -

Oxygentm ACX Graphics Accelerator User’S Guide
The OxygenTM ACX Graphics Accelerator User’s Guide 3Dlabs,® Inc. 480 Potrero Avenue Sunnyvale, CA 94086 408 - 530 - 4700 www.3dlabs.com Copyright 1999 by 3Dlabs, Inc. 3Dlabs and Permedia are registered trademarks, and Oxygen is a trademark of 3Dlabs, Inc. or 3Dlabs Inc. Ltd. Pentium is a registered trademark of Intel. OpenGL is a registered trademark of Silicon Graphics, Inc. Soft Engine is a trademark of Vibrant Graphics, Inc. AutoCAD is a registered trademark of AutoDesk Inc. Microsoft and Windows NT are registered trademarks of the Microsoft Corporation. All other trademarks and registered trademarks are the property of their respective holders. Caution: Changes or modifications to the Oxygen ACX graphics accelerator card not expressly approved by 3Dlabs, Inc. void the user’s warranty. FCC Notice: This equipment has been tested and found to comply with the limits for a Class B digital device, pursuant to Part 15 of the FCC Rules. These limits are designed to provide reasonable protection against harmful interference in a residential installation. This equipment generates, uses, and can radiate radio frequency energy. If product is not installed and used in accordance with the instruction manual, it may cause harmful interference to radio communications; however, there is no guarantee that interference will not occur in a particular installation. If this equipment does cause harmful interference to radio or television reception, which can be determined by turning the equipment off and on, the user is encouraged to try to correct the interference by one or more of the following measures: 1. Re-orient or relocate the receiving antenna. -

The Oxygentm VX1 Oxygentm GVX1 Graphics Accelerator
The OxygenTM VX1 and OxygenTM GVX1 Graphics Accelerator User’s Guide 3Dlabs,® Inc. 480 Potrero Avenue Sunnyvale, CA 94086 408 - 530 - 4700 www.3dlabs.com Copyright 1999 by 3Dlabs, Inc. 3Dlabs, GLINT and Permedia are registered trademarks, and Oxygen and PowerThreads are trademarks of 3Dlabs, Inc. or 3Dlabs Inc. Ltd. Pentium is a registered trademark of Intel. OpenGL is a registered trademark of Silicon Graphics, Inc. Soft Engine is a trademark of Vibrant Graphics, Inc. AutoCAD is a registered trademark of AutoDesk Inc. Colorific is a registered trademark of Sonnetech Ltd. Microsoft and Windows NT are registered trademarks of the Microsoft Corporation. All other trademarks and registered trademarks are the property of their respective holders. Caution: Changes or modifications to the Oxygen VX1 or Oxygen GVX1 graphics accelerator card not expressly approved by 3Dlabs, Inc. void the user’s warranty. FCC Notice: This equipment has been tested and found to comply with the limits for a Class B digital device, pursuant to Part 15 of the FCC Rules. These limits are designed to provide reasonable protection against harmful interference in a residential installation. This equipment generates, uses, and can radiate radio frequency energy. If product is not installed and used in accordance with the instruction manual, it may cause harmful interference to radio communications; however, there is no guarantee that interference will not occur in a particular installation. If this equipment does cause harmful interference to radio or television reception, which can be determined by turning the equipment off and on, the user is encouraged to try to correct the interference by one or more of the following measures: 1. -
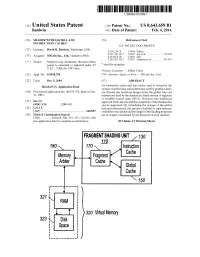
320 Virtual Memory
USOO864.3659B1 (12) United States Patent (10) Patent No.: US 8,643,659 B1 Baldwin (45) Date of Patent: Feb. 4, 2014 (54) SHADER WITH GLOBAL AND (56) References Cited INSTRUCTION CACHES U.S. PATENT DOCUMENTS (75) Inventor: David R. Baldwin, Weybridge (GB) 4,928,224. A 5/1990 Zulian (73) Assignee: 3DLabs Inc., Ltd., Hamilton (BM) 3. R ck 58. yet al. ....................... T12/228 7.245,302 B1* 7/2007 Donham et al. .............. 345,519 (*) Notice: Subject to any disclaimer, the term of this patent is extended or adjusted under 35 * cited by examiner U.S.C. 154(b) by 1387 days. Primary Examiner — Jeffrey Chow (21) Appl. No.: 10/958,758 (74) Attorney, Agent, or Firm — 3DLabs Inc., Ltd. (22) Filed: Oct. 5, 2004 (57) ABSTRACT O O An instruction cache and data cache used to virtualize the Related U.S. Application Data storage of global data and instructions used by graphics shad (60) Provisional application No. 60/533,532, filed on Dec. ers. Present day hardware design stores the global data and 31, 2003. instructions used by the shaders in a fixed amount of registers or writable control store (WCS). However, this traditional (51) Int. Cl. approach limits the size and the complexity of the shaders that G09G 5/36 (2006.01) can be supported. By virtualizing the storage of the global (52) U.S. Cl. data and instructions, the amount of global or state memory USPC - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - 345/557 available tO the shader and the length of the shading programs (58) Field of Classification Search are no longer constrained by the physical on-chip memory. -

• Leading Opengl® and Direct3d® Performance • Dual Independent
d 560 • Leading OpenGL® and Direct3D® performance • Dual independent highresolution displays • Full 3Dlabs® Acuity™ Driver Suite • Fully compatible with the Wildcat VP family • Professionalgrade reliability and quality Visual Processing Architecture 3Dlabs Acuity™ Driver Suite Wildcat VP560 uses 3Dlabs’ groundbreaking Visual The new, unified 3Dlabs Acuity Driver Suite runs across Processing Architecture to provide industrialstrength the entire Wildcat VP family and includes highly 2D and 3D performance, quality and functionality for optimized OpenGL and Direct3D drivers, a customized OpenGL and Direct3D applications for unmatched driver for 3D Studio Max and the new 3Dlabs Acuity graphics productivity. Window Manager that provides precision window control over multiple displays. Enhanced Dual-head Display Designed by Professionals for Professionals Wildcat VP560 directly drives two independent, high- 3Dlabs is the only PC graphics company solely focused resolution digital displays. An adaptor is included to on designing professionalgrade accelerators. Wildcat drive an analog display and a second analog adaptor VP560 is a part of the Wildcat VP family that continues is available freeofcharge from 3Dlabs for dual this tradition through relentless driver reliability testing analog output. Dual 10bit DACs provide flawless and constant optimization and certification of leading color representation by eliminating distracting display professional applications. artifacts. 100% Programmability Genuine programmability throughout the entire Wildcat VP560 pipeline provides a superset of traditional graphics processor functionality. Support for emerging highlevel shading languages, such as OpenGL 2.0 and Microsoft HLSL, will enable Wildcat VP560 to support new generation advanced authoring applications. High Performance Virtual Memory The highly innovative 16GB virtual memory of Wildcat VP560 shatters the limitation of onboard memory by automatically handling huge datasets, while caching essential data for fastest access.