Samsung Galaxy Note7 Fiasco Twitter Sentiment Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Contacting Dbx Technical Support
v1.0 25-Aug-21 My dbx product has developed a fault or I have a question about a product which I have purchased or perhaps intend to purchase. Who do I contact? The information below is applicable to products from dbx. Support for Harman Consumer products can be found at https://harmanaudio.com. Support for Harman Luxury products can be found at https://harmanluxuryaudio.com. USA Customers who have purchased a product in the USA or have a question about a product which they perhaps intend to purchase in the USA are supported directly by Harman Professional. Support contact information can be found at https://dbxpro.com/support/tech_support. This page contains a web-form where you can enter your contact details and query. Outside the USA Support outside of the USA is provided by Harman Professional distribution partners. These partners are responsible for sales, spare parts, repairs, technical support and general product queries. They will be able to provide assistance within local time-zone working hours for the territory. Distribution partner contact information can be obtained from https://dbxpro.com/support/tech_support after selecting your country from the drop-down selection box found at the top of the webpage. If a product develops a fault during the warranty period then please contact the point of sale (retailer or web-store). Warranty information can be found at https://dbxpro.com/warranty. About HARMAN Professional Solutions HARMAN Professional Solutions is the world’s largest professional audio, video, lighting, and control products and systems company. Our brands comprise AKG Acoustics®, AMX®, BSS Audio®, Crown International®, dbx Professional®, DigiTech®, JBL Professional®, Lexicon Pro®, Martin®, and Soundcraft®. -

Erp Modernization & Consolidation
ERP MODERNIZATION & CONSOLIDATION CASE STUDY CUSTOMER CONTEXT SUMMARY A global industrial manufacturing company was • Templatized implementation & rollout approach for rapid implementation running a legacy ERP for critical operations in supply across 54 entities in 26 months. chain, financial controlling & management incurring increasing maintenance costs & bandaging huge • ‘Process Templates’ for standardizations & synergies across processes. customization components to cover the process gaps • Optimal resources alignment in onshore-offshore mix with technical & making the adoption of a modern ERP challenges. business functions stream. PROJECT BACKGROUND SOLUTION BENEFITS • Project planned for 54 distinct entities across • Single Source of Truth across demand planning & forecasting, supply chain 22 countries. operations & financial controlling & management. • Plans executed for complex organizational • Consolidation of multiple manufacturing modes of process, discrete, structure of customer teams across entity configure to order, made to order, engineer to order. locations & shared-services based on operational • Seamless integration of B2B order management system with SAP Hybris. streams of ‘factory’, ‘distribution’, ‘sales’ & ‘finance’. PARTNER WITH AN INDUSTRY EXPERT • Integrated execution of sunsetting 5 ERP systems HARMAN (harman.com) designs and engineers & multiple satellite applications on a single ERP TOOLS / TECHNOLOGIES connected products and solutions for automakers, platform delivering post-modern application consumers, -
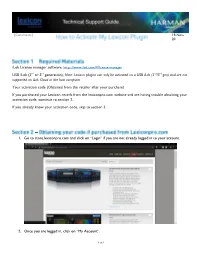
How to Activate My Lexicon Plugin.Pdf
[Comments] 19-Nov- 20 iLok License manager software: https://www.ilok.com/#!license-manager USB iLok (2nd or 3rd generation), Note: Lexicon plugins can only be activated on a USB iLok (2nd/3rd gen) and are not supported on iLok Cloud or the host computer. Your activation code (Obtained from the retailer after your purchase) If you purchased your Lexicon reverb from the lexiconpro.com website and are having trouble obtaining your activation code, continue to section 2. If you already know your activation code, skip to section 3. 1. Go to store.lexiconpro.com and click on “Login” if you are not already logged in to your account. 2. Once you are logged in, click on “My Account”. 1 of 7 3. Click on “Order History”. 4. Click on the order number for the specific order. 5. On the order, look for “iLok Authentication Key”. It should show the activation code below that. If it shows a yellow/orange button instead, then click on that to reveal the code. Copy this number. 2 of 7 3 of 7 1. Once you have your activation code, open iLok License Manager. Sign into your iLok account. 2. From the top tab, click on “Licenses”, then “Redeem Activation Code”. 4 of 7 3. Type or paste your code into the entry field, then hit “next” to finalize the redemption process. 1. Once the plugin code has been redeemed in iLok License Manager, the plugin should appear in your list of licenses. If you don’t see this, then click on the box that shows your username. -

Contacting Lexicon Professional Support
v1.0 26-Aug-21 My Lexicon Professional product has developed a fault or I have a question about a product which I have purchased or perhaps intend to purchase. Who do I contact? The information below is applicable to products from Lexicon Professional. Support for Harman Consumer products can be found at https://harmanaudio.com. Support for Harman Luxury products can be found at https://harmanluxuryaudio.com. USA Customers who have purchased a product in the USA or have a question about a product which they perhaps intend to purchase in the USA are supported directly by Harman Professional. Support contact information can be found at https://lexiconpro.com/support/tech_support. This page contains a web- form where you can enter your contact details and query. Outside the USA Support outside of the USA is provided by Harman Professional distribution partners. These partners are responsible for sales, spare parts, repairs, technical support and general product queries. They will be able to provide assistance within local time-zone working hours for the territory. Distribution partner contact information can be obtained from https://lexiconpro.com/support/tech_support after selecting your country from the drop-down selection box found at the top of the webpage. If a product develops a fault during the warranty period then please contact the point of sale (retailer or web-store). Warranty information can be found at https://lexiconpro.com/warranty. About HARMAN Professional Solutions HARMAN Professional Solutions is the world’s largest professional audio, video, lighting, and control products and systems company. Our brands comprise AKG Acoustics®, AMX®, BSS Audio®, Crown International®, dbx Professional®, DigiTech®, JBL Professional®, Lexicon Pro®, Martin®, and Soundcraft®. -

RV-5 User Guide
RV-5 Receiver User Guide IMPORTANT SAFETY INSTRUCTIONS 1. Read these instructions. the cart/apparatus combination to avoid injury frequency energy and, if not installed and used in 2. Keep these instructions. from tip-over. accordance with the instructions, may cause 3. Heed all warnings. 13. Unplug this apparatus during lightning storms or harmful interference to radio or television when unused for long periods of time. reception, which can be determined by turning the 4. Follow all instructions. 14. Refer all servicing to qualified service personnel. equipment off and on. The user is encouraged to try 5. Do not use this apparatus near water. Servicing is required when the apparatus has to correct the interference by one or more of the 6. Clean only with a dry cloth. been damaged in any way, such as when a power following measures: 7. Do not block any ventilation openings. Install in supply cord or plug is damaged, liquid has been • Re-orient or relocate the receiving antenna. accordance with the manufacturer’s instructions. spilled or objects have fallen into the apparatus, • Increase the separation between the equipment and 8. Do not install near any heat sources such as the apparatus has been exposed to rain or the receiver. radiators, heat registers, stoves, or other moisture, does not operate normally, or has been apparatus (including amplifiers) that produce dropped. • Connect the equipment into an outlet on a circuit heat. 15. Do not expose this apparatus to dripping or different from that to which the receiver is connected. 9. Do not defeat the safety purpose of the polarized splashing and ensure that no objects filled with or grounding-type plug. -

Welcome to Post-COVID World | Digitalization to Dominate Tech Industry
Welcome To The Musk Continues To Ride Post-Covid World High With Tesla-SpaceX `125 VOL. 33 | ISSUE 12 | DECEMBER 2020 PCQUEST How To Buy The u Greatest DE Gadgets C EMBER 2020 For Your www.pcquest.com New Year UNDERSTAND • CHOOSE • IMPLEMENT IT u A Goldmine CCOVID-19OVID-19 & TTECHECH 22020020 T We arree aalreadlready llivingiving iinn an uuppggrraadeded NNeew NNormalormal hat’s Waiting For Columbus, Not For M idas u Cyber S ecurity Job R oles T o Watch Out For In 2021 Special Subscription offer on page 42 76 pages including cover When Even The Brick — Christof Domenig The 6 Essential Rules Of — Shahid Nizami CEO MD-APAC CBecame Smart oWienerberger Global nBeing A Businesst DisruptoreHubSpot nts `125 VOL. 33 | ISSUE 1 | JANUARY 2020 PCQUEST DATA/CLOUD 8-18 COVER STORY — YEARENDER The Importance Of Intelligent Transformation u JANUARY 2020 www.pcquest.com — Vivek Sharma UNDERSTAND • CHOOSE • IMPLEMENT IT MD—India P8 A GREAT YEAR LenovoFOR DCG TECHNOLOGY While the Covid-19 u Personalized pandemic-lockdown- recession was really tragic, E xperince DDIGITALIGITAL AACCELERATIONCCELERATION Toopp ttrendsrends fforor tthehe NNeew Yeeaar the real silver lining was the T hrough Intelligent Digital Workspace way technology stood up, accelerated and filled in the vacuum so that mankind could not only cope, but u R e-Imagining Business look forward to boot. We are entering a brand new T era which we are still hrough A struggling to define and I- R P A predict what it will actually be like. Terms like “New Special Subscription offer on page 58 76 pages -

Remote-Controlled Digital Mixer Any Device
Ui12 Ui16 Hardware Form Floor Floor/Rack Wi-Fi Router Onboard Yes Yes Ethernet control Yes Yes Total Inputs 12 16 XLR Mic Inputs 4 Mic/Line, 4 Mic 8 Mic/Line, 4 Mic Hi-Z/instrument channels 2 2 Main Outputs XLR and 1/4” XLR and 1/4” Aux / Monitor Sends 4 balanced XLR 6 balanced XLR USB Playback 2-channel 2-channel USB Stereo Recording 2-channel 2-channel HDMI Output No Yes Headphone 1/4” out 2 2 Stereo RCA Line input Yes Yes Includes Soundcraft, Harman International Industries Ltd., Cranborne House, Cranborne Road, Potters Bar, Hertfordshire EN6 3JN, UK T: +44 (0)1707 665000 F: +44 (0)1707 660742 E: [email protected] Soundcraft USA, 8500 Balboa Boulevard, Northridge, CA 91329, USA T: +1-818-893-8411 F: +1-818-920-3208 E: [email protected] www.soundcraft.com Part No: 5055926 E & OE 01/2015 Remote-Controlled Digital Mixer Any device. Anywhere. The freedom to mix. Key features • Tablet/PC/Smartphone Controlled Digital Mixer • Integrated Wi-Fi • Cross-platform compatibility with iOS, Android, Windows, Mac OS, and Linux devices • Use up to 10 control devices (tablets, phones, PCs) simultaneously • Legendary Harman Signal Processing from dbx®, Digitech®, and Lexicon® • Fully recallable and remote-controlled mic preamps • 4-band Parametric EQ, High-Pass Filter, Compressor, De-esser and Noise Gate on input channels • 31-band Graphic EQ, Noise Gate and Compressor on all outputs • Real-Time Frequency Analyser (RTA) on inputs and outputs • 3 dedicated Lexicon FX effects processors: Reverb, Delay and Chorus (4 on Ui16) • Subgroups, Mute Groups, View Groups, and more mixer controls • Show/Snapshot recall with channel safes and security lockout • 2-channel USB audio playback and recording • dbx AFS2 on all outputs Ui. -

Harman International Announces New Collaboration with Sony
Harman International Announces New Collaboration with Sony Audio and Entertainment Leaders Join Forces on New Products and Retail Sales STAMFORD, CT – Harman International Industries, Incorporated (NYSE: HAR), the global leader in audio and infotainment, announced today two important initiatives in a newly-formed collaboration with Sony Corporation. Combining the superior technology and innovation for which both companies are world-renowned, Harman has introduced the new JBL® docking station designed for Sony’s Walkman® digital media player. Launched in November 2009, the JBL Sony Walkman docking stations will initially be sold exclusively in the Japanese market, and then introduced into other markets in the course of 2010. Additionally, Sony has begun offering products under Harman’s JBL brand in Sony Style stores throughout Canada, and Sony is assessing the expansion of this relationship into other markets. Several JBL products will be available in the Sony Style stores, including the JBL Balboa, CS and ES home sound system speakers, and JBL Duet II and JBL Duet III portable speakers. “By collaborating on both technologies and retail distribution channels, Harman and Sony have upped the ante in bringing consumers the most advanced sound systems available for home and personal use,”said Dinesh C. Paliwal, Chairman, President and CEO of Harman International. “Both companies have a long history of developing products whose innovation is unsurpassed, and we look forward to expanding this exciting partnership with Sony in the months and years to come.” Sony Style stores and www.sonystyle.com offer the company’s latest products and accessories directly to consumers. Harman International (www.harman.com) designs, manufactures and markets a wide range of audio and infotainment products for the automotive, consumer and professional markets. -

Harman International 2007 Annual Report Harman International Is a Leading Global Provider of High-Fidelity Audio and Infotainment Systems
Harman International 2007 Annual Report Harman International is a leading global provider of high-fidelity audio and infotainment systems. Our family of legendary brands includes Harman Kardon,® JBL,® Revel,® Mark Levinson,® Infinity,® Lexicon,® Soundcraft-Studer,® AKG,® Becker® and QNX.® Around the home, our products enrich daily lives with unmatched clarity. From portable music players to integrated home entertainment systems, the Harman name has been synonymous with a superior sound experience for more than 50 years. On the highway, we entertain and inform the world’s discriminating drivers and passengers. Our audio, DVD and navigation systems are the choice of both luxury automakers and aftermarket enthusiasts who will settle for nothing less than the Harman experience. Our professional products help leading artists of every genre to record and to perform – from advanced studio mixing systems that capture every subtle note, to audio solutions that fill the world’s premier entertainment and sporting venues with high-fidelity sound. Our network of manufacturing, sales and service resources is staffed by more than 10,500 dedicated Harman professionals, along with leading retailers, systems integrators and channel partners. Although we hail from many cultures, we are united by a single set of values encompassing integrity, creativity, quality and human development. Welcome to the world of Harman International. Cover: Harman Professional audio systems provide the perfect mix of high fidelity, command, and control for leading entertainment -

Convention Program
Systems—Jean-Marc Jot,1 Brandon Smith,2 Jeff Thompson2 room energy impulse response, elapsed times are still long when 1DTS, Inc., Los Gatos, CA, USA high spatial resolutions and/or simulations in several frequency 2 DTS, Inc., Bellevue, WA, USA bands are needed. In this work several data-parallel approaches of this finite-difference solution on Graphics Processing Units TH Dialog is often considered the most important audio element are proposed using a compute unified device architecture pro- in a movie or television program. The potential for artifact-free gramming model. A comparison of their performance running AES 139 CONVENTION dialog salience personalization is one of the advantages of new on different models of Nvidia GPUs is carried out. In general, 2D object-based multichannel digital audio formats, along with the vertical block approach running in a Tesla K20C shows the best ability to ensure that dialog remains comfortably audible in the speed-up of more than 15 times versus CPU version. presence of concurrent sound effects or music. In this paper we Convention Paper 9359 PROGRAM review some of the challenges and requirements of dialog control and enhancement methods in consumer audio systems, and their implications in the specification of object-based digital audio for- 12:00 noon mats. We propose a solution incorporating audio object loudness P1-7 An Improved and Generalized Diode Clipper Model for Wave OCTOBER 20 – NOVEMBER 1, 2015 metadata, including a simple and intuitive consumer personaliza- Digital Filters—Kurt James Werner,1 Vaibhav Nangia,1 Alberto tion interface and a practical head-end encoder extension. -
ISA PNP and ACPI ID List
Last updated: August 25, 2015 Company PNPid Approved on Date 21ST CENTURY ENTERTAINMENT BUT 04/25/02 2-Tel B.V. TTL 03/20/99 3Com Corporation TCM 11/29/96 3D Perception TDP 05/16/02 3M VSD 10/16/98 3NOD Digital Technology Co. Ltd. NOD 12/11/14 A D S Exports NGS 07/16/98 A Plus Info Corporation API 11/29/96 A&R Cambridge Ltd ACG 06/13/07 A/Vaux Electronics AVX 08/29/12 A+V Link APV 01/27/10 Aashima Technology B.V. TRU 05/08/98 Aava Mobile Oy AAM 08/13/13 ABBAHOME INC. ABA 11/08/99 Abeam Tech Ltd MEG 11/29/96 Ably-Tech Corporation ATC 11/29/96 AboCom System Inc ABC 03/28/97 ACC Microelectronics WTC 11/29/96 Access Works Comm Inc AWC 11/29/96 Acco UK ltd. PKA 05/12/03 Accton Technology Corporation ACC 11/29/96 Acculogic ACU 11/29/96 AccuScene Corporation Ltd ASL 06/13/07 Ace CAD Enterprise Company Ltd ANT 11/29/96 Acer Inc CHE 11/29/96 Acer Labs ALI 11/29/96 Acer Netxus Inc ANX 11/29/96 Acer Technologies ACR 11/29/96 Acksys ACK 11/29/96 Acnhor Datacomm ADC 11/29/96 Acon CAL 11/29/96 Acrolink Inc ALK 03/12/97 Acroloop Motion Control Systems Inc ACM 03/26/98 ACT Labs Ltd LAB 09/02/97 Actek Engineering Pty Ltd ACE 11/29/96 Actiontec Electric Inc AEI 11/29/96 ActivCard S.A ACV 05/08/98 Aculab Ltd ACB 11/29/96 Acutec Ltd. -

Rv-6, Rv-9, Mc-10
RV-6, RV-9, MC-10 Deutsch HANDBUCH AVR Surround Verstärker menu ok info mute input mode direct display zone RV-9 Receiver phones aux D-1 Klasse II Produkt Bei diesem Gerät handelt es sich um ein doppelt isoliertes elektrisches Gerät der Schutzklasse II. Es wurde so konzipiert, VORSICHT: Um das Risiko eines Stromschlages zu minimieren, sollten Sie die Abdeckungen (oder die Rückseite) nicht entfernen. Sicherheit Im Geräteinneren befinden sich keine zu wartenden Teile. Überlassen Sie die Wartung des Geräts einem Fachmann. dass es keine Erdung benötigt. WARNUNG: Um das Risiko von Brand oder Stromschlag zu reduzieren, setzen Sie das Gerät weder Regen noch Feuchtigkeit aus. Das Blitzsymbol im gleichseitigen Dreieck weist den Benutzer auf eine nicht isolierte „gefährliche Spannung“ im Gehäuse des Geräts hin, die stark genug sein kann, um einen Stromschlag auszulösen. Das Ausrufezeichen in einem gleichseitigen Dreieck weist den Anwender auf wichtige Anweisungen zum Betrieb und zur Instandhaltung (Wartung) in der Dokumentation hin. VORSICHT: In Kanada und den USA muss zur Vorbeugung gegen elektrische Schläge der breite Teil des Steckers vorsichtig in die breite Öffnung der Steckdose eingesteckt werden. Wichtige Sicherheitsanweisungen 10. Schützen Sie das Netzkabel, dass möglichst nicht Um die Gefahr von Stromschlag so gering wie möglich 22. Nichtnutzung darauf getreten und dass es nicht eingeklemmt wird. zu halten, dürfen Wartungsarbeiten, die nicht in Ziehen Sie zum Strom sparen den Netzstecker, wenn Sie 1. Lesen Sie diese Anweisungen. Besondere Vorsicht sollte man bei Netzsteckern, diesen Anleitungen enthalten sind, ausschließlich von das Gerät für längere Zeit nicht nutzen. 2. Bewahren Sie die Anweisungen auf. Steckdosen und an der Ausgangsstelle qualifizierten Fachleuten durchgeführt werden.