Manchester Forum in Linguistics 2018
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Translated and Edited Publications
Translated and edited publications There are nearly 250 items in this list, including co-translations and revised editions. Editing and translations from German and French are indicated, otherwise the listed publications are translations from Dutch. Katrijn Van Bragt and Sven Van Dorst, Study of a Young Woman: An exceptional glimpse into Michaelina Wautier’s studio (1604–1689) (Phoebus Focus 19) (Antwerp: The Phoebus Foundation, 2020) Leen Kelchtermans, Portrait of Elisabeth Jordaens: Jacob Jordaens’ (1593–1678) tribute to his eldest daughter and country life (Phoebus Focus 18) (Antwerp: The Phoebus Foundation, 2020) Nils Büttner, A Sailor and a Woman Embracing: Peter Paul Rubens (1577–1640) and modern painting (Phoebus Focus 16) (Antwerp: The Phoebus Foundation, 2020) Dina Aristodemo, Descrittione di tutti i Paesi Bassi: Lodovico Guicciardini and the Low Countries (Phoebus Focus 15) (Antwerp: The Phoebus Foundation, 2020) Timothy De Paepe, Elegant Company in a Garden: A musical painting full of sixteenth-century wisdom (Phoebus Focus 9) (Antwerp: The Phoebus Foundation, 2020) Chris Stolwijk and Renske Cohen Tervaert, Masterpieces in the Kröller- Müller Museum (Otterlo: Kröller-Müller Museum, 2020) Maximiliaan Martens et al., Van Eyck: An Optical Revolution (Antwerp: Hannibal, 2020). All the translations from Dutch. Nienke Bakker and Lisa Smit (eds.), In the Picture: Portraying the Artist (Amsterdam: Van Gogh Museum, 2020) Hans Vlieghe, Apollo on His Sun Chariot (Phoebus Focus 8) (Antwerp: The Phoebus Foundation, 2019) Joris Van Grieken, Maarten Bassens, et al., Bruegel in Black & White: The World of Bruegel (Antwerp: Hannibal, 2019). Translation of all but one of the texts. Bert van Beneden (ed.) From Titian to Rubens: Masterpieces from Antwerp and other Flemish Cities (Ghent: Snoeck, 2019); exhibition catalogue Venice, Palazzo Ducale. -

Ii. Disposiciones Y Anuncios Del Estado Sumario
Suplemento al número 81, correspondiente al día 6 de abril de 2009 Fascículo I SUMARIO II. DISPOSICIONES Y ANUNCIOS DEL ESTADO — Coslada (Régimen económico) .................... 183 — Estremera (Régimen económico) .................. 209 — Ministerios .................................... 1 — Getafe (Régimen económico) ..................... 210 — Humanes de Madrid (Régimen económico) .......... 215 III. ADMINISTRACIÓN LOCAL — Leganés (Régimen económico) .................... 217 — Pozuelo de Alarcón (Régimen económico) ........... 221 AYUNTAMIENTOS — San Fernando de Henares (Régimen económico) ...... 236 — Madrid (Régimen económico) ..................... 95 — San Martín de la Vega (Régimen económico) ......... 238 — Madrid (Contratación) ........................... 150 — San Sebastián de los Reyes (Régimen económico) ..... 249 — Ajalvir (Régimen económico) ..................... 152 — Valdemorillo (Régimen económico) ................ 250 — Alcalá de Henares (Régimen económico) ............ 152 — Alcobendas (Régimen económico) ................. 152 — Aranjuez (Régimen económico) ................... 155 IV. ADMINISTRACIÓN DE JUSTICIA — Boadilla del Monte (Régimen económico) ........... 182 — Juzgados de Primera Instancia e Instrucción .......... 252 — Brunete (Régimen economico) .................... 183 — JuzgadosdeloSocial............................ 252 II. DISPOSICIONES Y ANUNCIOS DEL ESTADO MINISTERIO DE TRABAJO E INMIGRACIÓN ción del presente anuncio en el tablón de edictos del Ayuntamiento del último domicilio co- nocido del deudor y en -

16Th FINA World Masters Championships 2015 KAZAN (RUS)
16th FINA World Masters Championships 2015 KAZAN (RUS) 800 m Freestyle Men Results RANK SURNAME & NAME FED BORN 50 m 100 m 200 m 300 m 400 m 500 m 600 m 700 m FINAL TEAM CAT AGE GROUP 85-89 QUALIFYING STANDARD: 23:13.00 CR : 15:16.96 WR : 14:37.00 1 SKOBELEV Boris RUS 1930 57.07 2:04.20 4:21.07 6:40.73 8:59.42 11:19.63 13:41.02 16:02.54 18:20.43 Russian Reserve 85-89 1:07.13 2:16.87 2:19.66 2:18.69 2:20.21 2:21.39 2:21.52 2:17.89 2 COUTTIE Peter AUS 1930 1:10.96 2:34.81 5:22.83 8:08.13 10:53.13 13:37.70 16:20.90 19:02.42 21:41.08 Malvern Marlins 85-89 1:23.85 2:48.02 2:45.30 2:45.00 2:44.57 2:43.20 2:41.52 2:38.66 AGE GROUP 80-84 QUALIFYING STANDARD: 20:40.00 CR : 13:28.82 WR : 11:49.00 1 VERESHAGINE Anry RUS 1934 43.97 1:30.97 3:10.65 4:51.02 6:33.13 8:15.05 9:57.37 11:39.31 13:15.13 CR All Stars 80-84 47.00 1:39.68 1:40.37 1:42.11 1:41.92 1:42.32 1:41.94 1:35.82 2 BROVIN Igor RUS 1932 44.99 1:36.71 3:26.25 5:15.64 7:07.53 8:58.81 10:53.14 12:52.05 14:39.25 Sprut 80-84 51.72 1:49.54 1:49.39 1:51.89 1:51.28 1:54.33 1:58.91 1:47.20 3 MULLINS Steve USA 1932 56.13 2:04.19 4:18.97 6:35.14 8:50.62 11:04.23 13:18.27 15:29.71 17:32.64 Illinois Masters 80-84 1:08.06 2:14.78 2:16.17 2:15.48 2:13.61 2:14.04 2:11.44 2:02.93 4 KAMAL Ahmed Fouad EGY 1933 54.26 2:00.61 4:23.06 6:43.94 9:06.08 11:27.77 13:45.86 16:04.98 18:07.97 Gezira Sporting Club 80-84 1:06.35 2:22.45 2:20.88 2:22.14 2:21.69 2:18.09 2:19.12 2:02.99 NOT CLASSIFIED 0 HOLE Gerhard GER 1935 80-84 Ssf Bonn 05 DNS AGE GROUP 75-79 QUALIFYING STANDARD: 18:50.00 CR : 11:25.95 WR : 11:08.00 -

Muslims in Spain, 1492–1814 Mediterranean Reconfigurations Intercultural Trade, Commercial Litigation, and Legal Pluralism
Muslims in Spain, 1492– 1814 Mediterranean Reconfigurations Intercultural Trade, Commercial Litigation, and Legal Pluralism Series Editors Wolfgang Kaiser (Université Paris I, Panthéon- Sorbonne) Guillaume Calafat (Université Paris I, Panthéon- Sorbonne) volume 3 The titles published in this series are listed at brill.com/ cmed Muslims in Spain, 1492– 1814 Living and Negotiating in the Land of the Infidel By Eloy Martín Corrales Translated by Consuelo López- Morillas LEIDEN | BOSTON This is an open access title distributed under the terms of the CC BY-NC 4.0 license, which permits any non-commercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited. Further information and the complete license text can be found at https://creativecommons.org/licenses/by-nc/4.0/ The terms of the CC license apply only to the original material. The use of material from other sources (indicated by a reference) such as diagrams, illustrations, photos and text samples may require further permission from the respective copyright holder. Cover illustration: “El embajador de Marruecos” (Catalog Number: G002789) Museo del Prado. Library of Congress Cataloging-in-Publication Data Names: Martín Corrales, E. (Eloy), author. | Lopez-Morillas, Consuelo, translator. Title: Muslims in Spain, 1492-1814 : living and negotiating in the land of the infidel / by Eloy Martín-Corrales ; translated by Consuelo López-Morillas. Description: Leiden ; Boston : Brill, [2021] | Series: Mediterranean reconfigurations ; volume 3 | Original title unknown. | Includes bibliographical references and index. Identifiers: LCCN 2020046144 (print) | LCCN 2020046145 (ebook) | ISBN 9789004381476 (hardback) | ISBN 9789004443761 (ebook) Subjects: LCSH: Muslims—Spain—History. | Spain—Ethnic relations—History. -

Conselleria De Sanitat Consellería De Sanidad
Conselleria de Sanitat Consellería de Sanidad Notificació de liquidacions per taxes sanitàries en Notificación de liquidaciones por tasas sanitarias en l’Hospital General de Castelló. Liquidació número el Hospital General de Castellón. Liquidación número 0466705600514 i altres. [2014/517] 0466705600514 y otras. [2014/517] Segons que disposa l’article 112 de la Llei 58/2003, de 17 de De conformidad con lo dispuesto en el artículo 112 de la Ley desembre, General Tributària, i com que s’ha intentat la notificació a la 58/2003, de 17 de diciembre, General Tributaria, y habiéndose intenta- persona interessada o al seu representant per dues vegades, sense que do la notificación al interesado o su representante por dos veces, sin que haja sigut possible per causes no imputables al centre gestor, es posa haya sido posible practicarlas por causas no imputables al centro gestor, de manifest, mitjançant este anunci, que estan pendents de notificar les se pone de manifiesto, mediante el presente anuncio, que se encuentran liquidacions per taxes sanitàries que s’especifiquen a continuació. pendientes de notificar las liquidaciones por tasas sanitarias cuyo inte- resado se especifica a continuación. Per tot això, dispose que els subjectes passius, obligats tributaris En virtud de lo anterior dispongo que los sujetos pasivos, obligados indicats anteriorment, o els seus representants ben acreditats, hauran de tributarios indicados anteriormente, o sus representantes debidamente comparéixer en el termini de 15 dies naturals, comptadors des de l’ende- acreditados, deberán comparecer en el plazo de 15 días naturales, con- mà de la publicació d’esta resolució en el Diari Oficial de la Comunitat tados desde el siguiente al de la publicación de la presente resolución Valenciana, de dilluns a divendres, en l’horari de 09.00 a 14.00 hores, en el Diari Oficial de la Generalitat Valenciana, de lunes a viernes, en en el centre gestor Hospital de Castelló (av. -
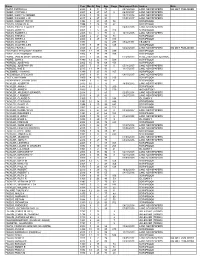
Obituary Index-F Surnames
Name Year Month Day Age Page Newspaper Date Source Note FAATZ, PATRICIA A 2020 5 14 78 05/16/2020 LANC NEWSPAPERS NO OBIT PUBLISHED FABER, CYNTHIA J 2007 6 27 67 0 06/30/2007 LANC NEWSPAPERS FABER, NANCY H FERBER 2016 3 10 89 03/11/2016 LANC NEWSPAPERS FABER, RICHARD J JR 2017 2 27 91 03/01/2017 LANC NEWSPAPERS FABER, ROBERT PETER 1994 1 25 25 54 SCRAPBOOK FABIAN, CAROLYN S 1998 1 24 50 42 SCRAPBOOK FABIAN, ESTELLE GRACE 2015 6 3 65 06/09/2015 LANC NEWSPAPERS FABIAN, JERRY C 2001 7 5 46 310 SCRAPBOOK FABIAN, ROBERT J 2005 10 9 78 0 10/11/2005 LANC NEWSPAPERS FABIAN, STEVE A 2005 2 21 56 78 SCRAPBOOK FABIAN, TERRY A 2000 6 27 45 349 SCRAPBOOK FABIAN, WALTER A 1971 82 297 07/22/1971 CB OBITS FABIAN, WALTER A SR 1971 7 17 82 128 SCRAPBOOK FABIANI, FRANK J 2020 4 21 64 04/22/2020 LANC NEWSPAPERS NO OBIT PUBLISHED FABIANSKI, THEODORE KASIMIR 2003 12 13 80 499 SCRAPBOOK FABLE, RITA FROHOCK 2004 8 17 78 355 SCRAPBOOK FABRE, JANE M (NIGHTENGALE) 2013 7 26 84 07/29/2013 INTELLIGENCER JOURNAL FABRE, JOHN S 1990 12 22 81 509 SCRAPBOOK FABRIZIO, JOSEPH D 2002 10 16 69 453 SCRAPBOOK FABRIZIO, JOSEPH P SR 2007 5 9 84 0 05/11/2007 LANC NEWSPAPERS FABRIZIO, MAE E 2015 11 14 90 11/17/2015 LANC NEWSPAPERS FACEMIRE, H WAYNE 1989 5 25 33 167 SCRAPBOOK FACENDOLA, STEVEN G 2017 8 11 31 08/15/2017 LANC NEWSPAPERS FACEY, MARYANN 2000 4 20 66 230 SCRAPBOOK FACKENTHAL, FRANK D DR 1968 9 5 85 11 SCRAPBOOK FACKLER, ALBERT R 2012 10 7 79 10/09/2012 LANC NEWSPAPERS FACKLER, ANNA C 1984 11 3 72 250 SCRAPBOOK FACKLER, ANNIE K 1949 2 28 73 179 AKS OBIT BK 1 FACKLER, ARLENE -

MREB Cleared Protocols
MREB Cleared Protocols MREB# Date Cleared Title Faculty Faculty Dept Student Type Level of Project 2003 014 Feb-10-2003 I. Bourgeault Health Studies R. Walji Faculty 2004 064 May-11-2004 Canadian Professors as Public Intellectuals N. McLaughlin Sociology K. Turcotte Faculty 2004 157 Oct-24-2004 M. Cadieux Psychology Faculty 2005 061 Aug-10-2005 S. Mestelman Economics M. Rogers Faculty 2005 168 Mar-01-2006 An exploration of Self-Actualization (the mind-body- W. Shaffir Sociology Y. Le Blanc PhD energy connection) as a Holistic Health Practice: participant observation 2005 186 Feb-05-2006 B. Milliken Psychology Hannah Teja Faculty 2006 006 Feb-06-2006 Automaticity and Focus of Attention in Handwriting J. Starkes Kinesiology J. Cullen Faculty 2006 007 Feb-06-2006 Actively Building Capacity in Primary Care Research C. Levitt Family Medicine Faculty 2006 008 Feb-09-2006 Parents: The unacknowledged victims of childhood T. Vaillancourt Psychology J. Johnson PostDoc bullying 2006 009 Feb-09-2006 Community medicine focus groups I. Tyler Family Medicine M. Hau Medical Student 2006 011 Feb-21-2006 Code-switching and prosody in sentence comprehension C. Anderson Linguistics Faculty 2006 012 Feb-28-2006 Elicited Writing Errors K. Humphreys Psychology D. Pollock MA 2006 013 Apr-05-2006 Correlation Between Student's High-School Mathematics M. Lovric Mathematics M. Fioroni MA Backgrounds and Performance in First Year Mathematics at McMaster University 2006 014 Mar-08-2006 The Impossible Policy Problem? An Exploration of the V. Satzewich Sociology A. Walker MA Policy Roadblocks to Foreign Credential Recognition in Canada 2006 015 Feb-05-2006 Inclusive Occupational Therapy Education: A Pilot Survey B. -

Using Standard Syste
PHYSICAL REVIEW D VOLUME 55, NUMBER 10 15 MAY 1997 Cumulative Author Index All authors of papers published so far in the current volume are listed alphabetically with the issue and page numbers following the dash. A more complete index, with the full title listed with each ®rst author's name and subsequent authors cross-referenced, is published in the last issue of the volume. A cumulative author and subject index covering Physical Review A through E, Physical Review Letters, and Reviews of Modern Physics is published annually under separate cover. Abashian, A.Ð͑9͒ 5667 Anderson, Paul R.Ð͑6͒ 3440; ͑10͒ 6116 Badgett, W.Ð͑3͒ 1142; ͑5͒ 2546; Abbasabadi, AliÐ͑9͒ 5647 Anderson, S.Ð͑3͒ R1119; ͑5͒ 2559; ͑9͒ R5263 Abe, F.Ð͑3͒ 1142; ͑5͒ 2546; ͑9͒ R5263 ͑7͒ R3919; ͑9͒ 5273 Baer, HowardÐ͑3͒ 1466; ͑5͒ 3201; Abe, K.Ð͑1͒ 19; ͑5͒ 2533, 2533 Andersson, NilsÐ͑2͒ 468 ͑7͒ 4463 Andreev, Yu. M.Ð͑3͒ 1233 Abel, S. A.Ð͑3͒ 1623 Bagdasarov, S.Ð͑3͒ 1142; ͑5͒ 2546; Anisovich, V. V.Ð͑5͒ 2918 Abney, MarkÐ͑2͒ 582 ͑9͒ R5263 Anninos, PeterÐ͑2͒ 829; ͑4͒ 1948 Abrahams, AndrewÐ͑2͒ 829 Bagger, JonathanÐ͑2͒ 1091 Anselmino, M.Ð͑9͒ 5841 Abt, I.Ð͑5͒ 2533 ͑ ͒ AntilloÂn, ArmandoÐ͑10͒ 6327 Bagger, Jonathan A.Ð 5 3188 Acharya, B. S.Ð͑8͒ R4521 Antoniadis, IgnatiosÐ͑8͒ 4756, 4770 Baier, R.Ð͑7͒ 4344 Achasov, N. N.Ð͑5͒ 2663, 2672 Antoniazzi, L.Ð͑7͒ 3927 Bailey, M. W.Ð͑3͒ 1142; ͑5͒ 2546; Adam, ChristophÐ͑10͒ 6299 Antos, J.Ð͑3͒ 1142; ͑5͒ 2546; ͑9͒ R5263 ͑9͒ R5263 Adhikari, RathinÐ͑6͒ 3836 Antunes, Nuno D.Ð͑2͒ 925 Baird, K. G.Ð͑5͒ 2533 Afanasev, AndreiÐ͑7͒ 4380 Anway-Wiese, C.Ð͑3͒ 1142; ͑5͒ 2546 Baker, JohnÐ͑2͒ 829 Ahlen, S. -

Index to 2003 Obituaries in the Canton Repository
Index to 2003 Obituaries in the Canton Repository Published by the Stark County District Library Canton, Ohio 2005 Page 1 Index to 2003 Obituaries in the Canton Repository The following is an alphabetical listing, by the deceased’s surname, of obituaries that appeared in the Canton, Ohio newspaper, The Repository. It was compiled by the library staff during the course of the year in the hope that it would be a useful tool to genealogy, as well as other researchers. To use this index, simply locate the name of the person whose obituary you wish to find. The entries will appear as follows: Miller William A. (Estella M.) Mrs. 1940 Jan. 13 30 The first column is the name of the deceased. The second gives the date on which the item appeared. And the third tells the page number containing the obituary. You may find one name with multiple listings showing different dates and locations in the paper. This indicates consecutive listings for that individual. I encourage you to view each for additional information. Page 2 Index to Obituaries in the 2003 Canton Repository Surname Given Name Maiden Title Year Mth. Day Sec. Pg. Abate Tammy Lynn Taylor 2003 Jan. 28 B 4 Abate Tammy Lynn Taylor 2003 Jan. 28 B 5 Abrams Harlan 2003 Apr. 27 B 4 Acker Mary Ann 2003 Jan. 11 B 3 Ackeret Vernon C. 2003 May 26 B 6 Ackerman Donald E. 2003 May 10 B 4 Ackerman Geraldine M. Kintz 2003 Feb. 19 B 4 Ackerman Jack J. 2003 May 30 B 4 Ackerman Marilyn S. -

Diplomatic List – Fall 2018
United States Department of State Diplomatic List Fall 2018 Preface This publication contains the names of the members of the diplomatic staffs of all bilateral missions and delegations (herein after “missions”) and their spouses. Members of the diplomatic staff are the members of the staff of the mission having diplomatic rank. These persons, with the exception of those identified by asterisks, enjoy full immunity under provisions of the Vienna Convention on Diplomatic Relations. Pertinent provisions of the Convention include the following: Article 29 The person of a diplomatic agent shall be inviolable. He shall not be liable to any form of arrest or detention. The receiving State shall treat him with due respect and shall take all appropriate steps to prevent any attack on his person, freedom, or dignity. Article 31 A diplomatic agent shall enjoy immunity from the criminal jurisdiction of the receiving State. He shall also enjoy immunity from its civil and administrative jurisdiction, except in the case of: (a) a real action relating to private immovable property situated in the territory of the receiving State, unless he holds it on behalf of the sending State for the purposes of the mission; (b) an action relating to succession in which the diplomatic agent is involved as an executor, administrator, heir or legatee as a private person and not on behalf of the sending State; (c) an action relating to any professional or commercial activity exercised by the diplomatic agent in the receiving State outside of his official functions. -- A diplomatic agent’s family members are entitled to the same immunities unless they are United States Nationals. -

Iii. Administración Local
BOCM BOLETÍN OFICIAL DE LA COMUNIDAD DE MADRID B.O.C.M. Núm. 224 SÁBADO 20 DE SEPTIEMBRE DE 2014 Pág. 59 III. ADMINISTRACIÓN LOCAL AYUNTAMIENTO DE 24 FUENLABRADA RÉGIMEN ECONÓMICO No habiendo resultado posible practicar la notificación al interesado o su representante, conforme a lo dispuesto en el artículo 112 de la Ley General Tributaria, mediante el pre- sente anuncio se cita a los contribuyentes a continuación indicados para que comparezcan en el lugar que se indica, a fin de que les sean notificadas las actuaciones llevadas a cabo en los procedimientos tributarios que les afectan y que a continuación se señalan: Actuación que se notifica Providencia de apremio: en el uso de las facultades que me confiere el artículo 5.3.c) del Real Decreto 1174/1987, de 18 de septiembre, en relación con el artículo 70 del Real Decreto 939/2005, de 29 de julio, por el que se aprueba el Reglamento General de Recau- dación, no habiendo satisfecho el obligado tributario las deudas por el concepto, ejercicio e importe expresado, habiendo sido notificadas en legal forma y expirado el plazo de ingre- so en período voluntario, se inicia el devengo de los intereses de demora. Asimismo, con- forme a lo dispuesto en el artículo 167 de la Ley 58/2003, de 17 de diciembre, General Tri- butaria, procedo a liquidar los recargo establecidos en el artículo 28 de dicha Ley, recargo de apremio reducido del 10 por 100, si se satisface la totalidad de la deuda y el propio re- cargo dentro de los plazos previstos en el artículo 62.5 de la Ley General Tributaria, y recar- go ordinario del 20 por 100 cuando se satisfaga la deuda y el recargo fuera de dicho plazo. -

16Th FINA World Masters Championships 2015 KAZAN (RUS)
16th FINA World Masters Championships 2015 KAZAN (RUS) 50 m Freestyle Women Entry List ORD CODE SURNAME & NAME FED BORN CAT TEAM Q.TIME AGE GROUP 90-94 1 JPN_124247 OTSUKA Masako JPN 1925 90-94 Sukoyaka St 1:50.00 AGE GROUP 85-89 1 JPN_124244 AMANO Toshiko JPN 1926 85-89 Sukoyaka St 1:25.00 AGE GROUP 80-84 1 JPN_123097 AKIYAMA Ayako JPN 1935 80-84 Tanashi A&A 59.00 2 JPN_123103 MIYOSHI Satoko JPN 1935 80-84 Hiroshima Msc 48.00 AGE GROUP 75-79 1 JPN_122909 KAWAHARA Kyoko JPN 1940 75-79 Tobu Owada 1:00.50 2 JPN_124186 SATO Setsuko JPN 1938 75-79 Motoyama Ss 1:00.45 3 JPN_119553 NAGAYA Mieko JPN 1937 75-79 Asahikawa Ss 1:00.00 4 JPN_119557 NAKAZAWA Keiko JPN 1938 75-79 Okayama Manei C 1:00.00 5 JPN_122855 ARASE Yaeko JPN 1938 75-79 Hiroshima Msc 59.17 6 JPN_120558 OTSUKA Yuko JPN 1939 75-79 Takaido Sc 48.00 7 RUS_122492 SHURKUS Nella RUS 1939 75-79 Russian Reserve 48.00 8 JPN_124246 TSUCHIYA Toshiko JPN 1938 75-79 Sukoyaka St 47.00 9 RUS_117347 GUBINA Alfiya RUS 1940 75-79 Poseidon 46.00 10 RUS_124228 KASHINA Lorina RUS 1939 75-79 Troyka 45.00 11 GER_115502 GRUNER Gisela GER 1936 75-79 Ssv Blau-Weiss Gersdorf 43.30 12 JPN_124237 OSAKI Yoshiko JPN 1938 75-79 St Kansai 37.00 13 GER_119068 SCHULZ Christel GER 1940 75-79 Sg Einheit Rathenow 36.00 AGE GROUP 70-74 1 JPN_122931 NAGASAWA Hiroko JPN 1943 70-74 Sakurambo 55.95 2 EGY_120689 ZULFICAR Nadjia EGY 1943 70-74 Al Gezira Sporting Club 54.00 3 AUS_113830 GREGORY Judy AUS 1943 70-74 Malvern Marlins 52.00 4 IND_121939 RAY Lal Pari IND 1943 70-74 Bihar Swimming Association 52.00 5 RUS_123186