Detecting Non-Tree-Like Signal Using Multiple Tree Topologies Author: Annemarie Verkerk
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

《International Symposium》 Let's Talk About Trees National Museum
《International Symposium》 Let’s Talk about Trees National Museum of Ethnology, Osaka, Japan. February 10, 2013 Abstract [Austronesian Language Case Studies 2] Limitations of the tree model: A case study from North Vanuatu Siva KALYAN1 and Alexandre FRANÇOIS2 1. Northumbria University 2. CNRS/LACITO Since the beginnings of historical linguistics, the family tree has been the most widely accepted model for representing historical relations between languages. It is even being reinvigorated by current research in computational phylogenetics (e.g. Gray et al. 2009). While this sort of representation is certainly easy to grasp, and allows for a simple, attractive account of the development of a language family, the assumptions made by the tree model are applicable in only a small number of cases. The tree model is appropriate when a speaker population undergoes successive splits, with subsequent loss of contact among subgroups. For all other scenarios, it fails to provide an accurate representation of language history (cf. Durie & Ross 1996; Pawley 1999; Heggarty et al. 2010). In particular, it is unable to deal with dialect continua, as well as language families that develop out of dialect continua (for which Ross 1988 has proposed the term "linkage"). In such cases, the scopes of innovations (in other words, their isoglosses) are not nested, but rather they persistently intersect, so that any proposed tree representation is met with abundant counterexamples. Though Ross's initial observations about linkages concerned the languages of Western Melanesia, it is clear that linkages are found in many other areas as well (such as Fiji: cf. Geraghty 1983). In this presentation, we focus on the 17 languages of the Torres and Banks islands in Vanuatu, which form a linkage (Tryon 1996, François 2011), and attempt to develop adequate representations for it. -

Concepts and Methods of Historical Linguistics-The Germanic Family Of
CURSO 2016 - 2017 CONCEPTS AND METHODS OF HISTORICAL LINGUISTICS Tutor: Carlos Hernández Simón Sir William Jones, Jacob Grimm and Karl Verner from Lisa Minnick 2011: “Let them eat metaphors, Part 1: Order from Chaos and the Indo-European Hypothesis” Functional Shift https://functionalshift.wordpress.com/2011/10/09/metaphors1/ [retrieved February 17, 2017] CONCEPTS AND METHODS OF HISTORICAL LINGUISTICS HISTORICAL AND COMPARATIVE LINGUISTICS AIMS OF STUDY 1) Language change and stability 2) Reconstruction of earlier stages of languages 3) Discovery and implementation of research methodologies Theodora Bynon (1981) 1) Grammars that result from the study of different time spans in the evolution of a language 2) Contrast them with the description of other related languages 3) Linguistic variation cannot be separated from sociological and geographical factors 3 CONCEPTS AND METHODS OF HISTORICAL LINGUISTICS ORIGINS • Renaissance: Contrastive studies of Greek and Latin • Nineteenth Century: Sanskrit 1) Acknowledgement of linguistic change 2) Development of the Comparative Method • Robert Beekes (1995) 1) The Greeks 2) Languages Change • R. Lawrence Trask (1996) 1) 6000-8000 years 2) Historical linguist as a kind of archaeologist 4 CONCEPTS AND METHODS OF HISTORICAL LINGUISTICS THE COMPARATIVE METHOD • Sir William Jones (1786): Greek, Sanskrit and Latin • Reconstruction of Proto-Indo-European • Regular principle of phonological change 1) The Neogrammarians 2) Grimm´s Law (1822) and Verner’s Law (1875) 3) Laryngeal Theory : Ferdinand de Saussure (1879) • Two steps: 1) Isolation of a set of cognates: Latin: decem; Greek: deca; Sanskrit: daśa; Gothic: taihun 2) Phonological correspondences extracted: 1. Latin d; Greek d; Sanskrit d; Gothic t 2. Latin e; Greek e; Sanskrit a; Gothic ai 3. -
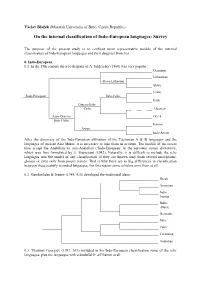
Internal Classification of Indo-European Languages: Survey
Václav Blažek (Masaryk University of Brno, Czech Republic) On the internal classification of Indo-European languages: Survey The purpose of the present study is to confront most representative models of the internal classification of Indo-European languages and their daughter branches. 0. Indo-European 0.1. In the 19th century the tree-diagram of A. Schleicher (1860) was very popular: Germanic Lithuanian Slavo-Lithuaian Slavic Celtic Indo-European Italo-Celtic Italic Graeco-Italo- -Celtic Albanian Aryo-Graeco- Greek Italo-Celtic Iranian Aryan Indo-Aryan After the discovery of the Indo-European affiliation of the Tocharian A & B languages and the languages of ancient Asia Minor, it is necessary to take them in account. The models of the recent time accept the Anatolian vs. non-Anatolian (‘Indo-European’ in the narrower sense) dichotomy, which was first formulated by E. Sturtevant (1942). Naturally, it is difficult to include the relic languages into the model of any classification, if they are known only from several inscriptions, glosses or even only from proper names. That is why there are so big differences in classification between these scantily recorded languages. For this reason some scholars omit them at all. 0.2. Gamkrelidze & Ivanov (1984, 415) developed the traditional ideas: Greek Armenian Indo- Iranian Balto- -Slavic Germanic Italic Celtic Tocharian Anatolian 0.3. Vladimir Georgiev (1981, 363) included in his Indo-European classification some of the relic languages, plus the languages with a doubtful IE affiliation at all: Tocharian Northern Balto-Slavic Germanic Celtic Ligurian Italic & Venetic Western Illyrian Messapic Siculian Greek & Macedonian Indo-European Central Phrygian Armenian Daco-Mysian & Albanian Eastern Indo-Iranian Thracian Southern = Aegean Pelasgian Palaic Southeast = Hittite; Lydian; Etruscan-Rhaetic; Elymian = Anatolian Luwian; Lycian; Carian; Eteocretan 0.4. -

Gothic Introduction – Part 1: Linguistic Affiliations and External History Roadmap
RYAN P. SANDELL Gothic Introduction – Part 1: Linguistic Affiliations and External History Roadmap . What is Gothic? . Linguistic History of Gothic . Linguistic Relationships: Genetic and External . External History of the Goths Gothic – Introduction, Part 1 2 What is Gothic? . Gothic is the oldest attested language (mostly 4th c. CE) of the Germanic branch of the Indo-European family. It is the only substantially attested East Germanic language. Corpus consists largely of a translation (Greek-to-Gothic) of the biblical New Testament, attributed to the bishop Wulfila. Primary manuscript, the Codex Argenteus, accessible in published form since 1655. Grammatical Typology: broadly similar to other old Germanic languages (Old High German, Old English, Old Norse). External History: extensive contact with the Roman Empire from the 3rd c. CE (Romania, Ukraine); leading role in 4th / 5th c. wars; Gothic kingdoms in Italy, Iberia in 6th-8th c. Gothic – Introduction, Part 1 3 What Gothic is not... Gothic – Introduction, Part 1 4 Linguistic History of Gothic . Earliest substantively attested Germanic language. • Only well-attested East Germanic language. The language is a “snapshot” from the middle of the 4th c. CE. • Biblical translation was produced in the 4th c. CE. • Some shorter and fragmentary texts date to the 5th and 6th c. CE. Gothic was extinct in Western and Central Europe by the 8th c. CE, at latest. In the Ukraine, communities of Gothic speakers may have existed into the 17th or 18th century. • Vita of St. Cyril (9th c.) mentions Gothic as a liturgical language in the Crimea. • Wordlist of “Crimean Gothic” collected in the 16th c. -

UC Berkeley UC Berkeley Electronic Theses and Dissertations
UC Berkeley UC Berkeley Electronic Theses and Dissertations Title Iranian Dialectology and Dialectometry Permalink https://escholarship.org/uc/item/5pv6f9g9 Author Cathcart, Chundra Aroor Publication Date 2015 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California Iranian Dialectology and Dialectometry By Chundra Aroor Cathcart A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Linguistics in the Graduate Division of the University of California, Berkeley Committee in charge: Professor Andrew J. Garrett, Chair Professor Gary B. Holland Professor Martin Schwartz Spring 2015 Abstract Studies in Iranian Dialectology and Dialectometry by Chundra Aroor Cathcart Doctor of Philosophy in Linguistics University of California, Berkeley Professor Andrew Garrett, Chair This dissertation investigates the forces at work in the formation of a tightly knit but ultimately non-genetic dialect group. The Iranian languages, a genetic sub-branch of the larger Indo-European language family, are a group whose development has been profoundly affected by millennia of internal contact. This work is concerned with aspects of the diversification and disparification (i.e., the development of different versus near-identical features across languages) of this group of languages, namely issues pertaining to the development of the so-called West Iranian group, whose status as a legitimate genetic subgroup has long remained unclear. To address the phenomena under study, I combine a traditional comparative-historical approach with existing quantitative methods as well as newly developed quantitative methods designed to deal with the sort of linguistic situation that Iranian typifies. The studies I undertake support the idea that West Iranian is not a genetic subgroup, as sometimes assumed; instead, similarities between West Iranian languages that give the impression of close genetic relatedness have come about due to interactions between contact and parallel driftlike tendencies. -

Adverbial Reinforcement of Demonstratives in Dialectal German
Glossa a journal of general linguistics Adverbial reinforcement of COLLECTION: NEW PERSPECTIVES demonstratives in dialectal ON THE NP/DP DEBATE German RESEARCH PHILIPP RAUTH AUGUSTIN SPEYER *Author affiliations can be found in the back matter of this article ABSTRACT CORRESPONDING AUTHOR: Philipp Rauth In the German dialects of Rhine and Moselle Franconian, demonstratives are Universität des Saarlandes, reinforced by locative adverbs do/lo ‘here/there’ in order to emphasize their deictic Germany strength. Interestingly, these adverbs can also appear in the intermediate position, i.e., [email protected] between the demonstrative and the noun (e.g. das do Bier ‘that there beer’), which is not possible in most other varieties of European German. Our questionnaire study and several written and oral sources suggest that reinforcement has become mandatory in KEYWORDS: demonstrative contexts. We analyze this grammaticalization process as reanalysis of demonstrative; reinforcer; do/lo from a lexical head to the head of a functional Index Phrase. We also show that a German; Rhine Franconian; functional DP-shell can better cope with this kind of syntactic change and with certain Moselle Franconian; Germanic; serialization facts concerning adjoined adjectives. Romance; dialectal German; grammaticalization; reanalysis; NP; DP; questionnaire TO CITE THIS ARTICLE: Rauth, Philipp and Augustin Speyer. 2021. Adverbial reinforcement of demonstratives in dialectal German. Glossa: a journal of general linguistics 6(1): 4. 1–24. DOI: https://doi. org/10.5334/gjgl.1166 1 INTRODUCTION Rauth and Speyer 2 Glossa: a journal of In colloquial Standard German, the only difference between definite determiners (1a) and general linguistics DOI: 10.5334/gjgl.1166 demonstratives is emphatic stress in demonstrative contexts (1b). -

A Concise History of English a Concise Historya Concise of English
A Concise History of English A Concise HistoryA Concise of English Jana Chamonikolasová Masarykova univerzita Brno 2014 Jana Chamonikolasová chamonikolasova_obalka.indd 1 19.11.14 14:27 A Concise History of English Jana Chamonikolasová Masarykova univerzita Brno 2014 Dílo bylo vytvořeno v rámci projektu Filozofická fakulta jako pracoviště excelentního vzdě- lávání: Komplexní inovace studijních oborů a programů na FF MU s ohledem na požadavky znalostní ekonomiky (FIFA), reg. č. CZ.1.07/2.2.00/28.0228 Operační program Vzdělávání pro konkurenceschopnost. © 2014 Masarykova univerzita Toto dílo podléhá licenci Creative Commons Uveďte autora-Neužívejte dílo komerčně-Nezasahujte do díla 3.0 Česko (CC BY-NC-ND 3.0 CZ). Shrnutí a úplný text licenčního ujednání je dostupný na: http://creativecommons.org/licenses/by-nc-nd/3.0/cz/. Této licenci ovšem nepodléhají v díle užitá jiná díla. Poznámka: Pokud budete toto dílo šířit, máte mj. povinnost uvést výše uvedené autorské údaje a ostatní seznámit s podmínkami licence. ISBN 978-80-210-7479-8 (brož. vaz.) ISBN 978-80-210-7480-4 (online : pdf) ISBN 978-80-210-7481-1 (online : ePub) ISBN 978-80-210-7482-8 (online : Mobipocket) Contents Preface ....................................................................................................................4 Acknowledgements ................................................................................................5 Abbreviations and Symbols ...................................................................................6 1 Introduction ........................................................................................................7 -

Vocalisations: Evidence from Germanic Gary Taylor-Raebel A
Vocalisations: Evidence from Germanic Gary Taylor-Raebel A thesis submitted for the degree of doctor of philosophy Department of Language and Linguistics University of Essex October 2016 Abstract A vocalisation may be described as a historical linguistic change where a sound which is formerly consonantal within a language becomes pronounced as a vowel. Although vocalisations have occurred sporadically in many languages they are particularly prevalent in the history of Germanic languages and have affected sounds from all places of articulation. This study will address two main questions. The first is why vocalisations happen so regularly in Germanic languages in comparison with other language families. The second is what exactly happens in the vocalisation process. For the first question there will be a discussion of the concept of ‘drift’ where related languages undergo similar changes independently and this will therefore describe the features of the earliest Germanic languages which have been the basis for later changes. The second question will include a comprehensive presentation of vocalisations which have occurred in Germanic languages with a description of underlying features in each of the sounds which have vocalised. When considering phonological changes a degree of phonetic information must necessarily be included which may be irrelevant synchronically, but forms the basis of the change diachronically. A phonological representation of vocalisations must therefore address how best to display the phonological information whilst allowing for the inclusion of relevant diachronic phonetic information. Vocalisations involve a small articulatory change, but using a model which describes vowels and consonants with separate terminology would conceal the subtleness of change in a vocalisation. -

Trees, Waves and Linkages: Models of Language Diversification Alexandre François
Trees, Waves and Linkages: Models of Language Diversification Alexandre François To cite this version: Alexandre François. Trees, Waves and Linkages: Models of Language Diversification. Bowern, Claire; Evans, Bethwyn. The Routledge Handbook of Historical Linguistics, Routledge, pp.161-189, 2014, 978-0-41552-789-7. 10.4324/9781315794013.ch6. halshs-00874726v2 HAL Id: halshs-00874726 https://halshs.archives-ouvertes.fr/halshs-00874726v2 Submitted on 19 Mar 2015 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. The Routledge Handbook of Historical Linguistics Edited by Claire Bowern and Bethwyn Evans RH of Historical Linguistics BOOK.indb iii 3/26/2014 1:20:21 PM 6 Trees, waves and linkages Models of language diversifi cation Alexandre François 1 On the diversifi cation of languages 1.1 Language extinction, language emergence The number of languages spoken on the planet has oscillated up and down throughout the history of mankind.1 Different social factors operate in opposite ways, some resulting in the decrease of language diversity, others favouring the emergence of new languages. Thus, languages fade away and disappear when their speakers undergo some pressure towards abandoning their heritage language and replacing it in all contexts with a new language that is in some way more socially prominent (Simpson, this volume). -

3 Proto-Germanic
A CONCISE HISTORY OF ENGLISH 3 Proto-Germanic 3.1 The common ancestor of Germanic languages Proto-Germanic, also referred to as Primitive Germanic, Common Germanic, or Ur- Germanic, is one of the descendants of Proto-Indo-European and the common ancestor of all Germanic languages. Th is Germanic proto-language, which was reconstructed by the comparative method, is not attested by any surviving texts. Th e only written records available are the runic Vimose inscriptions from around 200 AD found in Denmark, which represent an early stage of Proto-Norse or Late Proto-Germanic. (Comrie 1987) Proto-Germanic is assumed to have developed between about 500 BC and the be- ginning of the Common Era. (Ringe 2006, p. 67). It came aft er the First Germanic Sound Shift , which was probably contemporary with the Nordic Bronze Age. Th e pe- riod between the end of Proto-Indo-European (i.e. probably aft er 3 500 BC) and the beginning of Proto-Germanic (500 BC) is referred to as Pre-Proto-Germanic period. However, Pre-Proto-Germanic is sometimes included under the wider meaning of Proto- Germanic, and the notion of the Germanic parent language is used to refer to both stages. Th e First Germanic Sound Shift , also known as Grimm’s law or Rask’s rule, is a chain shift of Proto-Indo-European stops which took place between the Proto-Indo-European and the Proto-Germanic stage of development and which distinguishes Germanic lan- guages from other Indo-European centum languages. Grimm’s law, together with a relat- ed shift entitled Verner’s law, is described in greater detail in Chapter 7. -

A Linguistic History of English, Vol. 2. by DON RINGE and ANN TAYLOR. Oxford
REVIEWS 741 guistics (subsense units, hyponymy and meronymy, antonymy), whereas Dąbrowska 2004 sees cognitive linguistics mostly from the perspective of acquisition and gives a general orientation to the field only in Ch . 1 0. By contrast, Evans & Green 2006 is relatively comprehensive and specif - ically designed as a textbook, but intimidating in its bulk (over 800 pages). Given these alterna - tives, if one needs an introduction to cognitive linguistics in general or L’s work in particular, this book is an attractive candidate. REFERENCES Croft, William , and D. Alan Cruse . 2004. Cognitive linguistics . Cambridge: Cambridge University Press. D browska, Ewa Ą . 2004. Language, mind and brain . Washington, DC: Georgetown University Press. Evans, Vyvyan , and Melanie Green . 2006. Cognitive linguistics: An introduction . Edinburgh: Edinburgh University Press. Langacker, Ronald W . 1987 . Foundations of cognitive grammar, vol. 1: Theoretical prerequisites . Stan - ford, CA: Stanford University Press. Langacker, Ronald W . 1991a . Foundations of cognitive grammar, vol. 2: Descriptive application . Stan - ford, CA: Stanford University Press. Langacker, Ronald W . 1991b. Concept, image, and symbol . Berlin: Mouton de Gruyter. Langacker, Ronald W . 2000. Grammar and conceptualization. Berlin: Mouton de Gruyter. Langacker, Ronald W . 2008 . Cognitive grammar: A basic introduction . Oxford: Oxford University Press. Taylor, John R . 2002. Cognitive grammar . Oxford: Oxford University Press. Ungerer, Friedrich , and Hans-Jorg Schmid . 1996. An introduction to cognitive linguistics . London: Longman. HSL fakultet, UiT 9037 Tromsø, Norway [[email protected]] The development of Old English: A linguistic history of English, vol. 2. By Don Ringe and Ann Taylor . Oxford: Oxford University Press, 2014. Pp. ix, 614. ISBN 9780199207848. $135 (Hb). -

Het Noordzeegermaanse Vraagstuk Schiepen Een Volmaakt Kader Om Toch Nog Eens Een Poging Te Doen Om Meer Klaarheid Te Scheppen Over “Dat Verdraaide Ingveoons”!
2009 – 2010 Het Noor dzeegermaans: Een status questionis Verhandeling voorgelegd aan de Faculteit Letteren en Wijsbegeerte voor het verkrijgen van de graad van Master in de Historische Taal- en Letterkunde door Alexander Demoor Promotor: Prof. Dr. Luc De Grauwe 2 Dankwoord Ik wens prof. dr. De Grauwe uit de grond van mijn hart te bedanken voor de schier oneindige (!) bereidwilligheid tot nuttige raadgevingen en opbouwende commentaar die hij aan de dag legde tijdens het schrijven van deze verhandeling. Zonder de overweldigende hoeveelheid aan relevante en fascinerende bronnen die hij mij, een verstokt pendelstudent, op de meest uiteenlopende wijzen bezorgde, was dit alles nooit tot stand gekomen. Eveneens wil ik mevr. Rottier van de vakgroep Duitse Taalkunde alsook mevr. Willems en mevr. Bouckaert van de vakgroep Nederlandse Taalkunde bedanken voor hun soepelheid ten opzichte van het ontleningssysteem van de Gentse Universiteitsbibliotheken en vooral de vriendelijke hulp die mij werd gegeven toen ik weer eens de weg naar het juiste boek zoek was. Ik druk bij deze ook de oprechte waardering uit voor de algemene steun van mijn ouders tijdens dit uitdagende en erg intensieve studiejaar, en het geduld en begrip dat zij opbrachten voor de mindere dagen. Dit dankwoord is ook gericht aan de kameraden, zowel mannelijk als vrouwelijk, die mij inspiratie verleenden tijdens het schrijfproces en af en toe wat verstrooiing boden. Vooral de begeesterende gesprekken met dhr. Krekelbergh over het archeologische aspect van het Noordzeegermaanse vraagstuk schiepen een volmaakt kader om toch nog eens een poging te doen om meer klaarheid te scheppen over “dat verdraaide Ingveoons”! 3 4 Inhoudsopgave Dankwoord - 3 - Inhoudsopgave - 5 - 1.