Intel(R) C++ Compiler Optimizing Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

October 1998
OCTOBER 1998 GAME DEVELOPER MAGAZINE V GAME PLAN It’s First and Goal for EDITOR IN CHIEF Alex Dunne [email protected] MANAGING EDITOR Tor D. Berg [email protected] Fantasy Sports DEPARTMENTS EDITOR Wesley Hall whall@mfi.com his fall, as the leaves turn success stories. Unlike the traditional ART DIRECTOR Laura Pool lpool@mfi.com shades of orange and the days studio’s royalty revenue model, SWS has EDITOR-AT-LARGE Chris Hecker grow shorter, one of the two revenue streams: a two-year licens- [email protected] largest, most massively multi- ing agreement to develop more than 40 CONTRIBUTING EDITORS Jeff Lander T [email protected] player games picks up steam and sucks online games for CNN/SI (http://base- in participants. It’s a role-playing game ball.cnnsi.com), plus revenue from ban- Mel Guymon [email protected] that draws tens of thousands (gads, ner advertising displayed on the CNN/SI Omid Rahmat probably more) of players, and if my game’s web pages, which garner 50 mil- [email protected] predictions are right, it will be one of lion page views per month. Surprisingly, ADVISORY BOARD Hal Barwood the most popular attractions on the and in contrast to most commercial fan- Noah Falstein eventual TV set-top box. I’m talking tasy leagues, some of the CNN/SI Brian Hook about fantasy football leagues. leagues are free for participants and Susan Lee-Merrow It’s taken quite a bit of time for me to offer cash prizes for winners. These are Mark Miller 2 accept the fact that fantasy league sports the guppy leagues which, hopefully, (there are also fantasy leagues for base- entice the most enthusiastic players to COVER IMAGE Epic MegaGames ball, hockey, and perhaps even pro join the premiere leagues for $15. -

North American Company Profiles 8X8
North American Company Profiles 8x8 8X8 8x8, Inc. 2445 Mission College Boulevard Santa Clara, California 95054 Telephone: (408) 727-1885 Fax: (408) 980-0432 Web Site: www.8x8.com Email: [email protected] Fabless IC Supplier Regional Headquarters/Representative Locations Europe: 8x8, Inc. • Bucks, England U.K. Telephone: (44) (1628) 402800 • Fax: (44) (1628) 402829 Financial History ($M), Fiscal Year Ends March 31 1992 1993 1994 1995 1996 1997 1998 Sales 36 31 34 20 29 19 50 Net Income 5 (1) (0.3) (6) (3) (14) 4 R&D Expenditures 7 7 7 8 8 11 12 Capital Expenditures — — — — 1 1 1 Employees 114 100 105 110 81 100 100 Ownership: Publicly held. NASDAQ: EGHT. Company Overview and Strategy 8x8, Inc. is a worldwide leader in the development, manufacture and deployment of an advanced Visual Information Architecture (VIA) encompassing A/V compression/decompression silicon, software, subsystems, and consumer appliances for video telephony, videoconferencing, and video multimedia applications. 8x8, Inc. was founded in 1987. The “8x8” refers to the company’s core technology, which is based upon Discrete Cosine Transform (DCT) image compression and decompression. In DCT, 8-pixel by 8-pixel blocks of image data form the fundamental processing unit. 2-1 8x8 North American Company Profiles Management Paul Voois Chairman and Chief Executive Officer Keith Barraclough President and Chief Operating Officer Bryan Martin Vice President, Engineering and Chief Technical Officer Sandra Abbott Vice President, Finance and Chief Financial Officer Chris McNiffe Vice President, Marketing and Sales Chris Peters Vice President, Sales Michael Noonen Vice President, Business Development Samuel Wang Vice President, Process Technology David Harper Vice President, European Operations Brett Byers Vice President, General Counsel and Investor Relations Products and Processes 8x8 has developed a Video Information Architecture (VIA) incorporating programmable integrated circuits (ICs) and compression/decompression algorithms (codecs) for audio/video communications. -

IXP400 Software's Programmer's Guide
Intel® IXP400 Software Programmer’s Guide June 2004 Document Number: 252539-002c Intel® IXP400 Software Contents INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY RELATING TO SALE AND/OR USE OF INTEL PRODUCTS, INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT, OR OTHER INTELLECTUAL PROPERTY RIGHT. Intel Corporation may have patents or pending patent applications, trademarks, copyrights, or other intellectual property rights that relate to the presented subject matter. The furnishing of documents and other materials and information does not provide any license, express or implied, by estoppel or otherwise, to any such patents, trademarks, copyrights, or other intellectual property rights. Intel products are not intended for use in medical, life saving, life sustaining, critical control or safety systems, or in nuclear facility applications. The Intel® IXP400 Software v1.2.2 may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. MPEG is an international standard for video compression/decompression promoted by ISO. Implementations of MPEG CODECs, or MPEG enabled platforms may require licenses from various entities, including Intel Corporation. This document and the software described in it are furnished under license and may only be used or copied in accordance with the terms of the license. The information in this document is furnished for informational use only, is subject to change without notice, and should not be construed as a commitment by Intel Corporation. -

Intel740™ Graphics Accelerator
Intel740™ Graphics Accelerator Design Guide August 1998 Order Number: 290619-003 Information in this document is provided in connection with Intel products. No license, express or implied, by estoppel or otherwise, to any intellectual property rights is granted by this document. Except as provided in Intel's Terms and Conditions of Sale for such products, Intel assumes no liability whatsoever, and Intel disclaims any express or implied warranty, relating to sale and/or use of Intel products including liability or warranties relating to fitness for a particular purpose, merchantability, or infringement of any patent, copyright or other intellectual property right. Intel products are not intended for use in medical, life saving, or life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. Contact your local Intel sales office or your distributor to obtain the latest specifications and before placing your product order. The Intel740™ graphics accelerator may contain design defects or errors known as errata which may cause the products to deviate from published specifications. Such errata are not covered by Intel’s warranty. Current characterized errata are available upon request. I2C is a two-wire communications bus/protocol developed by Philips. SMBus is a subset of the I2C bus/protocol and was developed by Intel. Implementations of the I2C bus/protocol or the SMBus bus/protocol may require licenses from various entities, including Philips Electronics N.V. and North American Philips Corporation. Copies of documents which have an ordering number and are referenced in this document, or other Intel literature may be obtained by: calling 1-800-548-4725 or by visiting Intel's website at http://www.intel.com. -

Intel740™ Graphics Accelerator
Intel740™ Graphics Accelerator Software Developer’s Manual September 1998 Order Number: 290617-003 Information in this document is provided in connection with Intel products. No license, express or implied, by estoppel or otherwise, to any intellectual property rights is granted by this document. Except as provided in Intel's Terms and Conditions of Sale for such products, Intel assumes no liability whatsoever, and Intel disclaims any express or implied warranty, relating to sale and/or use of Intel products including liability or warranties relating to fitness for a particular purpose, merchantability, or infringement of any patent, copyright or other intellectual property right. Intel products are not intended for use in medical, life saving, or life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. The Intel740 graphics accelerator may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available upon request. I2C is a two-wire communications bus/protocol developed by Philips. SMBus is a subset of the I2C bus/protocol and was developed by Intel. Implementations of the I2C bus/protocol or the SMBus bus/protocol may require licenses from various entities, including Philips Electronics N.V. and North American Philips Corporation. Contact your local Intel sales office or your distributor to obtain the latest specifications and before placing your product order. Copies of documents which have an ordering number and are referenced in this document, or other Intel literature, may be obtained from: http://www.intel.com or call 1-800-548-4725 Copyright © Intel Corporation, 1997-1998 *Third-party brands and names are the property of their respective owners. -

Display Panel Debugging with the Intel Graphics Memory Controller Hub
Display Panel Debugging with the Intel Graphics Memory Controller Hub Application Note January 2005 Order Number: 305964-001 Display Panel Debugging with the Intel Graphics Memory Controller Hub INFORMATIONLegal Lines and Disclaimers IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. Intel products are not intended for use in medical, life saving, life sustaining, critical control or safety systems, or in nuclear facility applications. Intel may make changes to specifications and product descriptions at any time, without notice. Intel Corporation may have patents or pending patent applications, trademarks, copyrights, or other intellectual property rights that relate to the presented subject matter. The furnishing of documents and other materials and information does not provide any license, express or implied, by estoppel or otherwise, to any such patents, trademarks, copyrights, or other intellectual property rights. Designers must not rely on the absence or characteristics of any features or instructions marked “reserved” or “undefined.” Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. Intel processor numbers are not a measure of performance. -

Intel® Cluster Toolkit 2.0 Tutorial (Revision 20051122)
Intel® Cluster Toolkit 2.0 Tutorial (Revision 20051122) Table of Contents 1. Disclaimer and Legal Information ........................................................................................... 2 2. Introduction ............................................................................................................................. 3 3. Synopsis of New Features...................................................................................................... 4 4. Acronyms and Definitions ....................................................................................................... 6 5. Conventions ............................................................................................................................ 7 6. Intel Software Downloads and Installation for the Intel® Cluster Toolkit................................ 8 6.1 Installation of Intel® Cluster Toolkit on 32 Bit and 64 Bit Nodes which Share a Common /opt Directory ............................................................................................................................. 13 7. The Parallel Install Capability for the Intel® Cluster Toolkit Installer.................................... 14 8. The Software Architecture of the Intel® Cluster Toolkit........................................................ 15 9. Getting Started with Intel® MPI Library ................................................................................ 17 9.1 Launching MPD Daemons .......................................................................................... -
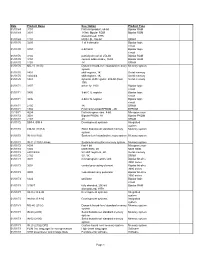
Date Product Name Description Product Type 01/01/69 3101 First
Date Product Name Description Product Type 01/01/69 3101 first Intel product, 64-bit Bipolar RAM 01/01/69 3301 1K-bit, Bipolar ROM Bipolar ROM discontinued, 1976 01/01/69 1101 MOS LSI, 256-bit SRAM 01/01/70 3205 1-of-8 decoder Bipolar logic circuit 01/01/70 3404 6-bit latch Bipolar logic circuit 01/01/70 3102 partially decoded, 256-bit Bipolar RAM 01/01/70 3104 content addressable, 16-bit Bipolar RAM 01/01/70 1103 1K DRAM 01/01/70 MU-10 (1103) Dynamic board-level standard memory Memory system system 01/01/70 1401 shift register, 1K Serial memory 01/01/70 1402/3/4 shift register, 1K Serial memory 01/01/70 1407 dynamic shift register, 200-bit (Dual Serial memory 100) 01/01/71 3207 driver for 1103 Bipolar logic circuit 01/01/71 3405 3-bit CTL register Bipolar logic circuit 01/01/71 3496 4-bit CTL register Bipolar logic circuit 01/01/71 2105 1K DRAM 01/01/71 1702 First commercial EPROM - 2K EPROM 11/15/71 4004 first microprocessor, 4-bit Microprocessor 01/01/72 3601 Bipolar PROM, 1K Bipolar PROM 01/01/72 2107 4K DRAM 01/01/72 SIM 4, SIM 8 Development systems Integrated system 01/01/72 CM-50 (1101A) Static board-level standard memory Memory system system 01/01/72 IN-10 (1103) System-level standard memory system Memory system 01/01/72 IN-11 (1103) Univac System-level custom memory system Memory system 01/01/72 8008 first 8-bit Microprocessor 01/01/72 1302 MOS ROM, 2K MOS ROM 01/01/72 2401/2/3/4 5V shift registers, 2K Serial memory 01/01/72 2102 5V, 1K SRAM 01/01/73 3001 microprogram control unit Bipolar bit-slice 3000 series 01/01/73 3002 central -

IXP42X Product Line of Network Processors and IXC1100 Control Plane Processor PCI 16-Bit Read Implementation
Intel® IXP42X Product Line of Network Processors and IXC1100 Control Plane Processor PCI 16-Bit Read Implementation Application Note September 2004 Document Number: 300375-002 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. Intel products are not intended for use in medical, life saving, life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked “reserved” or “undefined.” Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. Contact your local Intel sales office or your distributor to obtain the latest specifications and before placing your product order. Copies of documents which have an ordering number and are referenced in this document, or other Intel literature may be obtained by calling 1-800-548-4725 or by visiting Intel's website at -

Fabless: the Transformation of the Semiconductor Industry
DANIEL NENNI PAUL MCLELLAN FABLESS: THE TRANSFORMATION OF THE SEMICONDUCTOR INDUSTRY Foreword by Dr. Cliff Hou, VP of R&D, TSMC A SEMIWIKI.COM PROJECT FABLESS: The Transformation of The Semiconductor Industry DANIEL NENNI PAUL MCLELLAN WITH FOREWORD BY CLIFF HOU, VP OF R&D, TSMC A SEMIWIKI.COM PROJECT Fabless: The Transformation of the Semiconductor Industry Copyright 2013 by SemiWiki.com LLC. All rights reserved. Printed in the United States of America. Except as permitted under the United States Copyright Act of 1976, no part of this publication may be reproduced or distributed in any form or by any means, or stored in a data base or retrieval system without the prior written consent of the publisher. Authors: Daniel Nenni and Paul McLellan Editors: Beth Martin and Shushana Nenni ISBN: 978-1-4675-9307-6 BISAC: Business & Economics / General Fabless: The Transformation of the Semiconductor Industry Table of Contents Foreword .................................................................................................. iv Preface ......................................................................................................vi Chapter 1: The Semiconductor Century ............................................10 Chapter 2: The ASIC Business ............................................................21 In Their Own Words: VLSI Technology ......................................29 In Their Own Words: eSilicon Corporation .................................36 Chapter 3: The FPGA ..........................................................................44 -

Intel(R) C++ Intrinsic Reference
Intel® C++ Intrinsic Reference Document Number: 312482-003US Disclaimer and Legal Information INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. UNLESS OTHERWISE AGREED IN WRITING BY INTEL, THE INTEL PRODUCTS ARE NOT DESIGNED NOR INTENDED FOR ANY APPLICATION IN WHICH THE FAILURE OF THE INTEL PRODUCT COULD CREATE A SITUATION WHERE PERSONAL INJURY OR DEATH MAY OCCUR. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked "reserved" or "undefined." Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The information here is subject to change without notice. Do not finalize a design with this information. The products described in this document may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. Contact your local Intel sales office or your distributor to obtain the latest specifications and before placing your product order. -

Intel(R) Fortran Compiler Options
Intel(R) Fortran Compiler Options Document Number: 307780-003US Disclaimer and Legal Information INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. Intel products are not intended for use in medical, life saving, life sustaining, critical control or safety systems, or in nuclear facility applications. Intel may make changes to specifications and product descriptions at any time, without notice. The software described in this document may contain software defects which may cause the product to deviate from published specifications. Current characterized software defects are available on request. This document as well as the software described in it is furnished under license and may only be used or copied in accordance with the terms of the license. The information in this manual is furnished for informational use only, is subject to change without notice, and should not be construed as a commitment by Intel Corporation. Intel Corporation assumes no responsibility or liability for any errors or inaccuracies that may appear in this document or any software that may be provided in association with this document. Except as permitted by such license, no part of this document may be reproduced, stored in a retrieval system, or transmitted in any form or by any means without the express written consent of Intel Corporation.