Real-Time High-Resolution Background Matting
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Comparative Analysis of NLP Models for Google Meet Transcript Summarization
EasyChair Preprint № 5404 Comparative Analysis of NLP models for Google Meet Transcript Summarization Yash Agrawal, Atul Thakre, Tejas Tapas, Ayush Kedia, Yash Telkhade and Vasundhara Rathod EasyChair preprints are intended for rapid dissemination of research results and are integrated with the rest of EasyChair. April 28, 2021 Comparative Analysis of NLP models for Google Meet Transcript Summarization Yash Agrawal1,a) Atul Thakre1,b) Tejas Tapas1,c) Ayush Kedia1,d) Yash Telkhade1,e) Vasundhara Rathod1,f) 1) Computer Science & Engineering, Shri Ramdeobaba College of Engineering and Management, Nagpur, India a) [email protected] , +91 7083645470 b) [email protected] , +91 8956758226 c) [email protected] , +918380073925 d) [email protected] , +91 8459811323 e) [email protected] , +91 9021067230 f) [email protected], +918055225407 Abstract. Manual transcription and summarization is a cumbersome process necessitating the development of an efficient automatic text summarization technique. In this study, a Chrome extension is used for making the process of transcription hassle- free. It uses the text summarization technique to generate concise and succinct matter. Also, the tool is accessorized using Google Translation, to convert the processed text into users' desired language. This paper illustrates, how captions can be traced from the online meetings, corresponding to which, meeting transcript is sent to the backend where it is summarized using an NLP model. It also walks through three different NLP models and presents a comparative study among them. The NLTK model utilizes the sentence ranking technique for extractive summarization. Word Embedding model uses pre-trained Glove Embeddings for extractive summarization. The T5 model performs abstractive summarization using transformer architecture. -

Quick Deployment Guide for Enabling Remote Working with Hangouts Meet
Enabling Remote Working with Hangouts Meet and Hangouts Chat: A quick deployment guide Work Transformation: Productivity & Collaboration Contents About this guide 2 1. Requirements 4 1.1 General requirements 4 1.2 Network requirements 4 1.3 Optimize Meet traffic for remote workers 5 2. Set up G Suite 7 2.1 Enroll in G Suite 7 2.2 Verify your domain 12 2.3 Provision your users 14 Step 1: Open the user management interface 14 Step 2: Download the CSV template file 15 Step 3: Add your users to the CSV template 16 Step 4: Upload the CSV file and provision your users 17 Troubleshooting upload errors 17 2.4 Distribute user credentials 18 2.5 Disable out-of-scope G Suite applications 19 2.6 Configure Meet 20 2.7 Configure Chat 22 2.8 Securing your setup 22 3. Appendix: User guide 22 3.1 Documentation hub 22 3.2 Meet/Calendar integrations 23 Schedule your meetings with Google Calendar 23 Deploy the Microsoft Outlook Meet plug-in 24 1 About this guide Highlights To provide companies with a deployment plan and guide to quickly Purpose enable remote working using Google Meet and Google Chat. Intended IT administrators audience Key That the audience has the required access and rights documented in the assumptions general requirements. This document provides guidance for quickly bootstrapping your company with the adoption of Hangouts Meet (for video conferencing) and Hangouts Chat (for instant messaging). Since Hangouts Meet and Hangouts Chat are part of the G Suite offering, this guide will walk you through the steps required to create a G Suite account, configure the billing, create the users, secure your setup, and teach your users how to use the communication suite. -

W Shekatkar Committee Report W Atmanirbhar Bharat Abhiyan W
MONTHLY MAGAZINE FOR TNPSC EXAMS MAY–2020 w Atmanirbhar Bharat Abhiyan w Cleanest City List w Shekatkar Committee Report w Konark Sun Temple w Char Dham Project w Samagra Shiksha Abhiyan VETRII IAS STUDY CIRCLE TNPSC CURRENT AFFAIRS MAY - 2020 An ISO 9001 : 2015 Institution | Providing Excellence Since 2011 Head Office Old No.52, New No.1, 9th Street, F Block, 1st Avenue Main Road, (Near Istha siddhi Vinayakar Temple), Anna Nagar East – 600102. Phone: 044-2626 5326 | 98844 72636 | 98844 21666 | 98844 32666 Branches SALEM KOVAI No.189/1, Meyanoor Road, Near ARRS Multiplex, (Near Salem New No.347, D.S.Complex (3rd floor), Nehru Street,Near Gandhipuram bus Stand), Opp. Venkateshwara Complex, Salem - 636004. Central Bus Stand, Ramnagar, Kovai - 9 0427-2330307 | 95001 22022 75021 65390 Educarreerr Location Vivekanandha Educational Institutions for Women, Elayampalayam, Tiruchengode - TK Namakkal District - 637 205. 04288 - 234670 | 91 94437 34670 Patrician College of Arts and Science, 3, Canal Bank Rd, Gandhi Nagar, Opposite to Kotturpuram Railway Station, Adyar, Chennai - 600020. 044 - 24401362 | 044 - 24426913 Sree Saraswathi Thyagaraja College Palani Road, Thippampatti, Pollachi - 642 107 73737 66550 | 94432 66008 | 90951 66009 www.vetriias.com My Dear Aspirants, Greetings to all of you! “What we think we become” Gautama Buddha. We all have dreams. To make dreams come into reality it takes a lot of determination, dedication, self discipline and continuous effort. We at VETRII IAS Study Circle are committed to provide the right guidance, quality coaching and help every aspirants to achieve his or her life’s cherished goal of becoming a civil servant. -

What's New for Google in 2020?
Kevin A. McGrail [email protected] What’s new for Google in 2020? Introduction Kevin A. McGrail Director, Business Growth @ InfraShield.com Google G Suite TC, GDE & Ambassador https://www.linkedin.com/in/kmcgrail About the Speaker Kevin A. McGrail Director, Business Growth @ InfraShield.com Member of the Apache Software Foundation Release Manager for Apache SpamAssassin Google G Suite TC, GDE & Ambassador. https://www.linkedin.com/in/kmcgrail 1Q 2020 STORY TIME: Google Overlords, Pixelbook’s Secret Titan Key, & Googlesplain’ing CES Jan 2020 - No new new hardware was announced at CES! - Google Assistant & AI Hey Google, Read this Page Hey Google, turn on the lights at 6AM Hey Google, Leave a Note... CES Jan 2020 (continued) Google Assistant & AI Speed Dial Interpreter Mode (Transcript Mode) Hey Google, that wasn't for you Live Transcripts Hangouts Meet w/Captions Recorder App w/Transcriptions Live Transcribe Coming Next...: https://mashable.com/article/google-translate-transcription-audio/ EXPERT TIP: What is Clipping? And Whispering! Streaming Games - Google Stadia Android Tablets No more Android Tablets? AI AI AI AI AI Looker acquisition for 2.6B https://www.cloudbakers.com/blog/why-cloudbakers-loves-looker-for-business-intelligence-bi From Thomas Kurian, head of Google Cloud: “focusing on digital transformation solutions for retail, healthcare, financial services, media and entertainment, and industrial and manufacturing verticals. He highlighted Google's strengths in AI for each vertical, such as behavioral analytics for retail, -

Google Meet Guide
Google Meet Guide How to Schedule a Meeting (class sessions and office hours) 1. Access Hunter SOE Google Calendar 2. Create a new event and select More Options 3. Click Add Conferencing and then Hangouts Meet 4. Add student myhunter.cuny.edu or huntersoe.org email addresses under Guests 5. Select the paperclip symbol to attach optional documents, presentations, videos, etc. 6. Use the description box for relevant information 7. Click Save and then Send Every person on the guest list will receive an email with the meeting link and all attachments. Scheduled meetings can be accessed from the email link, Google Calendar, or https://meet.google.com. How to Create an Instant Meeting 1. Go to https://meet.google.com 2. Click Start a Meeting > Continue 3. Allow access to camera and microphone 4. Click Start Meeting 5. To add participants: ▪ Manually enter email addresses in the tab ▪ Copy meeting link and send it in an email, Blackboard announcement, or Google Classroom post How to Join a Meeting 1. Click on the meeting link to instantly join or type in the meeting code on https://meet.google.com 2. Allow access to camera and microphone How to Leave a Meeting 1. Press the symbol to exit 2. Click Rejoin to reenter How to Present in a Meeting (PowerPoints, documents, etc.) 1. Open the file(s) before or during the meeting 2. Select Present Now > A window or Entire screen > Share ‘A window’ allows you to present a single file while ‘Entire screen’ allows you to show multiple files on your screen without stopping and starting a new presentation 3. -

Conferencing with Google Meet
Conferencing with Google Meet Table of Contents Google Meet 2 Schedule a Google Meet 2 Start a Meeting 4 Conduct a Meeting 6 Present Now 7 Settings 7 People and Chat 8 Record a Meeting 9 Center for Innovation in Teaching and Research !1 Google Meet Google Meet will allow you to conduct HD video conferencing with up to 30 students. Google Meet is fully integrated with our WIU gmail accounts, so you can join meetings directly from a Calendar event or email invite. You also have the ability to allow for non WIU participants. Great for having a guest speaker. Schedule a Google Meet The best way to set up a Google Meet is to schedule one using your Google calendar. Do the following: • Make sure you are logged into your WIU Google account. • Open your Google calendar. • Click on the day you would like to schedule the meeting. • Add a title in the space provided and click More Options. Add title Click More Options • Uncheck the All day check box and set the time you want the meeting to occur. • Under the Event Details, click the Add conferencing drop down and choose Hangouts Meet. A View Details link will appear to the right with info about the meeting, including a direct link. • Use the Add guests section to type in the email addresses of your students to invite them to the meeting. (Note: you can copy all of your student email addresses at once from the CITR Attendance Tracker). • Click Save to save the calendar event and meeting. -
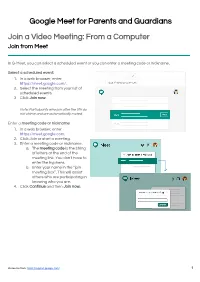
Google Meet for Parents and Guardians Join a Video Meeting: from a Computer Join from Meet
Google Meet for Parents and Guardians Join a Video Meeting: From a Computer Join from Meet In G-Meet, you can select a scheduled event or you can enter a meeting code or nickname. Select a scheduled event: 1. In a web browser, enter https://meet.google.com/. 2. Select the meeting from your list of scheduled events. 3. Click Join now. Note: Participants who join after the 5th do not chime and are automatically muted. Enter a meeting code or nickname: 1. In a web browser, enter https://meet.google.com. 2. Click Join or start a meeting. 3. Enter a meeting code or nickname. a. The meeting code is the string of letters at the end of the meeting link. You don't have to enter the hyphens. b. Enter your name in the “join meeting box”. This will assist others who are participating in knowing who you are. 4. Click Continue and then Join now. Resource from: https://support.google.com/ 1 Join with a meeting link URL Sometimes there isn’t enough time to schedule a meeting. With Google Meet, you can join an impromptu video meeting by clicking the meeting link URL sent to you in a text or email. 1. Click the meeting link sent to you in a chat message or email. 2. Follow the onscreen prompts to join the meeting. An existing participant might need to approve you if you try to join another organization’s meeting or don't have a Google Account. Join without a Google Account You don't need a Google Account to participate in Google Meet video meetings. -
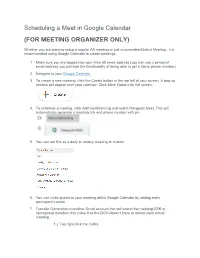
Scheduling a Meet in Google Calendar (FOR MEETING ORGANIZER ONLY)
Scheduling a Meet in Google Calendar (FOR MEETING ORGANIZER ONLY) Whether you are wanting setup a regular AA meeting or just a committee/District Meeting , it is recommended using Google Calendar to create meetings. 1. Make sure you are logged into your Area 58 email address (you can use a personal email address you just lose the functionality of being able to get a dial in phone number) 2. Navigate to your Google Calendar. 3. To create a new meeting, click the Create button in the top left of your screen. A pop-up window will appear over your calendar. Click More Options for full screen. 4. To schedule a meeting, click Add Conferencing and select Hangouts Meet. This will automatically generate a meeting link and phone number with pin 5. You can set this as a daily or weekly meeting or custom 6. You can invite guests to your meeting within Google Calendar by adding each participant’s email. 7. Transfer Ownership to another Gmail account that will attend the meeting(GSR or homegroup member) this make it so the DCM doesn’t have to attend each virtual meeting. 1.) Top right click the 3 dots 2.) Then click change owner 3.) Enter Gmail Account of GSR or Homegroup member you would like to transfer ownership to Note the following: o Guests do not need a google account to receive to a Google Calendar event. They will receive a link to their email account. Anonymity for Online Google Meet Some may be concerned about personal anonymity and be alarmed that full names may be displayed next to their video. -
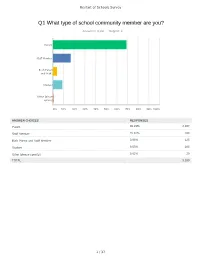
Restart of School Survey Responses
Restart of Schools Survey Q1 What type of school community member are you? Answered: 3,160 Skipped: 4 Parent Staff Member Both Parent and Staff... Student Other (please specify) 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES Parent 69.21% 2,187 Staff Member 16.87% 533 Both Parent and Staff Member 3.96% 125 Student 9.05% 286 Other (please specify) 0.92% 29 TOTAL 3,160 1 / 37 Restart of Schools Survey # OTHER (PLEASE SPECIFY) DATE 1 Grandparent 7/27/2020 1:57 PM 2 Resident 7/27/2020 12:02 PM 3 Grandparent 7/24/2020 11:20 PM 4 Grandmother 7/23/2020 12:18 PM 5 Grandparent 7/23/2020 12:06 PM 6 Grandparent 7/23/2020 5:31 AM 7 Parent/staff member 7/21/2020 6:59 PM 8 graduate of swmhs 7/21/2020 11:36 AM 9 Bus driver 7/21/2020 8:00 AM 10 12 month Secretary 7/16/2020 8:57 AM 11 Grandparent 7/15/2020 10:08 PM 12 Grandparent 7/15/2020 12:28 PM 13 Grandmother 7/15/2020 1:52 AM 14 Lunch/Playground Aide 7/13/2020 8:29 PM 15 I 7/12/2020 10:47 PM 16 Parent with student assisting in questionnaire 7/12/2020 8:55 PM 17 Grandparent 7/11/2020 5:53 PM 18 I 7/11/2020 11:47 AM 19 Family member 7/11/2020 11:38 AM 20 Spouse of staff member 7/10/2020 10:43 PM 21 Grandparent 7/10/2020 8:11 PM 22 Parent of Sayreville student who also works in another school district in NJ 7/10/2020 1:35 PM 23 Potential preschool parent/parent of catholic school student (runs in conjunction with with 7/10/2020 12:47 PM Sayreville public schools schedule) 24 LegalGuardian 7/10/2020 12:38 PM 25 Substitute teacher 7/10/2020 11:55 AM 26 grandmother 7/10/2020 11:30 AM 27 Grandparent 7/10/2020 11:12 AM 28 grand mother 7/10/2020 11:02 AM 29 Guardian 7/10/2020 10:41 AM 2 / 37 Restart of Schools Survey Q2 Select the school building(s) you either work or learn in or that your child(ren) learn in. -

Solving for Operational Efficiency with Google Cloud
Google Cloud Whitepaper June 2020 Solving for Operational Efciency with Google Cloud 1 Why operational efficiency matters now As businesses consider how to weather the road ahead, many are finding they need to make tough decisions about how to allocate resources. For most, it’s not simply about spending less, it’s about knowing which projects to prioritize, even if with limited funding, in order to maintain business continuity and ensure longevity. But this is easier said than done. Evaluating which projects will generate the right business outcomes and cost efficiencies presents a specific set of challenges, such as: • Unpredictable business conditions—Businesses must keep pace with dramatically changing requirements to survive, and thrive. To innovate quickly, IT teams need solutions that decrease their time to market, while also providing the agility and scalability they need to address any requirement thrown their way. • New investment needs—Businesses must adapt to new With current business models while also ensuring their teams have the tools they need to be productive from locations outside the business conditions, office. IT must now prioritize projects that weren’t in the it’s essential to be budget to ensure the survival of the business and the productivity of their workforce. empowered with facts, knowledge, • Limited visibility and control—Not all businesses have the and best practices. complete picture of their IT spend to make educated decisions about where and how to reduce costs, or whether to reinvest in other strategic areas. IT needs granular visibility and intelligent services that take the guesswork out of cost and resource optimization, while also providing robust governance that reduces the risk of overspending. -

Saint John the Evangelist School Health Plan Overview
Saint John the Evangelist School Health Plan Overview Mission Statement Saint John the Evangelist Catholic School provides a Christ-centered atmosphere that recognizes the God-given gifts inherent within each child on the journey toward spiritual and academic excellence. Philosophy of Learning Saint John the Evangelist School integrates Catholic teachings and virtues throughout our school culture. We foster a challenging and inclusive academic program addressing the diverse needs of students. In partnership with families and the parish community, we encourage students to serve others while growing in the image of Christ. Introduction: Saint John the Evangelist Catholic School (SJES) will reopen schools five days a week beginning on Wednesday, August 26, 2020. Preschool begins after Labor Day, Tuesday September 8th. Through research and feedback from our school community as well as guidance and consultation from the Office of Catholic Schools, we are confident we can open our school safely and effectively. Additionally, our Return to School Committee has been meeting weekly since late June and we will continue to meet on a weekly basis as we prepare to welcome staff on Monday, August 17th and students the following week. Saint John will comply with state and local public health directives in planning for reopening. Below is a summary of the approaches we will take. Please Note: All school health policies and procedures may change based on guidelines provided to our school by the Fauquier County Health Department, the Virginia Department of Health, the CDC, the Diocese of Arlington, and the Governor of Virginia. As these changes occur, the school will do its best to communicate these changes to you. -

Google Meet for Parents
Google Meet for Parents Google Meet is designed to work using the Chrome browser. You will need the Google Hangouts Meet app if using it on an iPad, iPhone or Android device. Computer You can enter a Google Meet with or without a Gmail account. Open Chrome. Click the link that was emailed to you or provided on Veracross. The link will be something like: https://meet.google.com/xxx-xxxx- xxx. The last 10 digits will be different for every Meet that a teacher sets up. When you see this screen, click Ask to join. If you are logged in to a Gmail account, a message will be sent to the teacher that Someone named your name wants to join this meeting. The teacher will either Deny entry or Admit. If you are not logged in to a Gmail account, you will need to enter your name on the Ask to join page and then click the Ask to join button. A message will be sent to the teacher that Someone named your name wants to join this meeting. The teacher will either Deny entry or Admit. If you see a pop-up window asking you to allow the camera and microphone for meet.google.com, click ALLOW. Click Dismiss on the Allow Meet to use your camera and microphone message. Join a Google Meet without a Gmail Account if the link does not work Try using an incognito window in Chrome. Enter the code provided by the teacher. If you see a pop-up window asking you to allow the camera and microphone for meet.google.com, click ALLOW.