Comparative Analysis of NLP Models for Google Meet Transcript Summarization
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Quick Deployment Guide for Enabling Remote Working with Hangouts Meet
Enabling Remote Working with Hangouts Meet and Hangouts Chat: A quick deployment guide Work Transformation: Productivity & Collaboration Contents About this guide 2 1. Requirements 4 1.1 General requirements 4 1.2 Network requirements 4 1.3 Optimize Meet traffic for remote workers 5 2. Set up G Suite 7 2.1 Enroll in G Suite 7 2.2 Verify your domain 12 2.3 Provision your users 14 Step 1: Open the user management interface 14 Step 2: Download the CSV template file 15 Step 3: Add your users to the CSV template 16 Step 4: Upload the CSV file and provision your users 17 Troubleshooting upload errors 17 2.4 Distribute user credentials 18 2.5 Disable out-of-scope G Suite applications 19 2.6 Configure Meet 20 2.7 Configure Chat 22 2.8 Securing your setup 22 3. Appendix: User guide 22 3.1 Documentation hub 22 3.2 Meet/Calendar integrations 23 Schedule your meetings with Google Calendar 23 Deploy the Microsoft Outlook Meet plug-in 24 1 About this guide Highlights To provide companies with a deployment plan and guide to quickly Purpose enable remote working using Google Meet and Google Chat. Intended IT administrators audience Key That the audience has the required access and rights documented in the assumptions general requirements. This document provides guidance for quickly bootstrapping your company with the adoption of Hangouts Meet (for video conferencing) and Hangouts Chat (for instant messaging). Since Hangouts Meet and Hangouts Chat are part of the G Suite offering, this guide will walk you through the steps required to create a G Suite account, configure the billing, create the users, secure your setup, and teach your users how to use the communication suite. -

Geographical Connections
WorldWise resource pack Making geographical connections WorldWise Week: 20-24 June 2016 WorldWise Week 2016: Making geographical connections This pack of resources provide activities for students from primary to post-16 around the theme ‘Making Geographical Connections‘, to consider how we are all surrounded by geographically based connections as well as disconnections; whether they be via transport and travel or technology, or even due to flooding. Resources: How do we connect? (Early years and primary, pp. 3–5) These activities for early years and primary pupils explore what making connections means and how people connect with each other. Mapping connections (Cross-curricular, pp. 6–7) These activities use a range of maps to explore how the world is connected on a global and local scale and connections with oceans and seas. Connecting with the future (Cross-curricular, pp. 8–9) These activities consider ways we currently connect with others and how we are likely to connect in the future. Transport and travel connections (Cross-curricular, pp. 10–12) This resource looks at how transport and travel enables us to make connections, and suggests ways of getting out of the classroom. Wet, Wet, Wet – Flooding connections (Secondary, pp. 13–18) These activities investigate how flooding can result from a combination of connected factors. How do students with special educational needs connect with the world? (Cross-curricular, pp. 19–20) This resource focuses on connecting SEN students with the outside world, and can be adapted for both primary and secondary groups. How can you use this year’s WorldWise Week resource pack? These resources have been written for young people of all ages to appreciate the value of school geography. -

W Shekatkar Committee Report W Atmanirbhar Bharat Abhiyan W
MONTHLY MAGAZINE FOR TNPSC EXAMS MAY–2020 w Atmanirbhar Bharat Abhiyan w Cleanest City List w Shekatkar Committee Report w Konark Sun Temple w Char Dham Project w Samagra Shiksha Abhiyan VETRII IAS STUDY CIRCLE TNPSC CURRENT AFFAIRS MAY - 2020 An ISO 9001 : 2015 Institution | Providing Excellence Since 2011 Head Office Old No.52, New No.1, 9th Street, F Block, 1st Avenue Main Road, (Near Istha siddhi Vinayakar Temple), Anna Nagar East – 600102. Phone: 044-2626 5326 | 98844 72636 | 98844 21666 | 98844 32666 Branches SALEM KOVAI No.189/1, Meyanoor Road, Near ARRS Multiplex, (Near Salem New No.347, D.S.Complex (3rd floor), Nehru Street,Near Gandhipuram bus Stand), Opp. Venkateshwara Complex, Salem - 636004. Central Bus Stand, Ramnagar, Kovai - 9 0427-2330307 | 95001 22022 75021 65390 Educarreerr Location Vivekanandha Educational Institutions for Women, Elayampalayam, Tiruchengode - TK Namakkal District - 637 205. 04288 - 234670 | 91 94437 34670 Patrician College of Arts and Science, 3, Canal Bank Rd, Gandhi Nagar, Opposite to Kotturpuram Railway Station, Adyar, Chennai - 600020. 044 - 24401362 | 044 - 24426913 Sree Saraswathi Thyagaraja College Palani Road, Thippampatti, Pollachi - 642 107 73737 66550 | 94432 66008 | 90951 66009 www.vetriias.com My Dear Aspirants, Greetings to all of you! “What we think we become” Gautama Buddha. We all have dreams. To make dreams come into reality it takes a lot of determination, dedication, self discipline and continuous effort. We at VETRII IAS Study Circle are committed to provide the right guidance, quality coaching and help every aspirants to achieve his or her life’s cherished goal of becoming a civil servant. -

Real-Time High-Resolution Background Matting
Real-Time High-Resolution Background Matting Shanchuan Lin* Andrey Ryabtsev* Soumyadip Sengupta Brian Curless Steve Seitz Ira Kemelmacher-Shlizerman University of Washington flinsh,ryabtsev,soumya91,curless,seitz,[email protected] Zoom input and background shot Zoom with new background Our Zoom plugin with new background Figure 1: Current video conferencing tools like Zoom can take an input feed (left) and replace the background, often introducing artifacts, as shown in the center result with close-ups of hair and glasses that still have the residual of the original background. Leveraging a frame of video without the subject (far left inset), our method produces real-time, high-resolution background matting without those common artifacts. The image on the right is our result with the corresponding close-ups, screenshot from our Zoom plugin implementation. Abstract ment can enhance privacy, particularly in situations where a user may not want to share details of their location and We introduce a real-time, high-resolution background re- environment to others on the call. A key challenge of this placement technique which operates at 30fps in 4K resolu- video conferencing application is that users do not typically tion, and 60fps for HD on a modern GPU. Our technique is have access to a green screen or other physical props used to based on background matting, where an additional frame of facilitate background replacement in movie special effects. the background is captured and used in recovering the al- pha matte and the foreground layer. The main challenge is While many tools now provide background replacement to compute a high-quality alpha matte, preserving strand- functionality, they yield artifacts at boundaries, particu- level hair details, while processing high-resolution images larly in areas where there is fine detail like hair or glasses in real-time. -

What's New for Google in 2020?
Kevin A. McGrail [email protected] What’s new for Google in 2020? Introduction Kevin A. McGrail Director, Business Growth @ InfraShield.com Google G Suite TC, GDE & Ambassador https://www.linkedin.com/in/kmcgrail About the Speaker Kevin A. McGrail Director, Business Growth @ InfraShield.com Member of the Apache Software Foundation Release Manager for Apache SpamAssassin Google G Suite TC, GDE & Ambassador. https://www.linkedin.com/in/kmcgrail 1Q 2020 STORY TIME: Google Overlords, Pixelbook’s Secret Titan Key, & Googlesplain’ing CES Jan 2020 - No new new hardware was announced at CES! - Google Assistant & AI Hey Google, Read this Page Hey Google, turn on the lights at 6AM Hey Google, Leave a Note... CES Jan 2020 (continued) Google Assistant & AI Speed Dial Interpreter Mode (Transcript Mode) Hey Google, that wasn't for you Live Transcripts Hangouts Meet w/Captions Recorder App w/Transcriptions Live Transcribe Coming Next...: https://mashable.com/article/google-translate-transcription-audio/ EXPERT TIP: What is Clipping? And Whispering! Streaming Games - Google Stadia Android Tablets No more Android Tablets? AI AI AI AI AI Looker acquisition for 2.6B https://www.cloudbakers.com/blog/why-cloudbakers-loves-looker-for-business-intelligence-bi From Thomas Kurian, head of Google Cloud: “focusing on digital transformation solutions for retail, healthcare, financial services, media and entertainment, and industrial and manufacturing verticals. He highlighted Google's strengths in AI for each vertical, such as behavioral analytics for retail, -

Caine Prize Annual Report 2015.Indd
THE CAINE PRIZE FOR AFRICAN WRITING Always something new from Africa Annual report 2015 2015 Shortlisted writers in Oxford, UK (from left): Masande Ntshanga, F.T. Kola, Elnathan John, Namwali Serpell and Segun Afolabi. The Caine Prize is supported by Sigrid Rausing and Eric Abraham Other partners include: The British Council, The Wyfold Charitable Trust, the Royal Over-Seas League, Commonwealth Writers (an initiative of the Commonwealth Foundation), The Morel Trust, Adam and Victoria Freudenheim, John and Judy Niepold, Arindam Bhattacharjee and other generous donors. Report on the 2015 Caine Prize and related activities 2015 Prize “Africa’s most important literary award.” International Herald Tribune This year’s Prize was won by Namwali Serpell from Zambia, for her story ‘The Sack’ published in Africa39 (Bloomsbury, London, 2014). Namwali Serpell’s first published story, ‘Muzungu’, was shortlisted for the 2010 Caine Prize for African Writing. In 2014, she was selected as one of the most promising African writers for the Africa39 Anthology, a project of the Hay Festival. Since winning the Caine Prize in July, Chatto & Windus in the UK and Hogarth in the US have bought world rights to her debut novel The Old Drift. For the first time in the history of the Caine Prize, the winner shared her prize money with the other shortlisted writers. Namwali Serpell next to the bust Chair of judges, Zoë Wicomb praised ‘The Sack’ as ‘an extraordinary story of the late Sir Michael Caine. about the aftermath of revolution with its liberatory promises shattered. It makes demands on the reader and challenges conventions of the genre. -

Integrating Deep Contextualized Word Embeddings Into Text Summarization Systems
Alma Mater Studiorum · Universita` di Bologna SCUOLA DI SCIENZE Corso di Laurea Magistrale in Informatica INTEGRATING DEEP CONTEXTUALIZED WORD EMBEDDINGS INTO TEXT SUMMARIZATION SYSTEMS Relatore: Presentata da: Prof. Fabio Tamburini Claudio Mastronardo Sessione I Anno Accademico 2018/2019 "Considerate la vostra semenza: fatti non foste a viver come bruti ma per seguir virtute e canoscenza" Dante Alighieri, Inferno XXVI, 116-120 Summary In this thesis deep learning tools will be used to tackle one of the most difficult natural language processing (NLP) problems: text summarization. Given a text, the goal is to generate a summary distilling and compressing information from the whole source text. Early approaches tried to capture the meaning of text by using rules written by human. After this symbolic rule-based era, statistical approaches for NLP have taken over rule-based ones. In the last years Deep Learning (DL) has positively impacted ev- ery NLP area, including text summarization. In this work the power of pointer-generator models [See et al., 2017] is leveraged in combination with pre-trained deep contextualized word embeddings [Peters et al., 2018]. We evaluate this approach on the two largest text summarization datasets avail- able right now: the CNN/Daily Mail dataset and the Newsroom dataset. The CNN/Daily Mail has been generated from the Q&A dataset published by DeepMind [Hermann et al., 2015], by concatenating sentences highlights leading to multi-sentence summaries. The Newsroom dataset is the first dataset explicitly built for text summarization [Grusky et al., 2018]. It is comprised of ∼1 million article-summary pairs having more or less degrees of extractiveness/abstractiveness and several compression ratios. -

Google Meet Guide
Google Meet Guide How to Schedule a Meeting (class sessions and office hours) 1. Access Hunter SOE Google Calendar 2. Create a new event and select More Options 3. Click Add Conferencing and then Hangouts Meet 4. Add student myhunter.cuny.edu or huntersoe.org email addresses under Guests 5. Select the paperclip symbol to attach optional documents, presentations, videos, etc. 6. Use the description box for relevant information 7. Click Save and then Send Every person on the guest list will receive an email with the meeting link and all attachments. Scheduled meetings can be accessed from the email link, Google Calendar, or https://meet.google.com. How to Create an Instant Meeting 1. Go to https://meet.google.com 2. Click Start a Meeting > Continue 3. Allow access to camera and microphone 4. Click Start Meeting 5. To add participants: ▪ Manually enter email addresses in the tab ▪ Copy meeting link and send it in an email, Blackboard announcement, or Google Classroom post How to Join a Meeting 1. Click on the meeting link to instantly join or type in the meeting code on https://meet.google.com 2. Allow access to camera and microphone How to Leave a Meeting 1. Press the symbol to exit 2. Click Rejoin to reenter How to Present in a Meeting (PowerPoints, documents, etc.) 1. Open the file(s) before or during the meeting 2. Select Present Now > A window or Entire screen > Share ‘A window’ allows you to present a single file while ‘Entire screen’ allows you to show multiple files on your screen without stopping and starting a new presentation 3. -

Conferencing with Google Meet
Conferencing with Google Meet Table of Contents Google Meet 2 Schedule a Google Meet 2 Start a Meeting 4 Conduct a Meeting 6 Present Now 7 Settings 7 People and Chat 8 Record a Meeting 9 Center for Innovation in Teaching and Research !1 Google Meet Google Meet will allow you to conduct HD video conferencing with up to 30 students. Google Meet is fully integrated with our WIU gmail accounts, so you can join meetings directly from a Calendar event or email invite. You also have the ability to allow for non WIU participants. Great for having a guest speaker. Schedule a Google Meet The best way to set up a Google Meet is to schedule one using your Google calendar. Do the following: • Make sure you are logged into your WIU Google account. • Open your Google calendar. • Click on the day you would like to schedule the meeting. • Add a title in the space provided and click More Options. Add title Click More Options • Uncheck the All day check box and set the time you want the meeting to occur. • Under the Event Details, click the Add conferencing drop down and choose Hangouts Meet. A View Details link will appear to the right with info about the meeting, including a direct link. • Use the Add guests section to type in the email addresses of your students to invite them to the meeting. (Note: you can copy all of your student email addresses at once from the CITR Attendance Tracker). • Click Save to save the calendar event and meeting. -
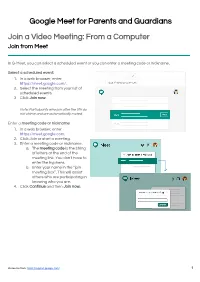
Google Meet for Parents and Guardians Join a Video Meeting: from a Computer Join from Meet
Google Meet for Parents and Guardians Join a Video Meeting: From a Computer Join from Meet In G-Meet, you can select a scheduled event or you can enter a meeting code or nickname. Select a scheduled event: 1. In a web browser, enter https://meet.google.com/. 2. Select the meeting from your list of scheduled events. 3. Click Join now. Note: Participants who join after the 5th do not chime and are automatically muted. Enter a meeting code or nickname: 1. In a web browser, enter https://meet.google.com. 2. Click Join or start a meeting. 3. Enter a meeting code or nickname. a. The meeting code is the string of letters at the end of the meeting link. You don't have to enter the hyphens. b. Enter your name in the “join meeting box”. This will assist others who are participating in knowing who you are. 4. Click Continue and then Join now. Resource from: https://support.google.com/ 1 Join with a meeting link URL Sometimes there isn’t enough time to schedule a meeting. With Google Meet, you can join an impromptu video meeting by clicking the meeting link URL sent to you in a text or email. 1. Click the meeting link sent to you in a chat message or email. 2. Follow the onscreen prompts to join the meeting. An existing participant might need to approve you if you try to join another organization’s meeting or don't have a Google Account. Join without a Google Account You don't need a Google Account to participate in Google Meet video meetings. -

Automatic Text Summarization of Article (NEWS) Using Lexical Chains and Wordnet
International Journal of Advanced Science and Technology Vol. 29, No.4, (2020), pp. 3242 – 3258 Automatic Text Summarization of Article (NEWS) Using Lexical Chains and WordNet Mr.K.JanakiRaman1and Mrs.K.Meenakshi2 PG Student1, Assistant Professor (OG)2 Department of Information Technology1,2 SRM Institute of Science and Technology,Chengalpattu1,2 [email protected],[email protected] Abstract Selection of important information or extracting the same from the original text of large size and present that data in the form of a smaller summaries for easy reading is called as Text Summarization. This process of rephrasing is where we get the shorter version of a text document. As such the Summarizer gives the summary of the News. With the help of few algorithms (like Position of the sentence / phrases, Similarity between the sentences in the main body and the title, Semantics, etc) we can create a Summarizer. Text Summarization has now become the need for numerous applications, for instance, market review for analysts, search engine for phones or PCs, business analysis for those who does business. Outline picks up the necessary data in less time. There are two significant methodologies for a synopsis (Extractive and Abstractive outline) which are talked about in detail later. The procedure conveyed for outline ranges from structured to linguistic. In this paper, we propose a system where we centre around the issue to distinguish the most significant piece of the record and produce an intelligent synopsis for them. In our method, we don't require total semantic interpretation for the substance present, rather, we just make a synopsis utilizing a model of point development in the substance shaped from lexical chains. -
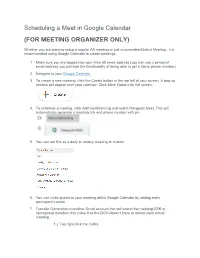
Scheduling a Meet in Google Calendar (FOR MEETING ORGANIZER ONLY)
Scheduling a Meet in Google Calendar (FOR MEETING ORGANIZER ONLY) Whether you are wanting setup a regular AA meeting or just a committee/District Meeting , it is recommended using Google Calendar to create meetings. 1. Make sure you are logged into your Area 58 email address (you can use a personal email address you just lose the functionality of being able to get a dial in phone number) 2. Navigate to your Google Calendar. 3. To create a new meeting, click the Create button in the top left of your screen. A pop-up window will appear over your calendar. Click More Options for full screen. 4. To schedule a meeting, click Add Conferencing and select Hangouts Meet. This will automatically generate a meeting link and phone number with pin 5. You can set this as a daily or weekly meeting or custom 6. You can invite guests to your meeting within Google Calendar by adding each participant’s email. 7. Transfer Ownership to another Gmail account that will attend the meeting(GSR or homegroup member) this make it so the DCM doesn’t have to attend each virtual meeting. 1.) Top right click the 3 dots 2.) Then click change owner 3.) Enter Gmail Account of GSR or Homegroup member you would like to transfer ownership to Note the following: o Guests do not need a google account to receive to a Google Calendar event. They will receive a link to their email account. Anonymity for Online Google Meet Some may be concerned about personal anonymity and be alarmed that full names may be displayed next to their video.