Mozilla Firefox
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
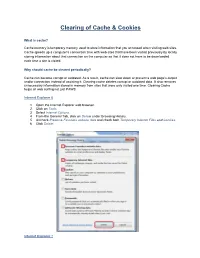
Clearing of Cache & Cookies
Clearing of Cache & Cookies What is cache? Cache memory is temporary memory used to store information that you accessed when visiting web sites. Cache speeds up a computer’s connection time with web sites that have been visited previously by locally storing information about that connection on the computer so that it does not have to be downloaded each time a site is visited. Why should cache be cleared periodically? Cache can become corrupt or outdated. As a result, cache can slow down or prevent a web page’s output and/or connection instead of assisting it. Clearing cache deletes corrupt or outdated data. It also removes unnecessary information stored in memory from sites that were only visited one time. Clearing Cache helps all web surfing not just PAWS. Internet Explorer 8 1. Open the Internet Explorer web browser. 2. Click on Tools. 3. Select Internet Options. 4. From the General Tab, click on Delete under Browsing History. 5. Uncheck Preserve Favorites website data and check both Temporary Internet Files and Cookies. 6. Click Delete. Internet Explorer 7 1. Open the Internet Explorer web browser. 2. Click on Tools. 3. Click on Internet Options. 4. Click on Delete under Browsing History. 5. Click Delete cookies. 6. When prompted, click Yes. 7. Click on Delete Internet Files. 8. When prompted, click Yes. 9. Click Close. 10. Click OK. 11. Close and reopen the browser for the changes to go into effect. Internet Explorer 6 1. Open the Internet Explorer web browser. 2. Click on Tools. 3. Click on Internet Options. 4. -

La Promotion Du Web Ouvert a Bien Changé Mais Mozilla Est Toujours Là
La promotion du Web Ouvert a bien changé mais Mozilla est toujours là Promouvoir le Web ouvert est l’une des missions de Mozilla. Mission parfaitement assumée et réussie il y a quelques années avec l’avènement de Firefox qui obligea Internet Explorer à quitter son arrogance pour rentrer dans le rang et se montrer plus respectueux des standards et donc des internautes. Sauf qu’aujourd’hui la donne a sensiblement changé. Avec la mobilité, les stores, les apps, les navigateurs intégrés, etc. c’est en effet un Web bien plus complexe qui se présente devant nous. Un Web enthousiasmant[1] mais plein d’embûches pour ceux qui sont attachés à son ouverture et à sa neutralité. C’est tout l’objet de ce très intéressant récent billet du développeur Mozilla Robert O’Callahan. Des changements dans la façon de promouvoir le Web Ouvert Shifts In Promoting The Open Web Robert O’Callahan – 30 septembre 201 – Blog personnel (Traduction Framalang : Antistress et Goofy) Historiquement Mozilla a dépensé pas mal d’énergie pour promouvoir l’usage du « Web ouvert » plutôt que de plateformes propriétaires et de code spécifique à des navigateurs non standards (IE6). Cette évangélisation reste nécessaire mais le paysage s’est modifié et je pense que notre discours doit s’adapter. Les plateformes dont nous devons nous préoccuper ont beaucoup changé. Au lieu de WPF, Slivertlight and Flash, les outils propriétaires pour développeurs avec lesquelles il faut rivaliser dorénavant sont iOS et Android. En conséquence, les fonctionnalités que le Web doit intégrer sont à présent orientées vers la mobilité. -

Marcia Knous: My Name Is Marcia Knous
Olivia Ryan: Can you just state your name? Marcia Knous: My name is Marcia Knous. OR: Just give us your general background. How did you come to work at Mozilla and what do you do for Mozilla now? MK: Basically, I started with Mozilla back in the Netscape days. I started working with Mozilla.org shortly after AOL acquired Netscape which I believe was in like the ’99- 2000 timeframe. I started working at Netscape and then in one capacity in HR shortly after I moved working with Mitchell as part of my shared responsibility, I worked for Mozilla.org and sustaining engineering to sustain the communicator legacy code so I supported them administratively. That’s basically what I did for Mozilla. I did a lot of I guess what you kind of call of blue activities where we have a process whereby people get access to our CVS repository so I was the gatekeeper for all the CVS forms and handle all the bugs that were related to CVS requests, that kind of thing. Right now at Mozilla, I do quality assurance and I run both our domestic online store as well as our international store where we sell all of our Mozilla gear. Tom Scheinfeldt: Are you working generally alone in small groups? In large groups? How do you relate to other people working on the project? MK: Well, it’s a rather interesting project. My capacity as a QA person, we basically relate with the community quite a bit because we have a very small internal QA organization. -

Mozilla Foundation and Subsidiary, December 31, 2018 and 2017
MOZILLA FOUNDATION AND SUBSIDIARY DECEMBER 31, 2018 AND 2017 INDEPENDENT AUDITORS’ REPORT AND CONSOLIDATED FINANCIAL STATEMENTS Mozilla Foundation and Subsidiary Independent Auditors’ Report and Consolidated Financial Statements Independent Auditors’ Report 1 - 2 Consolidated Financial Statements Consolidated Statement of Financial Position 3 Consolidated Statement of Activities and Change in Net Assets 4 Consolidated Statement of Functional Expenses 5 Consolidated Statement of Cash Flows 6 Notes to Consolidated Financial Statements 7 - 27 Independent Auditors’ Report THE BOARD OF DIRECTORS MOZILLA FOUNDATION AND SUBSIDIARY Mountain View, California Report on the Consolidated Financial Statements We have audited the accompanying consolidated financial statements of MOZILLA FOUNDATION AND SUBSIDIARY (Mozilla) which comprise the consolidated statement of financial position as of December 31, 2018 and 2017, and the related consolidated statements of activities and change in net assets, and cash flows for the years then ended, the statement of functional expenses for the year ended December 31, 2018, and the related notes to the consolidated financial statements (collectively, the financial statements). Management’s Responsibility for the Consolidated Financial Statements Management is responsible for the preparation and fair presentation of these financial statements in accordance with accounting principles generally accepted in the United States of America; this includes the design, implementation, and maintenance of internal control relevant to the preparation and fair presentation of financial statements that are free from material misstatement, whether due to fraud or error. Auditors’ Responsibility Our responsibility is to express an opinion on these financial statements based on our audits. We conducted our audits in accordance with auditing standards generally accepted in the United States of America. -
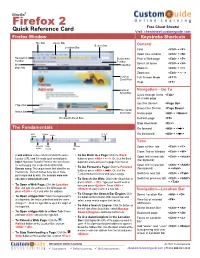
Firefox 2 Free Cheat Sheets! Quick Reference Card Visit: Cheatsheet.Customguide.Com Firefox Window Keystroke Shortcuts
® Mozilla Firefox 2 Free Cheat Sheets! Quick Reference Card Visit: cheatsheet.customguide.com Firefox Window Keystroke Shortcuts Title Bar Menu Bar Search bar General Location Bar Find <Ctrl> + <F> Open new window <Ctrl> + <N> Navigation Bookmarks Print a Web page <Ctrl> + <P> Toolbar Toolbar Select all items <Ctrl> + <A> Web Tabs Bar page tab Zoom in <Ctrl> + <+> Zoom out <Ctrl> + < - > Vertical Full Screen Mode <F11> Scroll Box Help <F1> Vertical Navigation—Go To Scroll Bar Cycle through items <Tab> on a web page Up One Screen <Page Up> Hyperlink Down One Screen <Page Down> Horizontal Status Bar Scroll Bar Home page <Alt> + <Home> Horizontal Scroll Box Refresh page <F5> Stop download <Esc> The Fundamentals Go forward <Alt> + < → > Back Search Reload Home Go backward <Alt> + < ← > button Bar Tabs Forward Stop Location Open a New Tab <Ctrl> + <T> button button Bar Close Tab or Window <Ctrl> + <W> • A web address is also called a Uniform Resource • To Go Back to a Page: Click the Back Open link in new tab <Ctrl> + <click> Locator (URL) and it is made up of several parts: button or press <Alt> + <←>. Or, click the Back (background) http:// Hypertext Transfer Protocol, the set of rules button list arrow and select a page from the list. for exchanging files on the World Wide Web. Open link in new tab <Ctrl> + <Shift> To Go Forward a Page: Click the Forward Domain name: The unique name that identifies an • (foreground) + <click> button or press <Alt> + <→>. Or, click the Internet site. Domain names have two or more Switch to next tab <Ctrl> + <Tab> parts separated by dots. -

Web Browser a C-Class Article from Wikipedia, the Free Encyclopedia
Web browser A C-class article from Wikipedia, the free encyclopedia A web browser or Internet browser is a software application for retrieving, presenting, and traversing information resources on the World Wide Web. An information resource is identified by a Uniform Resource Identifier (URI) and may be a web page, image, video, or other piece of content.[1] Hyperlinks present in resources enable users to easily navigate their browsers to related resources. Although browsers are primarily intended to access the World Wide Web, they can also be used to access information provided by Web servers in private networks or files in file systems. Some browsers can also be used to save information resources to file systems. Contents 1 History 2 Function 3 Features 3.1 User interface 3.2 Privacy and security 3.3 Standards support 4 See also 5 References 6 External links History Main article: History of the web browser The history of the Web browser dates back in to the late 1980s, when a variety of technologies laid the foundation for the first Web browser, WorldWideWeb, by Tim Berners-Lee in 1991. That browser brought together a variety of existing and new software and hardware technologies. Ted Nelson and Douglas Engelbart developed the concept of hypertext long before Berners-Lee and CERN. It became the core of the World Wide Web. Berners-Lee does acknowledge Engelbart's contribution. The introduction of the NCSA Mosaic Web browser in 1993 – one of the first graphical Web browsers – led to an explosion in Web use. Marc Andreessen, the leader of the Mosaic team at NCSA, soon started his own company, named Netscape, and released the Mosaic-influenced Netscape Navigator in 1994, which quickly became the world's most popular browser, accounting for 90% of all Web use at its peak (see usage share of web browsers). -

Security Analysis of Firefox Webextensions
6.857: Computer and Network Security Due: May 16, 2018 Security Analysis of Firefox WebExtensions Srilaya Bhavaraju, Tara Smith, Benny Zhang srilayab, tsmith12, felicity Abstract With the deprecation of Legacy addons, Mozilla recently introduced the WebExtensions API for the development of Firefox browser extensions. WebExtensions was designed for cross-browser compatibility and in response to several issues in the legacy addon model. We performed a security analysis of the new WebExtensions model. The goal of this paper is to analyze how well WebExtensions responds to threats in the previous legacy model as well as identify any potential vulnerabilities in the new model. 1 Introduction Firefox release 57, otherwise known as Firefox Quantum, brings a large overhaul to the open-source web browser. Major changes with this release include the deprecation of its initial XUL/XPCOM/XBL extensions API to shift to its own WebExtensions API. This WebExtensions API is currently in use by both Google Chrome and Opera, but Firefox distinguishes itself with further restrictions and additional functionalities. Mozilla’s goals with the new extension API is to support cross-browser extension development, as well as offer greater security than the XPCOM API. Our goal in this paper is to analyze how well the WebExtensions model responds to the vulnerabilities present in legacy addons and discuss any potential vulnerabilities in the new model. We present the old security model of Firefox extensions and examine the new model by looking at the structure, permissions model, and extension review process. We then identify various threats and attacks that may occur or have occurred before moving onto recommendations. -

Cross Site Scripting Attacks Xss Exploits and Defense.Pdf
436_XSS_FM.qxd 4/20/07 1:18 PM Page ii 436_XSS_FM.qxd 4/20/07 1:18 PM Page i Visit us at www.syngress.com Syngress is committed to publishing high-quality books for IT Professionals and deliv- ering those books in media and formats that fit the demands of our customers. We are also committed to extending the utility of the book you purchase via additional mate- rials available from our Web site. SOLUTIONS WEB SITE To register your book, visit www.syngress.com/solutions. Once registered, you can access our [email protected] Web pages. There you may find an assortment of value- added features such as free e-books related to the topic of this book, URLs of related Web sites, FAQs from the book, corrections, and any updates from the author(s). ULTIMATE CDs Our Ultimate CD product line offers our readers budget-conscious compilations of some of our best-selling backlist titles in Adobe PDF form. These CDs are the perfect way to extend your reference library on key topics pertaining to your area of expertise, including Cisco Engineering, Microsoft Windows System Administration, CyberCrime Investigation, Open Source Security, and Firewall Configuration, to name a few. DOWNLOADABLE E-BOOKS For readers who can’t wait for hard copy, we offer most of our titles in downloadable Adobe PDF form. These e-books are often available weeks before hard copies, and are priced affordably. SYNGRESS OUTLET Our outlet store at syngress.com features overstocked, out-of-print, or slightly hurt books at significant savings. SITE LICENSING Syngress has a well-established program for site licensing our e-books onto servers in corporations, educational institutions, and large organizations. -

Visual Validation of SSL Certificates in the Mozilla Browser Using Hash Images
CS Senior Honors Thesis: Visual Validation of SSL Certificates in the Mozilla Browser using Hash Images Hongxian Evelyn Tay [email protected] School of Computer Science Carnegie Mellon University Advisor: Professor Adrian Perrig Electrical & Computer Engineering Engineering & Public Policy School of Computer Science Carnegie Mellon University Monday, May 03, 2004 Abstract Many internet transactions nowadays require some form of authentication from the server for security purposes. Most browsers are presented with a certificate coming from the other end of the connection, which is then validated against root certificates installed in the browser, thus establishing the server identity in a secure connection. However, an adversary can install his own root certificate in the browser and fool the client into thinking that he is connected to the correct server. Unless the client checks the certificate public key or fingerprint, he would never know if he is connected to a malicious server. These alphanumeric strings are hard to read and verify against, so most people do not take extra precautions to check. My thesis is to implement an additional process in server authentication on a browser, using human recognizable images. The process, Hash Visualization, produces unique images that are easily distinguishable and validated. Using a hash algorithm, a unique image is generated using the fingerprint of the certificate. Images are easily recognizable and the user can identify the unique image normally seen during a secure AND accurate connection. By making a visual comparison, the origin of the root certificate is known. 1. Introduction: The Problem 1.1 SSL Security The SSL (Secure Sockets Layer) Protocol has improved the state of web security in many Internet transactions, but its complexity and neglect of human factors has exposed several loopholes in security systems that use it. -

Communications Cacm.Acm.Org of Theacm 06/2009 Vol.52 No.06
COMMUNICATIONS CACM.ACM.ORG OF THEACM 06/2009 VOL.52 NO.06 One Laptop Per Child: Vision vs. Reality Hard-Disk Drives: The Good, The Bad, and the Ugly How CS Serves The Developing World Network Front-End Processors The Claremont Report On Database Research Autonomous Helicopters Association for Computing Machinery Think Parallel..... It’s not just what we make. It’s what we make possible. Advancing Technology Curriculum Driving Software Evolution Fostering Tomorrow’s Innovators Learn more at: www.intel.com/thinkparallel ACM Ad.indd 1 4/17/2009 11:20:03 AM ABCD springer.com Noteworthy Computer Science Journals Autonomous Biological Personal and Robots Cybernetics Ubiquitous G. Sukhatme, University W. Senn, Universität Bern, Computing of Southern California, Physiologisches Institut; ACM Viterbi School of Engi- J. Rinzel, National neering, Dept. Computer Institutes of Health (NIH), P. Thomas, Univ. Coll. Science Dept. Health Education & London Interaction Centre Autonomous Robots Welfare; J. L. van Hemmen, reports on the theory and TU München, Abt. Physik Personal and Ubiquitous applications of robotic systems capable of Biological Cybernetics is an interdisciplinary Computing publishes peer-reviewed some degree of self-sufficiency. It features medium for experimental, theoretical and international research on handheld, wearable papers that include performance data on actual application-oriented aspects of information and mobile information devices and the robots in the real world. The focus is on the processing in organisms, including sensory, pervasive communications infrastructure that ability to move and be self-sufficient, not on motor, cognitive, and ecological phenomena. supports them to enable the seamless whether the system is an imitation of biology. -

Introducing HTML5.Pdf
ptg HTMLINTRODUCING 5 ptg BRUCE LAWSON REMY SHARP Introducing HTML5 Bruce Lawson and Remy Sharp New Riders 1249 Eighth Street Berkeley, CA 94710 510/524-2178 510/524-2221 (fax) Find us on the Web at: www.newriders.com To report errors, please send a note to [email protected] New Riders is an imprint of Peachpit, a division of Pearson Education Copyright © 2011 by Remy Sharp and Bruce Lawson Project Editor: Michael J. Nolan Development Editor: Jeff Riley/Box Twelve Communications Technical Editors: Patrick H. Lauke (www.splintered.co.uk), Robert Nyman (www.robertnyman.com) Production Editor: Cory Borman Copyeditor: Doug Adrianson Proofreader: Darren Meiss Compositor: Danielle Foster Indexer: Joy Dean Lee Back cover author photo: Patrick H. Lauke Notice of Rights ptg All rights reserved. No part of this book may be reproduced or transmitted in any form by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior written permission of the publisher. For informa- tion on getting permission for reprints and excerpts, contact permissions@ peachpit.com. Notice of Liability The information in this book is distributed on an “As Is” basis without war- ranty. While every precaution has been taken in the preparation of the book, neither the authors nor Peachpit shall have any liability to any person or entity with respect to any loss or damage caused or alleged to be caused directly or indirectly by the instructions contained in this book or by the com- puter software and hardware products described in it. Trademarks Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. -

0321687299.Pdf
Introducing HTML5 Bruce Lawson and Remy Sharp New Riders 1249 Eighth Street Berkeley, CA 94710 510/524-2178 510/524-2221 (fax) Find us on the Web at: www.newriders.com To report errors, please send a note to [email protected] New Riders is an imprint of Peachpit, a division of Pearson Education Copyright © 2011 by Remy Sharp and Bruce Lawson Project Editor: Michael J. Nolan Development Editor: Jeff Riley/Box Twelve Communications Technical Editors: Patrick H. Lauke (www.splintered.co.uk), Robert Nyman (www.robertnyman.com) Production Editor: Cory Borman Copyeditor: Doug Adrianson Proofreader: Darren Meiss Compositor: Danielle Foster Indexer: Joy Dean Lee Back cover author photo: Patrick H. Lauke Notice of Rights All rights reserved. No part of this book may be reproduced or transmitted in any form by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior written permission of the publisher. For informa- tion on getting permission for reprints and excerpts, contact permissions@ peachpit.com. Notice of Liability The information in this book is distributed on an “As Is” basis without war- ranty. While every precaution has been taken in the preparation of the book, neither the authors nor Peachpit shall have any liability to any person or entity with respect to any loss or damage caused or alleged to be caused directly or indirectly by the instructions contained in this book or by the com- puter software and hardware products described in it. Trademarks Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Peachpit was aware of a trademark claim, the designa- tions appear as requested by the owner of the trademark.