The Spatial and Temporal Prognosis of Oilseed Yield in Shandong
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Qingdao As a Colony: from Apartheid to Civilizational Exchange
Qingdao as a colony: From Apartheid to Civilizational Exchange George Steinmetz Paper prepared for the Johns Hopkins Workshops in Comparative History of Science and Technology, ”Science, Technology and Modernity: Colonial Cities in Asia, 1890-1940,” Baltimore, January 16-17, 2009 Steinmetz, Qingdao/Jiaozhou as a colony Now, dear Justinian. Tell us once, where you will begin. In a place where there are already Christians? or where there are none? Where there are Christians you come too late. The English, Dutch, Portuguese, and Spanish control a good part of the farthest seacoast. Where then? . In China only recently the Tartars mercilessly murdered the Christians and their preachers. Will you go there? Where then, you honest Germans? . Dear Justinian, stop dreaming, lest Satan deceive you in a dream! Admonition to Justinian von Weltz, Protestant missionary in Latin America, from Johann H. Ursinius, Lutheran Superintendent at Regensburg (1664)1 When China was ruled by the Han and Jin dynasties, the Germans were still living as savages in the jungles. In the Chinese Six Dynasties period they only managed to create barbarian tribal states. During the medieval Dark Ages, as war raged for a thousand years, the [German] people could not even read and write. Our China, however, that can look back on a unique five-thousand-year-old culture, is now supposed to take advice [from Germany], contrite and with its head bowed. What a shame! 2 KANG YOUWEI, “Research on Germany’s Political Development” (1906) Germans in Colonial Kiaochow,3 1897–1904 During the 1860s the Germans began discussing the possibility of obtaining a coastal entry point from which they could expand inland into China. -

Qingdao City Shandong Province Zip Code >>> DOWNLOAD (Mirror #1)
Qingdao City Shandong Province Zip Code >>> DOWNLOAD (Mirror #1) 1 / 3 Area Code & Zip Code; . hence its name 'Spring City'. Shandong Province is also considered the birthplace of China's . the shell-carving and beer of Qingdao. .Shandong china zip code . of Shandong Province,Shouguang 262700,Shandong,China;2Ruifeng Seed Industry Co.,Ltd,of Shouguang City,Shouguang 262700,Shandong .China Woodworking Machinery supplier, Woodworking Machine, Edge Banding Machine Manufacturers/ Suppliers - Qingdao Schnell Woodworking Machinery Co., Ltd.Qingdao Lizhong Rubber Co., Ltd. Telephone 13583252201. Zip code 266000 . Address: Liaoyang province Qingdao city Shandong District Road No.what is the zip code for Qingdao City, Shandong Prov China? . The postal code of Qingdao is 266000. i cant find the area code for gaomi city, shandong province.Province City Add Zip Email * Content * Code * Product Category Bamboo floor press Heavy bamboo press . No.111,Jing'Er Road,Pingdu, Qingdao >> .Shandong Gulun Rubber Co., Ltd. is a comprehensive . Zhongshan Street,Dezhou City, China, Zip Code . No.182,Haier Road,Qingdao City,Shandong Province E .. Qingdao City, Shandong Province, Qingdao, Shandong, China Telephone: Zip Code: Fax: Please sign in to . Qingdao Lifeng Rubber Co., Ltd., .Shandong Mcrfee Import and Export Co., Ltd. No. 139 Liuquan North Road, High-Tech Zone, Zibo City, Shandong Province Telephone: Zip Code: Fax: . Zip Code: Fax .Qingdao Dayu Paper Co., Ltd. Mr. Ike. .Qianlou Rubber Industrial Park, Mingcun Town, Pingdu, Qingdao City, Shandong Province.Postal code: 266000: . is a city in eastern Shandong Province on the east . the CCP-led Red Army entered Qingdao and the city and province have been under PRC .QingDao Meilleur Railway Co.,LTD AddressJinLing Industrial Park, JiHongTan Street, ChengYang District, Qingdao City, ShanDong Province, CHINA. -

Prevalence, Risk Factors, and Medical Costs of Chlamydia Trachomatis
Huai et al. BMC Infectious Diseases (2018) 18:534 https://doi.org/10.1186/s12879-018-3432-y RESEARCH ARTICLE Open Access Prevalence, risk factors, and medical costs of Chlamydia trachomatis infections in Shandong Province, China: a population- based, cross-sectional study Pengcheng Huai1,2,3 , Furong Li2, Zhen Li2, Lele Sun2,4,Xi’an Fu2,4, Qing Pan2,4, Gongqi Yu2,4, Zemin Chai2,4, Tongsheng Chu2, Zihao Mi2,4, Fangfang Bao2,4, Honglei Wang2,4, Bingni Zhou2,4, Chuan Wang2,4, Yonghu Sun2,4, Guiye Niu2,4, Yuan Zhang2,4, Fanghui Fu2,4, Xiaoqiao Lang2,4, Xiaoling Wang2,4, Hui Zhao2,4, Daina Liu2,4, Hong Liu2,4, Dianchang Liu2, Jian Liu2, Aiqiang Xu3,5 and Furen Zhang2,4* Abstract Background: A population-based study of Chlamydia trachomatis (CT) infections is essential in designing a specific control program; however, no large investigation of CT infections among the general population in mainland China has been conducted since 2000. We aimed to determine the prevalence, risk factors, and associated medical costs of CT among residents, 18–49 years of age, in Shandong, China. Methods: From May to August 2016, a multistage probability sampling survey involving 8074 individuals was distributed. Data were collected via face-to-face interviews, followed by self-administered questionnaire surveys. First-void urines were collected and tested for CT and Neisseria gonorrhoeae (NG) using nucleic acid amplification. Results: The weighted prevalence of CT infection was 2.3% (95% confidence interval [CI], 1.5–3.2) in females and 2.7% (1. 6–3.8) in males. Women, 30–34 years of age, had the highest prevalence of CT infections (3.5%, 2.6–4.4), while the highest prevalence of CT infections in males was in those 18–24 years of age (4.3%, 0.0–8.8). -

The Mineral Industry of China in 2016
2016 Minerals Yearbook CHINA [ADVANCE RELEASE] U.S. Department of the Interior December 2018 U.S. Geological Survey The Mineral Industry of China By Sean Xun In China, unprecedented economic growth since the late of the country’s total nonagricultural employment. In 2016, 20th century had resulted in large increases in the country’s the total investment in fixed assets (excluding that by rural production of and demand for mineral commodities. These households; see reference at the end of the paragraph for a changes were dominating factors in the development of the detailed definition) was $8.78 trillion, of which $2.72 trillion global mineral industry during the past two decades. In more was invested in the manufacturing sector and $149 billion was recent years, owing to the country’s economic slowdown invested in the mining sector (National Bureau of Statistics of and to stricter environmental regulations in place by the China, 2017b, sec. 3–1, 3–3, 3–6, 4–5, 10–6). Government since late 2012, the mineral industry in China had In 2016, the foreign direct investment (FDI) actually used faced some challenges, such as underutilization of production in China was $126 billion, which was the same as in 2015. capacity, slow demand growth, and low profitability. To In 2016, about 0.08% of the FDI was directed to the mining address these challenges, the Government had implemented sector compared with 0.2% in 2015, and 27% was directed to policies of capacity control (to restrict the addition of new the manufacturing sector compared with 31% in 2015. -

Spatial Optimization and Mode Analysis of Primary Industry Structure in Yellow River Delta Ping Yang, Yujian Yang
Spatial Optimization and Mode Analysis of Primary Industry Structure in Yellow River Delta Ping Yang, Yujian Yang To cite this version: Ping Yang, Yujian Yang. Spatial Optimization and Mode Analysis of Primary Industry Structure in Yellow River Delta. 6th Computer and Computing Technologies in Agriculture (CCTA), Oct 2012, Zhangjiajie, China. pp.150-160, 10.1007/978-3-642-36137-1_19. hal-01348227 HAL Id: hal-01348227 https://hal.inria.fr/hal-01348227 Submitted on 22 Jul 2016 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Distributed under a Creative Commons Attribution| 4.0 International License Spatial Optimization and Mode Analysis of Primary Industry Structure in Yellow River Delta Ping Yang, Yujian Yang* 1 The institute of sustainable development of Shandong Agricultural Science Academy 2S & T Information Engineering Technology Center of Shandong Academy of Agricultural Science, Information center of agronomy College of Shandong University *Corresponding author, Address: S&T Information Engineering Research Center, Number 202 Gongye North Road, -

Fiscal Reform and Land Public Finance: Zouping County In
Fiscal Reform and Land Public 7 Finance: Zouping County in National Context h SUSAN H. WHITING and has become a key source of fi scal revenue for local governments in China. LAs the value of land has increased with urbanization and economic development, local governments have sought to exploit their control over land in order to gener- ate both on- and off - budget revenue. Scholars and policy makers have come to refer to this phenomenon as “land public fi nance.” Th is chapter argues that land public fi nance is in large part an outgrowth of trends in central- local fi scal relations. During the course of China’s transition from a planned to a market economy, central- local fi scal relations have undergone a series of fundamental reforms. Cur- rent challenges grow out of a number of features of the Chinese po liti cal economy, the most important of which is the mismatch between the allocation of revenues and the assignment of expenditure responsibilities across levels of government. Local governments— county governments in particular— oft en lack adequate rev- enues within the formal fi scal system to fi nance the wide range of public goods and ser vices they are mandated by higher levels to provide. Th e mismatch between revenues and expenditure responsibilities leads to heavy reliance on intergovern- mental fi scal transfers that, nonetheless, have not yet eff ectively redressed revenue inadequacy or the high levels of in e qual ity that have emerged in the context of economic reform. Th is fi scal gap drives additional problems, including the growth of hidden government debts and off - budget funds at the local level. -

SEC61G Is Upregulated and Required for Tumor Progression in Human Kidney Cancer
MOLECULAR MEDICINE REPORTS 23: 427, 2021 SEC61G is upregulated and required for tumor progression in human kidney cancer HUI MENG1, XUEWEN JIANG1, JIAN WANG2, ZUNMENG SANG1, LONGFEI GUO1, GANG YIN1 and YU WANG3 1Department of Urology, Qilu Hospital, Cheeloo College of Medicine, Shandong University, Jinan, Shandong 250012; 2Department of Urology, People's Hospital of Laoling, Laoling, Shandong 253600; 3Reproductive Medicine Center, Department of Obstetrics and Gynecology, Qilu Hospital, Cheeloo College of Medicine, Shandong University, Jinan, Shandong 250012, P.R. China Received December 16, 2019; Accepted January 29, 2021 DOI: 10.3892/mmr.2021.12066 Abstract. Kidney cancer is a malignant tumor of the urinary promote kidney tumor progression. Therefore, the present system. Although the 5‑year survival rate of patients with study provided a novel candidate gene for predicting the kidney cancer has increased by ~30% in recent years due to prognosis of patients with kidney cancer. the early detection of low‑grade tumors using more accurate diagnostic methods, the global incidence of kidney cancer Introduction continues to increase every year. Therefore, identification of novel and efficient candidate genes for predicting the prog‑ Kidney cancer is a malignant tumor of the urinary system, nosis of patients with kidney cancer is important. The present accounting for 2.2% of all adult malignancies worldwide (1). study aimed to investigate the role of SEC61 translocon The most common type of kidney cancer is renal cell carci‑ subunit‑γ (SEC61G) in kidney cancer. The Cancer Genome noma (RCC), which accounts for 85‑90% of all cases (2). Atlas database was screened to obtain the expression profile According to the classification of International Society of of SEC61G and identify its association with kidney cancer Urological Pathology, RCC is primarily divided into three prognosis. -

Cereal Series/Protein Series Jiangxi Cowin Food Co., Ltd. Huangjindui
产品总称 委托方名称(英) 申请地址(英) Huangjindui Industrial Park, Shanggao County, Yichun City, Jiangxi Province, Cereal Series/Protein Series Jiangxi Cowin Food Co., Ltd. China Folic acid/D-calcium Pantothenate/Thiamine Mononitrate/Thiamine East of Huangdian Village (West of Tongxingfengan), Kenli Town, Kenli County, Hydrochloride/Riboflavin/Beta Alanine/Pyridoxine Xinfa Pharmaceutical Co., Ltd. Dongying City, Shandong Province, 257500, China Hydrochloride/Sucralose/Dexpanthenol LMZ Herbal Toothpaste Liuzhou LMZ Co.,Ltd. No.282 Donghuan Road,Liuzhou City,Guangxi,China Flavor/Seasoning Hubei Handyware Food Biotech Co.,Ltd. 6 Dongdi Road, Xiantao City, Hubei Province, China SODIUM CARBOXYMETHYL CELLULOSE(CMC) ANQIU EAGLE CELLULOSE CO., LTD Xinbingmaying Village, Linghe Town, Anqiu City, Weifang City, Shandong Province No. 569, Yingerle Road, Economic Development Zone, Qingyun County, Dezhou, biscuit Shandong Yingerle Hwa Tai Food Industry Co., Ltd Shandong, China (Mainland) Maltose, Malt Extract, Dry Malt Extract, Barley Extract Guangzhou Heliyuan Foodstuff Co.,LTD Mache Village, Shitan Town, Zengcheng, Guangzhou,Guangdong,China No.3, Xinxing Road, Wuqing Development Area, Tianjin Hi-tech Industrial Park, Non-Dairy Whip Topping\PREMIX Rich Bakery Products(Tianjin)Co.,Ltd. Tianjin, China. Edible oils and fats / Filling of foods/Milk Beverages TIANJIN YOSHIYOSHI FOOD CO., LTD. No. 52 Bohai Road, TEDA, Tianjin, China Solid beverage/Milk tea mate(Non dairy creamer)/Flavored 2nd phase of Diqiuhuanpo, Economic Development Zone, Deqing County, Huzhou Zhejiang Qiyiniao Biological Technology Co., Ltd. concentrated beverage/ Fruit jam/Bubble jam City, Zhejiang Province, P.R. China Solid beverage/Flavored concentrated beverage/Concentrated juice/ Hangzhou Jiahe Food Co.,Ltd No.5 Yaojia Road Gouzhuang Liangzhu Street Yuhang District Hangzhou Fruit Jam Production of Hydrolyzed Vegetable Protein Powder/Caramel Color/Red Fermented Rice Powder/Monascus Red Color/Monascus Yellow Shandong Zhonghui Biotechnology Co., Ltd. -
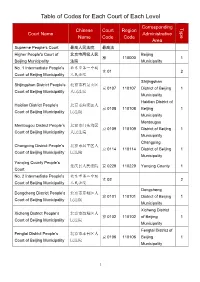
Table of Codes for Each Court of Each Level
Table of Codes for Each Court of Each Level Corresponding Type Chinese Court Region Court Name Administrative Name Code Code Area Supreme People’s Court 最高人民法院 最高法 Higher People's Court of 北京市高级人民 Beijing 京 110000 1 Beijing Municipality 法院 Municipality No. 1 Intermediate People's 北京市第一中级 京 01 2 Court of Beijing Municipality 人民法院 Shijingshan Shijingshan District People’s 北京市石景山区 京 0107 110107 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Haidian District of Haidian District People’s 北京市海淀区人 京 0108 110108 Beijing 1 Court of Beijing Municipality 民法院 Municipality Mentougou Mentougou District People’s 北京市门头沟区 京 0109 110109 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Changping Changping District People’s 北京市昌平区人 京 0114 110114 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Yanqing County People’s 延庆县人民法院 京 0229 110229 Yanqing County 1 Court No. 2 Intermediate People's 北京市第二中级 京 02 2 Court of Beijing Municipality 人民法院 Dongcheng Dongcheng District People’s 北京市东城区人 京 0101 110101 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Xicheng District Xicheng District People’s 北京市西城区人 京 0102 110102 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Fengtai District of Fengtai District People’s 北京市丰台区人 京 0106 110106 Beijing 1 Court of Beijing Municipality 民法院 Municipality 1 Fangshan District Fangshan District People’s 北京市房山区人 京 0111 110111 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Daxing District of Daxing District People’s 北京市大兴区人 京 0115 -

Download File
On the Periphery of a Great “Empire”: Secondary Formation of States and Their Material Basis in the Shandong Peninsula during the Late Bronze Age, ca. 1000-500 B.C.E Minna Wu Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Graduate School of Arts and Sciences COLUMIBIA UNIVERSITY 2013 @2013 Minna Wu All rights reserved ABSTRACT On the Periphery of a Great “Empire”: Secondary Formation of States and Their Material Basis in the Shandong Peninsula during the Late Bronze-Age, ca. 1000-500 B.C.E. Minna Wu The Shandong region has been of considerable interest to the study of ancient China due to its location in the eastern periphery of the central culture. For the Western Zhou state, Shandong was the “Far East” and it was a vast region of diverse landscape and complex cultural traditions during the Late Bronze-Age (1000-500 BCE). In this research, the developmental trajectories of three different types of secondary states are examined. The first type is the regional states established by the Zhou court; the second type is the indigenous Non-Zhou states with Dong Yi origins; the third type is the states that may have been formerly Shang polities and accepted Zhou rule after the Zhou conquest of Shang. On the one hand, this dissertation examines the dynamic social and cultural process in the eastern periphery in relation to the expansion and colonization of the Western Zhou state; on the other hand, it emphasizes the agency of the periphery during the formation of secondary states by examining how the polities in the periphery responded to the advances of the Western Zhou state and how local traditions impacted the composition of the local material assemblage which lay the foundation for the future prosperity of the regional culture. -

The Mineral Industry of China in 2007
2007 Minerals Yearbook CHINA U.S. Department of the Interior December 2009 U.S. Geological Survey THE MINERAL INDUS T RY OF CHINA By Pui-Kwan Tse After three decades of economic development, China probably have some impact on the global commodity prices has become one of the leading economic and trade powers (Batson and King, 2008). in the world, one of the top destinations for foreign direct investment, and an export destination of choice. During the Minerals in the National Economy past several years, the Government’s economic policy was to prevent economic slowdown and fight inflation. In 2007, China is rich in mineral resources and was the world’s China’s economic growth rate was 11.9% and represented the leading producer of aluminum, antimony, barite, bismuth, coal, fifth consecutive year of double-digit expansion. Industrial fluorspar, gold, graphite, iron and steel, lead, phosphate rock, production increased by 18.5% compared with that of 2006. rare earths, talc, tin, tungsten, and zinc in 2007. It ranked among The consumer price index (a measurement of inflation) rose to the top three countries in the world in the production of many a decade high of 4.8%. To prevent economic “overheating,” the other mineral commodities. China was the leading exporter Government raised interest rates and the People’s Bank of China of antimony, barite, coal, fluorspar, graphite, rare earths, and (the central bank) required commercial banks to increase the tungsten in the world. The country’s demand for chromium, reserve-requirement ratio 11 times to 11.5% at yearend 2007. -

CHINA VANKE CO., LTD.* 萬科企業股份有限公司 (A Joint Stock Company Incorporated in the People’S Republic of China with Limited Liability) (Stock Code: 2202)
Hong Kong Exchanges and Clearing Limited and The Stock Exchange of Hong Kong Limited take no responsibility for the contents of this announcement, make no representation as to its accuracy or completeness and expressly disclaim any liability whatsoever for any loss howsoever arising from or in reliance upon the whole or any part of the contents of this announcement. CHINA VANKE CO., LTD.* 萬科企業股份有限公司 (A joint stock company incorporated in the People’s Republic of China with limited liability) (Stock Code: 2202) 2019 ANNUAL RESULTS ANNOUNCEMENT The board of directors (the “Board”) of China Vanke Co., Ltd.* (the “Company”) is pleased to announce the audited results of the Company and its subsidiaries for the year ended 31 December 2019. This announcement, containing the full text of the 2019 Annual Report of the Company, complies with the relevant requirements of the Rules Governing the Listing of Securities on The Stock Exchange of Hong Kong Limited in relation to information to accompany preliminary announcement of annual results. Printed version of the Company’s 2019 Annual Report will be delivered to the H-Share Holders of the Company and available for viewing on the websites of The Stock Exchange of Hong Kong Limited (www.hkexnews.hk) and of the Company (www.vanke.com) in April 2020. Both the Chinese and English versions of this results announcement are available on the websites of the Company (www.vanke.com) and The Stock Exchange of Hong Kong Limited (www.hkexnews.hk). In the event of any discrepancies in interpretations between the English version and Chinese version, the Chinese version shall prevail, except for the financial report prepared in accordance with International Financial Reporting Standards, of which the English version shall prevail.