Integrative Biomarker Identification and Classification Using High Throughput Assays
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Systematic Detection of Divergent Brain Proteins in Human Evolution and Their Roles in Cognition
bioRxiv preprint doi: https://doi.org/10.1101/658658; this version posted June 3, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. Systematic detection of divergent brain proteins in human evolution and their roles in cognition Guillaume Dumas1,*, Simon Malesys1 and Thomas Bourgeron1 Affiliations: 1 Human Genetics and Cognitive Functions, Institut Pasteur, UMR3571 CNRS, Université de Paris, Paris, (75015) France * Corresponding author: [email protected] 1 bioRxiv preprint doi: https://doi.org/10.1101/658658; this version posted June 3, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. Abstract The human brain differs from that of other primates, but the underlying genetic mechanisms remain unclear. Here we measured the evolutionary pressures acting on all human protein- coding genes (N=17,808) based on their divergence from early hominins such as Neanderthal, and non-human primates. We confirm that genes encoding brain-related proteins are among the most conserved of the human proteome. Conversely, several of the most divergent proteins in humans compared to other primates are associated with brain-associated diseases such as micro/macrocephaly, dyslexia, and autism. We identified specific eXpression profiles of a set of divergent genes in ciliated cells of the cerebellum, that might have contributed to the emergence of fine motor skills and social cognition in humans. -

Supplementary Note
1 SUPPLEMENTARY NOTE 2 Table of Contents 3 1 Studies contributing to systolic (SBP) and diastolic blood pressure (DBP) analyses ............ 4 4 2 Consortia and studies providing association results for cardiovascular outcomes ............. 4 5 2.1 CHARGE - Heart Failure Working Group .................................................................................. 4 6 2.2 EchoGen (LM mass and LV weight) .......................................................................................... 4 7 2.3 NEURO-CHARGE (stroke) ........................................................................................................ 4 8 2.4 MetaStroke (stroke) ................................................................................................................ 5 9 2.5 CARDIoGRAMplusC4D (CAD) ................................................................................................... 5 10 2.6 CHARGE CKDgen (CKD, eGFR, microalbuminuria, UACR) ......................................................... 5 11 2.7 KidneyGen (creatinine) ........................................................................................................... 6 12 2.8 CHARGE (cIMT) ....................................................................................................................... 6 13 2.9 CHARGE (mild retinopathy, central retinal artery caliber) ....................................................... 6 14 2.10 SEED (mild retinopathy, central retinal artery caliber) .......................................................... 6 15 -

Comprehensive Analysis Reveals Novel Gene Signature in Head and Neck Squamous Cell Carcinoma: Predicting Is Associated with Poor Prognosis in Patients
5892 Original Article Comprehensive analysis reveals novel gene signature in head and neck squamous cell carcinoma: predicting is associated with poor prognosis in patients Yixin Sun1,2#, Quan Zhang1,2#, Lanlin Yao2#, Shuai Wang3, Zhiming Zhang1,2 1Department of Breast Surgery, The First Affiliated Hospital of Xiamen University, School of Medicine, Xiamen University, Xiamen, China; 2School of Medicine, Xiamen University, Xiamen, China; 3State Key Laboratory of Cellular Stress Biology, School of Life Sciences, Xiamen University, Xiamen, China Contributions: (I) Conception and design: Y Sun, Q Zhang; (II) Administrative support: Z Zhang; (III) Provision of study materials or patients: Y Sun, Q Zhang; (IV) Collection and assembly of data: Y Sun, L Yao; (V) Data analysis and interpretation: Y Sun, S Wang; (VI) Manuscript writing: All authors; (VII) Final approval of manuscript: All authors. #These authors contributed equally to this work. Correspondence to: Zhiming Zhang. Department of Surgery, The First Affiliated Hospital of Xiamen University, Xiamen, China. Email: [email protected]. Background: Head and neck squamous cell carcinoma (HNSC) remains an important public health problem, with classic risk factors being smoking and excessive alcohol consumption and usually has a poor prognosis. Therefore, it is important to explore the underlying mechanisms of tumorigenesis and screen the genes and pathways identified from such studies and their role in pathogenesis. The purpose of this study was to identify genes or signal pathways associated with the development of HNSC. Methods: In this study, we downloaded gene expression profiles of GSE53819 from the Gene Expression Omnibus (GEO) database, including 18 HNSC tissues and 18 normal tissues. -

Content Based Search in Gene Expression Databases and a Meta-Analysis of Host Responses to Infection
Content Based Search in Gene Expression Databases and a Meta-analysis of Host Responses to Infection A Thesis Submitted to the Faculty of Drexel University by Francis X. Bell in partial fulfillment of the requirements for the degree of Doctor of Philosophy November 2015 c Copyright 2015 Francis X. Bell. All Rights Reserved. ii Acknowledgments I would like to acknowledge and thank my advisor, Dr. Ahmet Sacan. Without his advice, support, and patience I would not have been able to accomplish all that I have. I would also like to thank my committee members and the Biomed Faculty that have guided me. I would like to give a special thanks for the members of the bioinformatics lab, in particular the members of the Sacan lab: Rehman Qureshi, Daisy Heng Yang, April Chunyu Zhao, and Yiqian Zhou. Thank you for creating a pleasant and friendly environment in the lab. I give the members of my family my sincerest gratitude for all that they have done for me. I cannot begin to repay my parents for their sacrifices. I am eternally grateful for everything they have done. The support of my sisters and their encouragement gave me the strength to persevere to the end. iii Table of Contents LIST OF TABLES.......................................................................... vii LIST OF FIGURES ........................................................................ xiv ABSTRACT ................................................................................ xvii 1. A BRIEF INTRODUCTION TO GENE EXPRESSION............................. 1 1.1 Central Dogma of Molecular Biology........................................... 1 1.1.1 Basic Transfers .......................................................... 1 1.1.2 Uncommon Transfers ................................................... 3 1.2 Gene Expression ................................................................. 4 1.2.1 Estimating Gene Expression ............................................ 4 1.2.2 DNA Microarrays ...................................................... -

University of Dundee a Comprehensive 1000 Genomes
University of Dundee A comprehensive 1000 Genomes-based genome-wide association meta-analysis of coronary artery disease Nikpay, Majid; Goel, Anuj; Won, Hong-Hee; Hall, Leanne M.; Willenborg, Christina; Kanoni, Stavroula Published in: Nature Genetics DOI: 10.1038/ng.3396 Publication date: 2015 Document Version Publisher's PDF, also known as Version of record Link to publication in Discovery Research Portal Citation for published version (APA): Nikpay, M., Goel, A., Won, H-H., Hall, L. M., Willenborg, C., Kanoni, S., Saleheen, D., Kyriakou, T., Nelson, C. P., Hopewell, J. C., Webb, T. R., Zeng, L., Dehghan, A., Elver, M., Armasu, S. M., Auro, K., Bjonnes, A., Chasman, D. I., Chen, S., ... Farrall, M. (2015). A comprehensive 1000 Genomes-based genome-wide association meta-analysis of coronary artery disease. Nature Genetics, 47(10), 1121-1130. https://doi.org/10.1038/ng.3396 General rights Copyright and moral rights for the publications made accessible in Discovery Research Portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. • Users may download and print one copy of any publication from Discovery Research Portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain. • You may freely distribute the URL identifying the publication in the public portal. Take down policy If you believe that this document breaches copyright please contact us providing details, and we will remove access to the work immediately and investigate your claim. -

C11orf16 (D-16): Sc-163799
SAN TA C RUZ BI OTEC HNOL OG Y, INC . C11orf16 (D-16): sc-163799 BACKGROUND PRODUCT C11orf16 (chromosome 11 open reading frame 16) is a 404 amino acid protein Each vial contains 200 µg IgG in 1.0 ml of PBS with < 0.1% sodium azide that is encoded by a gene located on human chromosome 11. With approxi - and 0.1% gelatin. mately 135 million base pairs and 1,400 genes, chromosome 11 makes up Blocking peptide available for competition studies, sc-163799 P, (100 µg around 4% of human genomic DNA and is considered a gene and disease pep tide in 0.5 ml PBS containing < 0.1% sodium azide and 0.2% BSA). association dense chromosome. The chromosome 11 encoded Atm gene is important for regulation of cell cycle arrest and apoptosis following double APPLICATIONS strand DNA breaks. Atm mutation leads to the disorder known as ataxia- C11orf16 (D-16) is recommended for detection of C11orf16 of human origin telangiectasia. The blood disorders Sickle cell anemia and β thalassemia are caused by HBB gene mutations. Wilms' tumors, WAGR syndrome and Denys- and BC051019 of mouse origin by Western Blotting (starting dilution 1:200, Drash syndrome are associated with mutations of the WT1 gene. Jervell and dilution range 1:100-1:1000), immunofluorescence (starting dilution 1:50, Lange-Nielsen syndrome, Jacobsen syndrome, Niemann-Pick disease, heredi - dilution range 1:50-1:500) and solid phase ELISA (starting dilution 1:30, tary angioedema and Smith-Lemli-Opitz syndrome are also associated with dilution range 1:30-1:3000); non cross-reactive with other C11orf family defects in chromosome 11. -
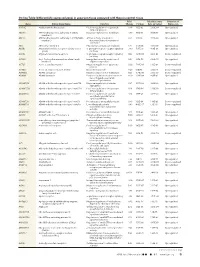
Differentially Expressed Genes in Aneurysm Tissue Compared With
On-line Table: Differentially expressed genes in aneurysm tissue compared with those in control tissue Fold False Discovery Direction of Gene Entrez Gene Name Function Change P Value Rate (q Value) Expression AADAC Arylacetamide deacetylase Positive regulation of triglyceride 4.46 1.33E-05 2.60E-04 Up-regulated catabolic process ABCA6 ATP-binding cassette, subfamily A (ABC1), Integral component of membrane 3.79 9.15E-14 8.88E-12 Up-regulated member 6 ABCC3 ATP-binding cassette, subfamily C (CFTR/MRP), ATPase activity, coupled to 6.63 1.21E-10 7.33E-09 Up-regulated member 3 transmembrane movement of substances ABI3 ABI family, member 3 Peptidyl-tyrosine phosphorylation 6.47 2.47E-05 4.56E-04 Up-regulated ACKR1 Atypical chemokine receptor 1 (Duffy blood G-protein–coupled receptor signaling 3.80 7.95E-10 4.18E-08 Up-regulated group) pathway ACKR2 Atypical chemokine receptor 2 G-protein–coupled receptor signaling 0.42 3.29E-04 4.41E-03 Down-regulated pathway ACSM1 Acyl-CoA synthetase medium-chain family Energy derivation by oxidation of 9.87 1.70E-08 6.52E-07 Up-regulated member 1 organic compounds ACTC1 Actin, ␣, cardiac muscle 1 Negative regulation of apoptotic 0.30 7.96E-06 1.65E-04 Down-regulated process ACTG2 Actin, ␥2, smooth muscle, enteric Blood microparticle 0.29 1.61E-16 2.36E-14 Down-regulated ADAM33 ADAM domain 33 Integral component of membrane 0.23 9.74E-09 3.95E-07 Down-regulated ADAM8 ADAM domain 8 Positive regulation of tumor necrosis 4.69 2.93E-04 4.01E-03 Up-regulated factor (ligand) superfamily member 11 production ADAMTS18 -

Comprehensive Analysis of Gene Expression and DNA Methylation for Human Nasopharyngeal Carcinoma
European Archives of Oto-Rhino-Laryngology (2019) 276:2565–2576 https://doi.org/10.1007/s00405-019-05525-2 HEAD AND NECK Comprehensive analysis of gene expression and DNA methylation for human nasopharyngeal carcinoma Hu Li1 · Fu‑Ling Wang2 · Liang‑peng Shan3 · Jun An1 · Ming‑lei Liu1 · Wei Li1 · Jing‑E. Zhang1 · Ping‑ping Wu1 Received: 7 March 2019 / Accepted: 18 June 2019 / Published online: 25 June 2019 © Springer-Verlag GmbH Germany, part of Springer Nature 2019 Abstract Purpose Nasopharyngeal carcinoma (NPC) is one of the most malignant head and neck carcinomas with unique epidemio- logical features. In this study, we aimed to identify the novel NPC-related genes and biological pathways, shedding light on the potential molecular mechanisms of NPC. Methods Based on Gene Expression Omnibus (GEO) database, an integrated analysis of microarrays studies was performed to identify diferentially expressed genes (DEGs) and diferentially methylated genes (DMGs) in NPC compared to nor- mal control. The genes which were both diferentially expressed and diferentially methylated were identifed. Functional annotation and protein–protein interaction (PPI) network construction were used to uncover biological functions of DEGs. Results Two DNA methylation and fve gene expression datasets were incorporated. A total of 1074 genes were up-regulated and 939 genes were down-regulated in NPC were identifed. A total of 719 diferential methylation CpG sites (DMCs) includ- ing 1 hypermethylated sites and 718 hypomethylated sites were identifed. Among which, 11 genes were both DEGs and DMGs in NPC. Pathways in cancer, p53 signaling pathway and Epstein–Barr virus infection were three pathways signifcantly enriched pathways in DEmRNAs of NPC. -

Rasmus Nielsen1, Melissa J. Hubisz2, 3, Ines Hellmann1, Dara Torgerson4, Aida M
Downloaded from genome.cshlp.org on September 29, 2021 - Published by Cold Spring Harbor Laboratory Press DARWINIAN AND DEMOGRAPHIC FORCES AFFECTING HUMAN PROTEIN CODING GENES Rasmus Nielsen1, Melissa J. Hubisz2, 3, Ines Hellmann1, Dara Torgerson4, Aida M. Andrés5, Anders Albrechtsen1, Ryan Gutenkunst3, Mark D. Adams6, Michele Cargill7, Adam Boyko3, Amit Indap3, Carlos D. Bustamante3, and Andrew G. Clark8. 1Department of Biology, University of Copenhagen, Universitetsparken 15, 2100 Kbh Ø, Denmark and Departments of Integrative Biology and Statistics, UC Berkeley, Berkeley, CA 94720. 2Department of Human Genetics, University of Chicago, Chicago, IL 60637 3Biological Statistics & Computational Biology, Cornell University, Ithaca, NY 14853 4 Department of Human Genetics, University of Chicago, 920 E. 58th St. CLSC 501, Chicago, IL 60637 5 Genome Technology Branch, National Human Genome Research Institute, National Institutes of Health, Bethesda, MD 20892 6 Department of Genetics, BRB-624, Case Western Reserve University, 10900 Euclid Ave., Cleveland, OH 44106 7 Navigenics, One Lagoon Dr, Suite 450, Redwood Shores, CA 9406 8 Molecular Biology & Genetics, Cornell University, Ithaca, NY 14853, USA Correspondence should be addressed to: Rasmus Nielsen, [email protected] Downloaded from genome.cshlp.org on September 29, 2021 - Published by Cold Spring Harbor Laboratory Press ABSTRACT Past demographic changes can produce distortions in patterns of genetic variation that can mimic the appearance of natural selection unless the demographic effects are explicitly removed. Here we fit a detailed model of human demography that incorporates divergence, migration, admixture and changes in population size to directly sequenced data from 9,315 protein coding genes from 20 European-American and 19 African-American individuals. -

Author Manuscript Faculty of Biology and Medicine Publication
Serveur Académique Lausannois SERVAL serval.unil.ch Author Manuscript Faculty of Biology and Medicine Publication This paper has been peer-reviewed but dos not include the final publisher proof-corrections or journal pagination. Published in final edited form as: Title: Seventy-five genetic loci influencing the human red blood cell. Authors: van der Harst P, Zhang W, Mateo Leach I, Rendon A, Verweij N, Sehmi J, Paul DS, Elling U, Allayee H, Li X, Radhakrishnan A, Tan ST, Voss K, Weichenberger CX, Albers CA, Al-Hussani A, Asselbergs FW, Ciullo M, Danjou F, Dina C, Esko T, Evans DM, Franke L, Gögele M, Hartiala J, Hersch M, Holm H, Hottenga JJ, Kanoni S, Kleber ME, Lagou V, Langenberg C, Lopez LM, Lyytikäinen LP, Melander O, Murgia F, Nolte IM, O'Reilly PF, Padmanabhan S, Parsa A, Pirastu N, Porcu E, Portas L, Prokopenko I, Ried JS, Shin SY, Tang CS, Teumer A, Traglia M, Ulivi S, Westra HJ, Yang J, Zhao JH, Anni F, Abdellaoui A, Attwood A, Balkau B, Bandinelli S, Bastardot F, Benyamin B, Boehm BO, Cookson WO, Das D, de Bakker PI, de Boer RA, de Geus EJ, de Moor MH, Dimitriou M, Domingues FS, Döring A, Engström G, Eyjolfsson GI, Ferrucci L, Fischer K, Galanello R, Garner SF, Genser B, Gibson QD, Girotto G, Gudbjartsson DF, Harris SE, Hartikainen AL, Hastie CE, In Hedbladthe absence of aB, copyright Illig statement,T, Jolley users J, should Kähönen assume that M, standard Kema copyright IP, protectionKemp applies,JP, Liang unless the L, article contains an explicit statement to the contrary. -

Genome-Wide Analysis of Long Non-Coding RNA Expression Profile in Lung Adenocarcinoma Compared to Spinal Metastasis
1516 Original Article Page 1 of 13 Genome-wide analysis of long non-coding RNA expression profile in lung adenocarcinoma compared to spinal metastasis Houlei Wang#, Annan Hu#, Yun Liang, Ketao Wang, Xiaogang Zhou, Jian Dong Department of Orthopaedic Surgery, Zhongshan Hospital, Fudan University, Shanghai, China Contributions: (I) Conception and design: H Wang, A Hu; (II) Administrative support: J Dong; (III) Provision of study materials or patients: X Zhou; (IV) Collection and assembly of data: K Wang; (V) Data analysis and interpretation: Y Liang; (VI) Manuscript writing: All authors; (VII) Final approval of manuscript: All authors. #These authors contributed equally to this work. Correspondence to: Jian Dong. Department of Orthopaedic Surgery, Zhongshan Hospital, Fudan University, No. 180 Fenglin Road, Shanghai 200032, China. Email: [email protected]. Background: Long non-coding RNAs (lncRNAs) play important roles in tumor metastasis. The aim of the present study was to investigate their expression profile and potential functions in spinal metastasis (SM) of lung adenocarcinoma. Methods: We conducted lncRNA and mRNA expression in lung adenocarcinoma and its SM tissue using microarray analysis. Quantitative reverse-transcriptase polymerase chain reaction (qRT-PCR) revealed 10 differentially expressed lncRNAs. Gene ontology and pathway analysis were performed to test the gene effect. Possible target genes of lncRNAs were predicted based on precise algorithms. Results: Microarray analysis found many significantly differentially expressed lncRNAs and mRNAs in lung adenocarcinoma compared with SM. qRT-PCR results aligned with those of the microarray analysis. The expression level of 10 lncRNAs showed the same trend (P<0.05). Biologic pathways known to be involved in cancer were identified among the differentially expressed mRNAs; these include cell adhesion molecules (related to 42 genes), focal adhesion (related to 31 genes), cytokine-cytokine receptor interaction (related to 48 genes), and extracellular matrix-receptor interaction (related to 23 genes). -

Homo Sapiens, Homo Neanderthalensis and the Denisova Specimen: New Insights on Their Evolutionary Histories Using Whole-Genome Comparisons
Genetics and Molecular Biology, 35, 4 (suppl), 904-911 (2012) Copyright © 2012, Sociedade Brasileira de Genética. Printed in Brazil www.sbg.org.br Research Article Homo sapiens, Homo neanderthalensis and the Denisova specimen: New insights on their evolutionary histories using whole-genome comparisons Vanessa Rodrigues Paixão-Côrtes, Lucas Henrique Viscardi, Francisco Mauro Salzano, Tábita Hünemeier and Maria Cátira Bortolini Departamento de Genética, Instituto de Biociências, Universidade Federal do Rio Grande do Sul, Porto Alegre, RS, Brazil. Abstract After a brief review of the most recent findings in the study of human evolution, an extensive comparison of the com- plete genomes of our nearest relative, the chimpanzee (Pan troglodytes), of extant Homo sapiens, archaic Homo neanderthalensis and the Denisova specimen were made. The focus was on non-synonymous mutations, which consequently had an impact on protein levels and these changes were classified according to degree of effect. A to- tal of 10,447 non-synonymous substitutions were found in which the derived allele is fixed or nearly fixed in humans as compared to chimpanzee. Their most frequent location was on chromosome 21. Their presence was then searched in the two archaic genomes. Mutations in 381 genes would imply radical amino acid changes, with a frac- tion of these related to olfaction and other important physiological processes. Eight new alleles were identified in the Neanderthal and/or Denisova genetic pools. Four others, possibly affecting cognition, occured both in the sapiens and two other archaic genomes. The selective sweep that gave rise to Homo sapiens could, therefore, have initiated before the modern/archaic human divergence.