Formal Language Definitions Symbol
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Marshall Mcluhan
Marshall McLuhan: Educational Implications* W.J. Gushue He received the Governor General's award for his work in literature, the Albert Schweitzer Chair at Fordham for his work in communications, and the Moison Award from the Canada Council as "explorer and interpreter of our age." He appeared on the covers of N eW8week, Saturday Review and Canada's largest weekend supplement. NBC made a one-hour docu mentary of his message and later repeated it, and the CBC gave him prime Sunday night viewing time on two occasions. He is one of the most publicized intellectuals of recent times. Ralph Thomas wrote in the Torfmto Star: "He has been explained, knocked and praised in just about every magazine in the EngIish, French, German and Italian languages." 1 As to newspaper coverage, which newspapers have not written about him? He has lectured city planners, advertising men, TV executives, university professors, students, and scientists; business men have sought his message from a yacht in the Aegean Sea, a hotel in the Laurentians, a former firehouse in San Francisco, and in the board rooms of IBM, General Electric, and Bell Telephone. Although "a torrent of criticism" has been heaped upon him by ':' Research for this paper was undertaken while Prof. Gushue was at the .ontario Institute for Studies in Education during the 1967-68 acad emic year. A slightly modified version was delivered at the C.A.P.E. conference in Calgary, June, 1968. - Ed. 3 4 Marshall McLuhan the old dogies of academe and the literary establishment, he has been eulogized in dozens of scholarly magazines and studied serious ly by thousands of intellectuals.2 The best indication of his worth is the fact that among his followers are to be found people (artists, really) who are part of what Susan Sontag calls "the new sensibility." 3 They are, to use Louis Kronenberger's phrase, "the symbol manipulators," the peo ple who are calling the shots - painters, sculptors, publishers, pub lic relations men, architects, film-makers, musicians, designers, consultants, editors, T.V. -

Chapter 2 Introduction to Classical Propositional
CHAPTER 2 INTRODUCTION TO CLASSICAL PROPOSITIONAL LOGIC 1 Motivation and History The origins of the classical propositional logic, classical propositional calculus, as it was, and still often is called, go back to antiquity and are due to Stoic school of philosophy (3rd century B.C.), whose most eminent representative was Chryssipus. But the real development of this calculus began only in the mid-19th century and was initiated by the research done by the English math- ematician G. Boole, who is sometimes regarded as the founder of mathematical logic. The classical propositional calculus was ¯rst formulated as a formal ax- iomatic system by the eminent German logician G. Frege in 1879. The assumption underlying the formalization of classical propositional calculus are the following. Logical sentences We deal only with sentences that can always be evaluated as true or false. Such sentences are called logical sentences or proposi- tions. Hence the name propositional logic. A statement: 2 + 2 = 4 is a proposition as we assume that it is a well known and agreed upon truth. A statement: 2 + 2 = 5 is also a proposition (false. A statement:] I am pretty is modeled, if needed as a logical sentence (proposi- tion). We assume that it is false, or true. A statement: 2 + n = 5 is not a proposition; it might be true for some n, for example n=3, false for other n, for example n= 2, and moreover, we don't know what n is. Sentences of this kind are called propositional functions. We model propositional functions within propositional logic by treating propositional functions as propositions. -

COMPSCI 501: Formal Language Theory Insights on Computability Turing Machines Are a Model of Computation Two (No Longer) Surpris
Insights on Computability Turing machines are a model of computation COMPSCI 501: Formal Language Theory Lecture 11: Turing Machines Two (no longer) surprising facts: Marius Minea Although simple, can describe everything [email protected] a (real) computer can do. University of Massachusetts Amherst Although computers are powerful, not everything is computable! Plus: “play” / program with Turing machines! 13 February 2019 Why should we formally define computation? Must indeed an algorithm exist? Back to 1900: David Hilbert’s 23 open problems Increasingly a realization that sometimes this may not be the case. Tenth problem: “Occasionally it happens that we seek the solution under insufficient Given a Diophantine equation with any number of un- hypotheses or in an incorrect sense, and for this reason do not succeed. known quantities and with rational integral numerical The problem then arises: to show the impossibility of the solution under coefficients: To devise a process according to which the given hypotheses or in the sense contemplated.” it can be determined in a finite number of operations Hilbert, 1900 whether the equation is solvable in rational integers. This asks, in effect, for an algorithm. Hilbert’s Entscheidungsproblem (1928): Is there an algorithm that And “to devise” suggests there should be one. decides whether a statement in first-order logic is valid? Church and Turing A Turing machine, informally Church and Turing both showed in 1936 that a solution to the Entscheidungsproblem is impossible for the theory of arithmetic. control To make and prove such a statement, one needs to define computability. In a recent paper Alonzo Church has introduced an idea of “effective calculability”, read/write head which is equivalent to my “computability”, but is very differently defined. -

Roth Book Notes--Mcluhan.Pdf
Book Notes: Reading in the Time of Coronavirus By Jefferson Scholar-in-Residence Dr. Andrew Roth Mediated America Part Two: Who Was Marshall McLuhan & What Did He Say? McLuhan, Marshall. The Mechanical Bride: Folklore of Industrial Man. (New York: Vanguard Press, 1951). McLuhan, Marshall and Bruce R. Powers. The Global Village: Transformations in World Life and Media in the 21st Century. (New York: Oxford University Press, 1989). McLuhan, Marshall. The Gutenberg Galaxy: The Making of Typographic Man. (Toronto: University of Toronto Press, 1962). McLuhan, Marshall. Understanding Media: The Extensions of Man. (Cambridge, MA: MIT Press, 1994. Originally Published 1964). The Mechanical Bride: The Gutenberg Galaxy Understanding Media: The Folklore of Industrial Man by Marshall McLuhan Extensions of Man by Marshall by Marshall McLuhan McLuhan and Lewis H. Lapham Last week in Book Notes, we discussed Norman Mailer’s discovery in Superman Comes to the Supermarket of mediated America, that trifurcated world in which Americans live simultaneously in three realms, in three realities. One is based, more or less, in the physical world of nouns and verbs, which is to say people, other creatures, and things (objects) that either act or are acted upon. The second is a world of mental images lodged between people’s ears; and, third, and most importantly, the mediasphere. The mediascape is where the two worlds meet, filtering back and forth between each other sometimes in harmony but frequently in a dissonant clanging and clashing of competing images, of competing cultures, of competing realities. Two quick asides: First, it needs to be immediately said that Americans are not the first ever and certainly not the only 21st century denizens of multiple realities, as any glimpse of Japanese anime, Chinese Donghua, or British Cosplay Girls Facebook page will attest, but Americans first gave it full bloom with the “Hollywoodization,” the “Disneyfication” of just about anything, for when Mae West murmured, “Come up and see me some time,” she said more than she could have ever imagined. -

Use Formal and Informal Language in Persuasive Text
Author’S Craft Use Formal and Informal Language in Persuasive Text 1. Focus Objectives Explain Using Formal and Informal Language In this mini-lesson, students will: Say: When I write a persuasive letter, I want people to see things my way. I use • Learn to use both formal and different kinds of language to gain support. To connect with my readers, I use informal language in persuasive informal language. Informal language is conversational; it sounds a lot like the text. way we speak to one another. Then, to make sure that people believe me, I also use formal language. When I use formal language, I don’t use slang words, and • Practice using formal and informal I am more objective—I focus on facts over opinions. Today I’m going to show language in persuasive text. you ways to use both types of language in persuasive letters. • Discuss how they can apply this strategy to their independent writing. Model How Writers Use Formal and Informal Language Preparation Display the modeling text on chart paper or using the interactive whiteboard resources. Materials Needed • Chart paper and markers 1. As the parent of a seventh grader, let me assure you this town needs a new • Interactive whiteboard resources middle school more than it needs Old Oak. If selling the land gets us a new school, I’m all for it. Advanced Preparation 2. Last month, my daughter opened her locker and found a mouse. She was traumatized by this experience. She has not used her locker since. If you will not be using the interactive whiteboard resources, copy the Modeling Text modeling text and practice text onto chart paper prior to the mini-lesson. -

Thinking Recursively Part Four
Thinking Recursively Part Four Announcements ● Assignment 2 due right now. ● Assignment 3 out, due next Monday, April 30th at 10:00AM. ● Solve cool problems recursively! ● Sharpen your recursive skillset! A Little Word Puzzle “What nine-letter word can be reduced to a single-letter word one letter at a time by removing letters, leaving it a legal word at each step?” Shrinkable Words ● Let's call a word with this property a shrinkable word. ● Anything that isn't a word isn't a shrinkable word. ● Any single-letter word is shrinkable ● A, I, O ● Any multi-letter word is shrinkable if you can remove a letter to form a word, and that word itself is shrinkable. ● So how many shrinkable words are there? Recursive Backtracking ● The function we wrote last time is an example of recursive backtracking. ● At each step, we try one of many possible options. ● If any option succeeds, that's great! We're done. ● If none of the options succeed, then this particular problem can't be solved. Recursive Backtracking if (problem is sufficiently simple) { return whether or not the problem is solvable } else { for (each choice) { try out that choice. if it succeeds, return success. } return failure } Failure in Backtracking S T A R T L I N G Failure in Backtracking S T A R T L I N G S T A R T L I G Failure in Backtracking S T A R T L I N G S T A R T L I G Failure in Backtracking S T A R T L I N G Failure in Backtracking S T A R T L I N G S T A R T I N G Failure in Backtracking S T A R T L I N G S T A R T I N G S T R T I N G Failure in Backtracking S T A R T L I N G S T A R T I N G S T R T I N G Failure in Backtracking S T A R T L I N G S T A R T I N G Failure in Backtracking S T A R T L I N G S T A R T I N G S T A R I N G Failure in Backtracking ● Returning false in recursive backtracking does not mean that the entire problem is unsolvable! ● Instead, it just means that the current subproblem is unsolvable. -

The Complexity of Richness: Media, Message, and Communication Outcomes
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by The University of North Carolina at Greensboro The complexity of richness: Media, message, and communication outcomes By: Robert F. Otondo, James R. Van Scotter, David G. Allen, Prashant Palvia Otondo, R.F., Van Scotter, J.R., Allen, D.G., and Palvia, P. ―The Complexity of Richness: Media, Message, and Communication Outcomes.‖ Information & Management. Vol. 40, 2008, pp. 21-30. Made available courtesy of Elsevier: http://www.elsevier.com ***Reprinted with permission. No further reproduction is authorized without written permission from Elsevier. This version of the document is not the version of record. Figures and/or pictures may be missing from this format of the document.*** Abstract: Dynamic web-based multimedia communication has been increasingly used in organizations, necessitating a better understanding of how it affects their outcomes. We investigated factor structures and relationships involving media and information richness and communication outcomes using an experimental design. We found that these multimedia contexts were best explained by models with multiple fine-grained constructs rather than those based on one- or two-dimensions. Also, media richness theory poorly predicted relationships involving these constructs. Keywords: Media richness theory; Information richness; Communication theory Article: 1. Introduction Investigation of relationships between the media and communication effectiveness has not provided consistent results. However, lack of understanding has not deterred organizations from investing heavily in new and dynamic forms of web-based multimedia for their marketing, public relations, training, and recruiting activities. Few studies have examined the effects of media channels and informational content on decision-making and other organizational outcomes. -

Midterm Study Sheet for CS3719 Regular Languages and Finite
Midterm study sheet for CS3719 Regular languages and finite automata: • An alphabet is a finite set of symbols. Set of all finite strings over an alphabet Σ is denoted Σ∗.A language is a subset of Σ∗. Empty string is called (epsilon). • Regular expressions are built recursively starting from ∅, and symbols from Σ and closing under ∗ Union (R1 ∪ R2), Concatenation (R1 ◦ R2) and Kleene Star (R denoting 0 or more repetitions of R) operations. These three operations are called regular operations. • A Deterministic Finite Automaton (DFA) D is a 5-tuple (Q, Σ, δ, q0,F ), where Q is a finite set of states, Σ is the alphabet, δ : Q × Σ → Q is the transition function, q0 is the start state, and F is the set of accept states. A DFA accepts a string if there exists a sequence of states starting with r0 = q0 and ending with rn ∈ F such that ∀i, 0 ≤ i < n, δ(ri, wi) = ri+1. The language of a DFA, denoted L(D) is the set of all and only strings that D accepts. • Deterministic finite automata are used in string matching algorithms such as Knuth-Morris-Pratt algorithm. • A language is called regular if it is recognized by some DFA. • ‘Theorem: The class of regular languages is closed under union, concatenation and Kleene star operations. • A non-deterministic finite automaton (NFA) is a 5-tuple (Q, Σ, δ, q0,F ), where Q, Σ, q0 and F are as in the case of DFA, but the transition function δ is δ : Q × (Σ ∪ {}) → P(Q). -

Chapter 6 Formal Language Theory
Chapter 6 Formal Language Theory In this chapter, we introduce formal language theory, the computational theories of languages and grammars. The models are actually inspired by formal logic, enriched with insights from the theory of computation. We begin with the definition of a language and then proceed to a rough characterization of the basic Chomsky hierarchy. We then turn to a more de- tailed consideration of the types of languages in the hierarchy and automata theory. 6.1 Languages What is a language? Formally, a language L is defined as as set (possibly infinite) of strings over some finite alphabet. Definition 7 (Language) A language L is a possibly infinite set of strings over a finite alphabet Σ. We define Σ∗ as the set of all possible strings over some alphabet Σ. Thus L ⊆ Σ∗. The set of all possible languages over some alphabet Σ is the set of ∗ all possible subsets of Σ∗, i.e. 2Σ or ℘(Σ∗). This may seem rather simple, but is actually perfectly adequate for our purposes. 6.2 Grammars A grammar is a way to characterize a language L, a way to list out which strings of Σ∗ are in L and which are not. If L is finite, we could simply list 94 CHAPTER 6. FORMAL LANGUAGE THEORY 95 the strings, but languages by definition need not be finite. In fact, all of the languages we are interested in are infinite. This is, as we showed in chapter 2, also true of human language. Relating the material of this chapter to that of the preceding two, we can view a grammar as a logical system by which we can prove things. -
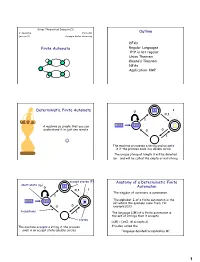
Deterministic Finite Automata 0 0,1 1
Great Theoretical Ideas in CS V. Adamchik CS 15-251 Outline Lecture 21 Carnegie Mellon University DFAs Finite Automata Regular Languages 0n1n is not regular Union Theorem Kleene’s Theorem NFAs Application: KMP 11 1 Deterministic Finite Automata 0 0,1 1 A machine so simple that you can 0111 111 1 ϵ understand it in just one minute 0 0 1 The machine processes a string and accepts it if the process ends in a double circle The unique string of length 0 will be denoted by ε and will be called the empty or null string accept states (F) Anatomy of a Deterministic Finite start state (q0) 11 0 Automaton 0,1 1 The singular of automata is automaton. 1 The alphabet Σ of a finite automaton is the 0111 111 1 ϵ set where the symbols come from, for 0 0 example {0,1} transitions 1 The language L(M) of a finite automaton is the set of strings that it accepts states L(M) = {x∈Σ: M accepts x} The machine accepts a string if the process It’s also called the ends in an accept state (double circle) “language decided/accepted by M”. 1 The Language L(M) of Machine M The Language L(M) of Machine M 0 0 0 0,1 1 q 0 q1 q0 1 1 What language does this DFA decide/accept? L(M) = All strings of 0s and 1s The language of a finite automaton is the set of strings that it accepts L(M) = { w | w has an even number of 1s} M = (Q, Σ, , q0, F) Q = {q0, q1, q2, q3} Formal definition of DFAs where Σ = {0,1} A finite automaton is a 5-tuple M = (Q, Σ, , q0, F) q0 Q is start state Q is the finite set of states F = {q1, q2} Q accept states : Q Σ → Q transition function Σ is the alphabet : Q Σ → Q is the transition function q 1 0 1 0 1 0,1 q0 Q is the start state q0 q0 q1 1 q q1 q2 q2 F Q is the set of accept states 0 M q2 0 0 q2 q3 q2 q q q 1 3 0 2 L(M) = the language of machine M q3 = set of all strings machine M accepts EXAMPLE Determine the language An automaton that accepts all recognized by and only those strings that contain 001 1 0,1 0,1 0 1 0 0 0 1 {0} {00} {001} 1 L(M)={1,11,111, …} 2 Membership problem Determine the language decided by Determine whether some word belongs to the language. -
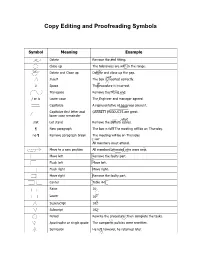
Copy Editing and Proofreading Symbols
Copy Editing and Proofreading Symbols Symbol Meaning Example Delete Remove the end fitting. Close up The tolerances are with in the range. Delete and Close up Deltete and close up the gap. not Insert The box is inserted correctly. # # Space Theprocedure is incorrect. Transpose Remove the fitting end. / or lc Lower case The Engineer and manager agreed. Capitalize A representative of nasa was present. Capitalize first letter and GARRETT PRODUCTS are great. lower case remainder stet stet Let stand Remove the battery cables. ¶ New paragraph The box is full. The meeting will be on Thursday. no ¶ Remove paragraph break The meeting will be on Thursday. no All members must attend. Move to a new position All members attended who were new. Move left Remove the faulty part. Flush left Move left. Flush right Move right. Move right Remove the faulty part. Center Table 4-1 Raise 162 Lower 162 Superscript 162 Subscript 162 . Period Rewrite the procedure. Then complete the tasks. ‘ ‘ Apostrophe or single quote The companys policies were rewritten. ; Semicolon He left however, he returned later. ; Symbol Meaning Example Colon There were three items nuts, bolts, and screws. : : , Comma Apply pressure to the first second and third bolts. , , -| Hyphen A valuable byproduct was created. sp Spell out The info was incorrect. sp Abbreviate The part was twelve feet long. || or = Align Personnel Facilities Equipment __________ Underscore The part was listed under Electrical. Run in with previous line He rewrote the pages and went home. Em dash It was the beginning so I thought. En dash The value is 120 408. -

Axiomatic Set Teory P.D.Welch
Axiomatic Set Teory P.D.Welch. August 16, 2020 Contents Page 1 Axioms and Formal Systems 1 1.1 Introduction 1 1.2 Preliminaries: axioms and formal systems. 3 1.2.1 The formal language of ZF set theory; terms 4 1.2.2 The Zermelo-Fraenkel Axioms 7 1.3 Transfinite Recursion 9 1.4 Relativisation of terms and formulae 11 2 Initial segments of the Universe 17 2.1 Singular ordinals: cofinality 17 2.1.1 Cofinality 17 2.1.2 Normal Functions and closed and unbounded classes 19 2.1.3 Stationary Sets 22 2.2 Some further cardinal arithmetic 24 2.3 Transitive Models 25 2.4 The H sets 27 2.4.1 H - the hereditarily finite sets 28 2.4.2 H - the hereditarily countable sets 29 2.5 The Montague-Levy Reflection theorem 30 2.5.1 Absoluteness 30 2.5.2 Reflection Theorems 32 2.6 Inaccessible Cardinals 34 2.6.1 Inaccessible cardinals 35 2.6.2 A menagerie of other large cardinals 36 3 Formalising semantics within ZF 39 3.1 Definite terms and formulae 39 3.1.1 The non-finite axiomatisability of ZF 44 3.2 Formalising syntax 45 3.3 Formalising the satisfaction relation 46 3.4 Formalising definability: the function Def. 47 3.5 More on correctness and consistency 48 ii iii 3.5.1 Incompleteness and Consistency Arguments 50 4 The Constructible Hierarchy 53 4.1 The L -hierarchy 53 4.2 The Axiom of Choice in L 56 4.3 The Axiom of Constructibility 57 4.4 The Generalised Continuum Hypothesis in L.