A Theorem for Knuth-Arrows
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Large but Finite
Department of Mathematics MathClub@WMU Michigan Epsilon Chapter of Pi Mu Epsilon Large but Finite Drake Olejniczak Department of Mathematics, WMU What is the biggest number you can imagine? Did you think of a million? a billion? a septillion? Perhaps you remembered back to the time you heard the term googol or its show-off of an older brother googolplex. Or maybe you thought of infinity. No. Surely, `infinity' is cheating. Large, finite numbers, truly monstrous numbers, arise in several areas of mathematics as well as in astronomy and computer science. For instance, Euclid defined perfect numbers as positive integers that are equal to the sum of their proper divisors. He is also credited with the discovery of the first four perfect numbers: 6, 28, 496, 8128. It may be surprising to hear that the ninth perfect number already has 37 digits, or that the thirteenth perfect number vastly exceeds the number of particles in the observable universe. However, the sequence of perfect numbers pales in comparison to some other sequences in terms of growth rate. In this talk, we will explore examples of large numbers such as Graham's number, Rayo's number, and the limits of the universe. As well, we will encounter some fast-growing sequences and functions such as the TREE sequence, the busy beaver function, and the Ackermann function. Through this, we will uncover a structure on which to compare these concepts and, hopefully, gain a sense of what it means for a number to be truly large. 4 p.m. Friday October 12 6625 Everett Tower, WMU Main Campus All are welcome! http://www.wmich.edu/mathclub/ Questions? Contact Patrick Bennett ([email protected]) . -

Lesson 2: the Multiplication of Polynomials
NYS COMMON CORE MATHEMATICS CURRICULUM Lesson 2 M1 ALGEBRA II Lesson 2: The Multiplication of Polynomials Student Outcomes . Students develop the distributive property for application to polynomial multiplication. Students connect multiplication of polynomials with multiplication of multi-digit integers. Lesson Notes This lesson begins to address standards A-SSE.A.2 and A-APR.C.4 directly and provides opportunities for students to practice MP.7 and MP.8. The work is scaffolded to allow students to discern patterns in repeated calculations, leading to some general polynomial identities that are explored further in the remaining lessons of this module. As in the last lesson, if students struggle with this lesson, they may need to review concepts covered in previous grades, such as: The connection between area properties and the distributive property: Grade 7, Module 6, Lesson 21. Introduction to the table method of multiplying polynomials: Algebra I, Module 1, Lesson 9. Multiplying polynomials (in the context of quadratics): Algebra I, Module 4, Lessons 1 and 2. Since division is the inverse operation of multiplication, it is important to make sure that your students understand how to multiply polynomials before moving on to division of polynomials in Lesson 3 of this module. In Lesson 3, division is explored using the reverse tabular method, so it is important for students to work through the table diagrams in this lesson to prepare them for the upcoming work. There continues to be a sharp distinction in this curriculum between justification and proof, such as justifying the identity (푎 + 푏)2 = 푎2 + 2푎푏 + 푏 using area properties and proving the identity using the distributive property. -
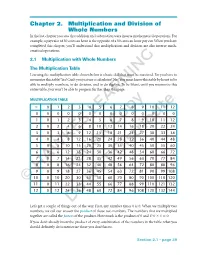
Chapter 2. Multiplication and Division of Whole Numbers in the Last Chapter You Saw That Addition and Subtraction Were Inverse Mathematical Operations
Chapter 2. Multiplication and Division of Whole Numbers In the last chapter you saw that addition and subtraction were inverse mathematical operations. For example, a pay raise of 50 cents an hour is the opposite of a 50 cents an hour pay cut. When you have completed this chapter, you’ll understand that multiplication and division are also inverse math- ematical operations. 2.1 Multiplication with Whole Numbers The Multiplication Table Learning the multiplication table shown below is a basic skill that must be mastered. Do you have to memorize this table? Yes! Can’t you just use a calculator? No! You must know this table by heart to be able to multiply numbers, to do division, and to do algebra. To be blunt, until you memorize this entire table, you won’t be able to progress further than this page. MULTIPLICATION TABLE ϫ 012 345 67 89101112 0 000 000LEARNING 00 000 00 1 012 345 67 89101112 2 024 681012Copy14 16 18 20 22 24 3 036 9121518212427303336 4 0481216 20 24 28 32 36 40 44 48 5051015202530354045505560 6061218243036424854606672Distribute 7071421283542495663707784 8081624324048566472808896 90918273HAWKESReview645546372819099108 10 0 10 20 30 40 50 60 70 80 90 100 110 120 ©11 0 11 22 33 44NOT 55 66 77 88 99 110 121 132 12 0 12 24 36 48 60 72 84 96 108 120 132 144 Do Let’s get a couple of things out of the way. First, any number times 0 is 0. When we multiply two numbers, we call our answer the product of those two numbers. -

Grade 7/8 Math Circles the Scale of Numbers Introduction
Faculty of Mathematics Centre for Education in Waterloo, Ontario N2L 3G1 Mathematics and Computing Grade 7/8 Math Circles November 21/22/23, 2017 The Scale of Numbers Introduction Last week we quickly took a look at scientific notation, which is one way we can write down really big numbers. We can also use scientific notation to write very small numbers. 1 × 103 = 1; 000 1 × 102 = 100 1 × 101 = 10 1 × 100 = 1 1 × 10−1 = 0:1 1 × 10−2 = 0:01 1 × 10−3 = 0:001 As you can see above, every time the value of the exponent decreases, the number gets smaller by a factor of 10. This pattern continues even into negative exponent values! Another way of picturing negative exponents is as a division by a positive exponent. 1 10−6 = = 0:000001 106 In this lesson we will be looking at some famous, interesting, or important small numbers, and begin slowly working our way up to the biggest numbers ever used in mathematics! Obviously we can come up with any arbitrary number that is either extremely small or extremely large, but the purpose of this lesson is to only look at numbers with some kind of mathematical or scientific significance. 1 Extremely Small Numbers 1. Zero • Zero or `0' is the number that represents nothingness. It is the number with the smallest magnitude. • Zero only began being used as a number around the year 500. Before this, ancient mathematicians struggled with the concept of `nothing' being `something'. 2. Planck's Constant This is the smallest number that we will be looking at today other than zero. -

Maths Secrets of Simpsons Revealed in New Book
MONDAY 7 OCTOBER 2013 WWW.THEDAY.CO.UK Maths secrets of Simpsons revealed in new book The most successful TV show of all time is written by a team of brilliant ‘mathletes’, says writer Simon Singh, and full of obscure mathematical jokes. Can numbers really be all that funny? MATHEMATICS Nerd hero: The smartest girl in Springfield was created by a team of maths wizards. he world’s most popular cartoon a perfect number, a narcissistic number insist that their love of maths contrib- family has a secret: their lines are and a Mersenne Prime. utes directly to the more obvious humour written by a team of expert mathema- Another of these maths jokes – a black- that has made the show such a hit. Turn- Tticians – former ‘mathletes’ who are board showing 398712 + 436512 = 447212 ing intuitions about comedy into concrete as happy solving differential equa- – sent shivers down Simon Singh’s spine. jokes is like wrestling mathematical tions as crafting jokes. ‘I was so shocked,’ he writes, ‘I almost hunches into proofs and formulas. Comedy Now, science writer Simon Singh has snapped my slide rule.’ The numbers are and maths, says Cohen, are both explora- revealed The Simpsons’ secret math- a fake exception to a famous mathemati- tions into the unknown. ematical formula in a new book*. He cal rule known as Fermat’s Last Theorem. combed through hundreds of episodes One episode from 1990 features a Mathletes and trawled obscure internet forums to teacher making a maths joke to a class of Can maths really be funny? There are many discover that behind the show’s comic brilliant students in which Bart Simpson who will think comparing jokes to equa- exterior lies a hidden core of advanced has been accidentally included. -
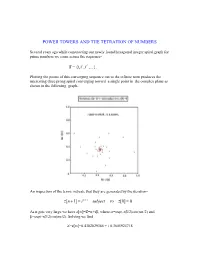
Power Towers and the Tetration of Numbers
POWER TOWERS AND THE TETRATION OF NUMBERS Several years ago while constructing our newly found hexagonal integer spiral graph for prime numbers we came across the sequence- i S {i,i i ,i i ,...}, Plotting the points of this converging sequence out to the infinite term produces the interesting three prong spiral converging toward a single point in the complex plane as shown in the following graph- An inspection of the terms indicate that they are generated by the iteration- z[n 1] i z[n] subject to z[0] 0 As n gets very large we have z[]=Z=+i, where =exp(-/2)cos(/2) and =exp(-/2)sin(/2). Solving we find – Z=z[]=0.4382829366 + i 0.3605924718 It is the purpose of the present article to generalize the above result to any complex number z=a+ib by looking at the general iterative form- z[n+1]=(a+ib)z[n] subject to z[0]=1 Here N=a+ib with a and b being real numbers which are not necessarily integers. Such an iteration represents essentially a tetration of the number N. That is, its value up through the nth iteration, produces the power tower- Z Z n Z Z Z with n-1 zs in the exponents Thus- 22 4 2 22 216 65536 Note that the evaluation of the powers is from the top down and so is not equivalent to the bottom up operation 44=256. Also it is clear that the sequence {1 2,2 2,3 2,4 2,...}diverges very rapidly unlike the earlier case {1i,2 i,3i,4i,...} which clearly converges. -
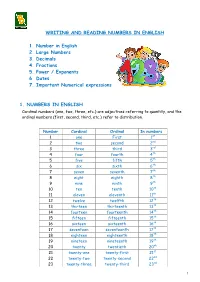
WRITING and READING NUMBERS in ENGLISH 1. Number in English 2
WRITING AND READING NUMBERS IN ENGLISH 1. Number in English 2. Large Numbers 3. Decimals 4. Fractions 5. Power / Exponents 6. Dates 7. Important Numerical expressions 1. NUMBERS IN ENGLISH Cardinal numbers (one, two, three, etc.) are adjectives referring to quantity, and the ordinal numbers (first, second, third, etc.) refer to distribution. Number Cardinal Ordinal In numbers 1 one First 1st 2 two second 2nd 3 three third 3rd 4 four fourth 4th 5 five fifth 5th 6 six sixth 6th 7 seven seventh 7th 8 eight eighth 8th 9 nine ninth 9th 10 ten tenth 10th 11 eleven eleventh 11th 12 twelve twelfth 12th 13 thirteen thirteenth 13th 14 fourteen fourteenth 14th 15 fifteen fifteenth 15th 16 sixteen sixteenth 16th 17 seventeen seventeenth 17th 18 eighteen eighteenth 18th 19 nineteen nineteenth 19th 20 twenty twentieth 20th 21 twenty-one twenty-first 21st 22 twenty-two twenty-second 22nd 23 twenty-three twenty-third 23rd 1 24 twenty-four twenty-fourth 24th 25 twenty-five twenty-fifth 25th 26 twenty-six twenty-sixth 26th 27 twenty-seven twenty-seventh 27th 28 twenty-eight twenty-eighth 28th 29 twenty-nine twenty-ninth 29th 30 thirty thirtieth 30th st 31 thirty-one thirty-first 31 40 forty fortieth 40th 50 fifty fiftieth 50th 60 sixty sixtieth 60th th 70 seventy seventieth 70 th 80 eighty eightieth 80 90 ninety ninetieth 90th 100 one hundred hundredth 100th 500 five hundred five hundredth 500th 1,000 One/ a thousandth 1000th thousand one thousand one thousand five 1500th 1,500 five hundred, hundredth or fifteen hundred 100,000 one hundred hundred thousandth 100,000th thousand 1,000,000 one million millionth 1,000,000 ◊◊ Click on the links below to practice your numbers: http://www.manythings.org/wbg/numbers-jw.html https://www.englisch-hilfen.de/en/exercises/numbers/index.php 2 We don't normally write numbers with words, but it's possible to do this. -

The Exponential Function
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln MAT Exam Expository Papers Math in the Middle Institute Partnership 5-2006 The Exponential Function Shawn A. Mousel University of Nebraska-Lincoln Follow this and additional works at: https://digitalcommons.unl.edu/mathmidexppap Part of the Science and Mathematics Education Commons Mousel, Shawn A., "The Exponential Function" (2006). MAT Exam Expository Papers. 26. https://digitalcommons.unl.edu/mathmidexppap/26 This Article is brought to you for free and open access by the Math in the Middle Institute Partnership at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in MAT Exam Expository Papers by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. The Exponential Function Expository Paper Shawn A. Mousel In partial fulfillment of the requirements for the Masters of Arts in Teaching with a Specialization in the Teaching of Middle Level Mathematics in the Department of Mathematics. Jim Lewis, Advisor May 2006 Mousel – MAT Expository Paper - 1 One of the basic principles studied in mathematics is the observation of relationships between two connected quantities. A function is this connecting relationship, typically expressed in a formula that describes how one element from the domain is related to exactly one element located in the range (Lial & Miller, 1975). An exponential function is a function with the basic form f (x) = ax , where a (a fixed base that is a real, positive number) is greater than zero and not equal to 1. The exponential function is not to be confused with the polynomial functions, such as x 2. One way to recognize the difference between the two functions is by the name of the function. -

Simple Statements, Large Numbers
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln MAT Exam Expository Papers Math in the Middle Institute Partnership 7-2007 Simple Statements, Large Numbers Shana Streeks University of Nebraska-Lincoln Follow this and additional works at: https://digitalcommons.unl.edu/mathmidexppap Part of the Science and Mathematics Education Commons Streeks, Shana, "Simple Statements, Large Numbers" (2007). MAT Exam Expository Papers. 41. https://digitalcommons.unl.edu/mathmidexppap/41 This Article is brought to you for free and open access by the Math in the Middle Institute Partnership at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in MAT Exam Expository Papers by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. Master of Arts in Teaching (MAT) Masters Exam Shana Streeks In partial fulfillment of the requirements for the Master of Arts in Teaching with a Specialization in the Teaching of Middle Level Mathematics in the Department of Mathematics. Gordon Woodward, Advisor July 2007 Simple Statements, Large Numbers Shana Streeks July 2007 Page 1 Streeks Simple Statements, Large Numbers Large numbers are numbers that are significantly larger than those ordinarily used in everyday life, as defined by Wikipedia (2007). Large numbers typically refer to large positive integers, or more generally, large positive real numbers, but may also be used in other contexts. Very large numbers often occur in fields such as mathematics, cosmology, and cryptography. Sometimes people refer to numbers as being “astronomically large”. However, it is easy to mathematically define numbers that are much larger than those even in astronomy. We are familiar with the large magnitudes, such as million or billion. -

1 Powers of Two
A. V. GERBESSIOTIS CS332-102 Spring 2020 Jan 24, 2020 Computer Science: Fundamentals Page 1 Handout 3 1 Powers of two Definition 1.1 (Powers of 2). The expression 2n means the multiplication of n twos. Therefore, 22 = 2 · 2 is a 4, 28 = 2 · 2 · 2 · 2 · 2 · 2 · 2 · 2 is 256, and 210 = 1024. Moreover, 21 = 2 and 20 = 1. Several times one might write 2 ∗ ∗n or 2ˆn for 2n (ˆ is the hat/caret symbol usually co-located with the numeric-6 keyboard key). Prefix Name Multiplier d deca 101 = 10 h hecto 102 = 100 3 Power Value k kilo 10 = 1000 6 0 M mega 10 2 1 9 1 G giga 10 2 2 12 4 T tera 10 2 16 P peta 1015 8 2 256 E exa 1018 210 1024 d deci 10−1 216 65536 c centi 10−2 Prefix Name Multiplier 220 1048576 m milli 10−3 Ki kibi or kilobinary 210 − 230 1073741824 m micro 10 6 Mi mebi or megabinary 220 40 n nano 10−9 Gi gibi or gigabinary 230 2 1099511627776 −12 40 250 1125899906842624 p pico 10 Ti tebi or terabinary 2 f femto 10−15 Pi pebi or petabinary 250 Figure 1: Powers of two Figure 2: SI system prefixes Figure 3: SI binary prefixes Definition 1.2 (Properties of powers). • (Multiplication.) 2m · 2n = 2m 2n = 2m+n. (Dot · optional.) • (Division.) 2m=2n = 2m−n. (The symbol = is the slash symbol) • (Exponentiation.) (2m)n = 2m·n. Example 1.1 (Approximations for 210 and 220 and 230). -

Attributes of Infinity
International Journal of Applied Physics and Mathematics Attributes of Infinity Kiamran Radjabli* Utilicast, La Jolla, California, USA. * Corresponding author. Email: [email protected] Manuscript submitted May 15, 2016; accepted October 14, 2016. doi: 10.17706/ijapm.2017.7.1.42-48 Abstract: The concept of infinity is analyzed with an objective to establish different infinity levels. It is proposed to distinguish layers of infinity using the diverging functions and series, which transform finite numbers to infinite domain. Hyper-operations of iterated exponentiation establish major orders of infinity. It is proposed to characterize the infinity by three attributes: order, class, and analytic value. In the first order of infinity, the infinity class is assessed based on the “analytic convergence” of the Riemann zeta function. Arithmetic operations in infinity are introduced and the results of the operations are associated with the infinity attributes. Key words: Infinity, class, order, surreal numbers, divergence, zeta function, hyperpower function, tetration, pentation. 1. Introduction Traditionally, the abstract concept of infinity has been used to generically designate any extremely large result that cannot be measured or determined. However, modern mathematics attempts to introduce new concepts to address the properties of infinite numbers and operations with infinities. The system of hyperreal numbers [1], [2] is one of the approaches to define infinite and infinitesimal quantities. The hyperreals (a.k.a. nonstandard reals) *R, are an extension of the real numbers R that contains numbers greater than anything of the form 1 + 1 + … + 1, which is infinite number, and its reciprocal is infinitesimal. Also, the set theory expands the concept of infinity with introduction of various orders of infinity using ordinal numbers. -

Big Numbers Tom Davis [email protected] September 21, 2011
Big Numbers Tom Davis [email protected] http://www.geometer.org/mathcircles September 21, 2011 1 Introduction The problem is that we tend to live among the set of puny integers and generally ignore the vast infinitude of larger ones. How trite and limiting our view! — P.D. Schumer It seems that most children at some age get interested in large numbers. “What comes after a thousand? After a million? After a billion?”, et cetera, are common questions. Obviously there is no limit; whatever number you name, a larger one can be obtained simply by adding one. But what is interesting is just how large a number can be expressed in a fairly compact way. Using the standard arithmetic operations (addition, subtraction, multiplication, division and exponentia- tion), what is the largest number you can make using three copies of the digit “9”? It’s pretty clear we should just stick to exponents, and given that, here are some possibilities: 999, 999, 9 999, and 99 . 9 9 Already we need to be a little careful with the final one: 99 . Does this mean: (99)9 or 9(9 )? Since (99)9 = 981 this interpretation would gain us very little. If this were the standard definition, then why c not write ab as abc? Because of this, a tower of exponents is always interpreted as being evaluated from d d c c c (c ) right to left. In other words, ab = a(b ), ab = a(b ), et cetera. 9 With this definition of towers of exponents, it is clear that 99 is the best we can do.