Classification of Propaganda on Fragment Level: Using Logistic Regression with Handcrafted Contextual Features
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Evocative and Persuasive Power of Loaded Words in the Political Discourse on Drug Reform
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by OpenEdition Lexis Journal in English Lexicology 13 | 2019 Lexicon, Sensations, Perceptions and Emotions Conjuring up terror and tears: the evocative and persuasive power of loaded words in the political discourse on drug reform Sarah Bourse Electronic version URL: http://journals.openedition.org/lexis/3182 DOI: 10.4000/lexis.3182 ISSN: 1951-6215 Publisher Université Jean Moulin - Lyon 3 Electronic reference Sarah Bourse, « Conjuring up terror and tears: the evocative and persuasive power of loaded words in the political discourse on drug reform », Lexis [Online], 13 | 2019, Online since 14 March 2019, connection on 20 April 2019. URL : http://journals.openedition.org/lexis/3182 ; DOI : 10.4000/ lexis.3182 This text was automatically generated on 20 April 2019. Lexis is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License. Conjuring up terror and tears: the evocative and persuasive power of loaded w... 1 Conjuring up terror and tears: the evocative and persuasive power of loaded words in the political discourse on drug reform Sarah Bourse Introduction 1 In the last few years, the use of the adjective “post-truth” has been emerging in the media to describe the political scene. This concept has gained momentum in the midst of fake allegations during the Brexit vote and the 2016 American presidential election, so much so that The Oxford Dictionary elected it word of the year in 2016. Formerly referring to the lies at the core of political scandals1, the term “post-truth” now describes a situation where the objective facts have far less importance and impact than appeals to emotion and personal belief in order to influence public opinion2. -
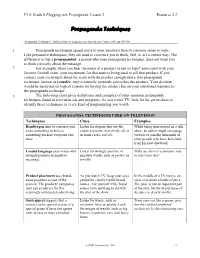
Lesson 2-Resource 2.2 Propaganda Techniques
ELA Grade 6 Plugging into Propaganda, Lesson 2 Resource 2.2 Propaganda Techniques “Propaganda Techniques,” Holt Literature & Language Arts, Introductory Course, 2003, pp. 643-645 1 Propaganda techniques appeal more to your emotions than to common sense or logic. Like persuasive techniques, they are used to convince you to think, feel, or act a certain way. The difference is that a propagandist, a person who uses propaganda techniques, does not want you to think critically about the message. 2 For example, when you hear the name of a product or see its logo* associated with your favorite football team, your excitement for that team is being used to sell that product. If you connect your excitement about the team with the product enough times, this propaganda technique, known as transfer, may eventually persuade you to buy the product. Your decision would be based not on logical reasons for buying the product but on your emotional response to the propaganda technique. 3 The following chart gives definitions and examples of other common propaganda techniques found in television ads and programs. As you watch TV, look for the given clues to identify these techniques in every kind of programming you watch. PROPAGANDA TECHNIQUES USED ON TELEVISION Techniques Clues Examples Bandwagon tries to convince you Listen for slogans that use the While being interviewed on a talk to do something or believe words everyone, everybody, all, or show, an author might encourage something because everyone else in some cases, nobody. viewers to join the thousands of does. other people who have benefited from his new diet book. -

Fake News Detection for the Russian Language
Fake news detection for the Russian language Gleb Kuzmin∗ Daniil Larionov∗ Moscow Institute of Physics and Technology Federal Research Center / Dolgoprudny, Russia ”Computer Science and Control” [email protected] / Moscow, Russia [email protected] Dina Pisarevskaya∗ Ivan Smirnov Federal Research Center Federal Research Center ”Computer Science and Control” ”Computer Science and Control” / Moscow, Russia / Moscow, Russia [email protected] [email protected] Abstract In this paper, we trained and compared different models for fake news detection in Russian. For this task, we used such language features as bag-of-n-grams and bag of Rhetorical Structure Theory features, and BERT embeddings. We also compared the score of our models with the human score on this task and showed that our models deal with fake news detection better. We investigated the nature of fake news by dividing it into two non-overlapping classes: satire and fake news. As a result, we obtained the set of models for fake news detection; the best of these models achieved 0.889 F1-score on the test set for 2 classes and 0.9076 F1-score on 3 classes task. 1 Introduction Fake news detection becomes a more significant task. It is connected with an increasing number of news in media and social media. To prevent rumors and misinformation from spreading in this news, we need to have a system able to detect fake news. It also could be useful because it’s hard for people to recognize fake news. Approaches to this task are being developed for English. However, fake news texts can be written originally in different ’source’ languages, i.e. -

Neural Architectures for Fine-Grained Propaganda Detection in News
Neural Architectures for Fine-Grained Propaganda Detection in News Pankaj Gupta1,2, Khushbu Saxena1, Usama Yaseen1,2, Thomas Runkler1, Hinrich Schutze¨ 2 1Corporate Technology, Machine-Intelligence (MIC-DE), Siemens AG Munich, Germany 2CIS, University of Munich (LMU) Munich, Germany [email protected] | [email protected] Abstract techniques in news articles at sentence and frag- ment level, respectively and thus, promotes ex- This paper describes our system (MIC-CIS) plainable AI. For instance, the following text is a details and results of participation in the propaganda of type ‘slogan’. fine-grained propaganda detection shared task Trump tweeted: ‘`BUILD THE WALL!" 2019. To address the tasks of sentence (SLC) | {z } and fragment level (FLC) propaganda detec- slogan tion, we explore different neural architectures Shared Task: This work addresses the two (e.g., CNN, LSTM-CRF and BERT) and ex- tasks in propaganda detection (Da San Mar- tract linguistic (e.g., part-of-speech, named en- tino et al., 2019) of different granularities: (1) tity, readability, sentiment, emotion, etc.), lay- Sentence-level Classification (SLC), a binary clas- out and topical features. Specifically, we have sification that predicts whether a sentence con- designed multi-granularity and multi-tasking tains at least one propaganda technique, and (2) neural architectures to jointly perform both the Fragment-level Classification (FLC), a token-level sentence and fragment level propaganda de- (multi-label) classification that identifies both the tection. Additionally, we investigate different ensemble schemes such as majority-voting, spans and the type of propaganda technique(s). relax-voting, etc. to boost overall system per- Contributions: (1) To address SLC, we de- formance. -

Media Bias, the Social Sciences, and NLP: Automating Frame Analyses to Identify Bias by Word Choice and Labeling
Media Bias, the Social Sciences, and NLP: Automating Frame Analyses to Identify Bias by Word Choice and Labeling Felix Hamborg Dept. of Computer and Information Science University of Konstanz, Germany [email protected] Abstract Even subtle changes in the words used in a news text can strongly impact readers’ opinions (Pa- Media bias can strongly impact the public per- pacharissi and de Fatima Oliveira, 2008; Price et al., ception of topics reported in the news. A dif- 2005; Rugg, 1941; Schuldt et al., 2011). When re- ficult to detect, yet powerful form of slanted news coverage is called bias by word choice ferring to a semantic concept, such as a politician and labeling (WCL). WCL bias can occur, for or other named entities (NEs), authors can label example, when journalists refer to the same the concept, e.g., “illegal aliens,” and choose from semantic concept by using different terms various words to refer to it, e.g., “immigrants” or that frame the concept differently and conse- “aliens.” Instances of bias by word choice and label- quently may lead to different assessments by ing (WCL) frame the referred concept differently readers, such as the terms “freedom fighters” (Entman, 1993, 2007), whereby a broad spectrum and “terrorists,” or “gun rights” and “gun con- trol.” In this research project, I aim to devise of effects occurs. For example, the frame may methods that identify instances of WCL bias change the polarity of the concept, i.e., positively and estimate the frames they induce, e.g., not or negatively, or the frame may emphasize specific only is “terrorists” of negative polarity but also parts of an issue, such as the economic or cultural ascribes to aggression and fear. -

Euphemism and Language Change: the Sixth and Seventh Ages
Lexis Journal in English Lexicology 7 | 2012 Euphemism as a Word-Formation Process Euphemism and Language Change: The Sixth and Seventh Ages Kate Burridge Electronic version URL: http://journals.openedition.org/lexis/355 DOI: 10.4000/lexis.355 ISSN: 1951-6215 Publisher Université Jean Moulin - Lyon 3 Electronic reference Kate Burridge, « Euphemism and Language Change: The Sixth and Seventh Ages », Lexis [Online], 7 | 2012, Online since 25 June 2012, connection on 30 April 2019. URL : http:// journals.openedition.org/lexis/355 ; DOI : 10.4000/lexis.355 Lexis is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License. Lexis 7: “Euphemism as a Word-Formation Process” 65 Euphemism and Language Change: The Sixth and Seventh Ages Kate Burridge1 Abstract No matter which human group we look at, past or present, euphemism and its counterpart dysphemism are powerful forces and they are extremely important for the study of language change. They provide an emotive trigger for word addition, word loss, phonological distortion and semantic shift. Word taBoo plays perpetual havoc with the methods of historical comparative linguistics, even undermining one of the cornerstones of the discipline – the arBitrary nature of the word. When it comes to taBoo words, speakers Behave as if there were a very real connection Between the physical shape of words and their taBoo sense. This is why these words are so unstaBle and why they are so powerful. This paper reviews the various communicative functions of euphemisms and the different linguistic strategies that are used in their creation, focusing on the linguistic creativity that surrounds the topic of ‘old age’ in Modern English (Shakespeare’s sixth and seventh ages). -

Sentiment Patterns in Videos from Left- and Right-Wing Youtube News Channels
Uphill from here: Sentiment patterns in videos from left- and right-wing YouTube news channels Felix Soldner1, Justin Chun-ting Ho2, Mykola Makhortykh3, Isabelle van der Vegt1, Maximilian Mozes1;4 and Bennett Kleinberg1;3 1University College London 2University of Edinburgh 3University of Amsterdam 4Technical University of Munich 1{felix.soldner, isabelle.vandervegt, bennett.kleinberg}@ucl.ac.uk [email protected], [email protected], [email protected] Abstract Netherlands) (Newman et al., 2018). The reasons for the growing online consumption of news are News consumption exhibits an increasing shift many: digital outlets provide higher interactivity towards online sources, which bring platforms such as YouTube more into focus. Thus, the and greater freedom of choice for news readers distribution of politically loaded news is eas- (Van Aelst et al., 2017), and the possibility to ac- ier, receives more attention, but also raises the cess them through mobile devices enables more concern of forming isolated ideological com- flexibility and convenience in consuming news munities. Understanding how such news is content (Schrøder, 2015). communicated and received is becoming in- Despite the multiple benefits associated with creasingly important. To expand our under- standing in this domain, we apply a linguistic "the digital turn" in news consumption, it also temporal trajectory analysis to analyze senti- raises concerns regarding possible changes in the ment patterns in English-language videos from societal role of news media (Coddington, 2015). news channels on YouTube. We examine tran- It has been established that there is a relationship scripts from videos distributed through eight between news consumption and the formation of channels with pro-left and pro-right political public agendas, including political attitudes of the leanings. -

Literature and Propaganda in George Orwell's Essays
LITERATURE AND PROPAGANDA IN GEORGE ORWELL'S ESSAYS Nina Sirkovi ć University of Split, Croatia [email protected] Abstract The paper explores the idea of manipulating language for the purpose of sending emotional messages and creating impressions in order to frame the reality to one's intentions. Among many other writers, George Orwell pointed out the social and political determination of literary writing and the author's responsibility in shaping the public opinion. In his essays, Orwell challenges the position of literature and art in general, concerning the society and political situation of his age. He questions the role of the writer in the age of totalitarianism, when the attitude to art is politically coloured and the integrity of the artist is threatened. The aim of the paper is to analyse several of Orwell's essays written between 1940 and 1949 in order to determine to what extent the relationship between art and politics is possible, provided that the artists still preserve their own sincerity and, as Orwell calls it “honest language“. Key-words: loaded language,literature, art, propaganda, totalitarianism. Introduction The world we live in is highly determined by the politics which influences our way of living, not only in a materialistic sense, but also determining in a great proportion our thinking, decision making and consequently, acting. Although loaded language is present in almost every aspect of human communication, politically loaded language can be dangerous since politics affects viewpoints of an enormous number of people, sometimes whole nations. Freely and Steinberg claim that loaded language provides many possibilities for obstacles to clear thinking. -

An Analysis of the Linguistic Techniques of Propaganda in Marketing and Politics
International Journal of English Learning and Teaching Skills; Vol. 2, No. 2; ISSN : 2639-7412 (Print) ISSN : 2638-5546 (Online) Running head: AN ANALYSIS OF THE LINGUISTIC TECHNIQUES 1 AN ANALYSIS OF THE LINGUISTIC TECHNIQUES OF PROPAGANDA IN MARKETING AND POLITICS Hanan Khaja Mohammad Irfan Institute of Engineering & Management, Kolkata 1181 International Journal of English Learning and Teaching Skills; Vol. 2, No. 2; ISSN : 2639-7412 (Print) ISSN : 2638-5546 (Online) AN ANALYSIS OF THE LINGUISTIC TECHNIQUES 2 Abstract Propaganda may be defined as the deliberate use of manipulation techniques in order to persuade the audience towards a biased opinion which helps a greater power or authority to develop the desirable perspective/choice in the target group. Though initially recognised with positive connotations, “propaganda” today is recognised as corrupt means frequently applied in politics and advertisements to subtly influence public opinion on a large scale which appear seemingly stochastic. This paper intends to explore the various linguistics techniques applied in order to promulgate propaganda and the effects they tend to have on the audience. Amongst the techniques varying from auditory to visual modes of propagation, this paper analyses the modes of establishing rhetoric through the use of language, standard parlance, prosody and other semiotic modalities in a public discourse. Keywords: Propaganda, manipulation, linguistic, techniques, language, parlance, prosody, semiotic modalities. 1182 International Journal of English Learning and Teaching Skills; Vol. 2, No. 2; ISSN : 2639-7412 (Print) ISSN : 2638-5546 (Online) AN ANALYSIS OF THE LINGUISTIC TECHNIQUES 3 AN ANALYSIS OF THE LINGUISTIC TECHNIQUES OF PROPAGANDA IN MARKETING AND POLITICS WHAT IS PROPAGANDA The origins of the semantics of propaganda are rooted in promulgation of “ideas that would not occur naturally, but only via a cultivated or artificial generation” by the Roman Catholic Church. -

1 the Purpose of This Paper Is to Investigate the Logical Boundaries
1 THE ARGUMENTATIVE USES OF EMOTIVE LANGUAGE The purpose of this paper is to investigate the logical boundaries of loaded words, euphemisms and persuasive definitions. The analysis of the argumentative uses of emotive words will be carried out based on argumentation schemes, dialectical concepts such as bias and burden of proof, and ethical principles such as values and value judgment. The object of our inquiry is emotive words, namely words which have an emotive value often exploited in order to advocate a point of view. There may be nothing wrong with using them to persuade an audience, but when emotive language is used to distort the image of reality it becomes deceptive and even fallacious. Determining the difference between reasonable and manipulative uses of emotive terms in arguments is a task that has often been taken up by logic textbooks, beginning with the ancient dialectical tradition. On our view, a term is considered as emotive if it leads the interlocutor to draw a value judgment on the fragment of reality the term is used to refer to. Emotive words therefore stimulate a classification of the kind good/bad on the grounds of values commonly shared by the community to which the interlocutors belong. Such terms can be used reasonably to support certain decisions or evaluations, and thus frame a discussion in a certain way; however, emotive language can be sometimes used in a tricky way, making it seem like no counter- arguments can be successful, or even required. The speaker, by using emotive words in certain ways, can make it seem like that is no need to accept, or even to consider, a contrary viewpoint, because doing so would stem from unacceptable values. -

Propaganda Anne Quaranto and Jason Stanley to Appear in the Routledge Handbook of Social and Political Philosophy of Language
1 Propaganda Anne Quaranto and Jason Stanley To appear in the Routledge Handbook of Social and Political Philosophy of Language Introduction Propaganda presents a problem. By assumption, propaganda bypasses reason. But how do propagandistic arguments compel? To make the matter more puzzling, propaganda often compels in the mask of reason. Consider Frederick Hoffmann’s 1896 book, Race Traits of the American Negro. In it, Hoffmann argues that Black people have less “vital force” than white people. This is a work of scientific racism, a work of racial propaganda, filled with statistics and massive amounts of evidence. In one chapter, Hoffmann argues that Black people have “excessive mortality.” In another, he argues that Black people have vastly greater propensity towards criminality. In each case, he claims that there is no environmental explanation - for example, he argues that “[i]n Washington, the colored race has had exceptional educational, religious, and social opportunities”, and so environment cannot explain racial differences in arrests. In his discussion of mortality, he argues that relevant white and Black populations in his studies have the same environmental conditions. Hoffmann’s book is presented as the epitome of reason. And yet it is racial propaganda. In his discussion of Hoffmann’s book, the historian Khalil Muhammad (2010) provides a clue about why Hoffmann’s book is propaganda, and how it uses the appearance of reason to be convincing. In his work, Hoffmann repeatedly argues that white European immigrant populations in Northern cities face worse social and environmental conditions than Blacks. And Hoffman argues that the solution to analogous social problems for these communities is an improved environment. -

Loaded Language Generates Framing Effects in the Extreme Dictator Game
Judgment and Decision Making, Vol. 14, No. 3, May, 2019, pp. 309–317 The power of moral words: Loaded language generates framing effects in the extreme dictator game Valerio Capraro∗ Andrea Vanzo† Abstract Understanding whether preferences are sensitive to the frame has been a major topic of debate in the last decades. For example, several works have explored whether the dictator game in the give frame gives rise to a different rate of pro-sociality than the same game in the take frame, leading to mixed results. Here we contribute to this debate with two experiments. In Study 1 (N=567) we implement an extreme dictator game in which the dictator either gets $0.50 and the recipient gets nothing, or the opposite (i.e., the recipient gets $0.50 and the dictator gets nothing). We experimentally manipulate the words describing the available actions using six terms, from very negative (e.g., stealing) to very positive (e.g., donating) connotations. We find that the rate of pro-sociality is affected by the words used to describe the available actions. In Study 2 (N=221) we ask brand new participants to rate each of the words used in Study 1 from “extremely wrong” to “extremely right”. We find that these moral judgments can explain the framing effect in Study 1. In sum, our studies provide evidence that framing effects in an extreme Dictator game can be generated using morally loaded language. Keywords: framing effect, moral preferences, dictator game, moral judgment 1 Introduction A stream of research has focused on whether the words used to describe the available actions can affect decision Understanding whether preferences are sensitive to non- makers’ choices.