Analyses of Characters in Dramatic Works by Using Document Embeddings
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ELEMENTS of FICTION – NARRATOR / NARRATIVE VOICE Fundamental Literary Terms That Indentify Components of Narratives “Fiction
Dr. Hallett ELEMENTS OF FICTION – NARRATOR / NARRATIVE VOICE Fundamental Literary Terms that Indentify Components of Narratives “Fiction” is defined as any imaginative re-creation of life in prose narrative form. All fiction is a falsehood of sorts because it relates events that never actually happened to people (characters) who never existed, at least not in the manner portrayed in the stories. However, fiction writers aim at creating “legitimate untruths,” since they seek to demonstrate meaningful insights into the human condition. Therefore, fiction is “untrue” in the absolute sense, but true in the universal sense. Critical Thinking – analysis of any work of literature – requires a thorough investigation of the “who, where, when, what, why, etc.” of the work. Narrator / Narrative Voice Guiding Question: Who is telling the story? …What is the … Narrative Point of View is the perspective from which the events in the story are observed and recounted. To determine the point of view, identify who is telling the story, that is, the viewer through whose eyes the readers see the action (the narrator). Consider these aspects: A. Pronoun p-o-v: First (I, We)/Second (You)/Third Person narrator (He, She, It, They] B. Narrator’s degree of Omniscience [Full, Limited, Partial, None]* C. Narrator’s degree of Objectivity [Complete, None, Some (Editorial?), Ironic]* D. Narrator’s “Un/Reliability” * The Third Person (therefore, apparently Objective) Totally Omniscient (fly-on-the-wall) Narrator is the classic narrative point of view through which a disembodied narrative voice (not that of a participant in the events) knows everything (omniscient) recounts the events, introduces the characters, reports dialogue and thoughts, and all details. -

Sustainable Development As Deus Ex Machina
Biological Conservation 209 (2017) 54–61 Contents lists available at ScienceDirect Biological Conservation journal homepage: www.elsevier.com/locate/bioc Discussion Sustainable development as deus ex machina Claudio Campagna a,b,⁎,DanielGuevarac, Bernard Le Boeuf d a Wildlife Conservation Society, Marine and Argentina Programs, Amenábar 1595, 1426 Buenos Aires, Argentina b Department of Ecology and Evolutionary Biology, University of California, Santa Cruz, California 95064, United States c Department of Philosophy, University of California, Santa Cruz, California 95064, United States d Department of Ecology and Evolutionary Biology, Institute for Marine Sciences, University of California, Santa Cruz, California 95064, United States article info abstract Article history: The advocacy of sustainable development (SD) by governments, NGOs and scientists over the last three decades Received 3 August 2016 has failed to diminish the alarming species extinction rate fueled by overuse and habitat destruction. Attempts to Received in revised form 9 January 2017 satisfy worldwide demands for economic growth and development have, in fact, thwarted conservation efforts Accepted 25 January 2017 and greatly diminished the diversity and abundance of life forms, including key iconic species. Here, we argue Available online xxxx that this crisis is one of values rooted in a discourse that justifies development and downplays the morality of human-caused extinction of life forms. The language of SD does not convey the loss—worse, it masks or rational- Keywords: Language izes it as blameless or necessary. The language of SD represents the loss in biodiversity as fallout from the reduced Conservation discourse capacity of ecosystems to provide services for human benefit, while providing no sense of the values necessary Species crisis for conserving life for its own sake. -

Plot Devices in Jane Austen's Novels
Copyright is owned by the Author of the thesis. Permission is given for a copy to be downloaded by an individual for the purpose of research and private study only. The thesis may not be reproduced elsewhere without the permission of the Author. Plot Devices in Jane Austen's Novels: Sense and Sensibility Pride and Prejudice and Persuasion A thesis presented in partial fulfilment of the requirements for the degree of Master of Arts in English at Massey University JANE ELIZABETH BROOKER 1981 ii. ABSTRACT Th is thesi s evaluates vari ous p l ot devices occurring in three novels by Jane Austen. The novels studied are Sense and Sensibility (1811), Pride and Prejudice (1813), and Persuasion (1 818) . I have chosen novels from different periods of Jane Austen ' s career as a novelist . One of the novels, Pride and Prejudice is regarded as having a virtually flawless plot , while both Sense and Sensibility and Persua sion are considered to have major plot flaws . To evaluate Jane Austen's use of plot devices , I have iso lated the main devices in each novel . Each chapter of the thesis is devoted to one t ype of plot device. The plot devices analysed come under the headings of Journeys and Character Positioning, Revelations, Elopements , Illnesses, Alternative Suitors, Minor Characters, and Conclusion. At the end of each chapter I have summarised the main points and compared the devices discussed in the chapter . The con clusion is divided int o three parts , dealing separately with the three novels . In my analysis of plot devices I have looked particularly for consistency of characterisation, and for plausible events. -

The Deus Ex Machina After the Death of God
PERFORMANCE PHILOSOPHY THEATRICAL IMMANENCE: THE DEUS EX MACHINA AFTER THE DEATH OF GOD FREDDIE ROKEM TEL AVIV UNIVERSITY/UNIVERSITY OF CHICAGO What, has this thing appeared again tonight? Shakespeare, Hamlet Introducing the Deus ex Machina The Latin term deus ex machina (apò mēkhanês theós, in Classical Greek) refers to the sudden and often unexpected appearance of a divine figure on the theatre stage, unravelling the otherwise insoluble predicaments of the humans, thus bringing the performance-narrative to a closure. Its literal meaning, “god from the machine,” comes from ancient stagecraft in which an actor playing a deity would be physically lowered by a crane-like mechanism onto the stage. Such supernatural interventions were quite common on the Greek classical stages, but they were severely criticized already by Aristotle, who argued (in chapter XV of The Poetics) that since the poet should always aim either at the necessary or the probable […] the unravelling of the plot, no less than the complication, must arise out of the plot itself, it must not be brought about by the deus ex machina—as in the Medea […]. The deus ex machina should be employed only for events external to the drama— for antecedent or subsequent events, which lie beyond the range of human knowledge, and which require to be reported or foretold; for to the gods we ascribe the power of seeing all things. Within the action there must be nothing irrational. If the irrational cannot be excluded, it should be outside the scope of the tragedy. Such is the irrational element in the Oedipus by Sophocles. -

DEUS EX MACHINA Towards an Aesthetics of Autonomous and Semi-Autonomous Machines by ELIZABETH ANN JOCHUM B.A., Wellesley College, 2001
DEUS EX MACHINA Towards an Aesthetics of Autonomous and Semi-Autonomous Machines by ELIZABETH ANN JOCHUM B.A., Wellesley College, 2001 M.A., University of Colorado, 2007 A thesis submitted to the Faculty of the Graduate School of the University of Colorado in partial fulfillment of the requirement for the degree of Doctor of Philosophy Department of Theatre and Dance 2013 This thesis entitled: Deus Ex Machina: Towards an Aesthetics of Autonomous and Semi-Autonomous Machines written by Elizabeth Ann Jochum has been approved for the Department of Theatre and Dance Professor Oliver Gerland III Professor Todd Murphey Date The final copy of this thesis has been examined by the signatories, and we Find that both the content and the form meet acceptable presentation standards Of scholarly work in the above mentioned discipline. iii Jochum, Elizabeth Ann (Ph.D., Theatre, Department of Theatre and Dance) Deus ex Machina: Towards an Aesthetics of Autonomous and Semi-Autonomous Machines Thesis directed by Associate Professor Oliver Gerland III Robots and puppets are linked by a common human impulse: the desire to give life to nonliving objects through the animation of material forms. Like puppets, robots are technological objects capable of revealing aspects of the human experience and have demonstrated the ability to provoke the suspension of disbelief and evoke agency. While the role of puppets and automata in theatre history is well established (Segel 1995, Jurkowski 1996, Reilly 2011), the study of robots in theatre performance is largely unexamined. Citing the presence of autonomous and semi- autonomous machines in live performance and technological developments that result in increasingly responsive and interactive robots, I argue that these technological players warrant critical investigation and study of their methods of representation. -

Andujar Uncles Ex Machina Final
Uncles Ex Machina: Familial Epiphany in Euripides’ Electra Rosa Andújar At the close of Euripides’s Electra, the Dioscuri suddenly appear ‘on high’ to their distraught niece and nephew, who have just killed their mother, the divine twins’ mortal sister. This is in fact the second longest extant deus ex machina (after the final scene in Hippolytus), and the only scene in which a tragedian attempts to resolve directly the aftermath of the matricide. In this article, I argue that Castor and Polydeuces’ sudden apparition to Orestes and Electra constitutes a specialized point of intersection between the mortal and immortal realms in Greek tragedy: familial epiphany; that is, an appearance by a god who has an especially intimate relationship with those on stage. Euripides’ focus on the familial divine as a category accentuates various contradictions inherent to both ancient Greek theology and dramaturgy. The Dioscuri are a living paradox, ambiguously traversing the space between dead heroes and gods, managing at the same time to occupy both. They oscillate uniquely between the mortal and immortal worlds, as different sources assign different fathers to each brother, and others speak of each one possessing divinity on alternate days. As I propose, the epiphany of these ambiguous brothers crystallizes the problem of the gods’ physical presence in drama. Tragedy is the arena in which gods burst suddenly into the mortal realm, decisively and irrevocably altering human action. The physical divine thus tends to be both marginal and directorial, tasked with reining in the plot or directing its future course. The appearance of the familial divine, on the other hand, can in fact obscure the resolution and future direction of a play, undermining the authority of the tragic gods. -

Master List of Terms Tested Literary Criticism 2009-2015 Last Updated 12 July 2015
Master List of Terms Tested Literary Criticism 2009-2015 last updated 12 July 2015 The first column details the year and test in which the term found in the second column serves as a correct answer; the remaining four columns offer the distractors used in a particular test item. I do not mind sending as an attachment a Word file that the coach and his or her team can manipulate in a manner that serves them best. Contact me: [email protected] Please contact me when you find a typo, inconsistency, or anything more serious: [email protected] Please note that the variety of distractors and, indeed, the terms themselves follows the editorial decisions that have characterized each succeeding edition of The Handbook to Literature. We are currently using the twelfth edition. Use Control + F to find a term. 2015 S rune keen koine logo siglum 2015 S ethos bathos logos mythos pathos 2015 S slam calypso rap reggae scat 2015 S aesthetics essentialism expressionism formalism metaphysics 2015 S dirge encomium epithalamium eulogy ode 2015 S tritagonist antagonist deuteragonist eiron protagonist 2015 S roman noir Gothic novel novel of incident roman à clef underground press 2015 S Agrarians Bet Generation Knickerbocker Group Muckrakers Transcendental Club 2015 S School of Donne Fleshly School of Poetry Graveyard School School of Night School of Spenser 2015 S epic question epic catalogue epic formula epic ideal epic simile 2015 S acatalectic catalectic chiasmic hypercatalectic vatic 2015 S philology belle-lettres exegesis lexicography synopsis 2015 -

DEUS EX MACHINA Writers Ponder Life and Then Try “Deus Ex Machina” Is a Literary Term
DEUS EX MACHINA Writers ponder life and then try “Deus ex machina” is a literary term. I to make sense of it by writing about it. Art see eyes glazing over, but bear with me. Translat- imitating life. I thought about that while ed literally as “God from the machine”, it’s a device writing this column and it occurred to me conceived to solve sticky plot points and requires that life also imitates art. Apparently this a completely unexpected and largely implausible occurred to Oscar Wilde as well, who wrote, circumstance. It’s not used often and it’s seldom “Life imitates art far more than art imitates successful, going all the way back to Euripides, life.” A circular puzzle and one that can get whose use of it was roundly criticized. The film away from you pretty quickly if you follow it “Adaptation” applied it to great effect when a prob- down the rabbit hole. lematic character was gobbled up by an alligator It does seem, however, that deus that comes out of nowhere. Since “Adaptation” is ex machina might have been a plot device a tongue in cheek film about writing, this is one developed to help us make sense out of time it worked in a double entendre sort of way. the indiscriminate nature of life. How nice Greek theater used a crane (machina) to lower ac- would it be to have a crane poised overhead tors portraying gods (deus) sent to get a plot back to drop angels down to halt the inevitable - on track. -
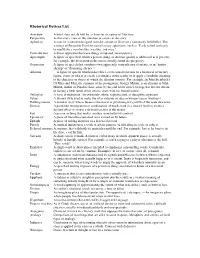
Rhetorical Devices List
Rhetorical Devices List Anecdote A brief story or tale told by a character in a piece of literature Perspective A character's view of the situation or events in the story Aphorism A concise statement designed to make a point or illustrate a commonly held belief. The writings of Benjamin Franklin contain many aphorisms, such as "Early to bed and early to rise/Make a man healthy, wealthy, and wise." Contradiction A direct opposition between things compared; inconsistency Apostrophe A figure of speech in which a person, thing, or abstract quality is addressed as if present; for example, the invocation to the muses usually found in epic poetry. Oxymoron A figure of speech that combines two apparently contradictory elements, as in "jumbo shrimp" or "deafening silence." Allusion —A figure of speech which makes brief, even casual reference to a historical or literary figure, event, or object to create a resonance in the reader or to apply a symbolic meaning to the character or object of which the allusion consists. For example, in John Steinbeck's Of Mice and Men, the surname of the protagonist, George Milton, is an allusion to John Milton, author of Paradise Lost, since by the end of the novel, George has lost the dream of having a little ranch of his own to share with his friend Lennie. Syllogism A form of deduction. An extremely subtle, sophisticated, or deceptive argument Satire A literary style used to make fun of or ridicule an idea or human vice or weakness Bildungsroman A novel or story whose theme is the moral or psychological growth of the main character. -

The COVID-19 Pandemic As Deus-Ex- Machina on the Israeli Political Stage? Discoursenet Collaborative Working Paper Series
The COVID-19 Pandemic as Deus-Ex- Machina on the Israeli Political Stage? The Early Pandemic Speeches of Benjamin Netanyahu Ariella Lahav DiscourseNet Collaborative Working Paper Series no. 2/5 | July 2020 Special Issue: Discourse Studies Essays no. 2/5 | July 2020 on the Corona-Crisis About the author About the CWPS Ariella Lahav is a member of ADARR (Analysis of Discourse, The DiscourseNet Collaborative Working Paper Series Argumentation and Rhetoric) Group at Tel-Aviv University (CWPS) reflects ongoing research activity at the intersec- (TAU). Ariella has a MA in French Culture studies, a BA in tion of language and society in an interdisciplinary field of English Literature and French Language and Literature, and discourse studies. Prolonging the activities and publica- a LLB, all from TAU, and in addition is an Israeli corporate tions of DiscourseNet, it welcomes contributions which and securities lawyer and mediator. actively engage in a dialogue across different theories of https://il.linkedin.com/in/ariella-lahav-9b4b342 discourse, disciplines, topics, methods and methodologies. contact: [email protected]. All contributions to the CWPS are work in progress. The CWPS offers an environment for an open discussion of the drafts, reports or presentations. Authors are provided with two expert commentaries for their paper and more exten- sive discussions of their ideas in the context of Discourse - Net Conferences. The CWPS seeks to provide support for the advancement and publication of the presented works. It does not inhibit further publication of the revised contribution. For further information on the CWPS visit: https://discourseanalysis.net/dncwps © Ariella Lahav 2020 About the Special Issue: Discourse Studies Essays on the Corona Crisis Any reproduction, publication and reprint in the form of a different publication, whether printed or produced elec- Edited by Jens Maeße, David Adler & Elena Psyllakou tronically, in whole or in part, is permitted only with the ex- plicit written authorisation of the authors. -

Latin Phrases Used in Philosophy
Latin and Greek for Philosophers* James Lesher The following definitions have been prepared to help you understand the meaning of the Latin words and phrases you will encounter in your study of philosophy. But first a word of caution: it would be a mistake to suppose that in mastering these definitions you will have acquired a sufficient grounding in the Latin language to employ these terms successfully in your own work. Here H. W. Fowler offers some good advice: ‘Those who use words or phrases belonging to languages with which they have little or no acquaintance do so at their peril. Even in e.g., i.e., and et cetera, there lurk unsuspected possibilities of exhibiting ignorance’ (Modern English Usage, p. 207). Use these definitions as an aid to understanding the Latin terms and phrases you encounter, but resist the temptation to begin sprinkling them about in your own writings and conversations. Latin prepositions used in the following definitions: a or ab: ‘from’ ad: ‘to’ or ‘toward’ de: ‘from’ or ‘concerning’ ex: ‘from’ or ‘out of’ per: ‘through’ or ‘by’ in: ‘in’ or ‘on’ sub: ‘under’ post: ‘after’ pro: ‘for’ or ‘in exchange for’ propter: ‘because of’ A fortiori: preposition + the ablative neuter singular of the comparative adjective fortior/fortius (literally: ‘from the stronger thing’): arguing to a conclusion from an already established stronger statement (e.g. ‘All animals are mortal, a fortiori all human beings are mortal’). A posteriori: preposition + the ablative neuter singular of the comparative adjective posterior/posteriorus (literally: ‘from the later thing’): things known a posteriori are known on the basis of experience (e.g. -

The Function of the Deus Ex Machina in Euripidean Drama
The Function of the Deus ex Machina in Euripidean Drama Dissertation Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Christine Rose Elizabeth Hamilton, B.A. Graduate Program in Greek and Latin The Ohio State University 2017 Dissertation Committee: Dana L. Munteanu, Advisor Sarah Iles Johnston Thomas Richard Hawkins 1 Copyright by Christine Rose Elizabeth Hamilton 2017 2 Abstract This dissertation explores Euripides’ use of the deus ex machina device in his extant plays. While many scholars have discussed aspects of the deus ex machina my project explores the overall function not only of the deus ex machina within its play but also the function of two other aspects common to deus ex machina speeches: aitia and prophecy. I argue that deus ex machina interventions are not motivated by a problem in the plot that they must solve but instead they are used to connect the world of the play to the world of the audience through use of cult aitia and prophecy. In Chapter 1, I provide an analysis of Euripides’ deus ex machina scenes in the Hippolytus, Andromache, Suppliants, Electra, Ion, Iphigenia in Tauris, Helen, Orestes, Bacchae, and Medea. I argue that in all but the Orestes the intervention does not have a major effect on the plot or characters and I identify certain trends in the function of deus ex machina scenes such as consolation, enhancing Athenian pride, and increasing experimentation in the deus ex machina’s role in respect to the plot of the play and the wider world of myth.