Xoxa: a Lightweight Approach to Normalizing and Signing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Describing Media Content of Binary Data in XML W3C Working Group Note 2 May 2005
Table of Contents Describing Media Content of Binary Data in XML W3C Working Group Note 2 May 2005 This version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050502 Latest version: http://www.w3.org/TR/xml-media-types Previous version: http://www.w3.org/TR/2004/WD-xml-media-types-20041102 Editors: Anish Karmarkar, Oracle Ümit Yalçınalp, SAP (formerly of Oracle) Copyright © 2005 W3C ® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. > >Abstract This document addresses the need to indicate the content-type associated with binary element content in an XML document and the need to specify, in XML Schema, the expected content-type(s) associated with binary element content. It is expected that the additional information about the content-type will be used for optimizing the handling of binary data that is part of a Web services message. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/. This document is a W3C Working Group Note. This document includes the resolution of the comments received on the Last Call Working Draft previously published. The comments on this document and their resolution can be found in the Web Services Description Working Group’s issues list and in the section C Change Log [p.11] . A diff-marked version against the previous version of this document is available. -
XML Specifications Growth of the Web
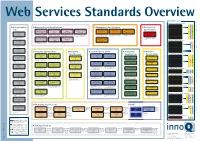
Web Services Standards Overview Dependencies Messaging Specifications SOAP 1.1 SOAP 1.2 Interoperability Business Process Specifications Management Specifications Presentation SOAP Message Transmission Optimization Mechanism WS-Notification the trademarks of their respective owners. of their respective the trademarks Management Using Web Management Of WS-BaseNotification Issues Business Process Execution WS-Choreography Model Web Service Choreography Web Service Choreography WS-Management Specifications Services (WSDM-MUWS) Web Services (WSDM-MOWS) Language for Web Services 1.1 Overview Interface Description Language AMD, Dell, Intel, Microsoft and Sun WS-Topics (BPEL4WS) · 1.1 · BEA Systems, IBM, (WSCI) · 1.0 · W3C 1.0 1.0 1.0 · W3C (CDL4WS) · 1.0 · W3C Microsystems Microsoft, SAP, Sun Microsystems, SAP, BEA Systems WS-BrokeredNotification Working Draft Candidate Recommendation OASIS OASIS Published Specification Web Services for Remote Security Resource Basic Profile Siebel Systems · OASIS-Standard and Intalio · Note OASIS-Standard OASIS-Standard Metadata Portlets (WSRP) WS-Addressing – Core 1.1 ̆ ̆ ̆ ̆ ̆ ̆ ̆ 2.0 WS-I Business Process Execution Language for Web Services WS-Choreography Model Overview defines the format Web Service Choreography Interface (WSCI) describes Web Service Choreography Description Language Web Service Distributed Management: Management Using Web Service Distributed Management: Management Of WS-Management describes a general SOAP-based WS-Addressing – WSDL Binding 1.1(BPEL4WS) provides a language for the formal -

On the Integrity and Trustworthiness of Web Produced Data
CORE Metadata, citation and similar papers at core.ac.uk Provided by Open Repository of the University of Porto On the Integrity and Trustworthiness of web produced data Luís A. Maia Mestrado Integrado em Engenharia de Redes e Sistemas Informáticos Departamento de Ciência de Computadores 2013 Orientador Professor Doutor Manuel Eduardo Carvalho Duarte Correia, Professor Auxiliar do Departamento de Computadores, Faculdade de Ciências da Universidade do Porto Todas as correções determinadas pelo júri, e só essas, foram efetuadas. O Presidente do Júri, Porto, ______/______/_________ Acknowledgments I would like to express my appreciation for the help of my supervisor in researching and bringing different perspectives and to thank my family, for their support and dedication. 3 Abstract Information Systems have been a key tool for the overall performance improvement of administrative tasks in academic institutions. While most systems intend to deliver a paperless environment to each institution it is recurrent that document integrity and accountability is still relying on traditional methods such as producing physical documents for signing and archiving. While this method delivers a non-efficient work- flow and has an effective monetary cost, it is still the common method to provide a degree of integrity and accountability on the data contained in the databases of the information systems. The evaluation of a document signature is not a straight forward process, it requires the recipient to have a copy of the signers signature for comparison and training beyond the scope of any office employee training, this leads to a serious compromise on the trustability of each document integrity and makes the verification based entirely on the trust of information origin which is not enough to provide non-repudiation to the institutions. -

XML Signature/Encryption — the Basis of Web Services Security
Special Issue on Security for Network Society Falsification Prevention and Protection Technologies and Products XML Signature/Encryption — the Basis of Web Services Security By Koji MIYAUCHI* XML is spreading quickly as a format for electronic documents and messages. As a consequence, ABSTRACT greater importance is being placed on the XML security technology. Against this background research and development efforts into XML security are being energetically pursued. This paper discusses the W3C XML Signature and XML Encryption specifications, which represent the fundamental technology of XML security, as well as other related technologies originally developed by NEC. KEYWORDS XML security, XML signature, XML encryption, Distributed signature, Web services security 1. INTRODUCTION 2. XML SIGNATURE XML is an extendible markup language, the speci- 2.1 Overview fication of which has been established by the W3C XML Signature is an electronic signature technol- (WWW Consortium). It is spreading quickly because ogy that is optimized for XML data. The practical of its flexibility and its platform-independent technol- benefits of this technology include Partial Signature, ogy, which freely allows authors to decide on docu- which allows an electronic signature to be written on ment structures. Various XML-based standard for- specific tags contained in XML data, and Multiple mats have been developed including: ebXML and Signature, which enables multiple electronic signa- RosettaNet, which are standard specifications for e- tures to be written. The use of XML Signature can commerce transactions, TravelXML, which is an EDI solve security problems, including falsification, spoof- (Electronic Data Interchange) standard for travel ing, and repudiation. agencies, and NewsML, which is a standard specifica- tion for new distribution formats. -

What Is XML Schema?
72076_FM 3/22/02 10:39 AM Page i XML Schema Essentials R. Allen Wyke Andrew Watt Wiley Computer Publishing John Wiley & Sons, Inc. 72076_AppB 3/22/02 10:47 AM Page 378 72076_FM 3/22/02 10:39 AM Page i XML Schema Essentials R. Allen Wyke Andrew Watt Wiley Computer Publishing John Wiley & Sons, Inc. 72076_FM 3/22/02 10:39 AM Page ii Publisher: Robert Ipsen Editor: Cary Sullivan Developmental Editor: Scott Amerman Associate Managing Editor: Penny Linskey Associate New Media Editor: Brian Snapp Text Design & Composition: D&G Limited, LLC Designations used by companies to distinguish their products are often claimed as trademarks. In all instances where John Wiley & Sons, Inc., is aware of a claim, the product names appear in initial capital or ALL CAPITAL LETTERS. Readers, however, should contact the appropriate companies for more complete information regarding trademarks and registration. This book is printed on acid-free paper. Copyright © 2002 by R. Allen Wyke and Andrew Watt. All rights reserved. Published by John Wiley & Sons, Inc. Published simultaneously in Canada. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copy- right Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 750-4744. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 605 Third Avenue, New York, NY 10158-0012, (212) 850-6011, fax (212) 850- 6008, E-Mail: PERMREQ @ WILEY.COM. -

Command Injection in XML Signatures and Encryption Bradley W
Command Injection in XML Signatures and Encryption Bradley W. Hill Information Security Partners, July 12, 2007 [email protected] Abstract. The XML Digital Signature1 (XMLDSIG) and XML Encryption2 (XMLENC) standards are complex protocols for securing XML and other content. Among its complexities, the XMLDSIG standard specifies various “Transform” algorithms to identify, manipulate and canonicalize signed content and key material. Unfortunately, the defined transforms have not been rigorously constrained to prevent their use as attack vectors, and denial of service or even arbitrary code execution are probable in implementations that have not specifically guarded against such risks. Attacks against the processing application can be embedded in the KeyInfo portion of a signature, making them inherently unauthenticated, or in the SignedInfo block. Although tampering with the SignedInfo should be detectable, a defective implied order of operations in the specification may still allow unauthenticated attacks here. The ability to execute arbitrary code and perform file system operations with a malicious, invalid signature has been confirmed by the researcher in at least two independent XMLDSIG implementations, and other implementations may be similarly vulnerable. This paper describes the vulnerabilities in detail and offers advice for remediation. The most damaging attack is also likely to apply in other contexts where XSLT is accepted as input, and should be considered by all implementers of complex XML processing systems. Categories and Subject Descriptors Primary Classification: K.6.5 Security and Protection Subject: Invasive software Unauthorized access Authentication Additional Classification: D.2.3 Coding Tools and Techniques (REVISED) Subject: Standards D.2.1 Requirements/Specifications (D.3.1) Subject: Languages Tools General Terms: Security, Reliability, Verification, and Design. -

Sams Teach Yourself XML in 21 Days
Steven Holzner Teach Yourself XML in 21 Days THIRD EDITION 800 East 96th Street, Indianapolis, Indiana, 46240 USA Sams Teach Yourself XML in 21 Days, ASSOCIATE PUBLISHER Michael Stephens Third Edition ACQUISITIONS EDITOR Copyright © 2004 by Sams Publishing Todd Green All rights reserved. No part of this book shall be reproduced, stored in a retrieval DEVELOPMENT EDITOR system, or transmitted by any means, electronic, mechanical, photocopying, record- Songlin Qiu ing, or otherwise, without written permission from the publisher. No patent liability MANAGING EDITOR is assumed with respect to the use of the information contained herein. Although every precaution has been taken in the preparation of this book, the publisher and Charlotte Clapp author assume no responsibility for errors or omissions. Nor is any liability assumed PROJECT EDITOR for damages resulting from the use of the information contained herein. Matthew Purcell International Standard Book Number: 0-672-32576-4 INDEXER Library of Congress Catalog Card Number: 2003110401 Mandie Frank PROOFREADER Printed in the United States of America Paula Lowell First Printing: October 2003 TECHNICAL EDITOR 06050403 4321 Chris Kenyeres Trademarks TEAM COORDINATOR Cindy Teeters All terms mentioned in this book that are known to be trademarks or service marks have been appropriately capitalized. Sams Publishing cannot attest to the accuracy INTERIOR DESIGNER of this information. Use of a term in this book should not be regarded as affecting Gary Adair the validity of any trademark or service mark. COVER DESIGNER Warning and Disclaimer Gary Adair PAGE LAYOUT Every effort has been made to make this book as complete and as accurate as possi- ble, but no warranty or fitness is implied. -

Bibliography of Erik Wilde
dretbiblio dretbiblio Erik Wilde's Bibliography References [1] AFIPS Fall Joint Computer Conference, San Francisco, California, December 1968. [2] Seventeenth IEEE Conference on Computer Communication Networks, Washington, D.C., 1978. [3] ACM SIGACT-SIGMOD Symposium on Principles of Database Systems, Los Angeles, Cal- ifornia, March 1982. ACM Press. [4] First Conference on Computer-Supported Cooperative Work, 1986. [5] 1987 ACM Conference on Hypertext, Chapel Hill, North Carolina, November 1987. ACM Press. [6] 18th IEEE International Symposium on Fault-Tolerant Computing, Tokyo, Japan, 1988. IEEE Computer Society Press. [7] Conference on Computer-Supported Cooperative Work, Portland, Oregon, 1988. ACM Press. [8] Conference on Office Information Systems, Palo Alto, California, March 1988. [9] 1989 ACM Conference on Hypertext, Pittsburgh, Pennsylvania, November 1989. ACM Press. [10] UNIX | The Legend Evolves. Summer 1990 UKUUG Conference, Buntingford, UK, 1990. UKUUG. [11] Fourth ACM Symposium on User Interface Software and Technology, Hilton Head, South Carolina, November 1991. [12] GLOBECOM'91 Conference, Phoenix, Arizona, 1991. IEEE Computer Society Press. [13] IEEE INFOCOM '91 Conference on Computer Communications, Bal Harbour, Florida, 1991. IEEE Computer Society Press. [14] IEEE International Conference on Communications, Denver, Colorado, June 1991. [15] International Workshop on CSCW, Berlin, Germany, April 1991. [16] Third ACM Conference on Hypertext, San Antonio, Texas, December 1991. ACM Press. [17] 11th Symposium on Reliable Distributed Systems, Houston, Texas, 1992. IEEE Computer Society Press. [18] 3rd Joint European Networking Conference, Innsbruck, Austria, May 1992. [19] Fourth ACM Conference on Hypertext, Milano, Italy, November 1992. ACM Press. [20] GLOBECOM'92 Conference, Orlando, Florida, December 1992. IEEE Computer Society Press. http://github.com/dret/biblio (August 29, 2018) 1 dretbiblio [21] IEEE INFOCOM '92 Conference on Computer Communications, Florence, Italy, 1992. -

Describing Media Content of Binary Data in XML W3C Working Group Note 4 May 2005
Table of Contents Describing Media Content of Binary Data in XML W3C Working Group Note 4 May 2005 This version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050504 Latest version: http://www.w3.org/TR/xml-media-types Previous version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050502 Editors: Anish Karmarkar, Oracle Ümit Yalçınalp, SAP Copyright © 2005 W3C ® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. > >Abstract This document addresses the need to indicate the content-type associated with binary element content in an XML document and the need to specify, in XML Schema, the expected content-type(s) associated with binary element content. It is expected that the additional information about the content-type will be used for optimizing the handling of binary data that is part of a Web services message. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/. This document is a W3C Working Group Note. This document includes the resolution of the comments received on the Last Call Working Draft previously published. The comments on this document and their resolution can be found in the Web Services Description Working Group’s issues list. There is no technical difference between this document and the 2 May 2005 version; the acknowledgement section has been updated to thank external contributors. -

XML Information Set
XML Information Set XML Information Set W3C Recommendation 24 October 2001 This version: http://www.w3.org/TR/2001/REC-xml-infoset-20011024 Latest version: http://www.w3.org/TR/xml-infoset Previous version: http://www.w3.org/TR/2001/PR-xml-infoset-20010810 Editors: John Cowan, [email protected] Richard Tobin, [email protected] Copyright ©1999, 2000, 2001 W3C® (MIT, INRIA, Keio), All Rights Reserved. W3C liability, trademark, document use and software licensing rules apply. Abstract This specification provides a set of definitions for use in other specifications that need to refer to the information in an XML document. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. The latest status of this document series is maintained at the W3C. This is the W3C Recommendation of the XML Information Set. This document has been reviewed by W3C Members and other interested parties and has been endorsed by the Director as a W3C Recommendation. It is a stable document and may be used as reference material or cited as a normative reference from another document. W3C's role in making the Recommendation is to draw attention to the specification and to promote its widespread deployment. This enhances the functionality and interoperability of the file:///C|/Documents%20and%20Settings/immdca01/Desktop/xml-infoset.html (1 of 16) [8/12/2002 10:38:58 AM] XML Information Set Web. This document has been produced by the W3C XML Core Working Group as part of the XML Activity in the W3C Architecture Domain. -
5241 Index 0939-0964.Qxd 29/08/02 5.30 Pm Page 941
5241_index_0939-0964.qxd 29/08/02 5.30 pm Page 941 INDEX 941 5241_index_0939-0964.qxd 29/08/02 5.30 pm Page 942 Index 942 Regular A Alternatives, 362 Analysis Patterns: Reusable Expression ABSENT value, 67 Object Models, 521 Symbols abstract attribute, 62, 64–66 ancestor (XPath axis), 54 of complexType element, ancestor-or-self (XPath axis), . escape character, 368, 369 247–248, 512, 719 54 . metacharacter, 361 of element element, 148–149 Annotation, 82 ? metacharacter, 361, 375 mapping to object-oriented defined, 390 ( metacharacter, 361 language, 513–514 mapping to object-oriented ) metacharacter, 361 Abstract language, 521 { metacharacter, 361 attribute type, 934 Microsoft use of term, } metacharacter, 361 defined, 58 821–822 + metacharacter, 361, 375 element type, 16, 17, 18, 934 properties of, 411 * metacharacter, 361, 375 object, corresponding to docu- annotation content option ^ metacharacter, 379 ment, 14 for schema element, 115 \ metacharacter, 361 uses of term, 238, 931–932 annotation element, 82, 83, | metacharacter, 361 Abstract character, 67 254, 260, 722, 859 \. escape character, 366 Abstract document attributes of, 118 \? escape character, 366 document information item content options for, 118–119 \( escape character, 367 view of, 62 example of use of, 117 \) escape character, 367 infoset view of, 62 function of, 116, 124, 128 \{ escape character, 367 makeup of, 59 nested, 83–84 \} escape character, 367 properties of, 66 Anonymous component, 82 \+ escape character, 367 Abstract element, 14–15 any element, 859 \- escape character, -

Feasibility and Performance Evaluation of Canonical XML
Feasibility and Performance Evaluation of Canonical XML Student Research Project Manuel Binna Student: E-mail: [email protected] Matriculation Number: 108004202162 Supervisor: Dipl.-Inf. Meiko Jensen Period: 20.07.2010 - 19.10.2010 Chair for Network and Data Security Prof. Dr. Jörg Schwenk Faculty of Electrical Engineering and Information Technology Ruhr University Bochum Feasibility and Performance Evaluation of Canonical XML Manuel Binna Abstract Within the boundaries of the XML specification, XML documents can be formatted in various ways without losing the logical equivalence of its content within the scope of the application. However, some applications like XML Signature cannot deal with this flexibility, thus needing a definite textual representation in order to distinguish changes which do or do not alter the logical equivalence of XML content. Canonical XML provides a method to transform textually different yet logically equivalent XML content into a single definite textual representation. This work evaluates the upcoming new major version Canonical XML Version 2.0 with respect to feasibility and performance. Chair for Network and Data Security, Ruhr University Bochum 2 Feasibility and Performance Evaluation of Canonical XML Manuel Binna Declaration I hereby declare that the content of this thesis is a work of my own and that it is original to the best of my knowledge, except where indicated by references to other sources. ____________________________ ______________________________________ Location, Date Signature Chair for Network and Data Security, Ruhr University Bochum 3 Feasibility and Performance Evaluation of Canonical XML Manuel Binna Table of Contents 1. Introduction! 5 1.1.XML 5 1.2.Canonicalization 6 1.3.History 7 1.4.Canonicalization and XML Signature 16 2.