And Frequency-Domain Supervised Clustering
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
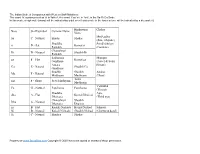
Note Staff Symbol Carnatic Name Hindustani Name Chakra Sa C
The Indian Scale & Comparison with Western Staff Notations: The vowel 'a' is pronounced as 'a' in 'father', the vowel 'i' as 'ee' in 'feet', in the Sa-Ri-Ga Scale In this scale, a high note (swara) will be indicated by a dot over it and a note in the lower octave will be indicated by a dot under it. Hindustani Chakra Note Staff Symbol Carnatic Name Name MulAadhar Sa C - Natural Shadaj Shadaj (Base of spine) Shuddha Swadhishthan ri D - flat Komal ri Rishabh (Genitals) Chatushruti Ri D - Natural Shudhh Ri Rishabh Sadharana Manipur ga E - Flat Komal ga Gandhara (Navel & Solar Antara Plexus) Ga E - Natural Shudhh Ga Gandhara Shudhh Shudhh Anahat Ma F - Natural Madhyam Madhyam (Heart) Tivra ma F - Sharp Prati Madhyam Madhyam Vishudhh Pa G - Natural Panchama Panchama (Throat) Shuddha Ajna dha A - Flat Komal Dhaivat Dhaivata (Third eye) Chatushruti Shudhh Dha A - Natural Dhaivata Dhaivat ni B - Flat Kaisiki Nishada Komal Nishad Sahsaar Ni B - Natural Kakali Nishada Shudhh Nishad (Crown of head) Så C - Natural Shadaja Shadaj Property of www.SarodSitar.com Copyright © 2010 Not to be copied or shared without permission. Short description of Few Popular Raags :: Sanskrut (Sanskrit) pronunciation is Raag and NOT Raga (Alphabetical) Aroha Timing Name of Raag (Karnataki Details Avroha Resemblance) Mood Vadi, Samvadi (Main Swaras) It is a old raag obtained by the combination of two raags, Ahiri Sa ri Ga Ma Pa Ga Ma Dha ni Så Ahir Bhairav Morning & Bhairav. It belongs to the Bhairav Thaat. Its first part (poorvang) has the Bhairav ang and the second part has kafi or Så ni Dha Pa Ma Ga ri Sa (Chakravaka) serious, devotional harpriya ang. -

A Novel Hybrid Approach for Retrieval of the Music Information
International Journal of Applied Engineering Research ISSN 0973-4562 Volume 12, Number 24 (2017) pp. 15011-15017 © Research India Publications. http://www.ripublication.com A Novel Hybrid Approach for Retrieval of the Music Information Varsha N. Degaonkar Research Scholar, Department of Electronics and Telecommunication, JSPM’s Rajarshi Shahu College of Engineering, Pune, Savitribai Phule Pune University, Maharashtra, India. Orcid Id: 0000-0002-7048-1626 Anju V. Kulkarni Professor, Department of Electronics and Telecommunication, Dr. D. Y. Patil Institute of Technology, Pimpri, Pune, Savitribai Phule Pune University, Maharashtra, India. Orcid Id: 0000-0002-3160-0450 Abstract like automatic music annotation, music analysis, music synthesis, etc. The performance of existing search engines for retrieval of images is facing challenges resulting in inappropriate noisy Most of the existing human computation systems operate data rather than accurate information searched for. The reason without any machine contribution. With the domain for this being data retrieval methodology is mostly based on knowledge, human computation can give best results if information in text form input by the user. In certain areas, machines are taken in a loop. In recent years, use of smart human computation can give better results than machines. In mobile devices is increased; there is a huge amount of the proposed work, two approaches are presented. In the first multimedia data generated and uploaded to the web every day. approach, Unassisted and Assisted Crowd Sourcing This data, such as music, field sounds, broadcast news, and techniques are implemented to extract attributes for the television shows, contain sounds from a wide variety of classical music, by involving users (players) in the activity. -

The Rich Heritage of Dhrupad Sangeet in Pushtimarg On
Copyright © 2006 www.vallabhkankroli.org - All Rights Reserved by Shree Vakpati Foundation - Baroda ||Shree DwaDwarrrrkeshokesho Jayati|| || Shree Vallabhadhish Vijayate || The Rich Heritage Of Dhrupad Sangeet in Pushtimarg on www.vallabhkankroli.org Reference : 8th Year Text Book of Pushtimargiya Patrachaar by Shree Vakpati Foundation - Baroda Inspiration: PPG 108 Shree Vrajeshkumar Maharajshri - Kankroli PPG 108 Shree Vagishkumar Bawashri - Kankroli Copyright © 2006 www.vallabhkankroli.org - All Rights Reserved by Shree Vakpati Foundation - Baroda Contents Meaning of Sangeet ........................................................................................................................... 4 Naad, Shruti and Swar ....................................................................................................................... 4 Definition of Raga.............................................................................................................................. 5 Rules for Defining Ragas................................................................................................................... 6 The Defining Elements in the Raga................................................................................................... 7 Vadi, Samvadi, Anuvadi, Vivadi [ Sonant, Consonant, Assonant, Dissonant] ................................ 8 Aroha, avaroha [Ascending, Descending] ......................................................................................... 8 Twelve Swaras of the Octave ........................................................................................................... -

University of Mauritius Mahatma Gandhi Institute
University of Mauritius Mahatma Gandhi Institute Regulations And Programme of Studies B. A (Hons) Performing Arts (Vocal Hindustani) (Review) - 1 - UNIVERSITY OF MAURITIUS MAHATMA GANDHI INSTITUTE PART I General Regulations for B.A (Hons) Performing Arts (Vocal Hindustani) 1. Programme title: B.A (Hons) Performing Arts (Vocal Hindustani) 2. Objectives To equip the student with further knowledge and skills in Vocal Hindustani Music and proficiency in the teaching of the subject. 3. General Entry Requirements In accordance with the University General Entry Requirements for admission to undergraduate degree programmes. 4. Programme Requirement A post A-Level MGI Diploma in Performing Arts (Vocal Hindustani) or an alternative qualification acceptable to the University of Mauritius. 5. Programme Duration Normal Maximum Degree (P/T): 2 years 4 years (4 semesters) (8 semesters) 6. Credit System 6.1 Introduction 6.1.1 The B.A (Hons) Performing Arts (Vocal Hindustani) programme is built up on a 3- year part time Diploma, which accounts for 60 credits. 6.1.2 The Programme is structured on the credit system and is run on a semester basis. 6.1.3 A semester is of a duration of 15 weeks (excluding examination period). - 2 - 6.1.4 A credit is a unit of measure, and the Programme is based on the following guidelines: 15 hours of lectures and / or tutorials: 1 credit 6.2 Programme Structure The B.A Programme is made up of a number of modules carrying 3 credits each, except the Dissertation which carries 9 credits. 6.3 Minimum Credits Required for the Award of the Degree: 6.3.1 The MGI Diploma already accounts for 60 credits. -

12 NI 6340 MASHKOOR ALI KHAN, Vocals ANINDO CHATTERJEE, Tabla KEDAR NAPHADE, Harmonium MICHAEL HARRISON & SHAMPA BHATTACHARYA, Tanpuras
From left to right: Pandit Anindo Chatterjee, Shampa Bhattacharya, Ustad Mashkoor Ali Khan, Michael Harrison, Kedar Naphade Photo credit: Ira Meistrich, edited by Tina Psoinos 12 NI 6340 MASHKOOR ALI KHAN, vocals ANINDO CHATTERJEE, tabla KEDAR NAPHADE, harmonium MICHAEL HARRISON & SHAMPA BHATTACHARYA, tanpuras TRANSCENDENCE Raga Desh: Man Rang Dani, drut bandish in Jhaptal – 9:45 Raga Shahana: Janeman Janeman, madhyalaya bandish in Teental – 14:17 Raga Jhinjhoti: Daata Tumhi Ho, madhyalaya bandish in Rupak tal, Aaj Man Basa Gayee, drut bandish in Teental – 25:01 Raga Bhupali: Deem Dara Dir Dir, tarana in Teental – 4:57 Raga Basant: Geli Geli Andi Andi Dole, drut bandish in Ektal – 9:05 Recorded on 29-30 May, 2015 at Academy of Arts and Letters, New York, NY Produced and Engineered by Adam Abeshouse Edited, Mixed and Mastered by Adam Abeshouse Co-produced by Shampa Bhattacharya, Michael Harrison and Peter Robles Sponsored by the American Academy of Indian Classical Music (AAICM) Photography, Cover Art and Design by Tina Psoinos 2 NI 6340 NI 6340 11 at Carnegie Hall, the Rubin Museum of Art and Raga Music Circle in New York, MITHAS in Boston, A True Master of Khayal; Recollections of a Disciple Raga Samay Festival in Philadelphia and many other venues. His awards are many, but include the Sangeet Natak Akademi Puraskar by the Sangeet Natak Aka- In 1999 I was invited to meet Ustad Mashkoor Ali Khan, or Khan Sahib as we respectfully call him, and to demi, New Delhi, 2015 and the Gandharva Award by the Hindusthan Art & Music Society, Kolkata, accompany him on tanpura at an Indian music festival in New Jersey. -

Stephen M. Slawek Curriculum Vitae
Stephen M. Slawek Curriculum Vitae 10008 Sausalito Drive Butler School of Music Austin, TX 78759-6106 The University of Texas at Austin (512) 794-2981 Austin, TX. 78712-0435 (512) 471-0671 Education 1986 Ph.D. (Ethnomusicology) University of Illinois at Urbana-Champaign 1978 M.A. (Ethnomusicology) University of Hawaii at Manoa 1976 M. Mus. (Sitar) Banaras Hindu University 1974 B. Mus. (Sitar) Banaras Hindu University 1973 Diploma (Tabla) Banaras Hindu University 1971 B.A. (Biology) University of Pennsylvania Employment 1999-present Professor of Ethnomusicology, The University of Texas at Austin 2000 Visiting Professor, Rice University, Hanzsen and Lovett College 1989-1999 Associate Professor of Ethnomusicology and Asian Studies, The University of Texas at Austin 1985-1989 Assistant Professor of Ethnomusicology and Asian Studies, The University of Texas at Austin 1983-1985 Instructor of Ethnomusicology and Asian Studies, The University of Texas at Austin 1983 Visiting Lecturer of Ethnomusicology, University of Illinois at Urbana- Champaign 1982 Graduate Assistant, School of Music, University of Illinois at Urbana- Champaign 1978-1980 Archivist, Archives of Ethnomusicology, School of Music, University of Illinois at Urbana-Champaign Scholarship and Creative Activities Books under contract The Classical Music of India: Going Global with Ravi Shankar. New York and London: Routledge Press. 1997 Musical Instruments of North India: Eighteenth Century Portraits by Baltazard Solvyns. Delhi: Manohar Publishers. Pp. i-vi and 1-153. (with Robert L. Hardgrave) SLAWEK- curriculum vitae 2 1987 Sitar Technique in Nibaddh Forms. New Delhi: Motilal Banarsidass, Indological Publishers and Booksellers. Pp. i-xix and 1-232. Articles in scholarly journals 1996 In Raga, in Tala, Out of Culture?: Problems and Prospects of a Hindustani Musical Transplant in Central Texas. -

Music (Hindustani Music) Vocal and Instrumental (Sitar)
SEMESTER –III (THEORY ) INDIAN MUSIC (HINDUSTANI MUSIC) VOCAL AND INSTRUMENTAL (SITAR) Syllabus and Courses of Study in Indian Music for B.A. Under CBCS for the Examination to be held in Dec. 2017, 2018 and 2019 DURATION OF EXAMINATION: 2½Hrs MAX. MARKS: 40 (32+08) COURSE Code. UMUTC 301 EXTERNAL EXAM: 32 (Marks) CREDITS: 2(2hrs per week) INTERNAL EXAM: 08 (Marks) APPLIED THEORY AND HISTORY OF INDIAN MUSIC SECTION – A Prescribed Ragas: 1. Bhupali 2. Bheemplasi 3. Khamaj 1. (A) Writing description of the prescribed ragas. (B) Writing of notation of Chota Khayal/Razakhani Gat or/Maseetkhani Gat in any one of the above prescribed Ragas in Pandit V.N. Bhatkhandey notation system with few Tanas/Todas. 2. (A) Description of below mentioned Talas with giving single, Dugun,Tigun & Chougun layakaries in Pandit V.N. Bhatkhandey notation system. 1. Chartal 2. Tilwara Taal. (including previous Semester’s Talas). (B) Compartive study of the ragas with their similar Ragas(Samprakritik Ragas) & Identifying the Swar combinations of prescribed Ragas SECTION – B 1. Detailed study of the following Musicology: Meend,Murki,Gamak,Tarab,Chikari,Zamzama,Ghaseet,Krintan,Avirbhava, Tirobhava 2. Detailed study of the following:- Khayal,(Vilambit&Drut)&Razakhani/Maseetkhani Gat ,Dhrupad 3. Establishment of shudh swaras on 22 Shruties according to ancient,medieval & modern scholars 4.Classification of Indian Musical instruments with detailed study of your own instrument.(Sitar/Taanpura) SECTION – C 1. History of Indian Music of Ancient period with special reference of Grantha/books 2. Gamak and its kinds. 3. Origin of Notation System & its merits & demrits 4. -

INDIA INTERNATIONAL CENTRE Volume XXVIII
diary Price Re.1/- INDIA INTERNATIONAL CENTRE volume XXVIII. No. 2 March – April 2014 composed Carnatic music in Hindustani ragas as well as Same Difference NottuSvarams inspired by British band music; in recent MUSIC APPRECIATION PROMOTION: The North–South years, Carnatic ragas such as Hamsadhwani and Convergence in Carnatic and Hindustani Music Charukeshi have been adopted enthusiastically by the Panelists: Subhadra Desai, Saraswati Rajagopalan north; Maharashtrian abhangs have become staples at and Suanshu Khurana Chair: Vidya Shah, March 21 Carnatic concerts; Indian classical music has shown a PERFORMANCE: A Celebration of Carnatic and willingness to naturalise Western imports such as the Hindustani Music violin, guitar, saxophone, mandolin and even the organ. Carnatic Vocal Recital by Sudha Raghunathan So what this really means is that you have two distinct Hindustani Vocal Recital by Meeta Pandit systems, with often disparate ideas about what constitutes Collaboration: Spirit of India, March 22 good music production, but tantalisingly similar lexicons and grammatical constructs that occasionally become the This was a thought-provoking discussion-demonstration basis for some interesting conversations. on the convergence between Carnatic and Hindustani music, two systems divided by a putatively common These insights kept coming to mind the next evening, musical language. The audience certainly converged; as to when the clamour of birdsong at the picturesque Rose the systems, it was largely a revelation of their divergences, Garden heralded performances by Meeta Pandit of the though a very interesting, and at times even amusing one. Gwalior gharana and then Sudha Raghunathan, the Madras Music Academy’s Sangeeta Kalanidhi for this Carnatic training begins with the raga Mayamalavagaula, year. -

B.A. General Music V & VI Sem. with 10% I.A. W.E.F. 2012-13
B.A. General Music V & VI Semesters w.e.f. 2012-13. Semester-V 1. Theory 40+10(Int. 3 Hours Assessment) 2. Practical 50 20-30 Minutes Semester-VI 1. Theory 40+10(Int. 3 Hours Assessment) 2. Practical 50 20-30 Minutes Note(i) A candidate can opt Music (Vocal) and/or Music (Instrumental) and/or Music (Tabla) and/or Indian Classical Dance (Kathak). (ii) The question paper (Theory) will be divided into three Sections comprising of 10 questions in all. Candidates will be required to attempt five questions in all, selecting at least one question from each section. All questions will carry equal marks. B.A. (General) Vocal Semester (V) Paper-1 (Theory) Time-3Hours Max.Marks: 40+10(Int. Assesment) Note: The Question paper will be divided into 3 Section Comprising of 10 question in all. The Candidate will be required to attempt 5 questions in all, Selecting at least one question from each Section. All questions will carry equal marks. Section-A (A) Historical Study and detailed description of the ragas prescribed in the Syllabus (B) Ability to write the rotations of Vilambit and drut Khayales in the following ragas: (1) Todi (2) Puria Dhanashree (3) Basant (4) Kamod (5) Bhimpalasi (C) Ability to write the hand with dugun, Tigun and Chaugun Layakaries. (1) Dhamar (2) Surtal (Thekas on Tabla also) Section-B (A) Origin and development of rotation System Merits and demerits of rotation system. (B) Lalit kalon mein sangeet ka sthan. Contribution of the following Scholars to Indian music. (1) Acharya K.C.D.Brihas pati (2) Lal mani mishra (3) Pt. -

Raga (Melodic Mode) Raga This Article Is About Melodic Modes in Indian Music
FREE SAMPLES FREE VST RESOURCES EFFECTS BLOG VIRTUAL INSTRUMENTS Raga (Melodic Mode) Raga This article is about melodic modes in Indian music. For subgenre of reggae music, see Ragga. For similar terms, see Ragini (actress), Raga (disambiguation), and Ragam (disambiguation). A Raga performance at Collège des Bernardins, France Indian classical music Carnatic music · Hindustani music · Concepts Shruti · Svara · Alankara · Raga · Rasa · Tala · A Raga (IAST: rāga), Raag or Ragam, literally means "coloring, tingeing, dyeing".[1][2] The term also refers to a concept close to melodic mode in Indian classical music.[3] Raga is a remarkable and central feature of classical Indian music tradition, but has no direct translation to concepts in the classical European music tradition.[4][5] Each raga is an array of melodic structures with musical motifs, considered in the Indian tradition to have the ability to "color the mind" and affect the emotions of the audience.[1][2][5] A raga consists of at least five notes, and each raga provides the musician with a musical framework.[3][6][7] The specific notes within a raga can be reordered and improvised by the musician, but a specific raga is either ascending or descending. Each raga has an emotional significance and symbolic associations such as with season, time and mood.[3] The raga is considered a means in Indian musical tradition to evoke certain feelings in an audience. Hundreds of raga are recognized in the classical Indian tradition, of which about 30 are common.[3][7] Each raga, state Dorothea -

(Vocal & Instrumental) Faculty of Performing Arts the M. S
Implementation of Choice Based Credit System Department of Music (Vocal & Instrumental) Faculty of Performing Arts The M. S. University of Baroda (Appendix – A) A general framework for Master’s Program shall as follows. Level Semester – Wise credits Total Credits 1 2 3 4 Master’s program 24 24 24 24 96 The credit framework for the Core course shall be as follows. HOURS Course Credit % Marks Lecture + Practical Core Compulsory TheoryIPrinciples of Music I 03 03 + 00 30%+70% Core Compulsory Theory II Study of Ragas I 03 03 + 00 30%+70% Core Compulsory IIIHistory of Music I 03 03 + 00 30%+70% Core compulsory IV Dissertation I from Core Theory 02 02 + 00 30%+70% Prescribed Syllabus Core Compulsory Practical IIntensive Practical study of 05 02 + 05 30%+70% Ragas I Core Compulsory Practical IIPractical Tradition and 05 02 + 05 30%+70% composition of Ragas I Core Compulsory Practical III Stage Performance I 03 01 + 03 30%+70% Core Subject Total Credits 24 16 + 13 30%+70% 1 Department of Music (Vocal & Instrumental) Academic Faculty of Performing Arts Year 2018-19 The Maharaja Sayajirao University of Baroda Master of Performing Arts : Music (Vocal / Sitar / Violin) Post – Graduate Program Year 1 Core Compulsory-1 : Theory I Principle of Music I Credit 3 Semester 1 Section I Aesthetics of Music Hours 45 Section II Acoustics of Music Vocal / Sitar / Violin (Practical- 0 credit & Theory-3 credit= 3 credit) To introduce Concept of Shruti and its interpretations in ancient period OBJECTIVES To improve knowledge of student in Principles of Music To introduce of Indian & Western Music scales & Notation systems Unit-1 Section I Aesthetics of Music 12 hours The Ras – Sutra of Acharya Bharat Muni. -

Machine Learning Approaches for Mood Identification in Raga: Survey
International Journal of Innovations in Engineering and Technology (IJIET) Machine Learning Approaches for Mood Identification in Raga: Survey Priyanka Lokhande Department of Computer Engineering Maharashtra Institute of Technology, Pune, Maharashtra, India Bhavana S. Tiple Department of Computer Engineering Maharashtra Institute of Technology, Pune, Maharashtra, India Abstract- Music is a “language of emotion”, which defines the emotion or feeling through music. Music directly connects to the soul and induces emotion in mind and brains. In Hindustani Classical Music raga plays very important role. It defines characteristics that differentiate ragas uniquely. Hindustani Classical Music also has nine different swaras that specifically define the emotion. In this paper we surveyed different techniques for raga identification and differentiate them according to their work and accuracy. We give the rasa - bhava relationship and raga-rasa mapping that defines the emotion related to raga. Keywords – Indian Classical Music, Emotion, Raga- Rasa relation, Classifiers. I. INTRODUCTION Indian classical music: One of an ancient tradition is Indian classical music that is an art form that is continuously growing. It has its roots in Sam Veda. Indian classical music is divided into two branches: Carnatic (South Indian Classical Music) and Hindustani (North Indian Classical Music). Carnatic music is sharp and involves many rhythmic and tonal complexities. Hindustani is mellifluous and meant to be entertainment and pleasure oriented music. Indian classical music and Western music vary from each other with respect to their notes, timings and different characteristics associated with raga. Swaras of Indian classical music are similar to the note of western classical music. There are many characteristics of Hindustani classical music.