Context Free Languages
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Parsing Based on N-Path Tree-Controlled Grammars
Theoretical and Applied Informatics ISSN 1896–5334 Vol.23 (2011), no. 3-4 pp. 213–228 DOI: 10.2478/v10179-011-0015-7 Parsing Based on n-Path Tree-Controlled Grammars MARTIN Cˇ ERMÁK,JIR͡ KOUTNÝ,ALEXANDER MEDUNA Formal Model Research Group Department of Information Systems Faculty of Information Technology Brno University of Technology Božetechovaˇ 2, 612 66 Brno, Czech Republic icermak, ikoutny, meduna@fit.vutbr.cz Received 15 November 2011, Revised 1 December 2011, Accepted 4 December 2011 Abstract: This paper discusses recently introduced kind of linguistically motivated restriction placed on tree-controlled grammars—context-free grammars with some root-to-leaf paths in their derivation trees restricted by a control language. We deal with restrictions placed on n ¸ 1 paths controlled by a deter- ministic context–free language, and we recall several basic properties of such a rewriting system. Then, we study the possibilities of corresponding parsing methods working in polynomial time and demonstrate that some non-context-free languages can be generated by this regulated rewriting model. Furthermore, we illustrate the syntax analysis of LL grammars with controlled paths. Finally, we briefly discuss how to base parsing methods on bottom-up syntax–analysis. Keywords: regulated rewriting, derivation tree, tree-controlled grammars, path-controlled grammars, parsing, n-path tree-controlled grammars 1. Introduction The investigation of context-free grammars with restricted derivation trees repre- sents an important trend in today’s formal language theory (see [3], [6], [10], [11], [12], [13] and [15]). In essence, these grammars generate their languages just like ordinary context-free grammars do, but their derivation trees have to satisfy some simple pre- scribed conditions. -

High-Performance Context-Free Parser for Polymorphic Malware Detection
High-Performance Context-Free Parser for Polymorphic Malware Detection Young H. Cho and William H. Mangione-Smith The University of California, Los Angeles, CA 91311 {young, billms}@ee.ucla.edu http://cares.icsl.ucla.edu Abstract. Due to increasing economic damage from computer network intrusions, many routers have built-in firewalls that can classify packets based on header information. Such classification engine can be effective in stopping attacks that target protocol specific vulnerabilities. However, they are not able to detect worms that are encapsulated in the packet payload. One method used to detect such application-level attack is deep packet inspection. Unlike the most firewalls, a system with a deep packet inspection engine can search for one or more specific patterns in all parts of the packets. Although deep packet inspection increases the packet filtering effectiveness and accuracy, most of the current implementations do not extend beyond recognizing a set of predefined regular expressions. In this paper, we present an advanced inspection engine architecture that is capable of recognizing language structures described by context-free grammars. We begin by modifying a known regular expression engine to function as the lexical analyzer. Then we build an efficient multi-threaded parsing co-processor that processes the tokens from the lexical analyzer according to the grammar. 1 Introduction One effective method for detecting network attacks is called deep packet inspec- tion. Unlike the traditional firewall methods, deep packet inspection is designed to search and detect the entire packet for known attack signatures. However, due to high processing requirement, implementing such a detector using a general purpose processor is costly for 1+ gigabit network. -

Compiler Design
CCOOMMPPIILLEERR DDEESSIIGGNN -- PPAARRSSEERR http://www.tutorialspoint.com/compiler_design/compiler_design_parser.htm Copyright © tutorialspoint.com In the previous chapter, we understood the basic concepts involved in parsing. In this chapter, we will learn the various types of parser construction methods available. Parsing can be defined as top-down or bottom-up based on how the parse-tree is constructed. Top-Down Parsing We have learnt in the last chapter that the top-down parsing technique parses the input, and starts constructing a parse tree from the root node gradually moving down to the leaf nodes. The types of top-down parsing are depicted below: Recursive Descent Parsing Recursive descent is a top-down parsing technique that constructs the parse tree from the top and the input is read from left to right. It uses procedures for every terminal and non-terminal entity. This parsing technique recursively parses the input to make a parse tree, which may or may not require back-tracking. But the grammar associated with it ifnotleftfactored cannot avoid back- tracking. A form of recursive-descent parsing that does not require any back-tracking is known as predictive parsing. This parsing technique is regarded recursive as it uses context-free grammar which is recursive in nature. Back-tracking Top- down parsers start from the root node startsymbol and match the input string against the production rules to replace them ifmatched. To understand this, take the following example of CFG: S → rXd | rZd X → oa | ea Z → ai For an input string: read, a top-down parser, will behave like this: It will start with S from the production rules and will match its yield to the left-most letter of the input, i.e. -

Type Checking by Context-Sensitive Languages
TYPE CHECKING BY CONTEXT-SENSITIVE LANGUAGES Lukáš Rychnovský Doctoral Degree Programme (1), FIT BUT E-mail: rychnov@fit.vutbr.cz Supervised by: Dušan Kolárˇ E-mail: kolar@fit.vutbr.cz ABSTRACT This article presents some ideas from parsing Context-Sensitive languages. Introduces Scattered- Context grammars and languages and describes usage of such grammars to parse CS languages. The main goal of this article is to present results from type checking using CS parsing. 1 INTRODUCTION This work results from [Kol–04] where relationship between regulated pushdown automata (RPDA) and Turing machines is discussed. We are particulary interested in algorithms which may be used to obtain RPDAs from equivalent Turing machines. Such interest arises purely from practical reasons because RPDAs provide easier implementation techniques for prob- lems where Turing machines are naturally used. As a representant of such problems we study context-sensitive extensions of programming language grammars which are usually context- free. By introducing context-sensitive syntax analysis into the source code parsing process a whole class of new problems may be solved at this stage of a compiler. Namely issues with correct variable definitions, type checking etc. 2 SCATTERED CONTEXT GRAMMARS Definition 2.1 A scattered context grammar (SCG) G is a quadruple (V,T,P,S), where V is a finite set of symbols, T ⊂ V,S ∈ V\T, and P is a set of production rules of the form ∗ (A1,...,An) → (w1,...,wn),n ≥ 1,∀Ai : Ai ∈ V\T,∀wi : wi ∈ V Definition 2.2 Let G = (V,T,P,S) be a SCG. Let (A1,...,An) → (w1,...,wn) ∈ P. -

Compiler Construction
Compiler construction Martin Steffen February 20, 2017 Contents 1 Abstract 1 1.1 Parsing . .1 1.1.1 First and follow sets . .1 1.1.2 Top-down parsing . 15 1.1.3 Bottom-up parsing . 43 2 Reference 78 1 Abstract Abstract This is the handout version of the slides. It contains basically the same content, only in a way which allows more compact printing. Sometimes, the overlays, which make sense in a presentation, are not fully rendered here. Besides the material of the slides, the handout versions may also contain additional remarks and background information which may or may not be helpful in getting the bigger picture. 1.1 Parsing 31. 1. 2017 1.1.1 First and follow sets Overview • First and Follow set: general concepts for grammars – textbook looks at one parsing technique (top-down) [Louden, 1997, Chap. 4] before studying First/Follow sets – we: take First/Follow sets before any parsing technique • two transformation techniques for grammars, both preserving the accepted language 1. removal for left-recursion 2. left factoring First and Follow sets • general concept for grammars • certain types of analyses (e.g. parsing): – info needed about possible “forms” of derivable words, 1. First-set of A which terminal symbols can appear at the start of strings derived from a given nonterminal A 1 2. Follow-set of A Which terminals can follow A in some sentential form. 3. Remarks • sentential form: word derived from grammar’s starting symbol • later: different algos for First and Follow sets, for all non-terminals of a given grammar • mostly straightforward • one complication: nullable symbols (non-terminals) • Note: those sets depend on grammar, not the language First sets Definition 1 (First set). -
Left-Recursive Grammars
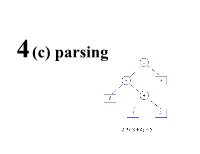
Parsing • A grammar describes the strings of tokens that are syntactically legal in a PL • A recogniser simply accepts or rejects strings. • A generator produces sentences in the language described by the grammar • A parser construct a derivation or parse tree for a sentence (if possible) • Two common types of parsers: – bottom-up or data driven – top-down or hypothesis driven • A recursive descent parser is a way to implement a top- down parser that is particularly simple. Top down vs. bottom up parsing • The parsing problem is to connect the root node S S with the tree leaves, the input • Top-down parsers: starts constructing the parse tree at the top (root) of the parse tree and move down towards the leaves. Easy to implement by hand, but work with restricted grammars. examples: - Predictive parsers (e.g., LL(k)) A = 1 + 3 * 4 / 5 • Bottom-up parsers: build the nodes on the bottom of the parse tree first. Suitable for automatic parser generation, handle a larger class of grammars. examples: – shift-reduce parser (or LR(k) parsers) • Both are general techniques that can be made to work for all languages (but not all grammars!). Top down vs. bottom up parsing • Both are general techniques that can be made to work for all languages (but not all grammars!). • Recall that a given language can be described by several grammars. • Both of these grammars describe the same language E -> E + Num E -> Num + E E -> Num E -> Num • The first one, with it’s left recursion, causes problems for top down parsers. -

BNF • Syntax Diagrams
Some Preliminaries • For the next several weeks we’ll look at how one can define a programming language • What is a language, anyway? “Language is a system of gestures, grammar, signs, 3 sounds, symbols, or words, which is used to represent and communicate concepts, ideas, meanings, and thoughts” • Human language is a way to communicate representaons from one (human) mind to another Syntax • What about a programming language? A way to communicate representaons (e.g., of data or a procedure) between human minds and/or machines CMSC 331, Some material © 1998 by Addison Wesley Longman, Inc. IntroducCon Why and How We usually break down the problem of defining Why? We want specificaons for several a programming language into two parts communies: • Other language designers • defining the PL’s syntax • Implementers • defining the PL’s semanBcs • Machines? Syntax - the form or structure of the • Programmers (the users of the language) expressions, statements, and program units How? One way is via natural language descrip- Seman-cs - the meaning of the expressions, Bons (e.g., user manuals, text books) but there statements, and program units are more formal techniques for specifying the There’s not always a clear boundary between syntax and semanBcs the two Syntax part Syntax Overview • Language preliminaries • Context-free grammars and BNF • Syntax diagrams This is an overview of the standard process of turning a text file into an executable program. IntroducCon Lexical Structure of Programming Languages A sentence is a string of characters over some -

Top-Down Parser
Top-Down Parser We have learnt in the last chapter that the top-down parsing technique parses the input, and starts constructing a parse tree from the root node gradually moving down to the leaf nodes. The types of top-down parsing are depicted below: Recursive Descent Parsing Recursive descent is a top-down parsing technique that constructs the parse tree from the top and the input is read from left to right. It uses procedures for every terminal and non-terminal entity. This parsing technique recursively parses the input to make a parse tree, which may or may not require back-tracking. But the grammar associated with it (if not left factored) cannot avoid back-tracking. A form of recursive-descent parsing that does not require any back-tracking is known as predictive parsing. This parsing technique is regarded recursive as it uses context-free grammar which is recursive in nature. Back-tracking Top- down parsers start from the root node (start symbol) and match the input string against the production rules to replace them (if matched). To understand this, take the following example of CFG: S → rXd | rZd X → oa | ea Z → ai For an input string: read, a top-down parser, will behave like this: It will start with S from the production rules and will match its yield to the left-most letter of the input, i.e. ‘r’. The very production of S (S → rXd) matches with it. So the top-down parser advances to the next input letter (i.e. ‘e’). The parser tries to expand non-terminal ‘X’ and checks its production from the left (X → oa). -

Table Driven Prediction for Recursive Descent LL(K) Parsers
Rochester Institute of Technology RIT Scholar Works Theses 12-2007 Table driven prediction for recursive descent LL(k) parsers William M. Leiserson Follow this and additional works at: https://scholarworks.rit.edu/theses Recommended Citation Leiserson, William M., "Table driven prediction for recursive descent LL(k) parsers" (2007). Thesis. Rochester Institute of Technology. Accessed from This Thesis is brought to you for free and open access by RIT Scholar Works. It has been accepted for inclusion in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact [email protected]. Table Driven Prediction for Recursive Descent LL(k) Parsers by William M Leiserson A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science in Computer Science Supervised by Professor James Heliotis, PhD Department of Computer Science Golisano, College of Computing and Information Science Rochester Institute of Technology Rochester, New York December 2007 Approved By: James Heliotis James Heliotis, PhD Professor of Computer Science, RIT Primary Adviser Axel Schreiner Axel Schreiner, PhD Professor of Computer Science, RIT F. Kazemian \:t/1 /o-, Fereydoun Kazemian, PhD Professor of Computer Science, RIT Thesis Release Permission Form Rochester Institute of Technology Golisano College of Computing and Information Science Title: Table Driven Prediction for Recursive Descent LL(k) Parsers I, William M Leiserson, hereby grant permission to the Wallace Memorial Library re porduce my thesis in whole or part. William Leiserson William M Leiserson ;z_/g/zoo1 Acknowledgments I am grateful to Prof. Jim Heliotis for his help in developing this work and especially for directing me to prior art in the area of design. -

LL(*): the Foundation of the ANTLR Parser Generator DRAFT
LL(*): The Foundation of the ANTLR Parser Generator DRAFT Accepted to PLDI 2011 Terence Parr Kathleen S. Fisher University of San Francisco AT&T Labs Research [email protected] kfi[email protected] Abstract In the \top-down" world, Ford introduced Packrat parsers Despite the power of Parser Expression Grammars (PEGs) and the associated Parser Expression Grammars (PEGs) [5, and GLR, parsing is not a solved problem. Adding nonde- 6]. PEGs preclude only the use of left-recursive grammar terminism (parser speculation) to traditional LL and LR rules. Packrat parsers are backtracking parsers that attempt parsers can lead to unexpected parse-time behavior and in- the alternative productions in the order specified. The first troduces practical issues with error handling, single-step de- production that matches at an input position wins. Pack- bugging, and side-effecting embedded grammar actions. This rat parsers are linear rather than exponential because they paper introduces the LL(*) parsing strategy and an asso- memoize partial results, ensuring input states will never be ciated grammar analysis algorithm that constructs LL(*) parsed by the same production more than once. The Rats! parsing decisions from ANTLR grammars. At parse-time, [7] PEG-based tool vigorously optimizes away memoization decisions gracefully throttle up from conventional fixed k ≥ events to improve speed and reduce the memory footprint. 1 lookahead to arbitrary lookahead and, finally, fail over to A significant advantage of both GLR and PEG parser backtracking depending on the complexity of the parsing de- generators is that they accept any grammar that conforms cision and the input symbols. -

Properties of LL-Regular Languages
Purdue University Purdue e-Pubs Department of Computer Science Technical Reports Department of Computer Science 1977 Properties of LL-Regular Languages David A. Poplawski Report Number: 77-241 Poplawski, David A., "Properties of LL-Regular Languages" (1977). Department of Computer Science Technical Reports. Paper 177. https://docs.lib.purdue.edu/cstech/177 This document has been made available through Purdue e-Pubs, a service of the Purdue University Libraries. Please contact [email protected] for additional information. PROPERTIES OF LL-REGULAR LANGUAGES David A. Poplawski Computer Science Department Purdue University W. Lafayette, Ind 47907 CSD TR-241 PROPERTIES OF LL-REGULAR LRNGURGES David R. Pop: aujski Rugust 1, 1377' HSSTRROT: The requirements for a context-free grammar to be !_!_- regular are relaxed, producing a larger ciasa of grammars than the original definition. Relationships between LL-regular prannMars and 1 .arrzuaees and other classes of t'ramma^s and languages are investigated, decidability questions are considered and linear time parsing algorithm is described. INTRODUCTION Until recently, efficient deterministic top-down parsing of context- free languages ^as limited to the class of LL(k) languages [8,8], and some variants [1,7,9]. In addition the claso of l.L(f) languages [3] was introduced, but due to the arbitrary nature of the function f, efficient parsing was ofter, irripossi!:^ e. Efficient top-::'oiyn parsing has bean achieved by restricting f to the class of functions computab1, e by generalized sequential machines [5], thereby defining the class of LL-reg'j"iar languages. This paper extends the class of grammars which define LL-regular languages and in addition provides some neu; results not covered in [5], including a two pass parsing algorithm similar to the parsing algorithm for LR-regular languages [2]. -

A Guide to Parsing
A Guide to Parsing Comparing Algorithms and explaining Terminology Learn more at tomassetti.me We have already introduced a few parsing terms, while listing the major tools and libraries used for parsing in Java, C#, Python and JavaScript. In this article we make a more in-depth presentation of the concepts and algorithms used in parsing, so that you can get a better understanding of this fascinating world. We have tried to be practical in this article. Our goal is to help practicioners, not to explain the full theory. We just explain what you need to know to understand and build parser. After the definition of parsing the article is divided in three parts: 1. The Big Picture. A section in which we describe the fundamental terms and components of a parser. 2. Grammars. In this part we explain the main formats of a grammar and the most common issues in writing them. 3. Parsing Algorithms. Here we discuss all the most used parsing algorithms and say what they are good for. Table of Contents Definition of Parsing ........................................................................................................................... 5 The Big Picture .................................................................................................................................... 6 Regular Expressions ........................................................................................................................ 6 Regular Expressions in Grammars .............................................................................................