Boolean Grammars✩
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Parsing Based on N-Path Tree-Controlled Grammars
Theoretical and Applied Informatics ISSN 1896–5334 Vol.23 (2011), no. 3-4 pp. 213–228 DOI: 10.2478/v10179-011-0015-7 Parsing Based on n-Path Tree-Controlled Grammars MARTIN Cˇ ERMÁK,JIR͡ KOUTNÝ,ALEXANDER MEDUNA Formal Model Research Group Department of Information Systems Faculty of Information Technology Brno University of Technology Božetechovaˇ 2, 612 66 Brno, Czech Republic icermak, ikoutny, meduna@fit.vutbr.cz Received 15 November 2011, Revised 1 December 2011, Accepted 4 December 2011 Abstract: This paper discusses recently introduced kind of linguistically motivated restriction placed on tree-controlled grammars—context-free grammars with some root-to-leaf paths in their derivation trees restricted by a control language. We deal with restrictions placed on n ¸ 1 paths controlled by a deter- ministic context–free language, and we recall several basic properties of such a rewriting system. Then, we study the possibilities of corresponding parsing methods working in polynomial time and demonstrate that some non-context-free languages can be generated by this regulated rewriting model. Furthermore, we illustrate the syntax analysis of LL grammars with controlled paths. Finally, we briefly discuss how to base parsing methods on bottom-up syntax–analysis. Keywords: regulated rewriting, derivation tree, tree-controlled grammars, path-controlled grammars, parsing, n-path tree-controlled grammars 1. Introduction The investigation of context-free grammars with restricted derivation trees repre- sents an important trend in today’s formal language theory (see [3], [6], [10], [11], [12], [13] and [15]). In essence, these grammars generate their languages just like ordinary context-free grammars do, but their derivation trees have to satisfy some simple pre- scribed conditions. -

High-Performance Context-Free Parser for Polymorphic Malware Detection
High-Performance Context-Free Parser for Polymorphic Malware Detection Young H. Cho and William H. Mangione-Smith The University of California, Los Angeles, CA 91311 {young, billms}@ee.ucla.edu http://cares.icsl.ucla.edu Abstract. Due to increasing economic damage from computer network intrusions, many routers have built-in firewalls that can classify packets based on header information. Such classification engine can be effective in stopping attacks that target protocol specific vulnerabilities. However, they are not able to detect worms that are encapsulated in the packet payload. One method used to detect such application-level attack is deep packet inspection. Unlike the most firewalls, a system with a deep packet inspection engine can search for one or more specific patterns in all parts of the packets. Although deep packet inspection increases the packet filtering effectiveness and accuracy, most of the current implementations do not extend beyond recognizing a set of predefined regular expressions. In this paper, we present an advanced inspection engine architecture that is capable of recognizing language structures described by context-free grammars. We begin by modifying a known regular expression engine to function as the lexical analyzer. Then we build an efficient multi-threaded parsing co-processor that processes the tokens from the lexical analyzer according to the grammar. 1 Introduction One effective method for detecting network attacks is called deep packet inspec- tion. Unlike the traditional firewall methods, deep packet inspection is designed to search and detect the entire packet for known attack signatures. However, due to high processing requirement, implementing such a detector using a general purpose processor is costly for 1+ gigabit network. -

Compiler Design
CCOOMMPPIILLEERR DDEESSIIGGNN -- PPAARRSSEERR http://www.tutorialspoint.com/compiler_design/compiler_design_parser.htm Copyright © tutorialspoint.com In the previous chapter, we understood the basic concepts involved in parsing. In this chapter, we will learn the various types of parser construction methods available. Parsing can be defined as top-down or bottom-up based on how the parse-tree is constructed. Top-Down Parsing We have learnt in the last chapter that the top-down parsing technique parses the input, and starts constructing a parse tree from the root node gradually moving down to the leaf nodes. The types of top-down parsing are depicted below: Recursive Descent Parsing Recursive descent is a top-down parsing technique that constructs the parse tree from the top and the input is read from left to right. It uses procedures for every terminal and non-terminal entity. This parsing technique recursively parses the input to make a parse tree, which may or may not require back-tracking. But the grammar associated with it ifnotleftfactored cannot avoid back- tracking. A form of recursive-descent parsing that does not require any back-tracking is known as predictive parsing. This parsing technique is regarded recursive as it uses context-free grammar which is recursive in nature. Back-tracking Top- down parsers start from the root node startsymbol and match the input string against the production rules to replace them ifmatched. To understand this, take the following example of CFG: S → rXd | rZd X → oa | ea Z → ai For an input string: read, a top-down parser, will behave like this: It will start with S from the production rules and will match its yield to the left-most letter of the input, i.e. -
![Cs.FL] 7 Dec 2020 4 a Model Programming Language and Its Grammar 11 4.1 Alphabet](https://docslib.b-cdn.net/cover/1877/cs-fl-7-dec-2020-4-a-model-programming-language-and-its-grammar-11-4-1-alphabet-1741877.webp)
Cs.FL] 7 Dec 2020 4 a Model Programming Language and Its Grammar 11 4.1 Alphabet
Describing the syntax of programming languages using conjunctive and Boolean grammars∗ Alexander Okhotin† December 8, 2020 Abstract A classical result by Floyd (\On the non-existence of a phrase structure grammar for ALGOL 60", 1962) states that the complete syntax of any sensible programming language cannot be described by the ordinary kind of formal grammars (Chomsky's \context-free"). This paper uses grammars extended with conjunction and negation operators, known as con- junctive grammars and Boolean grammars, to describe the set of well-formed programs in a simple typeless procedural programming language. A complete Boolean grammar, which defines such concepts as declaration of variables and functions before their use, is constructed and explained. Using the Generalized LR parsing algorithm for Boolean grammars, a pro- gram can then be parsed in time O(n4) in its length, while another known algorithm allows subcubic-time parsing. Next, it is shown how to transform this grammar to an unambiguous conjunctive grammar, with square-time parsing. This becomes apparently the first specifica- tion of the syntax of a programming language entirely by a computationally feasible formal grammar. Contents 1 Introduction 2 2 Conjunctive and Boolean grammars 5 2.1 Conjunctive grammars . .5 2.2 Boolean grammars . .6 2.3 Ambiguity . .7 3 Language specification with conjunctive and Boolean grammars 8 arXiv:2012.03538v1 [cs.FL] 7 Dec 2020 4 A model programming language and its grammar 11 4.1 Alphabet . 11 4.2 Lexical conventions . 12 4.3 Identifier matching . 13 4.4 Expressions . 14 4.5 Statements . 15 4.6 Function declarations . 16 4.7 Declaration of variables before use . -

Type Checking by Context-Sensitive Languages
TYPE CHECKING BY CONTEXT-SENSITIVE LANGUAGES Lukáš Rychnovský Doctoral Degree Programme (1), FIT BUT E-mail: rychnov@fit.vutbr.cz Supervised by: Dušan Kolárˇ E-mail: kolar@fit.vutbr.cz ABSTRACT This article presents some ideas from parsing Context-Sensitive languages. Introduces Scattered- Context grammars and languages and describes usage of such grammars to parse CS languages. The main goal of this article is to present results from type checking using CS parsing. 1 INTRODUCTION This work results from [Kol–04] where relationship between regulated pushdown automata (RPDA) and Turing machines is discussed. We are particulary interested in algorithms which may be used to obtain RPDAs from equivalent Turing machines. Such interest arises purely from practical reasons because RPDAs provide easier implementation techniques for prob- lems where Turing machines are naturally used. As a representant of such problems we study context-sensitive extensions of programming language grammars which are usually context- free. By introducing context-sensitive syntax analysis into the source code parsing process a whole class of new problems may be solved at this stage of a compiler. Namely issues with correct variable definitions, type checking etc. 2 SCATTERED CONTEXT GRAMMARS Definition 2.1 A scattered context grammar (SCG) G is a quadruple (V,T,P,S), where V is a finite set of symbols, T ⊂ V,S ∈ V\T, and P is a set of production rules of the form ∗ (A1,...,An) → (w1,...,wn),n ≥ 1,∀Ai : Ai ∈ V\T,∀wi : wi ∈ V Definition 2.2 Let G = (V,T,P,S) be a SCG. Let (A1,...,An) → (w1,...,wn) ∈ P. -

Compiler Construction
Compiler construction Martin Steffen February 20, 2017 Contents 1 Abstract 1 1.1 Parsing . .1 1.1.1 First and follow sets . .1 1.1.2 Top-down parsing . 15 1.1.3 Bottom-up parsing . 43 2 Reference 78 1 Abstract Abstract This is the handout version of the slides. It contains basically the same content, only in a way which allows more compact printing. Sometimes, the overlays, which make sense in a presentation, are not fully rendered here. Besides the material of the slides, the handout versions may also contain additional remarks and background information which may or may not be helpful in getting the bigger picture. 1.1 Parsing 31. 1. 2017 1.1.1 First and follow sets Overview • First and Follow set: general concepts for grammars – textbook looks at one parsing technique (top-down) [Louden, 1997, Chap. 4] before studying First/Follow sets – we: take First/Follow sets before any parsing technique • two transformation techniques for grammars, both preserving the accepted language 1. removal for left-recursion 2. left factoring First and Follow sets • general concept for grammars • certain types of analyses (e.g. parsing): – info needed about possible “forms” of derivable words, 1. First-set of A which terminal symbols can appear at the start of strings derived from a given nonterminal A 1 2. Follow-set of A Which terminals can follow A in some sentential form. 3. Remarks • sentential form: word derived from grammar’s starting symbol • later: different algos for First and Follow sets, for all non-terminals of a given grammar • mostly straightforward • one complication: nullable symbols (non-terminals) • Note: those sets depend on grammar, not the language First sets Definition 1 (First set). -

A Boolean Grammar for a Simple Programming Language
A Boolean grammar for a simple programming language Alexander Okhotin [email protected] Technical report 2004–478 School of Computing, Queen’s University, Kingston, Ontario, Canada K7L 3N6 March 2004 Abstract A toy procedural programming language is defined, and a Boolean grammar for the set of well-formed programs in this language is constructed. This is apparently the first specification of a programming language entirely by a formal grammar. Contents 1 Introduction 2 2 Definition of the language 2 3 Boolean grammars 6 4 A Boolean grammar for the language 8 5 Conclusion 16 A A parser 19 B Test suite 22 C Performance 33 1 1 Introduction Formal methods have been employed in the specification of programming languages since the early days of computer science. Already the Algol 60 report [5, 6] used a context-free grammar to specify the complete lexical contents of the language, and, partially, its syntax. But still many actually syntactical requirements, such as the rules requiring the declaration of variables, were described in plain words together with the semantics of the language. The hope of inventing a more sophisticated context-free grammar that would specify the entire syntax of Algol 60 was buried by Floyd [3], who used a formal language- theoretic argument based upon the non-context-freeness of the language fanbncnjn > 0g to prove that identifier checking cannot be performed by a context-free grammar, and hence the set of well-formed Algol 60 programs is not context-free. The appealing prospects of giving a completely formal specification of the syntax of programming languages were not entirely abandoned, though. -

Using Contextual Representations to Efficiently Learn Context-Free
JournalofMachineLearningResearch11(2010)2707-2744 Submitted 12/09; Revised 9/10; Published 10/10 Using Contextual Representations to Efficiently Learn Context-Free Languages Alexander Clark [email protected] Department of Computer Science, Royal Holloway, University of London Egham, Surrey, TW20 0EX United Kingdom Remi´ Eyraud [email protected] Amaury Habrard [email protected] Laboratoire d’Informatique Fondamentale de Marseille CNRS UMR 6166, Aix-Marseille Universite´ 39, rue Fred´ eric´ Joliot-Curie, 13453 Marseille cedex 13, France Editor: Fernando Pereira Abstract We present a polynomial update time algorithm for the inductive inference of a large class of context-free languages using the paradigm of positive data and a membership oracle. We achieve this result by moving to a novel representation, called Contextual Binary Feature Grammars (CBFGs), which are capable of representing richly structured context-free languages as well as some context sensitive languages. These representations explicitly model the lattice structure of the distribution of a set of substrings and can be inferred using a generalisation of distributional learning. This formalism is an attempt to bridge the gap between simple learnable classes and the sorts of highly expressive representations necessary for linguistic representation: it allows the learnability of a large class of context-free languages, that includes all regular languages and those context-free languages that satisfy two simple constraints. The formalism and the algorithm seem well suited to natural language and in particular to the modeling of first language acquisition. Pre- liminary experimental results confirm the effectiveness of this approach. Keywords: grammatical inference, context-free language, positive data only, membership queries 1. -

Expressive Power of Graph Languages
Expressive Power of Graph Languages Timos Antonopoulos University of Cambridge Computer Laboratory St. Catharine’s College This dissertation is submitted for the degree of Doctor of Philosophy Abstract Finite model theory is a field of logic that originated from computer science and studies properties of finite logical structures. Algorithmic properties of problems are interpreted over structures and inspected using logical languages, and thus connections are made between the latter and computational models. The expressive power of such logical languages is examined and matched with classes of problems and algorithmic classifications. In this thesis, we look into the expressive power of Graph Logic and also its extension with a recursion operator, that was introduced by Cardelli, Gardner and Ghelli, and later systematically investigated by Dawar, Gardner and Ghelli. Graph Logic was introduced as a query language on labelled directed graphs and is an extension of first-order logic with a spatial connective that allows one to express that a graph can be decomposed into two subgraphs, and reason thereafter about the properties definable over the two subgraphs in isolation from each other. It was known that Graph Logic is contained in monadic second-order logic over graphs and we show that the containment is strict. Furthermore, we investigate the expressive power of the logic over restricted classes of graphs. In addition, the expressive power of Graph Logic with the recursion operator, which over many classes of graphs exceeds the one of monadic second-order logic, is studied and compared to the expressive power of other related languages. 2 Preface First of all, I would like to thank my supervisor Dr. -
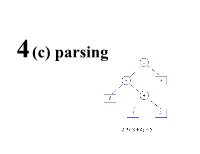
Left-Recursive Grammars
Parsing • A grammar describes the strings of tokens that are syntactically legal in a PL • A recogniser simply accepts or rejects strings. • A generator produces sentences in the language described by the grammar • A parser construct a derivation or parse tree for a sentence (if possible) • Two common types of parsers: – bottom-up or data driven – top-down or hypothesis driven • A recursive descent parser is a way to implement a top- down parser that is particularly simple. Top down vs. bottom up parsing • The parsing problem is to connect the root node S S with the tree leaves, the input • Top-down parsers: starts constructing the parse tree at the top (root) of the parse tree and move down towards the leaves. Easy to implement by hand, but work with restricted grammars. examples: - Predictive parsers (e.g., LL(k)) A = 1 + 3 * 4 / 5 • Bottom-up parsers: build the nodes on the bottom of the parse tree first. Suitable for automatic parser generation, handle a larger class of grammars. examples: – shift-reduce parser (or LR(k) parsers) • Both are general techniques that can be made to work for all languages (but not all grammars!). Top down vs. bottom up parsing • Both are general techniques that can be made to work for all languages (but not all grammars!). • Recall that a given language can be described by several grammars. • Both of these grammars describe the same language E -> E + Num E -> Num + E E -> Num E -> Num • The first one, with it’s left recursion, causes problems for top down parsers. -

BNF • Syntax Diagrams
Some Preliminaries • For the next several weeks we’ll look at how one can define a programming language • What is a language, anyway? “Language is a system of gestures, grammar, signs, 3 sounds, symbols, or words, which is used to represent and communicate concepts, ideas, meanings, and thoughts” • Human language is a way to communicate representaons from one (human) mind to another Syntax • What about a programming language? A way to communicate representaons (e.g., of data or a procedure) between human minds and/or machines CMSC 331, Some material © 1998 by Addison Wesley Longman, Inc. IntroducCon Why and How We usually break down the problem of defining Why? We want specificaons for several a programming language into two parts communies: • Other language designers • defining the PL’s syntax • Implementers • defining the PL’s semanBcs • Machines? Syntax - the form or structure of the • Programmers (the users of the language) expressions, statements, and program units How? One way is via natural language descrip- Seman-cs - the meaning of the expressions, Bons (e.g., user manuals, text books) but there statements, and program units are more formal techniques for specifying the There’s not always a clear boundary between syntax and semanBcs the two Syntax part Syntax Overview • Language preliminaries • Context-free grammars and BNF • Syntax diagrams This is an overview of the standard process of turning a text file into an executable program. IntroducCon Lexical Structure of Programming Languages A sentence is a string of characters over some -

Top-Down Parser
Top-Down Parser We have learnt in the last chapter that the top-down parsing technique parses the input, and starts constructing a parse tree from the root node gradually moving down to the leaf nodes. The types of top-down parsing are depicted below: Recursive Descent Parsing Recursive descent is a top-down parsing technique that constructs the parse tree from the top and the input is read from left to right. It uses procedures for every terminal and non-terminal entity. This parsing technique recursively parses the input to make a parse tree, which may or may not require back-tracking. But the grammar associated with it (if not left factored) cannot avoid back-tracking. A form of recursive-descent parsing that does not require any back-tracking is known as predictive parsing. This parsing technique is regarded recursive as it uses context-free grammar which is recursive in nature. Back-tracking Top- down parsers start from the root node (start symbol) and match the input string against the production rules to replace them (if matched). To understand this, take the following example of CFG: S → rXd | rZd X → oa | ea Z → ai For an input string: read, a top-down parser, will behave like this: It will start with S from the production rules and will match its yield to the left-most letter of the input, i.e. ‘r’. The very production of S (S → rXd) matches with it. So the top-down parser advances to the next input letter (i.e. ‘e’). The parser tries to expand non-terminal ‘X’ and checks its production from the left (X → oa).