Parsing Based on N-Path Tree-Controlled Grammars
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Geometric Hierarchy Beyond Context-Free Languages*
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector Theoretical Computer Science 104 (1992) 235-261 235 Elsevier A geometric hierarchy beyond context-free languages* David J. Weir School of Cognitive and Computing Science, University of Sussex, Falmer. Brighton BNI 9QH, UK Communicated by M.A. Harrison Received October 1990 Revised March 1991 Abstract Weir, D.J., A geometric hierarchy beyond context-free languages, Theoretical Computer Science 104 (1992) 235-261. This paper defines a geometric hierarchy of language classes the first member of which is context-free languages. This hierarchy generalizes the difference between context-free languages and the class of languages generated by four weakly equivalent grammar formalisms that are of interest to computa- tional linguists. A grammatical characterization of the hierarchy is given using a variant of control grammars. Each member of the progression is shown to share many of the attractive features of context-free grammars, in particular, we show that each member is an abstract family of languages. We give a progression of automata and show that it corresponds exactly to the language hierarchy defined with control grammars. 1. Introduction Recent work in computational linguistics suggests that more generative capacity than context-free grammars (CFG) is required to describe natural languages [14, 31. This has led to increased interest in grammar formalisms that are able to provide this additional power without sacrificing the attractive features of context-free languages (CFL) such as polynomial recognition, and various closure and decidability proper- ties. Several formalisms have been independently proposed as being suitable in this regard and it has been shown that the same class of languages is generated by four of these formalisms [19,22, 18,211. -

High-Performance Context-Free Parser for Polymorphic Malware Detection
High-Performance Context-Free Parser for Polymorphic Malware Detection Young H. Cho and William H. Mangione-Smith The University of California, Los Angeles, CA 91311 {young, billms}@ee.ucla.edu http://cares.icsl.ucla.edu Abstract. Due to increasing economic damage from computer network intrusions, many routers have built-in firewalls that can classify packets based on header information. Such classification engine can be effective in stopping attacks that target protocol specific vulnerabilities. However, they are not able to detect worms that are encapsulated in the packet payload. One method used to detect such application-level attack is deep packet inspection. Unlike the most firewalls, a system with a deep packet inspection engine can search for one or more specific patterns in all parts of the packets. Although deep packet inspection increases the packet filtering effectiveness and accuracy, most of the current implementations do not extend beyond recognizing a set of predefined regular expressions. In this paper, we present an advanced inspection engine architecture that is capable of recognizing language structures described by context-free grammars. We begin by modifying a known regular expression engine to function as the lexical analyzer. Then we build an efficient multi-threaded parsing co-processor that processes the tokens from the lexical analyzer according to the grammar. 1 Introduction One effective method for detecting network attacks is called deep packet inspec- tion. Unlike the traditional firewall methods, deep packet inspection is designed to search and detect the entire packet for known attack signatures. However, due to high processing requirement, implementing such a detector using a general purpose processor is costly for 1+ gigabit network. -

Compiler Design
CCOOMMPPIILLEERR DDEESSIIGGNN -- PPAARRSSEERR http://www.tutorialspoint.com/compiler_design/compiler_design_parser.htm Copyright © tutorialspoint.com In the previous chapter, we understood the basic concepts involved in parsing. In this chapter, we will learn the various types of parser construction methods available. Parsing can be defined as top-down or bottom-up based on how the parse-tree is constructed. Top-Down Parsing We have learnt in the last chapter that the top-down parsing technique parses the input, and starts constructing a parse tree from the root node gradually moving down to the leaf nodes. The types of top-down parsing are depicted below: Recursive Descent Parsing Recursive descent is a top-down parsing technique that constructs the parse tree from the top and the input is read from left to right. It uses procedures for every terminal and non-terminal entity. This parsing technique recursively parses the input to make a parse tree, which may or may not require back-tracking. But the grammar associated with it ifnotleftfactored cannot avoid back- tracking. A form of recursive-descent parsing that does not require any back-tracking is known as predictive parsing. This parsing technique is regarded recursive as it uses context-free grammar which is recursive in nature. Back-tracking Top- down parsers start from the root node startsymbol and match the input string against the production rules to replace them ifmatched. To understand this, take the following example of CFG: S → rXd | rZd X → oa | ea Z → ai For an input string: read, a top-down parser, will behave like this: It will start with S from the production rules and will match its yield to the left-most letter of the input, i.e. -

Grammars Controlled by Petri Nets
CORE Metadata, citation and similar papers at core.ac.uk Provided by The International Islamic University Malaysia Repository ChapterChapter 15 0 Grammars Controlled by Petri Nets J. Dassow, G. Mavlankulov, M. Othman, S. Turaev, M.H. Selamat and R. Stiebe Additional information is available at the end of the chapter http://dx.doi.org/10.5772/50637 1. Introduction Formal language theory, introduced by Noam Chomsky in the 1950s as a tool for a description of natural languages [8–10], has also been widely involved in modeling and investigating phenomena appearing in computer science, artificial intelligence and other related fields because the symbolic representation of a modeled system in the form of strings makes its processes by information processing tools very easy: coding theory, cryptography, computation theory, computational linguistics, natural computing, and many other fields directly use sets of strings for the description and analysis of modeled systems. In formal language theory a model for a phenomenon is usually constructed by representing it as a set of words, i.e., a language over a certain alphabet, and defining a generative mechanism, i.e., a grammar which identifies exactly the words of this set. With respect to the forms of their rules, grammars and their languages are divided into four classes of Chomsky hierarchy: recursively enumerable, context-sensitive, context-free and regular. Context-free grammars are the most investigated type of Chomsky hierarchy which, in addition, have good mathematical properties and are extensively used in many applications of formal languages. However, they cannot cover all aspects which occur in modeling of phenomena. -

Automaten Und Formale Sprachen Allrode (Harz), 27
HEORIE- TTAG 2011 21. Theorietag Automaten und Formale Sprachen Allrode (Harz), 27. – 29. September 2011 Tagungsband Jürgen Dassow, Bianca Truthe (Hrsg.) Titel: 21. Theorietag „Automaten und Formale Sprachen“, Allrode (Harz), 27. – 29.9.2011, Tagungsband Veröffentlicht durch die Otto-von-Guericke-Universität Magdeburg Fakultät für Informatik Universitätsplatz 2 39106 Magdeburg Herausgegeben von Jürgen Dassow und Bianca Truthe, 2011 Das Copyright liegt bei den Autoren der Beiträge. Vorwort Der Theorietag ist die Jahrestagung der Fachgruppe Automaten und Formale Sprachen der Ge- sellschaft für Informatik. Er wurde vor 20 Jahren in Magdeburg ins Leben gerufen. Seit dem Jahre 1996 wird der Theorietag von einem eintägigen Workshop mit eingeladenen Vorträgen begleitet. Im Laufe des Theorietags findet auch die jährliche Fachgruppensitzung statt. Die bisherigen Theorietage wurden in Magdeburg (1991), in Kiel (1992), auf Schloß Dag- stuhl (1993), in Herrsching bei München (1994 und 2003), auf Schloß Rauischholzhausen (1995), in Cunnersdorf in der Sächsischen Schweiz (1996), in Barnstorf bei Bremen (1997), in Riveris bei Trier (1998), in Schauenburg-Elmshagen bei Kassel (1999), in Wien (2000 und 2006), in Wendgräben bei Magdeburg (2001), in der Lutherstadt Wittenberg (2002 und 2009), in Caputh bei Potsdam (2004), in Lauterbad bei Freudenstadt (2005), in Leipzig (2007), in Wettenberg-Launsbach bei Gießen (2008) und in Baunatal bei Kassel (2010) ausgerichtet. Der diesjährige Theorietag wird nach 1991 und 2001 wieder von der Arbeitsgruppe „For- male Sprachen und Automaten“ der Otto-von-Guericke-Universität Magdeburg organisiert. Er findet mit dem vorangehenden Workshop vom 27. bis 29. September 2011 in Allrode im Harz statt. Auf dem Workshop tragen • Frank Drewes aus Umeå, • Manfred Droste aus Leipzig, • Florin Manea aus Bukarest, • Sergey Verlan aus Paris und • Georg Zetzsche aus Kaiserslautern vor. -

TH`ESE Zhe CHEN the Control System in Formal
N◦ d'ordre : 1036 THESE` pr´esent´ee`a l'Institut National des Sciences Appliquees´ de Toulouse pour l'obtention du titre de DOCTEUR de l'Universit´ede Toulouse d´elivr´epar l'INSA Sp´ecialit´e:Syst`emesInformatiques par Zhe CHEN Lab. Toulousain de Technologie et d'Ingenierie´ des Systemes` (LATTIS) Laboratoire d'Analyse et d'Architecture des Systemes` (LAAS-CNRS) Ecole´ Doctorale Syst`emes Titre de la th`ese: The Control System in Formal Language Theory and The Model Monitoring Approach for Reliability and Safety Soutenue le 9 Juillet 2010, devant le jury : Rapporteur : Maritta Heisel Professeur `al'Universit¨atDuisburg-Essen, Germany Rapporteur : Fabrice Bouquet Professeur `al'INRIA, Universit´ede Franche-Comt´e Examinateur: Gilles Motet Professeur `al'INSA de Toulouse - Directeur de th`ese Examinateur: Karama Kanoun Directeur de Recherche au LAAS-CNRS Examinateur: Jean-Paul Blanquart Astrium, European Aeronautic Defence and Space (EADS) Acknowledgement Although I have been mostly working independently in the lab during all those years, I would not have been able to do this thesis without the support, advice and encouragement of others, teachers, friends and colleagues. Accordingly, I would like to use this opportunity to express my gratitude to a number of people who over the years have contributed in various ways to the completion of this work. In the first place I would like to record my gratitude to my thesis supervisor Prof. Gilles Motet for guiding me in my research, and at the same time, for letting me the freedom to take initiatives in the development of my lines of research. -

Type Checking by Context-Sensitive Languages
TYPE CHECKING BY CONTEXT-SENSITIVE LANGUAGES Lukáš Rychnovský Doctoral Degree Programme (1), FIT BUT E-mail: rychnov@fit.vutbr.cz Supervised by: Dušan Kolárˇ E-mail: kolar@fit.vutbr.cz ABSTRACT This article presents some ideas from parsing Context-Sensitive languages. Introduces Scattered- Context grammars and languages and describes usage of such grammars to parse CS languages. The main goal of this article is to present results from type checking using CS parsing. 1 INTRODUCTION This work results from [Kol–04] where relationship between regulated pushdown automata (RPDA) and Turing machines is discussed. We are particulary interested in algorithms which may be used to obtain RPDAs from equivalent Turing machines. Such interest arises purely from practical reasons because RPDAs provide easier implementation techniques for prob- lems where Turing machines are naturally used. As a representant of such problems we study context-sensitive extensions of programming language grammars which are usually context- free. By introducing context-sensitive syntax analysis into the source code parsing process a whole class of new problems may be solved at this stage of a compiler. Namely issues with correct variable definitions, type checking etc. 2 SCATTERED CONTEXT GRAMMARS Definition 2.1 A scattered context grammar (SCG) G is a quadruple (V,T,P,S), where V is a finite set of symbols, T ⊂ V,S ∈ V\T, and P is a set of production rules of the form ∗ (A1,...,An) → (w1,...,wn),n ≥ 1,∀Ai : Ai ∈ V\T,∀wi : wi ∈ V Definition 2.2 Let G = (V,T,P,S) be a SCG. Let (A1,...,An) → (w1,...,wn) ∈ P. -

Compiler Construction
Compiler construction Martin Steffen February 20, 2017 Contents 1 Abstract 1 1.1 Parsing . .1 1.1.1 First and follow sets . .1 1.1.2 Top-down parsing . 15 1.1.3 Bottom-up parsing . 43 2 Reference 78 1 Abstract Abstract This is the handout version of the slides. It contains basically the same content, only in a way which allows more compact printing. Sometimes, the overlays, which make sense in a presentation, are not fully rendered here. Besides the material of the slides, the handout versions may also contain additional remarks and background information which may or may not be helpful in getting the bigger picture. 1.1 Parsing 31. 1. 2017 1.1.1 First and follow sets Overview • First and Follow set: general concepts for grammars – textbook looks at one parsing technique (top-down) [Louden, 1997, Chap. 4] before studying First/Follow sets – we: take First/Follow sets before any parsing technique • two transformation techniques for grammars, both preserving the accepted language 1. removal for left-recursion 2. left factoring First and Follow sets • general concept for grammars • certain types of analyses (e.g. parsing): – info needed about possible “forms” of derivable words, 1. First-set of A which terminal symbols can appear at the start of strings derived from a given nonterminal A 1 2. Follow-set of A Which terminals can follow A in some sentential form. 3. Remarks • sentential form: word derived from grammar’s starting symbol • later: different algos for First and Follow sets, for all non-terminals of a given grammar • mostly straightforward • one complication: nullable symbols (non-terminals) • Note: those sets depend on grammar, not the language First sets Definition 1 (First set). -

PETRI NET CONTROLLED GRAMMARS Sherzod Turaev ISBN:978-84-693-1536-1/DL:T-644-2010
UNIVERSITAT ROVIRA I VIRGILI PETRI NET CONTROLLED GRAMMARS Sherzod Turaev ISBN:978-84-693-1536-1/DL:T-644-2010 Facultat de Lletres Departament de Filologies Romàniques Petri Net Controlled Grammars PhD Dissertation Presented by Sherzod Turaev Supervised by Jürgen Dassow Tarragona, 2010 UNIVERSITAT ROVIRA I VIRGILI PETRI NET CONTROLLED GRAMMARS Sherzod Turaev ISBN:978-84-693-1536-1/DL:T-644-2010 Supervisor: Prof. Dr. Jürgen Dassow Fakultät für Informatik Institut für Wissens- und Sprachverarbeitung Otto-von-Guericke-Universität Magdeburg D-39106 Magdeburg, Germany Tutor: Dr. Gemma Bel Enguix Grup de Recerca en Lingüística Matemàtica Facultat de Lletres Universitat Rovira i Virgili Av. Catalunya, 35 43002 Tarragona, Spain UNIVERSITAT ROVIRA I VIRGILI PETRI NET CONTROLLED GRAMMARS Sherzod Turaev ISBN:978-84-693-1536-1/DL:T-644-2010 Acknowledgements It is a pleasure to thank many people who helped me to made this thesis possible. First of all I would like to express my sincere gratitude to my super- visor, Professor Jürgen Dassow. He helped me with his enthusiasm, his inspiration, and his efforts. During the course of this work, he provided with many helpful suggestions, constant encouragement, important advice, good teaching, good company, and lots of good ideas. It has been an honor to work with him. I would like to thank the head of our research group, Professor Car- los Martín-Vide, for his great effort in establishing the wonderful circum- stances of PhD School on Formal Languages and Applications, and for his help in receiving financial support throughout my PhD. This work was made thanks to the financial support of research grant 2006FI-01030 from AGAUR of Catalonia Government. -

Controlled Pure Grammar Systems
Journal of Universal Computer Science, vol. 18, no. 14 (2012), 2024-2040 submitted: 14/1/12, accepted: 16/4/12, appeared: 28/7/12 © J.UCS Controlled Pure Grammar Systems Alexander Meduna (Brno University of Technology, Faculty of Information Technology IT4Innovations Centre of Excellence, Brno, Czech Republic meduna@fit.vutbr.cz) Petr Zemek (Brno University of Technology, Faculty of Information Technology IT4Innovations Centre of Excellence, Brno, Czech Republic izemek@fit.vutbr.cz) Abstract: This paper discusses grammar systems that have only terminals, work in the leftmost way, and generate their languages under the regulation by control lan- guages over rule labels. It establishes three results concerning their generative power. First, without any control languages, these systems are not even able to generate all context-free languages. Second, with regular control languages, these systems, hav- ing no more than two components, characterize the family of recursively enumerable languages. Finally, with control languages that are themselves generated by regular- controlled context-free grammars, these systems over unary alphabets generate nothing but regular languages. In its introductory section, the paper gives a motivation for in- troducing these systems, and in the concluding section, it formulates several open problems. Key Words: formal languages, pure grammar systems, controlled derivations Category: F.4.2, F.4.3, F.1.1 1 Introduction Indisputably, context-free grammars are central to formal language theory as a whole (see [Rozenberg and Salomaa 1997, Dassow and P˘aun 1989, Meduna 2000, Salomaa 1973]). It thus comes as no surprise that this theory has introduced a broad variety of their modified versions, ranging from simplified and restricted versions up to fundamentally generalized systems based upon these grammars. -

Grammars with Regulated Rewriting
Grammars with Regulated Rewriting J¨urgen Dassow Otto-von-Guericke-Universit¨atMagdeburg PSF 4120, D – 39016 Magdeburg e-mail: [email protected] Abstract: Context-free grammars are not able to cover all linguistic phenomena. Thus we define some types of grammars where context-free rules are used and restric- tion imposed on the derivations. We illustrate the concepts by example, compare the generative power, give some closure and decidability properties and basic facts on syntactic complexity. 0. Introduction The regular and context-free grammars/languages are the most investigated types of formal languages which, in addition, have a lot of nice properties (see [9, 11, 14] and the corresponding chapters of this volume). However, these types of grammars/languages are not able to cover all aspects which occur in modelling of phenomena by means of formal languages. Here we only mention an example from natural languages. Let us consider the following sequence of a German dialect spoken in Switzerland: S1=Jan s¨aitdas mer em Hans h¨alfed. (Jan says that we helped Hans.) S2=Jan s¨aitdas mer em Hans es Huus h¨alfed aastriche. (Jan said that we helped Hans to paint the house.) S3=Jan s¨aitdas mer d’chind em Hans es Huus l¨ondh¨alfed aastriche. (Jan said that we allowed the children to help Hans to paint the house.) Further, let h be the morphisms which maps Hans and h¨alfed to the letter a, Huus, aastriche, d’chind and l¨ond to b and all other words of the sentences to the empty word. -
Left-Recursive Grammars
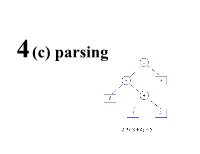
Parsing • A grammar describes the strings of tokens that are syntactically legal in a PL • A recogniser simply accepts or rejects strings. • A generator produces sentences in the language described by the grammar • A parser construct a derivation or parse tree for a sentence (if possible) • Two common types of parsers: – bottom-up or data driven – top-down or hypothesis driven • A recursive descent parser is a way to implement a top- down parser that is particularly simple. Top down vs. bottom up parsing • The parsing problem is to connect the root node S S with the tree leaves, the input • Top-down parsers: starts constructing the parse tree at the top (root) of the parse tree and move down towards the leaves. Easy to implement by hand, but work with restricted grammars. examples: - Predictive parsers (e.g., LL(k)) A = 1 + 3 * 4 / 5 • Bottom-up parsers: build the nodes on the bottom of the parse tree first. Suitable for automatic parser generation, handle a larger class of grammars. examples: – shift-reduce parser (or LR(k) parsers) • Both are general techniques that can be made to work for all languages (but not all grammars!). Top down vs. bottom up parsing • Both are general techniques that can be made to work for all languages (but not all grammars!). • Recall that a given language can be described by several grammars. • Both of these grammars describe the same language E -> E + Num E -> Num + E E -> Num E -> Num • The first one, with it’s left recursion, causes problems for top down parsers.