PROTEINS: Structure, Function and Bioinformatics in Press (Prot-00261-2006.R1)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Gene Symbol Gene Description ACVR1B Activin a Receptor, Type IB
Table S1. Kinase clones included in human kinase cDNA library for yeast two-hybrid screening Gene Symbol Gene Description ACVR1B activin A receptor, type IB ADCK2 aarF domain containing kinase 2 ADCK4 aarF domain containing kinase 4 AGK multiple substrate lipid kinase;MULK AK1 adenylate kinase 1 AK3 adenylate kinase 3 like 1 AK3L1 adenylate kinase 3 ALDH18A1 aldehyde dehydrogenase 18 family, member A1;ALDH18A1 ALK anaplastic lymphoma kinase (Ki-1) ALPK1 alpha-kinase 1 ALPK2 alpha-kinase 2 AMHR2 anti-Mullerian hormone receptor, type II ARAF v-raf murine sarcoma 3611 viral oncogene homolog 1 ARSG arylsulfatase G;ARSG AURKB aurora kinase B AURKC aurora kinase C BCKDK branched chain alpha-ketoacid dehydrogenase kinase BMPR1A bone morphogenetic protein receptor, type IA BMPR2 bone morphogenetic protein receptor, type II (serine/threonine kinase) BRAF v-raf murine sarcoma viral oncogene homolog B1 BRD3 bromodomain containing 3 BRD4 bromodomain containing 4 BTK Bruton agammaglobulinemia tyrosine kinase BUB1 BUB1 budding uninhibited by benzimidazoles 1 homolog (yeast) BUB1B BUB1 budding uninhibited by benzimidazoles 1 homolog beta (yeast) C9orf98 chromosome 9 open reading frame 98;C9orf98 CABC1 chaperone, ABC1 activity of bc1 complex like (S. pombe) CALM1 calmodulin 1 (phosphorylase kinase, delta) CALM2 calmodulin 2 (phosphorylase kinase, delta) CALM3 calmodulin 3 (phosphorylase kinase, delta) CAMK1 calcium/calmodulin-dependent protein kinase I CAMK2A calcium/calmodulin-dependent protein kinase (CaM kinase) II alpha CAMK2B calcium/calmodulin-dependent -

Kinome Profiling of Clinical Cancer Specimens
Published OnlineFirst March 23, 2010; DOI: 10.1158/0008-5472.CAN-09-3989 Review Cancer Research Kinome Profiling of Clinical Cancer Specimens Kaushal Parikh and Maikel P. Peppelenbosch Abstract Over the past years novel technologies have emerged to enable the determination of the transcriptome and proteome of clinical samples. These data sets will prove to be of significant value to our elucidation of the mechanisms that govern pathophysiology and may provide biological markers for future guidance in person- alized medicine. However, an equally important goal is to define those proteins that participate in signaling pathways during the disease manifestation itself or those pathways that are made active during successful clinical treatment of the disease: the main challenge now is the generation of large-scale data sets that will allow us to define kinome profiles with predictive properties on the outcome-of-disease and to obtain insight into tissue-specific analysis of kinase activity. This review describes the current techniques available to gen- erate kinome profiles of clinical tissue samples and discusses the future strategies necessary to achieve new insights into disease mechanisms and treatment targets. Cancer Res; 70(7); 2575–8. ©2010 AACR. Background the current state of the cell or tissue as characterized by pro- teomic and metabolic measurements (3). The past five years have seen an exponential increase in In this review we describe and evaluate the various tech- technological development to explore the genome and the niques that have recently become available to study the ki- proteome to understand the molecular basis of disease. How- nomes of clinical tissue samples. -
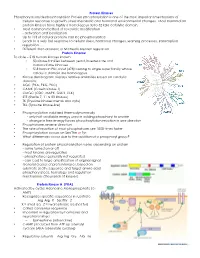
Protein Kinases Phosphorylation/Dephosphorylation Protein Phosphorylation Is One of the Most Important Mechanisms of Cellular Re
Protein Kinases Phosphorylation/dephosphorylation Protein phosphorylation is one of the most important mechanisms of cellular responses to growth, stress metabolic and hormonal environmental changes. Most mammalian protein kinases have highly a homologous 30 to 32 kDa catalytic domain. • Most common method of reversible modification - activation and localization • Up to 1/3 of cellular proteins can be phosphorylated • Leads to a very fast response to cellular stress, hormonal changes, learning processes, transcription regulation .... • Different than allosteric or Michealis Menten regulation Protein Kinome To date – 518 human kinases known • 50 kinase families between yeast, invertebrate and mammaliane kinomes • 518 human PKs, most (478) belong to single super family whose catalytic domain are homologous. • Kinase dendrogram displays relative similarities based on catalytic domains. • AGC (PKA, PKG, PKC) • CAMK (Casein kinase 1) • CMGC (CDC, MAPK, GSK3, CLK) • STE (Sterile 7, 11 & 20 kinases) • TK (Tryosine kinases memb and cyto) • TKL (Tyrosine kinase-like) • Phosphorylation stabilized thermodynamically - only half available energy used in adding phosphoryl to protein - change in free energy forces phosphorylation reaction in one direction • Phosphatases reverse direction • The rate of reaction of most phosphatases are 1000 times faster • Phosphorylation occurs on Ser/The or Tyr • What differences occur due to the addition of a phosphoryl group? • Regulation of protein phosphorylation varies depending on protein - some turned on or off -

Identification of Protein O-Glcnacylation Sites Using Electron Transfer Dissociation Mass Spectrometry on Native Peptides
Identification of protein O-GlcNAcylation sites using electron transfer dissociation mass spectrometry on native peptides Robert J. Chalkleya, Agnes Thalhammerb, Ralf Schoepfera,b, and A. L. Burlingamea,1 aDepartment of Pharmaceutical Chemistry, University of California, 600 16th Street, Genentech Hall, Suite N472, San Francisco, CA 94158; and bLaboratory for Molecular Pharmacology, and Department of Neuroscience, Physiology, and Pharmacology, University College London, Gower Street, London WC1E 6BT, United Kingdom Edited by James A. Wells, University of California, San Francisco, CA, and approved April 15, 2009 (received for review January 12, 2009) Protein O-GlcNAcylation occurs in all animals and plants and is and synaptic plasticity have been found O-GlcNAcylated (8). The implicated in modulation of a wide range of cytosolic and nuclear importance of O-GlcNAcylation is highlighted by the brain-specific protein functions, including gene silencing, nutrient and stress sens- OGT knockout mouse model that displays developmental defects ing, phosphorylation signaling, and diseases such as diabetes and that result in neonatal death (9). Most interestingly, in analogy to Alzheimer’s. The limiting factor impeding rapid progress in decipher- phosphorylation, synaptic activity leads to a dynamic modulation of ing the biological functions of protein O-GlcNAcylation has been the O-GlcNAc levels (10) and is also involved in long-term potentiation inability to easily identify exact residues of modification. We describe and memory (11). a robust, high-sensitivity strategy able to assign O-GlcNAcylation sites Phosphorylation is the most heavily studied regulatory PTM, and of native modified peptides using electron transfer dissociation mass proteomic approaches for global enrichment, detection, and char- spectrometry. -

GSK3 and Its Interactions with the PI3K/AKT/Mtor Signalling Network
Heriot-Watt University Research Gateway GSK3 and its interactions with the PI3K/AKT/mTOR signalling network Citation for published version: Hermida, MA, Kumar, JD & Leslie, NR 2017, 'GSK3 and its interactions with the PI3K/AKT/mTOR signalling network', Advances in Biological Regulation, vol. 65, pp. 5-15. https://doi.org/10.1016/j.jbior.2017.06.003 Digital Object Identifier (DOI): 10.1016/j.jbior.2017.06.003 Link: Link to publication record in Heriot-Watt Research Portal Document Version: Peer reviewed version Published In: Advances in Biological Regulation Publisher Rights Statement: © 2017 Elsevier B.V. General rights Copyright for the publications made accessible via Heriot-Watt Research Portal is retained by the author(s) and / or other copyright owners and it is a condition of accessing these publications that users recognise and abide by the legal requirements associated with these rights. Take down policy Heriot-Watt University has made every reasonable effort to ensure that the content in Heriot-Watt Research Portal complies with UK legislation. If you believe that the public display of this file breaches copyright please contact [email protected] providing details, and we will remove access to the work immediately and investigate your claim. Download date: 27. Sep. 2021 Accepted Manuscript GSK3 and its interactions with the PI3K/AKT/mTOR signalling network Miguel A. Hermida, J. Dinesh Kumar, Nick R. Leslie PII: S2212-4926(17)30124-0 DOI: 10.1016/j.jbior.2017.06.003 Reference: JBIOR 180 To appear in: Advances in Biological Regulation Received Date: 13 June 2017 Accepted Date: 23 June 2017 Please cite this article as: Hermida MA, Dinesh Kumar J, Leslie NR, GSK3 and its interactions with the PI3K/AKT/mTOR signalling network, Advances in Biological Regulation (2017), doi: 10.1016/ j.jbior.2017.06.003. -

Riok1 (BC002158) Mouse Tagged ORF Clone – MR204785 | Origene
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for MR204785 Riok1 (BC002158) Mouse Tagged ORF Clone Product data: Product Type: Expression Plasmids Product Name: Riok1 (BC002158) Mouse Tagged ORF Clone Tag: Myc-DDK Symbol: Riok1 Synonyms: 3110046C13Rik, Ad034, MGC7300 Vector: pCMV6-Entry (PS100001) E. coli Selection: Kanamycin (25 ug/mL) Cell Selection: Neomycin ORF Nucleotide >MR204785 ORF sequence Sequence: Red=Cloning site Blue=ORF Green=Tags(s) TTTTGTAATACGACTCACTATAGGGCGGCCGGGAATTCGTCGACTGGATCCGGTACCGAGGAGATCTGCC GCCGCGATCGCC ATGGTGAGGACGTGGGCAGAGAAGGAGATGAGGAATTTGTGCAGGCTAAAAACAGCAAACATACCATGTC CAGAACCAATCAGGCTAAGAAGTCATGTTCTTCTCATGGGCTTCATTGGCAAGGATGACATGCCAGCCCC ACTTTTGAAAAATGTCCAGCTGTCAGAGTCCAAGGCACGGGAGTTGTACCTGCAGGTCATTCAGTACATG AGGAAAATGTATCAGGATGCTAGACTTGTCCACGCGGATCTCAGTGAATTCAACATGCTGTACCATGGTG GAGATGTTTACATCATTGATGTTTCTCAGTCTGTGGAGCATGACCACCCACATGCATTGGAGTTCTTGAG AAAAGACTGTACCAATGTCAATGATTTCTTTTCCAAGCATGCTGTTGCAGTGATGACCGTGCGGGAGCTC TTCGACTTCGTCACAGATCCCTCCATCACTGCTGACAACATGGATGCTTACCTGGAAAAGGCTATGGAAA TAGCATCCCAGAGGACCAAGGAAGAAAAGACTAGCCAAGATCATGTGGATGAAGAGGTGTTCAAACAAGC ATATATTCCCAGAACCTTAAACGAAGTAAAGAATTATGAGAGAGATGTGGACATCATGATGAGGTTAAAG GAAGAAGACATGGCTTTGAACACTCAGCAAGACAACATTCTATACCAGACTGTCATGGGATTGAAAAAAG ATTTGTCAGGAGTCCAGAAGGTCCCCGCGCTCCTAGAAAGTGAAGTTAAGGAAGAGACTTGTTTTGGTTC AGACGATGCTGGGGGCTCTGAGTGCTCCGACACAGTCTCTGAAGAGCAGGAAGATCAAGCCGGATGCAGA AACCATATTGCTGACCCCGACGTTGATAAAAAGGAAAGAAAAAAGATGGTCAAGGAAGCCCAGAGAGAGA -

Modified Recipe to Inhibit GSK-3 for the Living Fungal Biomaterial Manufacture
bioRxiv preprint doi: https://doi.org/10.1101/496265; this version posted December 13, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. 1 Modified recipe to inhibit GSK-3 for the living fungal 2 biomaterial manufacture 1¶ 1¶ 1 1 1 3 Jinhui Chang , Po Lam Chan , Yichun Xie , Man Kit Cheung , Ka Lee Ma , Hoi Shan 1* 4 Kwan 1 5 School of Life Sciences, The Chinese University of Hong Kong, Shatin, New Territories, 6 Hong Kong 7 *Corresponding author: E-mail: [email protected] ¶ 8 These authors contributed equally to this work. 9 10 11 bioRxiv preprint doi: https://doi.org/10.1101/496265; this version posted December 13, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. 12 Abstract 13 Living fungal mycelium with suppressed or abolished fruit-forming ability is a self-healing 14 substance particularly valuable biomaterial for further engineering and development in 15 applications such as monitoring/sensing environmental changes and secreting signals. The 16 ability to suppress fungal fruiting is also a useful tool for maintaining stability (e.g., shape, 17 form) of a mycelium-based biomaterial with ease and lower cost. 18 The objective of this present study is to provide a biochemical solution to regulate the fruiting 19 body formation to replace heat killing of mycelium during production. -

Human RIOK1 / RIO Kinase 1 Protein (His & GST Tag)
Human RIOK1 / RIO kinase 1 Protein (His & GST Tag) Catalog Number: 14477-H20B General Information SDS-PAGE: Gene Name Synonym: AD034; bA288G3.1; RRP10; 3110046C13Rik; 5430416A05Rik; Ad034 Protein Construction: A DNA sequence encoding the human RIOK1 (Q9BRS2) (Met1-Lys568) was expressed with the N-terminal polyhistidine-tagged GST tag at the N-terminus. Source: Human Expression Host: Baculovirus-Insect Cells QC Testing Purity: > 85 % as determined by SDS-PAGE Bio Activity: Protein Description Kinase activity untested RIOK1, also known as RIO kinase 1, is a member of the RIO family of Endotoxin: atypical serine protein kinases first characterized in yeast. RIOK1 and RIOK2 proteins are present in organisms from Archaea to humans. RIOK1 < 1.0 EU per μg of the protein as determined by the LAL method functios as a new interactor of protein arginine methyltransferase 5 (PRMT5), competes with pICln for binding and modulates PRMT5 complex Stability: composition and substrate specificity. RioK1 and pICln bind to PRMT5 in a Samples are stable for up to twelve months from date of receipt at -70 ℃ mutually exclusive fashion. This results in a PRMT5-WD45/MEP50 core structure that either associates with pICln or RioK1 RIOK1 in distinct Predicted N terminal: Met complexes. RIOK1 functions in analogy to pICln as an adapter protein by recruiting the RNA-binding protein nucleolin to the PRMT5 complex for its Molecular Mass: symmetrical methylation. The recombinant human RIOK1/GST chimera consists of 805 amino acids References and has a calculated molecular mass of 93.4 kDa. The recombinant protein migrates as an approximately 94 kDa band in SDS-PAGE under reducing 1.Widmann B. -

Biochemical Investigation of the Interaction of Picln, Riok1 and COPR5 with the PRMT5–MEP50 Complex
Communications ChemBioChem doi.org/10.1002/cbic.202100079 1 2 3 Biochemical Investigation of the Interaction of pICln, RioK1 4 5 and COPR5 with the PRMT5–MEP50 Complex 6 [a, b] [c] [d, e] ' [f] 7 Adrian Krzyzanowski, Raphael Gasper, Hélène Adihou, Peter t Hart,* and [a, b] 8 Herbert Waldmann* 9 10 compete for the same binding site, but are not competitive 11 The PRMT5–MEP50 methyltransferase complex plays a key role with MEP50.[5] 12 in various cancers and is regulated by different protein–protein PRMT5 contains three domains, that is, the catalytic site- 13 interactions. Several proteins have been reported to act as containing Rossmann fold, a β-barrel domain used for dimeriza- 14 adaptor proteins that recruit substrate proteins to the active tion, and the TIM barrel, which acts as interaction site for 15 site of PRMT5 for the methylation of arginine residues. To MEP50 (Figure 1A).[3a,c] PRMT5 and MEP50 form a hetero- 16 define the interaction between these adaptor proteins and octameric complex whose structure has been determined,[3a] 17 PRMT5, we employed peptide truncation and mutation studies and structural information on the interaction between PRMT5 18 and prepared truncated protein constructs. We report the and the other adaptor proteins has only very recently been 19 characterisation of the interface between the TIM barrel of described in preliminary form.[7] Overexpression of PRMT5 is 20 PRMT5 and the adaptor proteins pICln, RioK1 and COPR5, and frequently observed in cancer which makes the protein an 21 identify the consensus amino acid sequence GQF[D/E]DA[E/D] intensively investigated anticancer target, and active-site di- 22 involved in binding. -

The Discovery of Novel Gsk3 Substrates and Their Role in the Brain
THE DISCOVERY OF NOVEL GSK3 SUBSTRATES AND THEIR ROLE IN THE BRAIN James Robinson A DISSERTATION IN FULFILMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY St. Vincent’s Clinical School Facility of Medicine The University of New South Wales May 2015 ORIGINALITY STATEMENT ‘I hereby declare that this submission is my own work and to the best of my knowledge it contains no materials previously published or written by another person, or substantial proportions of material which have been accepted for the award of any other degree or diploma at UNSW or any other educational institution, except where due acknowledgement is made in the thesis. Any contribution made to the research by others, with whom I have worked at UNSW or elsewhere, is explicitly acknowledged in the thesis. I also declare that the intellectual content of this thesis is the product of my own work, except to the extent that assistance from others in the project's design and conception or in style, presentation and linguistic expression is acknowledged.’ Signed ……………………………………………… Date ………………………………………………… ii |Page Abstract Bipolar Disorder (BD) is a debilitating disease that dramatically impairs people’s lives and severe cases can lead to exclusion from society and suicide. There are no clear genetic or environmental causes, and current treatments suffer from limiting side effects. Therefore, alternative intervention strategies are urgently required. Our approach is to determine mechanisms of action of current drug therapies, in the hope that they will lead to discovery of next generation therapeutic targets. Lithium has been the mainstay treatment for BD for over 50 years, although its mechanism of action is not yet clear. -

Targeting Posttranslational Modifications of RIOK1
RESEARCH ARTICLE Targeting posttranslational modifications of RIOK1 inhibits the progression of colorectal and gastric cancers Xuehui Hong1,2,3,4†, He Huang5,6†, Xingfeng Qiu2,3,4, Zhijie Ding2,3,4, Xing Feng7, Yuekun Zhu8, Huiqin Zhuo2,3,4, Jingjing Hou2,3,4, Jiabao Zhao2,3,4, Wangyu Cai2,3,4, Ruihua Sha9, Xinya Hong10, Yongxiang Li11*, Hongjiang Song12*, Zhiyong Zhang1,13* 1Longju Medical Research Center, Key Laboratory of Basic Pharmacology, Ministry of Education, Zunyi Medical College, Zunyi, China; 2Department of Gastrointestinal Surgery, Zhongshan Hospital of Xiamen University, Xiamen, China; 3Institute of Gastrointestinal Oncology, Medical College of Xiamen University, Xiamen, China; 4Xiamen Municipal Key Laboratory of Gastrointestinal Oncology, Xiamen, China; 5Department of Histology and Embryology, Xiangya School of Medicine, Central South University, Changsha, China; 6Digestive Cancer Laboratory, Second Affiliated Hospital of Xinjiang Medical University, Urumqi, China; 7Department of Radiation Oncology, Cancer Institute of New Jersey, Rutgers University, New Brunswick, United States; 8Department of General Surgery, The First Affiliated Hospital of Harbin Medical University, Harbin, China; 9Department of Digestive Disease, Hongqi Hospital, Mudanjiang Medical University, Mudanjiang, China; 10Department *For correspondence: of Medical Imaging and Ultrasound, Zhongshan Hospital of Xiamen University, 11 [email protected] Xiamen, Fujian, China; Department of General Surgery, The First Affiliated (YL); Hospital of Anhui Medical University, Hefei, China; 12Department of General [email protected] Surgery, The Third Affiliated Hospital of Harbin Medical University, Harbin, China; (HS); 13Department of Surgery, Robert-Wood-Johnson Medical School University [email protected] (ZZ) † Hospital, Rutgers University, The State University of New Jersey, New Brunswick, These authors contributed United States equally to this work Competing interests: The authors declare that no competing interests exist. -

Phosphorylation-Dependent Sub-Functionalization of the Calcium-Dependent Protein Kinase CPK28
bioRxiv preprint doi: https://doi.org/10.1101/2020.10.16.338442; this version posted October 17, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 1 Phosphorylation-dependent sub-functionalization of 2 the calcium-dependent protein kinase CPK28 3 4 5 Melissa Bredow1,#, Kyle W. Bender2,#,a, Alexandra Johnson Dingee1,b, Danalyn R. 6 Holmes1,c, Alysha Thomson1,d, Danielle Ciren1,e, Cailun A. S. Tanney1,f, Katherine E. 7 Dunning1,3, Marco Trujillo3, Steven C. Huber2, and Jacqueline Monaghan1,* 8 9 10 1 Department of Biology, Queen’s University, Kingston, Canada 11 2 Department of Plant Biology, School of Integrative Biology, University of Illinois- 12 Urbana-Champaign, Urbana-Champaign, United States of America 13 3 Department of Cell Biology, University of Freiburg, Freiburg, Germany 14 15 # These authors contributed equally to this work 16 * Corresponding author: [email protected] 17 18 19 a Current address: University of Zurich, Department of Plant and Microbial Biology, 20 Zurich, Switzerland 21 b Current address: Faculty of Law, Western University, London, Canada 22 c Current address: Center for Plant Molecular Biology, University of Tuebingen, 23 Tuebingen, Germany 24 d Current address: Faculty of Medicine, McMaster University, Hamilton, Canada 25 e Current address: Cold Spring Harbor Laboratory, Cold Spring Harbor, United States of 26 America 27 f Current address: Department of Plant Science, McGill University, Montreal, Canada 28 29 30 Keywords: calcium-dependent protein kinases, calcium-dependent protein kinase 28, 31 botrytis-induced kinase 1, phosphorylation, immune signaling, stem elongation, 32 biochemical mechanism 33 34 35 36 1 bioRxiv preprint doi: https://doi.org/10.1101/2020.10.16.338442; this version posted October 17, 2020.